详读 · GR-2(网络视频预训练的生成式视频-语言-动作模型)¶
卡片版见 卡片-GR-2。本页是全文精读:动机 → 逐模块方法 → 实验全表 → 局限/外部评价/我的判断 → 对我们。 来源:arXiv 2410.06158(v1,2024-10-08)· 项目页 作者:Chi-Lam Cheang、Ya Jing、Tao Kong(通讯)、Hongtao Wu(通讯)、Hanbo Zhang 等(字节跳动 ByteDance Research,作者按字母序)
0. 一句话定位¶
先在 3800 万条互联网视频(约 500 亿 token)上做"给文本+一帧 → 自回归预测后续帧"的视频生成预训练拿到"世界动态"先验;再用机器人轨迹微调成同时输出未来视频 + 动作轨迹的 GPT 式通用操作策略。核心赌注:视频生成能力可当"规划器"——先想象画面,动作只是去"复现"想象出来的轨迹。是 卡片-GR-1 的放大版(预训练视频从 80 万 → 3800 万)。

1. 问题与动机¶
- 目标:像语言/图像/视频基础模型一样,做一个预训练→高效微调的"通用操作智能体"——会多技能、能学新技能、能抗扰动。
- 痛点:机器人真机数据采集慢、难 scale。作者的解法不是堆机器人数据,而是借网络视频:视频里含"环境如何随文本指令演化"的动态信息,能迁移到动作预测(延续 GR-1 的信念)。
- 相比 GR-1 的三处升级(作者自陈):① 预训练数据与任务数大幅扩容(80 万→3800 万视频,100+ 任务,100+ 物体 bin-picking);② 新模型架构让预训练知识"无损"迁到微调;③ 真机部署引入全身控制 WBC(轨迹优化 + 实时运动跟踪)。
2. 方法逐模块¶
2.1 总体形式¶
单一语言条件策略 π:输入语言指令 l、观测历史 o(t-h:t)、机器人状态历史 s(t-h:t),端到端输出动作轨迹 a(t:t+k)。微调阶段同时预测下一帧图像:π(l, o, s) → o(t+1), a(t:t+k)。
2.2 两阶段训练¶
- 阶段一·视频生成预训练:GPT 式 transformer。语言用冻结文本编码器(CLIP[6])token 化;图像用 VQGAN 离散化成 token(VQGAN 在互联网+域内机器人数据上训,全程冻结,利于快训+高质量出图)。目标=自回归预测未来帧 token,再由 VQGAN 解码器还原图像。
- 阶段二·机器人数据微调:机器人数据是多视角(预训练视频只有单视角),GR-2 设计成"优雅吃多视角"。机器人状态=末端位姿(位置+旋转)+二值夹爪态,经线性层编码(微调时可训)。输出=各视角未来帧 + 动作轨迹。
- 动作头:用条件 VAE (cVAE) 生成整段动作轨迹(非单步动作)。作者强调"生成轨迹而非单步"对轨迹平滑 + 实时性都关键。
2.3 数据管线(图2)¶
- 预训练语料:Howto100M(36M)、Ego4D(1.2M)、Something-Something V2(46k)、EPIC-KITCHENS(46k)、Kinetics-700(121k) + 机器人数据 RT-1(82k)、Bridge(25k)。
- 清洗:手部过滤(MediaPipe)+ 重新打字幕(Open-Sora 流程)。合计 3800 万视频片段 ≈ 500 亿 token。
2.4 数据增强(微调期,用于泛化)¶
- 插新物体:训一个扩散模型(自采物体集 + Open Images),把指定物体插入指定区域。
- 换背景:用 SAM 抠背景区域,再用视频生成模型(Latte)以原视频+重绘帧为条件生成增强视频,保留机器人原运动。→ 即 "GR-2 w/ DA"。
2.5 真机系统 & 部署¶
- 硬件:7-DoF Kinova Gen3 机械臂 + Robotiq 2F-85 夹爪;两路相机:头部静态相机(全局)+ 腕部相机(特写交互)。
- GR-2 出笛卡尔空间动作轨迹 → 先做轨迹优化(平滑/连续)→ WBC 全身控制(基于 MOMA-Force[20])转成低层关节指令,200 Hz 执行,框架内含碰撞约束 + 可操作性。
3. 实验全量数字¶
3.1 多任务学习设置¶
- 105 个桌面任务,覆盖 8 类技能:拾取/放置/开盖/盖盖/打开/关闭/按压/倾倒。遥操作采集约 40,000 条轨迹(平均 400 条/任务)。数据稀缺设置用 1/8 数据 ≈ 50 条/任务(合计约 5,000 条)。
- 5 种评测:基础 = Simple、Distractor;泛化 = Unseen Backgrounds、Unseen Environments、Unseen Manipulation。
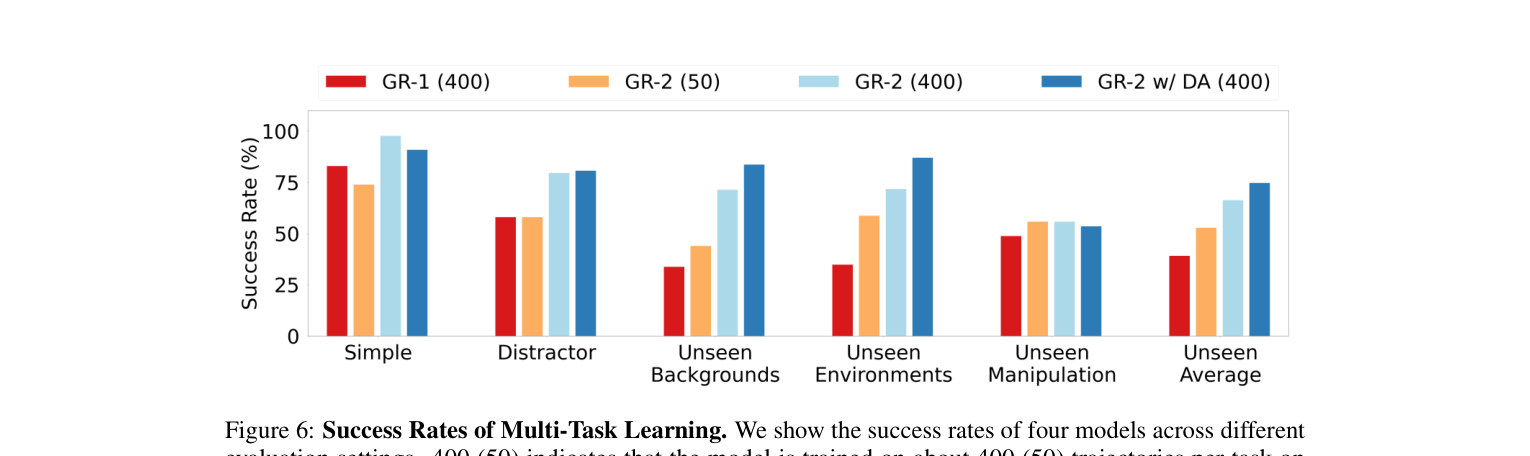
| 设置 | GR-1(400) | GR-2(50) | GR-2(400) | GR-2 w/DA(400) |
|---|---|---|---|---|
| Simple | ~83 | 73.9 | 97.7 | ~91 |
| Distractor | ~58 | ~58 | ~80 | ~81 |
| Unseen Backgrounds | ~34 | ~44 | 71.4 | ~84 |
| Unseen Environments | ~35 | ~59 | 71.7 | 87.0 |
| Unseen Manipulation | ~49 | ~56 | 55.8 | ~54 |
| 泛化三项平均 | ~39 | ~53 | ~67 | 74.7 |
注:带 ~ 者为从图6柱状图读出的近似值;精确数字(97.7 / 73.9 / 71.4 / 71.7 / 55.8 / 87.0 / 74.7)来自正文。GR-2(400) 把 Unseen Backgrounds、Unseen Environments 成功率翻倍于 GR-1。即使只用 50 条/任务,GR-2 在 Simple 仍达 73.9% 且三项泛化全面超 GR-1(400 条)。 典型失败:① 拾取新形状未见物体失败;② 被要求拾取未见物体时选错物体。Unseen Manipulation 仅 55.8%——是公认短板。
3.2 端到端 Bin-Picking(工业场景)¶
- 采集 约 94,000 条 pick-and-place 轨迹、55 种物体;指令极简:"move any object from the right basket to the left basket"。
- 测试 122 个物体(55 见过 + 67 未见过),4 设置:Seen / Unseen / Cluttered Seen / Cluttered Unseen(杂乱设置物体翻倍,12–17 件)。

| 指标 | GR-1 | GR-2 |
|---|---|---|
| 平均成功率(4 设置) | 33.3% | 79.0% |
GR-2 在 Unseen 与两个 Cluttered 设置成功率与 Seen 相当(GR-1 在这些设置直接崩)。能处理透明/可变形/反光等模型法难搞的物体。
3.3 CALVIN 基准(仿真,ABCD→D 长程)¶
- 34 任务,>20,000 专家演示;评 1000 条指令链,每链连做 5 个任务。对比 RT-1 / MT-ACT / HULC / RoboFlamingo / GR-1。
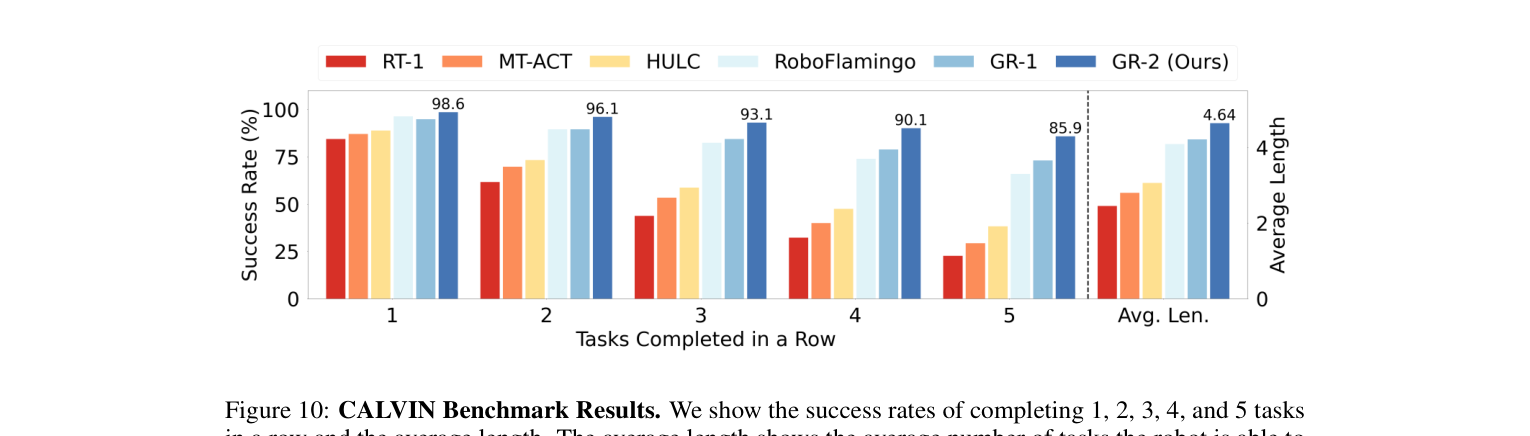
| 指标 | GR-1 | GR-2 |
|---|---|---|
| 完成 1 任务 | 94.9% | 98.6% |
| 完成 5 任务 | 73.1% | 85.9% |
| 平均长度 (Avg. Len, 满分5) | 4.21 | 4.64 |
GR-2 全面超过 5 个基线;2/3/4 连任务约 96.1 / 93.1 / 90.1(读图)。
3.4 自回归视频生成("想象即规划")¶
GR-2 边出动作边出未来视频,且生成视频与真机 rollout 高度吻合——说明预测动作其实在"复现预测视频里的轨迹"。推论:持续改进视频生成 = 持续改进动作预测(一条简单的自提升路径)。
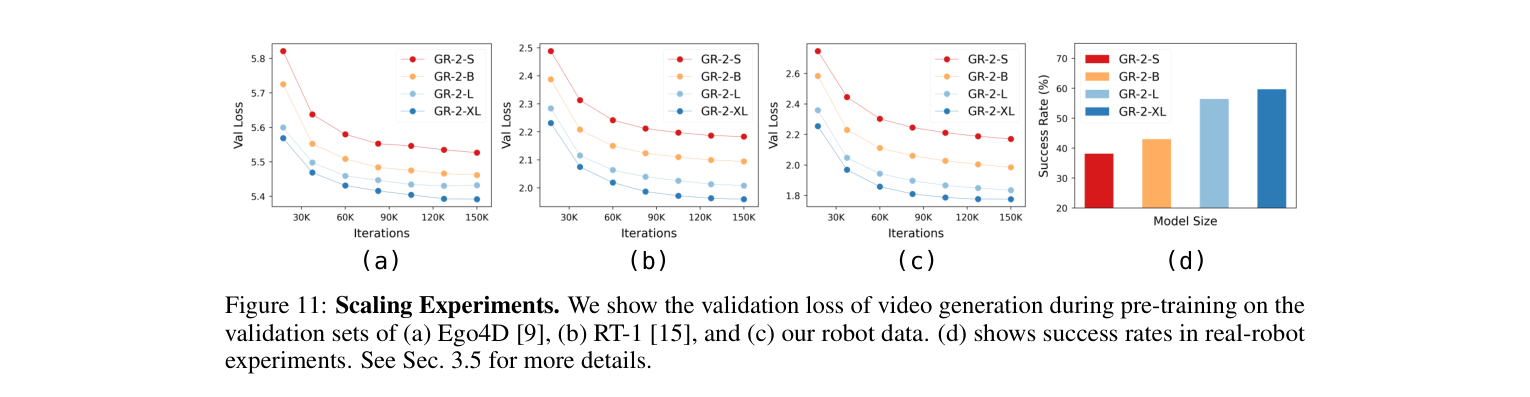
3.5 Scaling(规模律)¶
- 四档:GR-2-S(30M)、GR-2-B(95M,默认)、GR-2-L(312M)、GR-2-XL(719M)(数为可训练参数;默认模型总参 230M、可训 95M)。
- 结论:① 视频预测验证损失随模型增大单调下降(Ego4D / RT-1 / 域内机器人数据三套验证集均如此);② 微调后真机成功率随模型增大上升。→ 主打卖点:"还能继续 scale"。
4. 局限 / 存疑(诚实)¶
- Unseen Manipulation 仅 55.8%:真正的"新技能/新类别物体"泛化仍弱,是全文最低分,作者自己点名为未来方向。
- 数字口径要小心:Intro 的"5,000 条轨迹学 100+ 任务"是数据稀缺(1/8)设置,全量其实是 约 40,000 条;阅读时别把稀缺设置当默认战绩。
- 泛化很大程度靠数据增强堆出来:w/DA 才把 Unseen Environments 从 71.7 抬到 87.0。增强本身依赖额外的扩散/SAM/视频生成模型——系统复杂度高、非纯端到端。
- 未明确开源权重/数据/代码:只有项目页+报告(卡片-GR-2 已标"待核")。3800 万视频预训练 + 工业级算力,外部基本无法复现。
- 是技术报告而非同行评议论文:无消融严谨度的会议审稿背书;很多设计(VQGAN 冻结、cVAE 动作头、"无损迁移"的新架构)细节披露偏少,"无损迁移"无定量证据支撑。
- 真机只是单臂 Kinova + 平行夹爪:技能全是 pick/place 类桌面操作,无灵巧手、无力/触觉——和接触密集任务(对比 详读-DexTeleop-0)是两个世界。
- VQGAN 离散视觉 token:高频细节/小物体易丢,可能正是"未见小物体选错/抓不起"的根因之一。
5. 核心洞见¶
- "视频即策略先验" 的最强规模化证据之一:把动作预测寄生在"预测未来画面"上,让互联网视频的世界知识反哺操作。
- 生成视频 ↔ 动作高度对齐 给出一条诱人的自提升回路:视频生成越准 → 动作越准。这与 卡片-VPP(Video Prediction Policy)同一信仰:先学会"想象",动作自然涌现。
- Scaling 律在操作领域成立(验证损失↓、成功率↑随参数增长),为后续 GR-3 / GR00T 等大模型路线背书。
🗣️ 外部评价(同行评议/社区)¶
- 🌐 无正式同行评议 / OpenReview:GR-2 是 ByteDance 的 arXiv 技术报告,检索未见会议审稿记录或 OpenReview 讨论页(多次 WebSearch 仅返回 arXiv/项目页与二手博客)。→ 故无"独立审稿人挑刺"可引。
- 🌐 社区科普类报道以正面/描述性为主,未见实质批评:
- Research Graph(Medium)综述:复述两阶段范式与 97.7% 等数字,定位为"机器人操作的重要进展",无批评。medium.com/@researchgraph
- aibase 新闻:"字节发布 GR-2,展示智能自主操作新高度"——纯宣传向。aibase.com/news/12233
- aimodels.fyi 论文页:自动摘要,无独立评测。aimodels.fyi
- 🧑 侧面评价(来自后续 ByteDance 工作):GR-3 技术报告把自己定位为 GR-2 的后继(4B 参数,宣称胜过 NVIDIA GR00T、π0),等于官方承认 GR-2 在参数量/灵巧度上的不足并补强。GR-3 arXiv 2507.15493 · GR-RL 进一步攻"高精度/长程"短板 arXiv 2512.01801。
- 诚实说明:未检索到含明确批评的高质量独立第三方评测;上述均为厂商/科普口径。我的批评见下节。
🤔 我的判断(🤖)¶
- 它是"数据+算力胜利",方法新意被高估。"视频预训练→动作"在 GR-1、VPP、UniSim、UniPi 一脉里早有;GR-2 的真贡献是把规模推到 3800 万视频并证明 scaling 成立——这是工程里程碑,不是范式突破。所谓"无损知识迁移的新架构"披露太少,更像营销词。
- 97.7% 要打折看。那是 Simple(同分布) 成绩;真正考验泛化的 Unseen Manipulation 只有 55.8%,且漂亮泛化数字普遍靠数据增强(DA)撑。把 DA 那套(扩散插物体+SAM+视频生成)算进系统成本,"端到端通用策略"的纯度就没那么高。
- 闭源 + 工业算力 = 对外部团队近乎不可复现。对我们这种小团队,GR-2 的直接可借资产≈0,能借的只有"信念与配方":视频生成当规划器、cVAE 出整段轨迹、用生成数据做增强。
- 赌注成立但天花板存疑:VQGAN 离散 token 的视觉损失,对小物体/精细接触可能是硬伤——这也是为什么 GR 系列后来转向更强 backbone(GR-3)。对接触密集/力控任务(我们关心的触觉方向),GR-2 这条"纯视觉想象"路线先天缺一只手和一层皮。
6. 对我们(深一层)¶
- 路线对照:GR-2 = "纯视觉 + 世界想象"的大模型路线,和我们关注的视触觉/力控路线(详读-DexTeleop-0、视触觉世界模型如 OmniVTA/VT-WM)正交。GR-2 证明了"想象画面→动作"在视觉层 scale 得动;触觉层能否同样 scale 是开放问题。
- 直系亲缘:卡片-GR-1(前作,本文的放大版)、卡片-VPP(同信仰:视频预测当策略)。三者可串成"视频生成式策略"小专题。
- 可借配方(非代码):① 动作头用 cVAE 出整段轨迹而非单步(平滑+实时);② 用生成模型做数据增强补泛化;③ "视频生成越准→动作越准"的自提升回路值得在小规模上验证。
- 警示:别被 97.7% 带偏——做评测时务必区分同分布 vs 真泛化,并把数据增强的贡献单列。