详读 · DexPilot(纯视觉遥操作灵巧手-臂系统)¶
卡片版见 卡片-DexPilot。本页是全文精读:动机 → 方法(逐模块直觉+公式)→ 实验(全表)→ 洞见/局限 → 外部评价 → 对我们。 来源:arXiv 1910.03135(v2 2019-10-14)· 项目页 · 发表于 ICRA 2020 作者:Ankur Handa*、Karl Van Wyk*、Wei Yang、Jacky Liang(CMU)、Yu-Wei Chao、Qian Wan、Stan Birchfield、Nathan Ratliff、Dieter Fox(* 共同一作,NVIDIA 为主)
0. 一句话定位¶
只用四台深度相机观测裸手(无手套、无标记、无外骨骼),经"DART 模型追踪 + 神经网络先验 + 非线性优化重定向 + RMP 运动生成"四级流水线,把人手实时映射到 23 自由度(KUKA 臂 7 + Allegro 手 16) 的灵巧手-臂上,做远超抓放的精细操作(钱包抽钞、四指夹两块、拧罐盖)。目标是低成本采集高维多模态操作示范,喂给后续模仿学习。
1. 问题与动机¶
- 遥操作能把人的认知/直觉/创造力注入机器人,但高自由度多指手的遥操作要么贵(动捕/触觉手套),要么控制维度低。
- 纯视觉裸手追踪最便宜、对人干扰最小,但自遮挡/自相似导致追踪不稳,且前人多只研究"追踪"本身,不验证能否真正驱动物理机器人。
- DexPilot 的切入:用机器视觉 + 优化 + 运动生成 + GPU,把"低成本裸手追踪"做到能稳定驱动真机做精细活——即便没有触觉反馈,靠人的视觉认知(人本就靠视觉规划/预测手部动作)也能解决大量任务。
2. 系统总览(图1:能力展示)¶
 四级流水线,跑在三台电脑的三个线程上(学习线程 / 追踪线程 / 控制线程,菊花链相连):
1. DART(第V节):模型法稠密关节追踪。
2. 神经网络估手姿/关节角(第VI节):给 DART 提供初始化先验,防其陷入伪局部极小(否则每几分钟崩一次)。
3. 运动学重定向(第VII-A节):非线性优化把人手关节映射到 Allegro 关节。
4. RMP + 力矩级阻抗控制(第VII-B节):生成机器人运动。
全系统总延迟 约 1 秒。
四级流水线,跑在三台电脑的三个线程上(学习线程 / 追踪线程 / 控制线程,菊花链相连):
1. DART(第V节):模型法稠密关节追踪。
2. 神经网络估手姿/关节角(第VI节):给 DART 提供初始化先验,防其陷入伪局部极小(否则每几分钟崩一次)。
3. 运动学重定向(第VII-A节):非线性优化把人手关节映射到 Allegro 关节。
4. RMP + 力矩级阻抗控制(第VII-B节):生成机器人运动。
全系统总延迟 约 1 秒。
3. 硬件(图3)¶
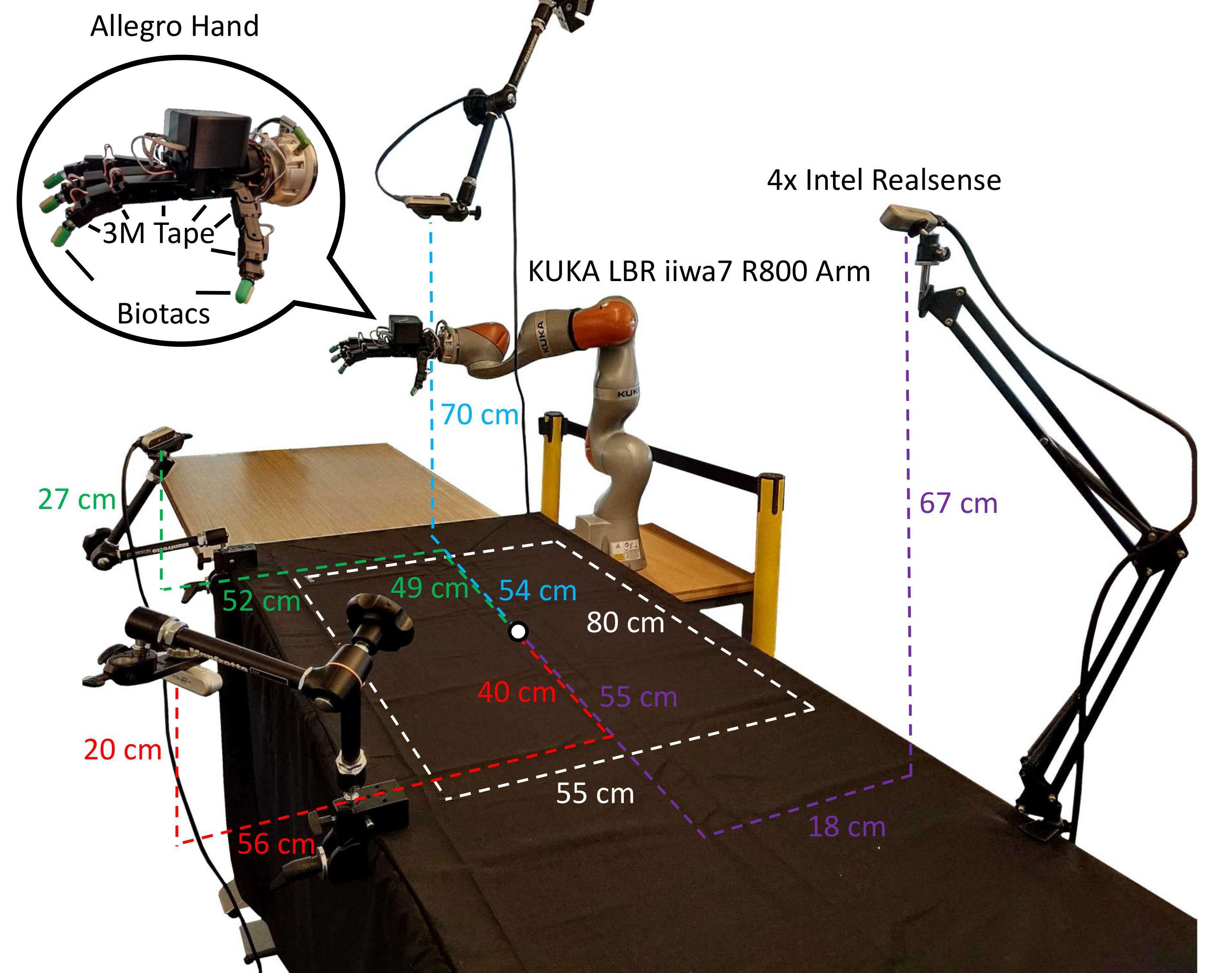 - 臂:KUKA LBR iiwa7 R800(7-DoF)。
- 手:Wonik Robotics Allegro(16-DoF)→ 合计 23 DoA。
- 触觉:指尖 4× SynTouch BioTac 传感器(共 92 路触觉信号)+ 指/掌内侧贴 3M TB641 防滑胶带。系统总输出:92 触觉 + 23 关节位置 + 23 关节力矩。
- 感知:4 台标定+时间同步的 Intel RealSense D415 RGB-D(深度需 < 1 m 才清晰)+ 2 块 NVIDIA GPU。
- 布局:黑布人手台紧邻机器人,靠视线直观映射;工作体积 80×55×38 cm。
- 臂:KUKA LBR iiwa7 R800(7-DoF)。
- 手:Wonik Robotics Allegro(16-DoF)→ 合计 23 DoA。
- 触觉:指尖 4× SynTouch BioTac 传感器(共 92 路触觉信号)+ 指/掌内侧贴 3M TB641 防滑胶带。系统总输出:92 触觉 + 23 关节位置 + 23 关节力矩。
- 感知:4 台标定+时间同步的 Intel RealSense D415 RGB-D(深度需 < 1 m 才清晰)+ 2 块 NVIDIA GPU。
- 布局:黑布人手台紧邻机器人,靠视线直观映射;工作体积 80×55×38 cm。
注:BioTac 触觉只用于记录数据(供后续学习),DexPilot 控制回路本身不用触觉反馈——这是它"无触觉也能干"的关键卖点。
4. 方法详解¶
4.1 DART 模型法追踪(第V节)¶
DART 把一个关节化人手网格模型去匹配输入点云,输出连续手姿+关节角。人手模型取自 MANO,重切成近/中/远三段链 + XML 描述运动学;共 20 个旋转关节(每指 4 个:1 外展 + 3 屈曲)。缺点:高度非线性优化,强依赖好的初始化,否则陷伪局部极小→崩。
4.2 神经网络补强追踪(第VI节,图5/6)¶
为长时间稳定追踪,用神经网络给 DART 提供手姿先验 + 手部分割。两阶段数据流程:
第一阶段(戴彩色手套)——图5:
 - 黑手套印彩色块(指尖 5 + 掌背 3)。GloveNet(4 层 ResNet-50 + spatial-softmax)从 RGB 回归 2D 块中心;OpenCV HSV 阈值自动出标注(50K 图数据集)。
- 四相机 2D 关键点 → 深度反投影成 3D → 滤波平滑得手姿;掌背三块定手姿(指尖块抖动太大,最终只用掌背)。用手姿包围盒分割出手部点喂 DART(防模型滑到手臂上)。
- 输出:为裸手点云自动生成标注,供第二阶段。
- 黑手套印彩色块(指尖 5 + 掌背 3)。GloveNet(4 层 ResNet-50 + spatial-softmax)从 RGB 回归 2D 块中心;OpenCV HSV 阈值自动出标注(50K 图数据集)。
- 四相机 2D 关键点 → 深度反投影成 3D → 滤波平滑得手姿;掌背三块定手姿(指尖块抖动太大,最终只用掌背)。用手姿包围盒分割出手部点喂 DART(防模型滑到手臂上)。
- 输出:为裸手点云自动生成标注,供第二阶段。
第二阶段(裸手)——图6: - 拟平面去桌面点 → PointNet++ 架构(基于点对点投票回归)预测 23 个关键点 3D 坐标(5 指×4 + 掌背 3)。输入点云统一下采样到 8192×3。 - 两阶段细化:一阶段粗分割+粗姿,二阶段从原始点云重采样手部点精修关键点(加随机化抗一阶段误差)。 - JointNet(两层全连接:69→128→256→20)把 23×3 关键点映成 20 维手指关节角,作 DART 关节先验。 - 训练量:100K 点云(每批 30–45 分钟、累计 7–8 小时由带手套先验的 DART 采集),单 TitanXp 训 15 小时。 - 精度:7000 张验证集上关键点平均误差 9.7 mm,关节误差 1.33°/关节。
4.3 运动学重定向(第VII-A 节,核心,图8/9)¶
难点:人手与 Allegro 关节轴/位置差异极大,不能直接对齐关节角。DexPilot 选择对齐指尖任务空间向量(指尖之间、指尖到掌的向量),因为抓取/操作中指尖(远端)最关键。代价函数:
C(q_h, q_a) = ½ Σ_i s(d_i) · ‖ r_i(q_a) − f(d_i)·r̂_i(q_h) ‖² + γ‖q_a‖²
r_i = 一坐标系到另一坐标系的向量(在本地坐标表达,故同时编码距离+方向+朝向);d_i=‖r_i(q_h)‖,r̂_i 为其单位向量。
- 切换权重 s(d_i):d>ε 取 1;d≤ε 且 r∈S1(主指→拇指向量)取 200;d≤ε 且 r∈S2(两主指都在与拇指捏合时它们之间的向量)取 400。→ 距离够近就大幅加权强约束接触几何。
- 投影/距离函数 f(d_i):d>ε 时 β·d(β=1.6 放大利于贴合);r∈S1 时 η1=1e-4 m(把主指与拇指几乎贴死做精捏);r∈S2 时 η2=3e-2 m(强制两主指间留最小间距防碰撞)。
- γ=2.5e-3 正则把 Allegro 角拉向零(=张开手),压冗余、防手指扎进掌心的怪极小。
- 额外:主指(食/中/无名)远端关节约束 = 中端关节(减冗余、仿人手)。
- 求解:SLSQP(NLopt 库),上一帧解作下一帧初值;正运动学用 Orocos KDL;输出再过一阶低通滤波去高频抖动 + 平滑投影算法引入的阶跃。
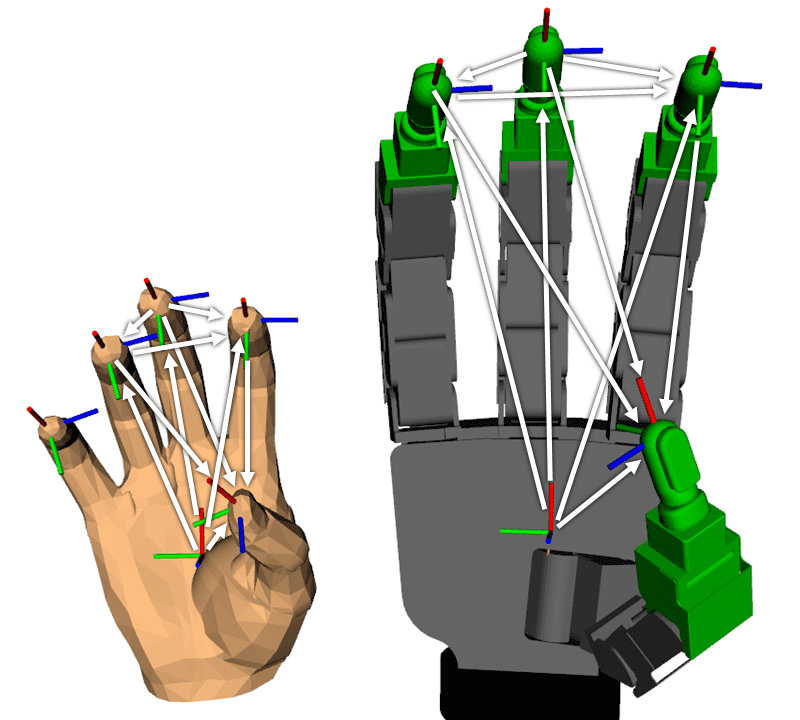

这套"投影+加权"是论文最被后人引用的部分:在追踪有误差时,仍能逼出指尖贴合的精密抓取(薄如一张纸都能捏住)。代价是松开小物体时投影会"粘手"(见局限)。
4.4 RMP 运动生成 + 控制(第VII-B 节)¶
- 黎曼运动策略(RMP):从势函数梯度+黎曼度量算加速度场,统一处理多优先级笛卡尔轨迹 + 避碰(用碰撞平面避免臂/掌撞桌或操作员)。控制 Allegro 掌的笛卡尔位姿。
- 臂:RMP 生成的关节轨迹送力矩级阻抗控制器 @200 Hz;手:重定向出的 Allegro 角送力矩级关节控制器 @30 Hz。
- 标定:用初始视图(人手张开掌平行桌面、指向前)对齐机器人初始位姿 → 机器人与人手同向运动,符合直觉。
4.5 附录里的关键消融/工程(第XII节)¶
- 彩色手套追踪(GloveNet):TTA(随机平移 16 张)算预测置信度,按 softmax 概率(
α=500,留p_i>0.2)入滚动缓冲取几何中位数做离群剔除。 - "端到端神经网络做重定向" 试过但不行(附录E):精度不如在线 SLSQP,且换任务要重训、调投影阈值麻烦 → 坚定选了优化法。
- 模型法 + 模型自由法互补(附录F/图20):神经网络给初始化,DART 在线精修;反复"采 DART 可靠数据→训网络→再增强 DART",达成长时间零失败追踪。
5. 实验(第VIII节)¶
5.1 设置¶
- 15 个任务,难度从经典抓放到多步长程(开茶抽屉取茶包再关、开钱包抽钞、开花生罐、砖块在手翻转 180°、套杯、滑卡片、翻盒…)。
- 2 名训练过的 pilot,每任务连续 5 次试验(不重置、避免挑结果),物体掉出工作区算失败。先 3–5 次非连续热身。
- 指标:完成时间 CT(速度)+ 成功率(可靠性)。
5.2 主要数字¶
| 维度 | 数字 |
|---|---|
| 系统自由度 | 23 DoA(KUKA 7 + Allegro 16) |
| 触觉/状态信号 | 92 触觉 + 23 关节位 + 23 力矩 |
| 相机/算力 | 4× RealSense D415 + 2 GPU |
| 工作体积 | 80×55×38 cm |
| 追踪精度 | 关键点 9.7 mm / 关节 1.33° |
| 系统延迟 | 约 1 s |
| 控制频率 | 臂 RMP 200 Hz / 手重定向 30 Hz |
| 重定向求解 | SLSQP(NLopt),上帧热启动 |
| 训练数据 | 100K 点云 + 50K 手套图;TitanXp 训 15 h |
5.3 完成时间(图14 / 附录D,单位秒,两 pilot 5 次均值)¶
| 任务 | Pilot1 均值±Std | Pilot2 均值±Std |
|---|---|---|
| 抓放·砖块 | 16 ± 3.11 | 19 ± 3.57 |
| 抓放·Spam | 19 ± 6.05 | 25 ± 3.78 |
| 滑卡片 | 32 ± 5.12 | 16 ± 2.54 |
| 抓放·薯片罐 | 27 ± 13.6 | 41 ± 16.22 |
| 砖块在手翻转 | 58 ± 9.50(含 2 次失败 F) | 36 ± 8.02(含 2F) |
| 倒珠 | 35 ± 6.21(1F) | 60 ± 8.61 |
| 翻盒 | 53 ± 16.73(1F) | 77 ± 60.18 |
| 大方块堆叠 | 71 ± 52.87 | 66 ± 20.12 |
| 花生罐 | 77 ± 8.25 | 80 ± 18.45 |
| 套杯 | 75 ± 13.2(1F) | 121 ± 6.18(1F) |
| 茶抽屉 | 109 ± 55.00 | 104 ± 66.22 |
| 中方块堆叠 | 180 ± 108.37 | 91 ± 38.63 |
| 钱包抽钞 | 105 ± 61.82 | 212 ± 114.36 |
| 小方块(2.3cm)堆叠 | 290 ± 165.88(1F) | 91 ± 23.57 |
| 容器(开塑料盒取纸盒) | 358 ± 72.18 | 228 ± 27.39 |
读数:① 任务越长程/越精细,CT 越大、方差越大(容器/钱包/小方块最难)。② 小方块堆叠最棘手——重定向投影方案让"松开小物"变得不可预测。③ 成功率(图15)整体高,证明纯视觉无触觉也能干,但精装配类是软肋。
5.4 多模态数据展示(图16)¶
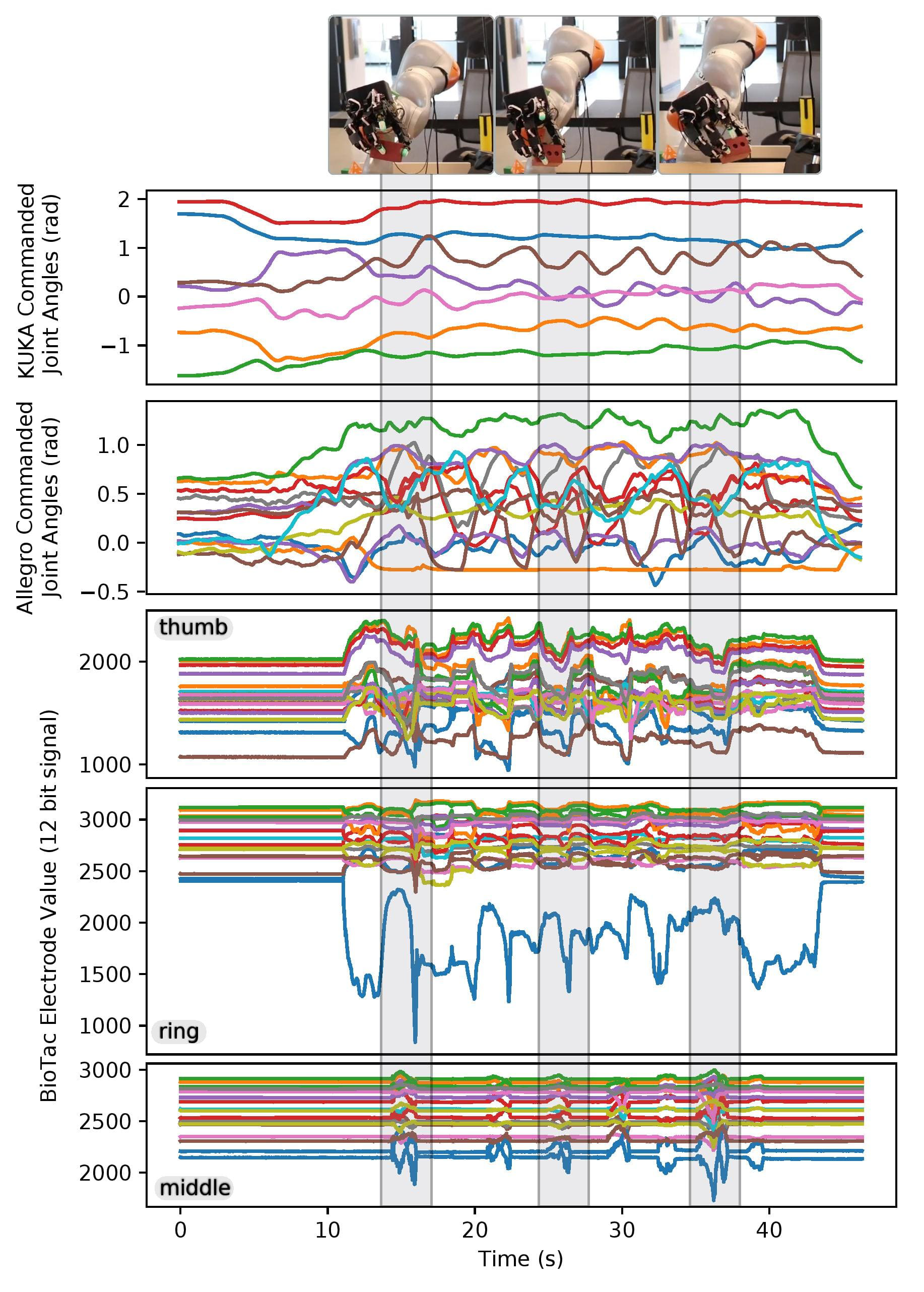 论文强调:每次遥操作都同时记录 92 触觉 + 关节位/速/力矩 + 相机流 → 这就是它要交付的"高维多模态状态-动作数据",供后续学传感运动策略;即使遥操作不完美(手里掉了又捡回)也是有价值的 play data(学失败恢复/长程规划)。
论文强调:每次遥操作都同时记录 92 触觉 + 关节位/速/力矩 + 相机流 → 这就是它要交付的"高维多模态状态-动作数据",供后续学传感运动策略;即使遥操作不完美(手里掉了又捡回)也是有价值的 play data(学失败恢复/长程规划)。
6. 局限(第X节,作者诚实点的)¶
- 无触觉反馈 → 精细任务难(pilot 感知不到接触力)。
- 重定向投影方案的副作用:对精捏极好,但手指步态(finger gaiting)与及时松开小物会被干扰(图18,常掉物);可关掉但治标不治本,根因是追踪分辨不出指尖真实接触。
- 高精装配几乎做不动:NIST 任务板插孔(16×10×49.5 mm 销,0.1 mm 间隙)成功率仅约 10%,且要求零件摆得离用户很近。
- 工作体积小、延迟约 1 s、RMP 响应可再调快;追踪对不同手型/手大小鲁棒性有限(贴近 DART 人手模型才好)。
7. 核心洞见 / 未来¶
- 关键结论:把灵巧遥操作的难点从"完美追踪"转移到"鲁棒的任务空间重定向 + 强力运动生成"——即便追踪有 ~1cm 误差,靠投影/加权也能逼出精密抓取,靠人的视觉认知补上闭环。低成本裸手 = 可规模化采数。
- 未来(作者列):① 提升追踪精度以缩小投影距离、改善细操作;② 在手上加自动力调制控制减负、防掉物;③ 加意图识别让机器人预测人意图、自动补全精细动作(人指挥策略、机器人管细节)。
8. 🗣️ 外部评价¶
经典老论文(2019 投、ICRA 2020),无 OpenReview;这里以被引/后续工作如何用它衡量影响力。
- 🌐 引用量:Semantic Scholar 显示 227 次引用(其中 20 次 highly influential,59 次 methods 类)。(Semantic Scholar 页,2026-06 读数,会随时间增长)
- 🌐 被做成标准库:开源重定向库
dexsuite/dex-retargeting直接内置DexPilotOptimizer——"crafted using insights from DexPilot",成为社区把人手映射到各种机器人手的通用基线之一。(GitHub) - 🌐 奠基"优化式重定向"范式:多篇综述/后续把 DexPilot 与 AnyTeleop 并列为"将重定向表述为带运动学约束的约束优化问题"的代表路线(区别于学习式/接触式重定向)。(Kilohertz-Safe, arXiv 2603.29213;DexFlow, arXiv 2505.01083)
- 🌐 直接前身:AnyTeleop(Qin et al., RSS 2023,同 NVIDIA 系)被普遍视为 DexPilot 的"通用化"后继——把"绑死一套硬件"做成"任意臂+任意手+任意相机"。
- 🧑 常见批评:后续工作指出 DexPilot/AnyTeleop 这类"优先速度、牺牲空间精度",指尖精度在精细装配上不足——这与论文自陈的 NIST 插孔 ~10% 一致。(DexFlow)
9. 🧑⚖️ 审稿人视角(🤖)¶
- 优点:系统完整度高(追踪→重定向→控制→真机闭环全打通,少见);重定向的投影/加权设计简洁且实用,被社区反复复用即是证明;任务覆盖面广、有真机数字。
- 可质疑:① 评估只2 名 pilot、各 5 次,统计力弱,且无与其他遥操作系统的定量对照(只定性比 [19] Shadow 端到端);② 成功率/CT 受 pilot 状态影响大(作者承认疲劳/情绪);③ 工程堆叠重(3 电脑 3 线程、4 相机 2 GPU、DART+多网络),"低成本"是相对动捕而言,复现门槛仍高;④ 控制回路不用触觉,精装配天花板低。
- 若今日投稿:会被要求与 VR/手套类(ALOHA、Open-Television、AnyTeleop)做统一基准对比,并报告跨更多被试的成功率显著性。
10. 对我们(深一层)¶
- 奠基坐标:DexPilot 是"纯视觉低成本采灵巧示范"这条线的源头之一,与 卡片-DexTeleop-0 / 详读-DexTeleop-0 是同战场的两代:DexPilot 解"怎么把裸手映射到差异巨大的机器人手"(运动学层),DexTeleop-0 在 VR 追踪上再加力觉闭环解"接触时力不平衡"(动力学层)——后者正是补 DexPilot "无触觉反馈"这个明写局限。
- 机制可借:4.3 的任务空间向量重定向 + 投影/加权是经久不衰的工件,
dex-retargeting拿来即用;我们若做灵巧数据采集,这是低成本默认方案。 - 与 UMI 对照:卡片-UMI 走"手持夹爪 in-the-wild 采数"绕开遥操作;DexPilot 走"工作室内裸手遥操作高 DoF 手"。一个便携但低自由度、一个高自由度但固定工作室——两条采数护城河路线,长期对照(见 概念-机器人数据与标注 若有)。
- 为下游供数:它产出的多模态状态-动作数据正是 卡片-DexMimicGen 这类"少示范放大"的上游来源。