详读 · AnyTouch(跨多视触觉传感器的统一"静态+动态"表征)¶
卡片版见 卡片-AnyTouch。本页是全文精读:动机 → TacQuad 数据集 → 方法(逐模块) → 实验(全表) → 消融/局限 → 对我们。 来源:arXiv 2502.12191(v3, 2025-04-01;ICLR 2025 会议论文)· 项目/代码/数据 作者:Ruoxuan Feng、Jiangyu Hu、Wenke Xia、Tianci Gao、Ao Shen、Yuhao Sun、Bin Fang(通讯)、Di Hu(通讯)。单位:中国人民大学 GeWu 实验室 + 武汉科技大学 + 北京邮电大学。
0. 一句话定位¶
视触觉传感器五花八门、彼此数据有 gap,单传感器各练各的 → 数据少、迁移差。AnyTouch 的解法是两件事叠在一起:① 采一个对齐的多传感器多模态数据集 TacQuad(同一物体同一位置,4 种传感器都摸一遍,再配视觉图 + 文本)当"桥";② 在其上做一个多层级表征学习框架,把静态(图像)与动态(视频)统一成 4D 张量输入,用"掩码建模(像素级) → 多模态对齐 + 跨传感器匹配(语义级)"两阶段提特征,并用 universal sensor token 泛化到没见过的传感器。目标是一套"传感器无关"的通用触觉表征。
1. 问题与动机¶
- 视触觉传感器标准化程度低:同样的接触,不同传感器读出来的图差别很大(硬件差异)。导致大家只能单传感器采数 + 单传感器训练 → 数据规模/多样性受限 → 感知能力次优、换传感器不通用。
- 前人尝试多传感器联合训练 / 多模态对齐 / 跨传感器生成,但缺"对齐的多传感器数据",没法把异构传感器真正整合进一个统一空间。
- 最接近的工作 Rodriguez et al. (2024):采了双传感器配对数据(32,256 对触觉图)做跨传感器生成,但只 2 种传感器、物体少、面向特定操作任务,且没利用多模态数据提升迁移性。
- AnyTouch 的切入:(a) 把对齐数据扩到 4 种传感器 + 配 视觉 + 文本 三模态;(b) 提出"静态 + 动态"双视角统一表征(人摸东西本就是"快摸辨材质"+"持续摸感知滑动/压力变化"两种过程的结合)。
2. TacQuad 数据集(图1,核心贡献之一)¶
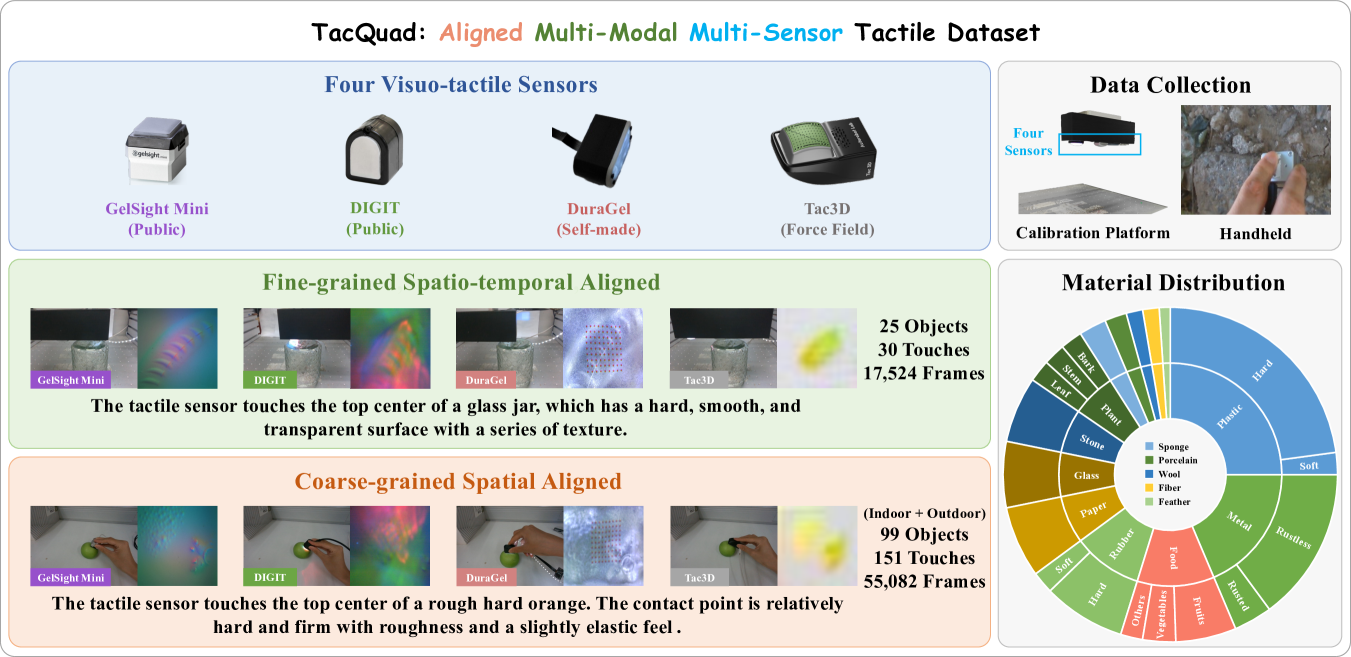
- 4 种传感器(刻意求多样):GelSight Mini(公开)、DIGIT(公开)、DuraGel(自制)、Tac3D(力场式,输出形变力场而非图像)。
- 总量 72,606 接触帧,分两档(在"采集成本 vs 配对精度"间折中):
- 细粒度·时空对齐:4 个传感器并排固定在容器里、装到标定平台可动端,程序控制按同位置同速度同深度依次按压 → 时空都对齐。精度要求高、慢,只采了 30 组 / 25 物 / 17,524 帧(可用于跨传感器生成等精细任务)。
- 粗粒度·空间对齐:手持依次按同一物同一位置,按压时加入扭转模拟真实动态触摸。快、量大:151 组 / 99 物 / 55,082 帧(含室内外场景)。
- 多模态标注:每帧配一张视觉图 + 一段触觉属性文本(GPT-4o 生成 + 人工校正)。文本作为"跨数据集一致的锚"来弥合传感器差异。
注:除 TacQuad 自带文本外,作者还用 GPT-4o 给训练用的几个大数据集补/扩文本,总共为 140 万 (1.4M) 样本 造了新文本对(解决三模态数据稀缺、多数集只有"视-触"对的问题)。
3. 方法详解(图2)¶
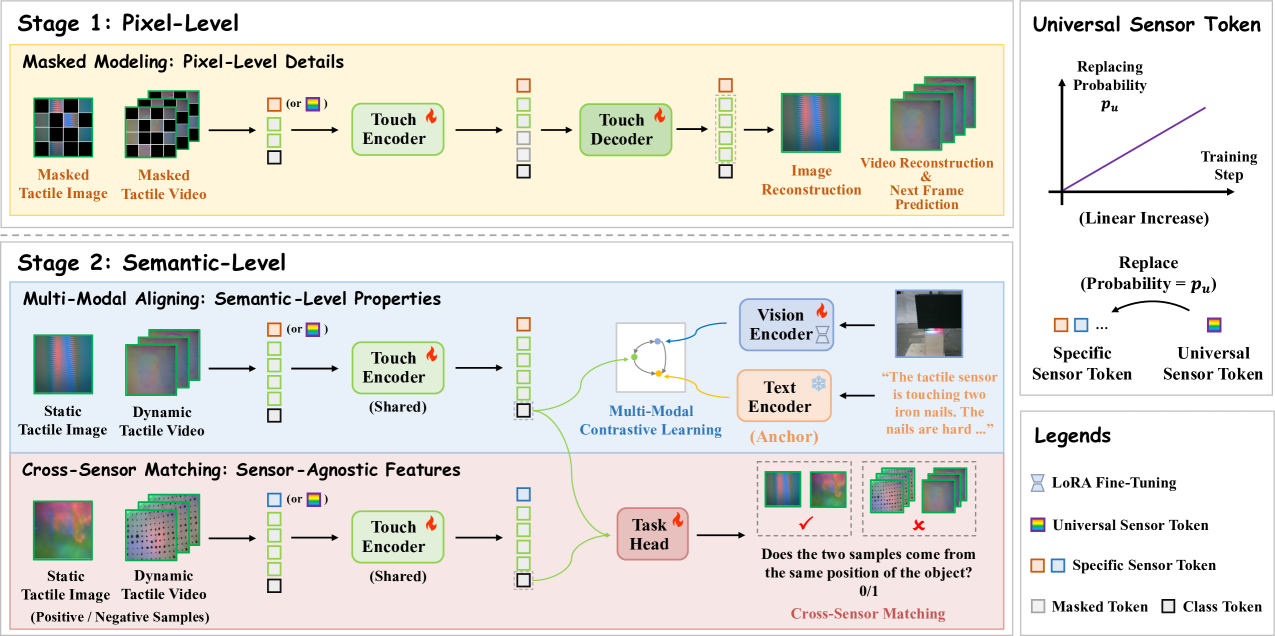
3.1 统一输入:把图像当"单帧视频"(4.1)¶
静态触觉图 I∈R^{1×H×W×3}、动态视频 V∈R^{F×H×W×3}。把图像沿时间轴复制 F 次,统一成 4D 张量 X_T∈R^{F×H×W×3}(借鉴 Omnivore/ImageBind 思路),再经共享 patch projection 变成时空 token。→ 同一套编码器同时吃图与视频,既学静态属性又学动态变化。
3.2 阶段1 · 掩码建模:学像素级细节(4.2)¶
- 用 MAE/VideoMAE 思路:按掩码率
ρ随机遮 token,解码器重建静态图Î、动态视频V̂,损失是像素空间 MSE(L^S_rec、L^D_rec)。 - 额外加一个下一帧预测
L^D_pred:重建视频的同时预测第 F+1 帧 → 强化对"连续形变变化"的理解。 - 这一层学到的是像素级、传感器相关的细粒度特征(后面 t-SNE 会看到它反而让样本"按传感器聚类",所以还不够)。
3.3 阶段2a · 多模态对齐:学语义级属性(4.3,图3)¶
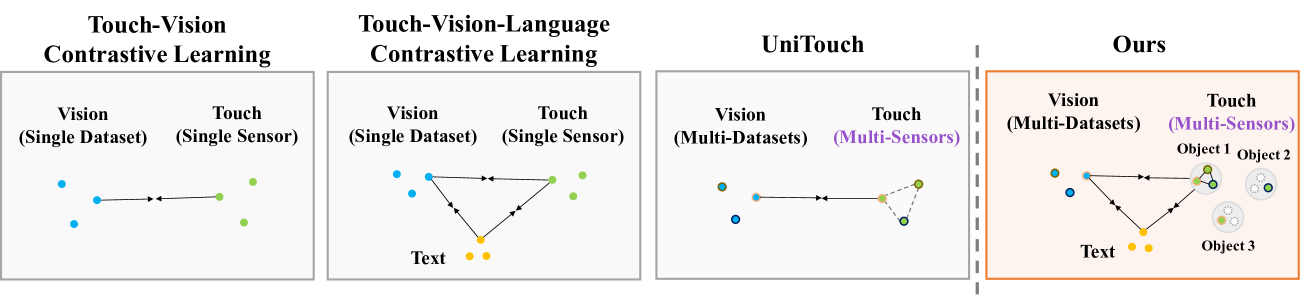
- 直接做"视-触"对齐在跨数据集(仿真 vs 真实)时不灵 → 选文本模态当锚(文本对触觉属性的描述跨数据集一致),对齐 触/视/文 三模态。
- 缺模态感知的对比学习:很多数据只有"视-触"对、没文本。做法是在 batch 内为每种模态组合取最大可用子集做对齐(公式3给的是"视→文",含缺失模态时只在交集
Ω_V∩Ω_L上算),方向对称地有 T→V/T→L/V→L 等六项,加权合成L_align(权重α_TV, α_TL, α_VL)。
3.4 阶段2b · 跨传感器匹配:抽传感器无关特征(4.4)¶
- 新任务:判断两张触觉图/视频是不是来自同物体同位置。正样本=同物同位另一传感器采的;负样本=任意其他物/位。
- 把 anchor 表征
x_T与正/负样本表征逐元素相乘后过 MLP 得匹配分m+/m−,用 BCE 损失L_match(公式6)。 - 作用:显式把"同一触觉信息、不同传感器"的表征聚到一起 → 形成统一多传感器空间、抽出传感器无关特征 → 利于泛化到未见传感器。
3.5 Universal Sensor Token(4.5,泛化关键)¶
- 已有做法用 sensor-specific token(每种传感器一组)存传感器信息,但换新传感器时没法把所有已见传感器的知识都迁过去。
- AnyTouch:除每传感器各
L个 specific token 外,再设一组通用 tokens_u。训练时以概率p_u把 specific token 随机替换成 universal token(公式7,i∼Bernoulli(p_u));推理时对新传感器一律用 universal token。→ 通用 token 吸收了所有已见传感器的共性知识。
3.6 两阶段训练 + 实现细节(4.6 / A.6)¶
- 阶段1
L_stage1 = L^S_rec + L^D_rec + L^D_pred(像素级);阶段2L_stage2 = L_align + λ·L_match(语义级)。顺序训练。 - 编码器基于 OpenCLIP-Large;触觉解码器 = ViT 8 层 / 维度 512。AdamW,lr=2e-4,1 epoch warm-up 后线性衰减。视频片段 T=3 帧。阶段1 训 20 epoch、阶段2 训 12 epoch,4×NVIDIA A800。掩码率 ρ=0.75。对齐时冻结文本编码器、对视觉编码器做 LoRA 微调。
α_TV=α_TL=1.0, α_VL=0.2,λ=0.1,每传感器 L=5 个 token,p_u在两阶段都从 0 线性增到 0.75。
4. 实验¶
4.1 设置¶
- 训练用 9 个数据集:Touch&Go(TAG)、VisGel、Cloth、ObjectFolder Real、TVL、YCB-Slide、SSVTP、Octopi + TacQuad 粗粒度子集。
- 下游 4 个数据集:TAG、Feel(GelSight 抓取成功预测)、ObjectFolder 1.0(TACTO 仿真,未见传感器)、ObjectFolder 2.0(Taxim 仿真,未见传感器)。
- 基线:单传感器 ViT-Lens-2 / TLV-Link / OmniBind;多传感器 UniTouch(之前的跨传感器 SOTA)。用全量数据重训的记为 UniTouch† / TLV-Link†。真机动态任务对比 T3(用了约 3M 数据,比 AnyTouch 多)。
- 三问:Q1 各传感器数据整合的增益?Q2 统一空间长什么样?Q3 静/动态感知更强吗?
4.2 Q1 传感器可迁移性(表1)¶
逐步把 GelSight→GelSlim→DIGIT→GelSight Mini 的数据加入训练,看 4 个下游任务(数字=准确率%):
| 训练数据 | 数据量 | TAG(材质,见) | Feel(抓取,见传感器未见集) | OF1.0(未见) | OF2.0(未见) |
|---|---|---|---|---|---|
| 无触觉预训练(CLIP) | / | 52.96 | 72.37 | 41.00 | 73.16 |
| +GelSight(TAG,VisGel,Cloth) | 996k | 83.55 (↑30.59) | 79.12 (↑6.75) | 46.12 (↑5.12) | 75.10 (↑1.94) |
| +OF Real | 2161k | 79.67 (↓3.88) | 79.28 (↑0.16) | 47.55 (↑1.43) | 75.53 (↑0.43) |
| +TVL,SSVTP,YCB-Slide | 2388k | 79.61 (↓0.06) | 79.10 (↓0.18) | 48.00 (↑0.45) | 75.57 (↑0.04) |
| +Octopi(全量) | 2427k | 79.70 (↑0.09) | 79.40 (↑0.30) | 48.75 (↑0.75) | 75.66 (↑0.09) |
- 触觉预训练本身极其关键:仅加 GelSight 数据,TAG 材质就从 52.96 飙到 83.55。
- 继续加更多传感器数据,未见传感器/未见集上稳步涨(迁移性确实存在),且未见传感器涨得比已见多。
- 两个诚实现象:(1) TAG 上加更多数据反而掉(79 几)——因为 TAG 本身在预训练里,加别的数据稀释了 TAG 占比(与 CLIP 论文"下游与预训练重叠越多越好"一致);(2) DIGIT 数据量更大但增益不如 GelSight Mini——推测 DIGIT 的图像与 GelSight 系差异更大(硬件差异)。
4.3 Q2 统一表征空间(图4,t-SNE)¶
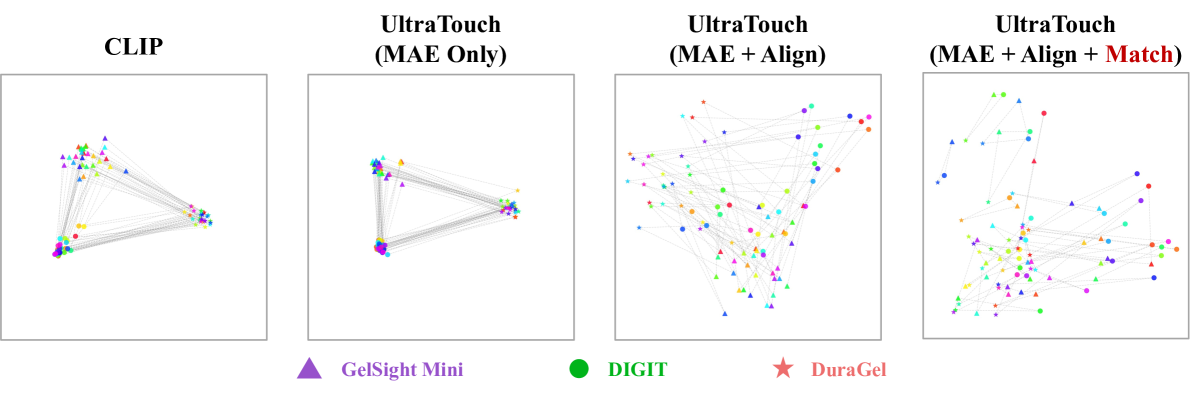
在 TacQuad 未用过的细粒度子集上做 t-SNE(每种颜色=一次触摸,虚线连同位置三传感器样本): - CLIP:没见过触觉图 → 按传感器聚类(最差)。 - +掩码建模:每个传感器内更集中,但仍按传感器分(像素级特征是传感器相关的)。 - +多模态对齐:开始按物体混合聚类,但还残留传感器倾向。 - +跨传感器匹配:不同传感器充分混合、清晰按物体触觉信息聚类 → 证明抽到了传感器无关特征、具备向未见传感器泛化的能力。
4.4 Q3-静态·已见传感器 GelSight(表2,准确率%)¶
| 方法 | 训练数据 | TAG材质 | TAG粗糙度 | TAG硬度 | Feel抓取 |
|---|---|---|---|---|---|
| CLIP | / | 52.96 | 84.09 | 88.34 | 72.37 |
| ViT-Lens-2 | TAG | 63.0 | 85.1 | 92.0 | - |
| TLV-Link | Touch100k | 67.2 | 84.7 | 91.3 | 94.5‡ |
| OmniBind | TAG | 67.45 | - | - | - |
| UniTouch | TAG,Feel*,YCB,OF2.0 | 61.3 | - | - | 82.3 |
| TLV-Link† | TAG,TVL,SSVTP,OFReal,TacQuad | 74.12 | 85.94 | 94.18 | 76.97 |
| AnyTouch(同UniTouch数据) | TAG,Feel*,YCB,OF2.0 | 82.74 | 86.01 | 94.24 | 87.17 |
| AnyTouch(全量) | 9数据集 | 80.82 | 86.74 | 94.68 | 80.53 |
- 同等数据下 AnyTouch 四项全面超 UniTouch(材质 82.74 vs 61.3,抓取 87.17 vs 82.3)。
- 全量数据版在硬度/粗糙度最佳;Feel 上与 UniTouch 相当(即便 UniTouch 把 Feel 当已见数据)。
- ‡ 原版 TLV-Link 用"抓取后"帧(Feel 上更易),别的模型用"抓取中"帧;AnyTouch 若也用抓取后帧可达 99.0。
- 一个反复出现的现象:少数据版 TAG 材质反而更高(同表1道理),但更多多传感器数据提升硬度/粗糙度——因为后两者是二分类、更简单。
4.5 Q3-静态·未见传感器 OF1.0/OF2.0(表3,linear probing,材质准确率%)¶
| 方法 | 训练数据 | OF1.0 | OF2.0 |
|---|---|---|---|
| CLIP | / | 41.00 | 73.16 |
| UniTouch | TAG,Feel,YCB-Slide,OF2.0* | 41.3 | 85.4 |
| UniTouch† | TAG,VisGel,TVL,SSVTP,OFReal,TacQuad | 47.25 | 75.29 |
| AnyTouch(同UniTouch数据) | TAG,Feel,YCB-Slide,OF2.0* | 46.50 | 85.87 |
| AnyTouch(全量) | 9数据集 | 49.62 | 76.02 |
- 同数据下 AnyTouch 两集都超 UniTouch;全量版在未见 OF1.0 最高(49.62)→ 学语义级传感器无关特征确实利于跨传感器迁移。
- (注:OF2.0 上 UniTouch 把它当已见数据,所以 85+ 偏高;全量 AnyTouch 76.02 是真·未见设置。)
4.6 Q3-真机动态·细粒度倒水(表4,图5)¶
任务:UFACTORY xArm 6 + Robotiq 2F-140 夹爪,仅靠触觉反馈,从初装 100g 珠子的杯里倒出 60g,5Hz 决策、每步在 倒/等/收 三动作里选。指标=倒出质量与目标的平均误差(g,越小越好),10 次平均。
| 方法 | 含动态感知模块 | 微调编码器(g)↓ | 冻结编码器(g)↓ |
|---|---|---|---|
| CLIP | ✘ | 5.22 | 49.1 |
| T3 (训练数据~3M) | ✘ | 2.33 | 9.74 |
| AnyTouch(仅静态) | ✘ | 2.45 | 9.60 |
| AnyTouch(含动态) | ✔ | 1.56 | 8.22 |
- 冻结时 CLIP 几乎做不了(49.1g,说明细粒度动态感知很难)。
- 仅静态版 AnyTouch 已与用更多数据的 T3 相当;加动态感知后误差降到 1.56g,最佳。→ 印证"静态+动态双视角"对真机任务的价值。
4.7 消融(附录表6,静态准确率%)¶
全量 AnyTouch 基线:TAG 80.82 / Feel 80.53 / OF1.0 49.62 / OF2.0 76.02。各去一项后的下降(节选):
| 去掉 | TAG | Feel | OF1.0 | OF2.0 |
|---|---|---|---|---|
| w/o 文本模态 | 75.91(↓4.91) | 78.93(↓1.60) | 48.87(↓0.75) | 75.52(↓0.50) |
| w/o 视觉模态 | 74.55(↓6.27) | 77.30(↓3.23) | 48.12(↓1.50) | 75.22(↓0.80) |
| w/o TacQuad里的文本 | 80.70(↓0.12) | 80.19(↓0.34) | 49.21(↓0.41) | 75.91(↓0.11) |
| w/o 阶段1(像素级) | 78.34(↓2.48) | 78.62(↓1.91) | 48.75(↓0.87) | 76.08(↑0.06) |
| w/o 阶段2(语义级) | 68.64(↓12.18) | 72.39(↓8.14) | 46.50(↓3.12) | 73.09(↓2.93) |
| w/o 跨传感器匹配 | 80.54(↓0.28) | 79.43(↓1.10) | 49.25(↓0.37) | 75.80(↓0.22) |
| w/o 动态感知 | 77.93(↓2.89) | 79.28(↓1.25) | 48.62(↓1.00) | 75.70(↓0.32) |
| w/o universal sensor token | 80.79(↓0.03) | 79.03(↓1.53) | 48.40(↓1.22) | 75.40(↓0.62) |
- 语义级阶段2最关键(去掉狂掉,OF2.0 甚至跌破 CLIP)→ 语义特征对综合感知与跨传感器泛化是核心。
- 跨传感器匹配 / universal token 的增益主要体现在"未见传感器"集(这些传感器还没进正样本对,潜力更大)。
- 去掉动态感知联合训练,静态也一致变差 → 动态训练反过来增强了静态感知。
4.8 跨传感器生成(附录表7,MSE↓)¶
验证表征质量:用 GelSight Mini 生成 DuraGel 图、用 DIGIT/GelSight Mini 重建 Tac3D 力场(Tac3D 对两模型都是未见传感器)。
| 模型 | 训练数据 | GelSightMini→DuraGel | GelSightMini→Tac3D | DIGIT→Tac3D |
|---|---|---|---|---|
| T3 | 3.08M | 0.2261 | 0.0167 | 0.0155 |
| AnyTouch | 2.48M | 0.2159 | 0.0151 | 0.0144 |
- 用更少数据三项全胜 T3,包括对未见 Tac3D 力场的生成 → 印证统一表征 + 对齐数据集的价值。
5. 核心洞见¶
- "对齐数据 + 多层级表征"双管齐下才是关键:光靠像素级(MAE)会按传感器聚类(不通用);必须叠加语义级对齐 + 跨传感器匹配才能把不同传感器揉进同一空间、按物体聚类。
- 文本当锚比"视-触直接对齐"更鲁棒(跨仿真/真实场景一致),是弥合传感器 gap 的便宜杠杆。
- 静态/动态统一不是噱头:动态联合训练连静态任务都涨;真机倒水靠它拿到最佳。
- universal sensor token 给"换硬件即用"提供了一条具体路径(推理时对新传感器统一用通用 token)。
6. 局限 / 存疑(作者附录 A.13 明确写了,诚实)¶
- TacQuad 规模相对训练总量仍小(7万帧级 vs 训练总量 2M+),物体多样性有限。作者计划扩团队、复制标定平台扩量。
- 传感器种类少(仅 4 种,全是视触觉/力场式);未研究同型号个体差异、gel 损坏等问题。
- 动态任务覆盖窄:真机只验了"倒水"一个任务。
- 帧数取舍:只用 T=3 帧(约 0.1s @30Hz)——为实时性牺牲长时序理解;更多帧可能更准但算力/延迟成本高(A.11 讨论)。
- 关于非视触觉传感器(温度/力矩等)只给了讨论性设想(A.12),未实做。
7. 对我们(深一层)¶
- 触觉统一表征的第二候选:与 卡片-T3 对照——T3 处理不对齐异构数据靠共享 trunk + 3M 量;AnyTouch 主动采对齐数据 + 文本锚 + 跨传感器匹配,用更少数据(2.48M)在生成/感知上反超 T3。结论沿用卡片判断:有对齐多传感器数据时优先 AnyTouch(还自带文本对齐、便于接语言/VLA);没有则用 T3。
- 与 卡片-TVL 同源谱系:TVL(Touch-Vision-Language)是本文训练集之一、也是"触觉接语言"路线的前作;AnyTouch 把它从"单传感器三模态"推广到"多传感器统一空间"。
- 数据是护城河:TacQuad 的"标定平台精对齐 + 手持快粗对齐"双档采集法,正对应 概念-机器人数据与标注 里"成本 vs 精度"的核心权衡——粗对齐可手工扩量、是规模化的现实路径。
- 机制可借:① 文本当锚做跨域对齐(比直接配对鲁棒);② 缺模态感知对比学习(batch 内按可用模态取子集,解决三模态数据稀缺);③ universal sensor token 应对团队换硬件场景。
- 与动态预测路线互补:本文学"表征"(含下一帧预测做辅助),与 卡片-TacForeSight 的"动态触觉预测"可对照(一个学统一表征、一个学动态预测)。
- 后续:已有 AnyTouch 2(arXiv 2602.09617, 2026)可一并跟。