详读 · FD-VLA(力蒸馏 VLA:推理时不用力/触觉传感器也有"力感知")¶
卡片版见 卡片-FD-VLA。本页是全文精读:动机 → 方法(逐模块) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2602.02142(v2,2026-03-20,cs.RO) 作者:Ruiteng Zhao、Wenshuo Wang、Yicheng Ma、Xiaocong Li、Francis E.H. Tay、Marcelo H. Ang Jr.、Haiyue Zhu(通讯) 机构:新加坡国立 NUS 高级机器人中心 + A*STAR SIMTech + 南洋理工 NTU + 宁波东方理工/哈佛。受新加坡 NRP 2.0「制造业领域机器人基础模型」资助。
0. 一句话定位¶
在 VLA 里加"力"这一模态,但不接力/触觉传感器:用一个力蒸馏模块 FDM,让一个可学查询 token 仅凭图像 + 机器人本体状态通过注意力"检索"出一个预测力 token;训练时用真实力传感器编码的"真力 token"去监督它,推理时丢掉传感器。声称蒸馏出的力 token 反而比直接喂传感器原始力更好。
1. 问题与动机¶
- 纯视觉 VLA 在真实部署有硬伤:遮挡、光照变化、深度歧义、细微接触效应在图像里都看不清 → 接触密集(contact-rich)任务做不好。
- 力/触觉是补这一短板最直接的模态(给出接触动力学、顺应性、物理交互),但还很欠开发。
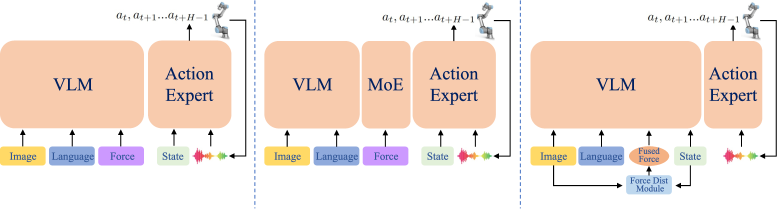
- 前人三条路各有代价(图1):
- Tactile-VLA:把原始力编码成隐向量,经跨模态对齐层直接融进预训练视觉-语言特征 → 风险是扰乱 VLM 已对齐好的图文语义(模态错配 + 灾难性干扰)。
- ForceVLA:把力编成专门 token,放在 VLM 之后用 force-aware MoE 融合(后融合保住了 VLM 语义) → 但 MoE 增加训练不稳定 + 推理复杂度,且后融合限制了细粒度的力-视觉-状态交互。
- FD-VLA(本文):用预测的力而非真实力,在 VLM 之前就做一次力-视觉-状态融合 → 既保 VLM 语义,又拿到细粒度早融合,且部署免传感器。
- 另一动机(图3):真实采到的原始力信号本身就脏——有高频噪声 + 低频漂移,直接喂策略未必最优。蒸馏出的隐 token 相当于一个去噪、任务相关的力代理。
2. 三条设计原则(作者自述)¶
- 只在训练期用真实力信号做蒸馏监督,得到"预测力 token";
- 在 VLM 之前 / 之内 / 之后都尽量做特征级跨模态融合对齐,既保预训练语义先验、又丰富动作表示;
- 部署期 sensor-free 推理,让方法能上各种没有力传感器的机器人。
3. 总体框架(图2)¶
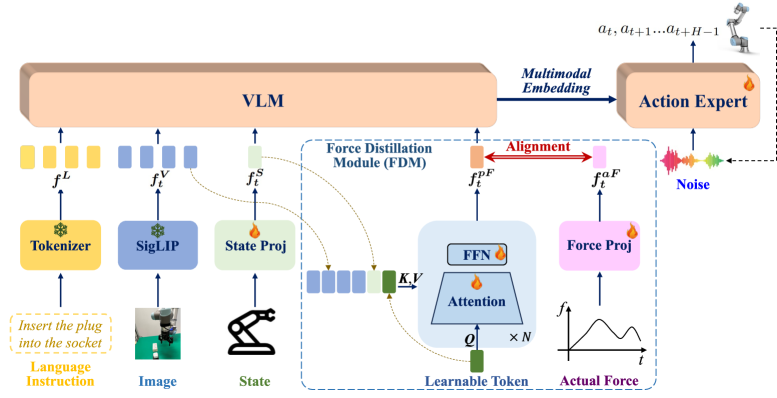
- 多模态输入:语言
L、视觉V_t、机器人状态S_t、力F_t(t=时间戳)。 - 骨干:沿用 SmolVLA,用预训练 SmolVLM-2 + SigLIP 当感知骨干,VLM 内部计算有选择地跳过(省算力)。视觉/语言/状态各经 VLM 分词器+视觉编码器+单层 MLP 投影到隐维
D,得f^V_t∈R^{Nv×D}、f^L∈R^{Nl×D}、f^S_t∈R^{Ns×D}。 - 不直接喂原始力:改由 FDM 从实时视觉+状态预测出隐力表示
f^{pF}_t = FDM(f^V_t, f^S_t, p),p∈R^{1×D}是一个可学习力预测 token。FDM 只在训练期对齐真实力编码f^{aF}∈R^{1×D},推理期完全不需要力测量。 - 四模态沿 token 维拼接
f^{fs}_t = [f^V_t, f^L, f^S_t, f^{pF}_t]送进 VLM。VLM 参数冻结,并用注意力掩码让状态/预测力 token(f^S_t, f^{pF}_t)与核心视觉-语言流解耦,防止干扰预训练语义。 - 动作专家:transformer 策略头 + 条件流匹配(conditional flow-matching)解码器,把融合特征映射成动作块
[a_t,…,a_{t+H-1}] = π_θ(VLM(f^{fs}_t))。
4. 方法详解¶
4.1 力蒸馏模块 FDM(核心)¶
- 核心直觉:力/触觉不是孤立量,而是与本体状态(关节力矩/速度/位置)和视觉(物体形变、空间变化)强相关。既然这些信号大多数机器人上本来就有,就可以从它们反推力 → 省掉物理传感器。附带还提升跨模态融合、过滤原始力的高频噪声。
- 两支并行分支:
- 真力分支(仅训练用):力传感器原始读数经轻量 MLP 编成
f^{aF}_t,投到与预测力同一嵌入空间,作监督信号。 - 预测分支:把"力隐变量生成"建模成以视觉-状态为上下文的检索问题,用单个可学查询
p。上下文矩阵C_t=[p, f^V_t, f^S_t]∈R^{Nc×D},Nc=1+Nv+Ns。单查询多头注意力:Q=pW_Q,K=C_t W_K,V=C_t W_V:
α_t = softmax( (pW_Q)([p,f^V_t,f^S_t]W_K)^T / √d_k )
Z = α_t V ∈ R^{H×d_k}
f^{pF}_t = FFN( LN([Z_1,…,Z_H]W_O + p) )
- 把
p也放进 K/V 里,经残差路径实现"自条件",把学到的接触先验直接注入聚合。 - 蒸馏损失(特征对齐):
L_dist = ‖ f^{pF}_t − f^{aF}_t ‖²₂
4.2 方向性注意力掩码(关键,借鉴 SmolVLA)¶
- 思路:把视觉/语言当冻结感知流,状态/力当控制流,单向放行。
- 两流:
X_percept = {f^V, f^L}(冻结感知),X_control = {f^S, f^{pF}}(控制)。掩码M∈{0,1}^{Nc×Nc}:
M_ij = 1 若 i,j 都是 percept (感知内部互看)
M_ij = 1 若 i 是 control 且 j 是 percept (控制→感知 单向)
M_ij = 1 若 i,j 都是 control 且 i≥j (控制内部因果)
M_ij = 0 其它
即 X'_percept = SelfAttn(X_percept),X'_control = SelfAttn(X_control, X_percept)。
- 效果:感知 token 只能互看 → 保住预训练图文对齐不被污染;控制 token 可看感知 token → 把本体感知+力融进感知上下文供动作预测。这正是它优于 Tactile-VLA"直接早融合污染语义"的关键。
4.3 动作专家(条件流匹配)¶
- transformer,预测动作块
A_t=[a_t,…,a_{t+H-1}],条件于 VLM 特征X_t。 - 流匹配目标:
L_τ(θ)=E[‖v_θ(A^τ_t,X_t) − u(A^τ_t|A_t)‖²],A^τ=τA+(1−τ)ε, ε∼N(0,I),向量场目标u=ε−A_t,τ采自 Beta 分布。学速度场而非逐步残差,契合分块动作预测。
4.4 总损失¶
L = L_τ(θ) + λ·L_dist,λ 控制力监督强度(具体取值正文未给,待核)。
5. 实验¶
5.1 平台与设置(图5)¶

- 硬件:UR5e 单臂;Azure Kinect 主 RGB;RealSense D405 夹爪 RGB;力信号取自 UR5e 内置力/力矩传感器(注意:采数阶段仍需此传感器)。
- 采数:用 3Dconnexion SpaceMouse 遥操作;每任务 50 条专家演示,流程标准化。
- 评测:每任务用 50 条训练、30 次独立测试;成功判据按任务严格定义(白板:所有可见痕迹全部擦净;急停按钮:完全压下且不回弹;插头:完全到位)。
5.2 任务(图4)¶
三个接触密集任务:1) 擦白板(全程持续接触、连续运动规划)、2) 按急停按钮(精确竖直下压、需克服弹簧阻力与位置)、3) 插插头(精确对位 + 接合时的受控施力)。

5.3 主结果(图6,每任务 30 次平均)¶
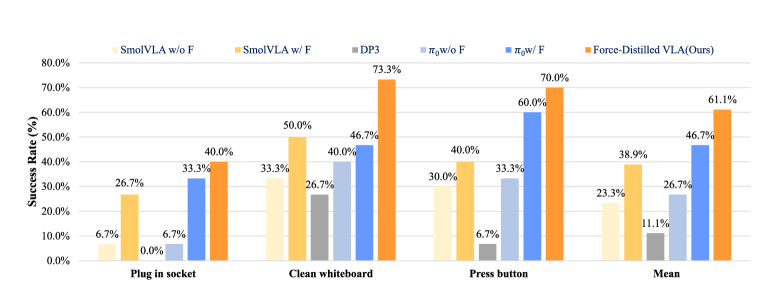
| 方法 | 插插座 | 擦白板 | 按按钮 | 均值 |
|---|---|---|---|---|
| SmolVLA(无力) | 6.7 | 33.3 | 30.0 | 23.3 |
| SmolVLA(+力) | 26.7 | 50.0 | 40.0 | 38.9 |
| DP3 | 0.0 | 26.7 | 6.7 | 11.1 |
| π0(无力) | 6.7 | 40.0 | 33.3 | 26.7 |
| π0(+力) | 33.3 | 46.7 | 60.0 | 46.7 |
| FD-VLA(本文) | 40.0 | 73.3 | 70.0 | 61.1 |
(单位 %,读自图6柱状图,与正文算术一致。基线:DP3=参数量与本文相当的强扩散控制基线;π0=约 10× 参数的 SOTA 大 VLA;SmolVLA=本文骨干。所有方法统一训练数据/评测/优化预算。)
- 擦白板 73.3%,比任何基线至少高 23.3%(次高 SmolVLA+力 50%)。
- 均值 61.1%:碾压 SmolVLA 无力(23.3)、DP3(11.1),也高于 约 10 倍参数的 π0 无力(26.7)。
- "原始力不够"的论证:给 SmolVLA 喂原始力涨 15.6%(23.3→38.9),但仍比本文低 22.2%;给 π0 喂原始力涨 20.0%(26.7→46.7),本文仍高 14.4%。→ 直接喂高维噪声力不如蒸馏出的紧凑力表示。
⚠️ 正文一处疑似笔误(待核):正文写 "even π0 without force encoding (46.7%)",但图6 与上下文算术(π0 无力 26.7→+20.0%=46.7 为有力)一致表明 46.7% 是 π0 有力、26.7% 才是 π0 无力。表中按图6/算术取值。
5.4 消融:FDM 的两个开关(表I,每格 成功次数/30)¶
| 变体 | 插插座 | 擦白板 | 按按钮 | 均值 |
|---|---|---|---|---|
| 去掉 FDM(直接 MLP 编码力) | 8/30 | 15/30 | 12/30 | 38.9 |
| FDM + "真力 token"(用 MLP 编真力替换可学 token) | 12/30 | 17/30 | 17/30 | 51.1 |
| FDM + 可学 token(本文) | 12/30 | 22/30 | 21/30 | 61.1 |
(均值单位 %;算术核对:35/90=38.9、46/90=51.1、55/90=61.1,全部吻合。)
- 加 FDM 就大涨(38.9→51.1):说明早期深度跨模态交互是主要增益来源。
- 可学 token > 真力 token(61.1 vs 51.1):把可学查询换成"真力编码的隐特征"反而掉点 → 印证"原始力高维且噪声、难被策略有效整合";可学 token 既躲开直喂原始力的坑、又借真力监督保住真实接触信息。
- 诚实读数:在最难的插插座上,"真力 token"与"可学 token"都是 12/30,可学 token 的增益全部来自擦白板(17→22)和按按钮(17→21),对插插座无额外帮助。
5.5 泛化(图7,仅定性)¶
两种视觉分布偏移:新背景(布局/纹理与训练不同)、视觉扰动(光照/对比度/彩色灯变化)。作者称两种场景下方法都鲁棒(新背景靠结构线索而非纹理过拟合、光照扰动下平滑适应)。注意:只有定性描述,无成功率数字。
6. 核心洞见¶
- 把"力"当成可预测的 token:利用本体状态/视觉形变与接触力的强相关,从"机器人本来就有的模态"里蒸馏出力,而不是去测它。
- 早融合(VLM 前) + 方向性掩码:既拿到细粒度力-视觉-状态交互,又不污染冻结 VLM 的图文语义——这是对 Tactile-VLA(污染风险)和 ForceVLA(后融合限制交互)的折中。
- 蒸馏≈去噪正则:学到的隐力是"去噪、任务相关的力代理",所以"预测力 > 原始真力"在小样本评测上成立。
7. 局限 / 存疑(诚实)¶
- 规模很小:单臂 UR5e、仅 3 个任务、每任务 50 条演示 / 30 次测试。"预测力胜过真实传感器"这种反直觉结论建立在 30 次 rollout 上,统计噪声不可忽略(可学 vs 真力 token 仅差 9 个 episode:55/90 vs 46/90)。
- "免传感器"只在推理期:训练/采数仍必须有力传感器打监督标签。所以它降的是部署硬件成本,没降数据采集成本——力标注的数据护城河依旧存在。
- 最难任务收益有限:插插座本文也只 40%,且可学 token 在该任务相对真力 token 无增益。
- 泛化无定量:图7 只有定性叙述。
- 复现性待定:文中无项目页 / 代码链接(待核);
λ、H、token 数等超参未在正文给全。 - 力来自 UR5e 内置 F/T(关节力矩估计),非指尖触觉 → 是"腕/关节级力",不是分布式触觉;对精细多指接触的适用性未验证。
8. 对我们(深一层)¶
- 直接撞"免触觉硬件部署"这条线(对照内部 idea3):FD-VLA 比 卡片-Tactile-VLA / ForceVLA / 卡片-VLA-Touch 更激进——推理期连力传感器都不要,纯视觉+状态预测力。和 HapticVLA 一起佐证"免触觉硬件部署"已是明确方向。
- 与 详读-DexTeleop-0 互为对照:DexTeleop-0 在采数端加指尖力传感把数据采精;FD-VLA 在部署端省力传感器。但二者都依赖采数阶段的力标注 → 共同指向 概念-机器人数据与标注 里的"力/触觉标注数据稀缺"才是真瓶颈。
- 机制可借:① "可学查询 token + 单查询注意力"从已有模态检索缺失模态,是通用的跨模态蒸馏套路,可迁去预测我们关心的触觉隐变量;② 方向性注意力掩码(冻结感知流 / 可写控制流)是给冻结 VLM 安全加模态的干净做法,见 概念-模型架构基础。
- 互为对照的实证点:它给出"原始力直喂不如蒸馏力"的小样本证据,呼应 卡片-AdapTac-PredictiveForceAttention(预测式力注意力)——都在说"力信号要先被模型加工成紧凑表示,而非裸喂"。
- 判断:思路新、骨干轻(SmolVLA)、工程干净;但证据等级偏弱(单臂/3 任务/30 trial、无代码)。结论"预测力>真实力"宜当有趣假设而非定论,可借机制、谨慎引用其数字。