详读 · 3D Diffusion Policy(DP3:用简洁 3D 点云表征喂扩散策略)¶
卡片版见 卡片-3D-DiffusionPolicy。本页是全文精读:动机 → 方法(逐模块) → 实验(全表数字) → 局限/洞见 → 对我们。 来源:arXiv 2403.03954(v7, 2024-09-27)· 项目页 · 代码 · RSS 2024 作者:Yanjie Ze、Gu Zhang(共同一作)、Kangning Zhang、Chenyuan Hu、Muhan Wang、Huazhe Xu(通讯)。机构:上海期智研究院 / 上海交大 / 清华 IIIS / 上海 AI Lab。

0. 一句话定位¶
把 Diffusion Policy 的视觉条件从 2D 图像换成"单视角稀疏点云 + 一个极轻 MLP 编码器",得到一个 64 维紧凑 3D 表征去条件化扩散策略。结论:用更少示范(仿真常 10 条、真机 40 条)拿到更高成功率、更快收敛、更强泛化(空间/视角/外观/实例),且真机几乎不出"危险乱指令"。 卖点不是新模型,而是"3D 表征对真机模仿学习至关重要"这件事被一个简单设计干净地证明。
1. 问题与动机¶
- 模仿学习采数贵:SOTA 的 Diffusion Policy 每个真机任务需 100–200 条人采示范,长程+易失败,采一套要好几天。
- 在线学习不解渴:要考虑安全、自动复位、人为干预、额外硬件成本。→ 核心问题:离线模仿学习如何用尽量少的示范学到鲁棒、可泛化的技能。
- 既有 3D 策略两大毛病(PerAct/GNFactor/RVT/ACT3D/3D Diffuser Actor 等):
- 设定不实用:把模仿学习改成"关键帧位姿预测+规划"范式,不适合高维稠密控制(如灵巧手)。
- 推理慢:架构复杂。PerAct 仅 2.23 FPS、3D Diffuser Actor 1.67 FPS。
- DP3 的切入:做一个通用且快、既能高维(22-DoF 灵巧手)又能低维控制的 3D 策略。
2. 方法详解¶
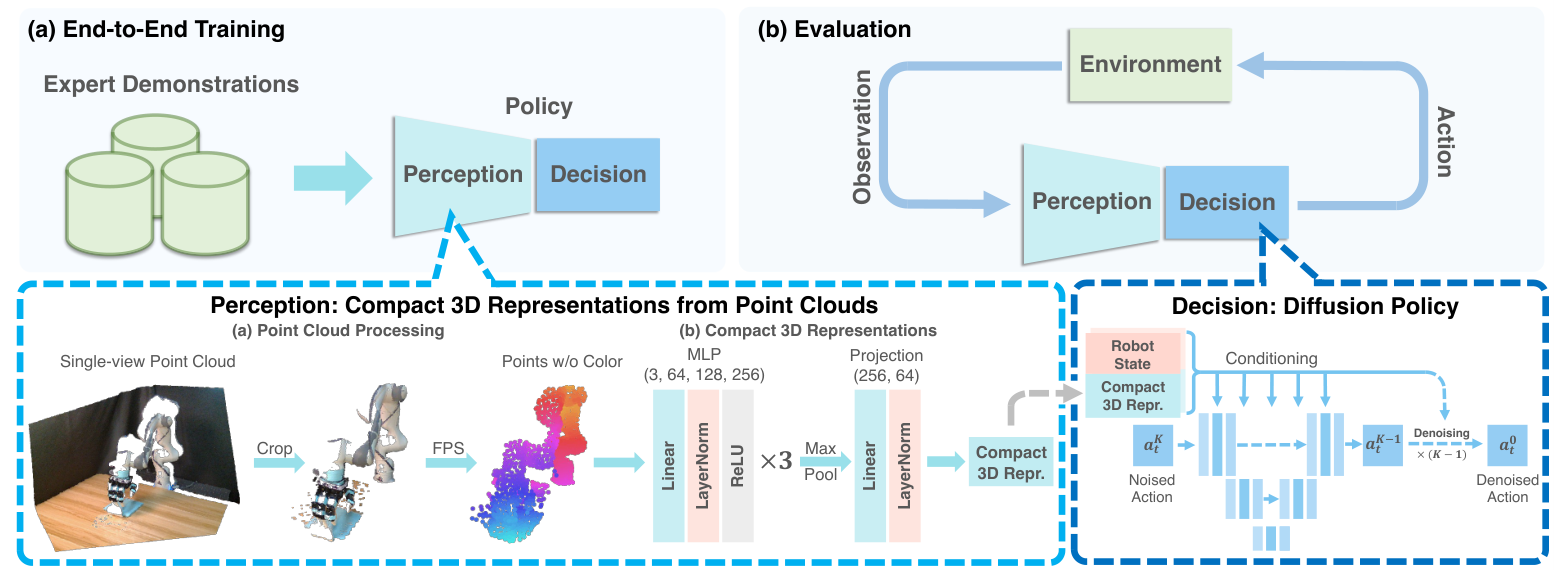
学一个视觉运动策略 π:O→A,分两块:(a) 感知(点云→紧凑 3D 特征)+ (b) 决策(扩散策略生成动作序列)。
2.1 感知 —— 稀疏点云编码(核心)¶
- 单视角相机(不像原 DP 在机器人周围布多相机)—— 为真机实用性。仿真和真机都取 84×84 深度图,用相机内外参转点云。不用颜色通道(为外观泛化)。
- 点云处理:① Crop 出包围盒内的点(去掉桌面/地面冗余点,消融显示这步极关键);② FPS 最远点采样降采样到 512 或 1024 点(比均匀采样更覆盖空间、更稳)。
- DP3 Encoder(极简):三层 MLP
(3→64→128→256),每层夹 LayerNorm + ReLU 稳训练 → MaxPool(顺序等变池化)→ 投影头(256→64)。最终 3D 特征仅 64 维。 - PyTorch 实现就十几行(见附录);机器人位姿另过一个小 MLP→64 维,与点云特征拼成 128 维条件向量。
- 反直觉结论:这个简单编码器胜过 PointNet/PointNet++/PointNeXt/Point Transformer,连预训练大编码器也不如它(见表)。
2.2 决策 —— 条件扩散策略¶
- 沿用 Diffusion Policy 的卷积 U-Net 去噪骨干,条件 = 3D 特征 v + 机器人位姿 q。从高斯噪声 a_K 迭代 K 步去噪到 a_0(反向过程,式1)。
- 训练目标:预测加到原动作上的噪声(MSE,式2,标准 DDPM 目标)。
- 实现关键:DDIM 调度器;用 sample prediction 而非 epsilon prediction(对高维动作生成更好、收敛更快,消融证实);训练 100 timesteps、推理 10 timesteps。MetaWorld 训 1000 epoch、其余 3000 epoch,batch 128。
- 短预测/执行 horizon:
H=4, N_obs=2, N_act=3(原 DP 常用 H=16/N_act=8)。为真机可被人打断时能立刻换动作;消融显示短 horizon 与长 horizon 几乎无差(78.3 vs 78.2)。
2.3 动机示例(图3)¶
只给 5 条示范,评测 1000 次看成功点在 3D 空间的覆盖:DP3 成功 415 次(铺满空间)、IBC 327、Diffusion Policy 285、BC-RNN 0。直观说明 3D 表征带来的样本效率与空间泛化。
3. 实验数字(全量)¶
3.1 仿真主结果(72 任务 / 7 域,3 seeds,每实验取最高 5 次成功率均值)¶
| 域 (任务数) | DP3 | Diffusion Policy |
|---|---|---|
| Adroit (3) | 68.3 | 31.7 |
| Bi-DexHands (6) | 70.2 | 61.3 |
| DexArt (4) | 68.5 | 49.0 |
| DexDeform (6) | 87.8 | 90.5 |
| DexMV (2) | 99.5 | 95.0 |
| HORA (1) | 71.0 | 49.0 |
| MetaWorld Easy (28) | 90.9 | 83.6 |
| MetaWorld Medium (11) | 61.6 | 31.1 |
| MetaWorld Hard (6) | 31.7 | 9.0 |
| MetaWorld Very Hard (5) | 49.0 | 26.6 |
| 平均 (72) | 74.4±29.9 | 59.8±35.9 |
- 相对提升 +24.2%,且方差更小。DP3 近 30 个任务成功率 >90%(DP 不足 15 个);DP3 没有任何任务 <10%,DP 有 >10 个任务 <10%。多数任务只用 10 条示范。
- 更多基线(10 任务平均):DP3 74.4 ≫ Diffusion Policy 44.0 ≫ BCRNN+3D 14.5 > IBC+3D 10.4 > BCRNN 9.8 > IBC 5.0。注:给 BCRNN/IBC 加 3D(用 DP3 Encoder)只小涨,说明增益不只来自 3D,更来自 DP3 整体设计。
3.2 效率¶
| 指标 | DP3 | Diffusion Policy | Simple DP3 |
|---|---|---|---|
| 推理速度 (FPS) | 12.7 | 12.3 | 25.3 (↑99%) |
| 平均成功率 (10 任务) | 74.4 | 44.0 | 70.2 (↓6%) |
- 收敛快:DP3 约 500 epoch就收敛(虽都训 3000 保证收敛),DP 慢得多或陷入次优。
- 3D 不必慢:DP3 推理速度略快于 DP(稀疏点云 + 紧凑表征)。Simple DP3(精简 U-Net 冗余)再快近 2 倍、精度仅降 6%。
- (脚注公平性)在 CALVIN 上对比 3D Diffuser Actor:同卡 2080Ti,3DDA 600ms 出 6 步、DP3 581ms 出 4 步 → 那个设定下 3DDA 控制频率反而更高(作者诚实标注)。
3.3 消融:3D 表征 & 编码器(6 任务 H/D/P/A/DA/SP 平均)¶
| 3D 表征 | 平均 |
|---|---|
| Point cloud (DP3) | 78.3 |
| Oracle State | 76.8 |
| Image | 40.7 |
| RGB-D | 34.7 |
| Voxel | 32.3 |
| Depth | 32.0 |
点云竟与 Oracle 状态(含物体状态/目标/速度)相当,说明点云足以学到近最优策略;RGB-D/Depth 远逊于点云 → 如何用深度信息很关键。
| 点云编码器 | 平均 |
|---|---|
| DP3 Encoder | 78.3 |
| PointNet | 15.7 |
| PointNeXt | 2.3 |
| PointNet++ | 2.2 |
| Point Transformer | 1.0 |
| PointNet++ (预训练) | 6.8 |
| PointNeXt (预训练) | 8.8 |
为什么 PointNet 系列垮:逐步把 PointNet 改成 DP3 风格发现,T-Net 与 BatchNorm 是主要拖累;去掉这两者,PointNet 涨到 72.3(接近 DP3 的 78.3)。解释:固定相机的控制任务不需要 T-Net 的特征变换。
3.4 消融:设计选择(6 任务平均)¶
| 设计 | 平均 | 说明 |
|---|---|---|
| DP3 (全) | 78.3 | — |
| w/o cropping | 45.3 | 裁剪点云增益最大 |
| w/o LayerNorm | 73.0 | 稳训练 |
| w/o sample pred | 67.0 | sample 预测收敛更快 |
| w/o projection | 77.7 | 投影头主要为加速、几乎不损精度 |
| w/ color | 72.0 | 去色 → 外观泛化更稳 |
| DDIM→DPM-solver++ | 48.3 | DPM-solver++ 处理不了高维动作 |
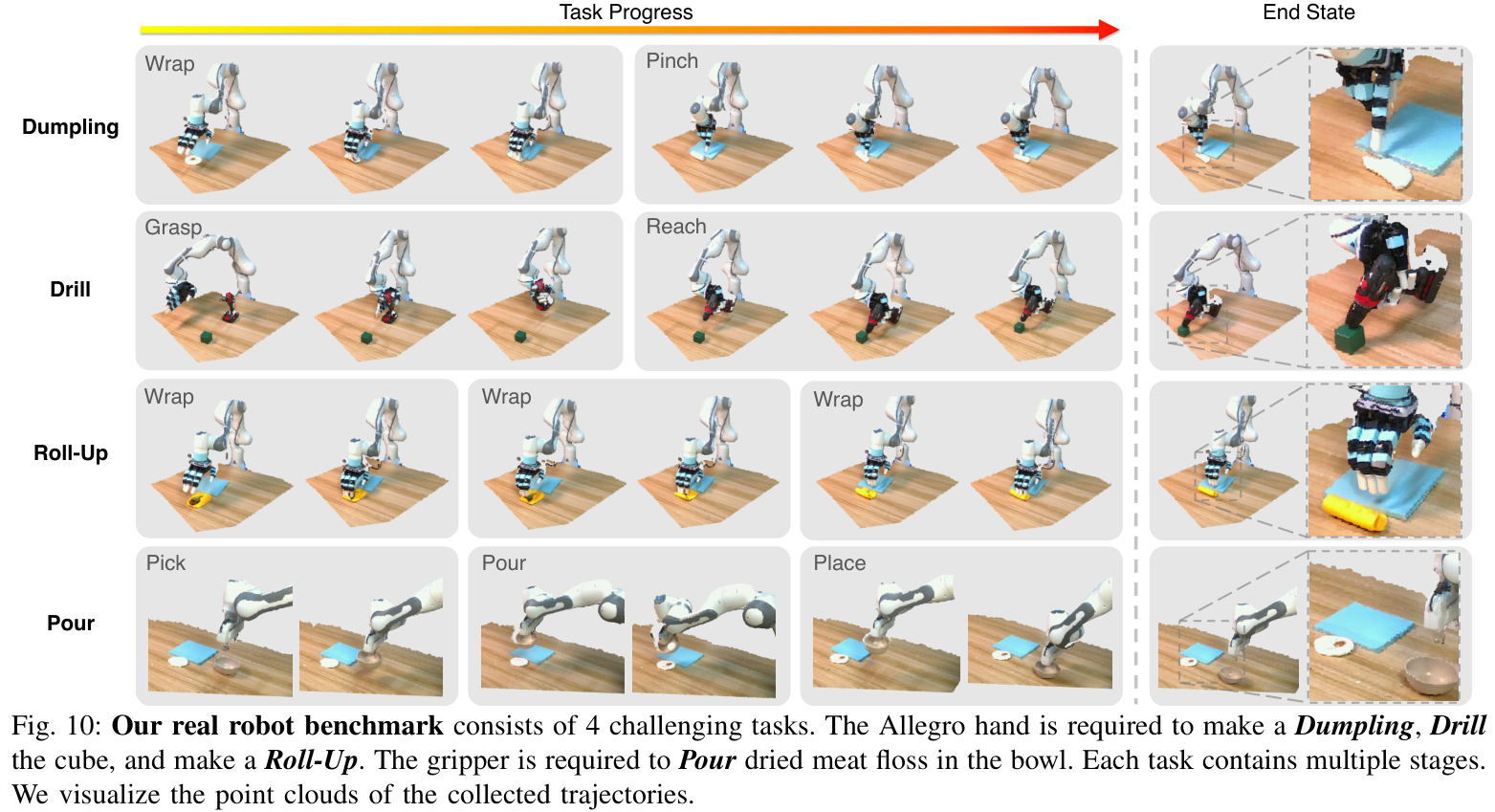
3.5 真机(4 任务,2 机器人:Allegro 手 + 夹爪;单 RealSense L515;各 40 条示范;每任务 10 trial)¶
| 真机任务 | Diffusion Policy | DP (Depth) | DP3 |
|---|---|---|---|
| Roll-Up | 0 | 40 | 90 |
| Dumpling | 30 | 20 | 70 |
| Drill | 70 | 10 | 80 |
| Pour | 40 | 10 | 100 |
| 平均 | 35.0±25.0 | 20.0±12.2 | 85.0±11.2 |
- 泛化(真机):空间泛化(Pour 5 个未见位姿)DP3 4/5、两基线 0/5;外观泛化(Drill 5 种颜色)DP3 5/5、基线全败;实例泛化(Drill 换 5 种日常物)DP3 5/5;视角泛化(Roll-Up 3 视角)DP3 全过——但需手动变换点云、且大幅变视角仍难。杂乱场景(pick&place,50 条)DP3 80%、DP 60%、DP3+PointNeXt 0、DP3+color 80(但换色/换物就垮)。
3.6 部署安全(亮点,但作者标注为定性观察)¶
| 安全违规率 ↓ | Roll-Up | Dumpling | Drill | Pour | 平均 |
|---|---|---|---|---|---|
| Diffusion Policy | 90 | 20 | 20 | 0 | 32.5 |
| DP (Depth) | 20 | 30 | 30 | 20 | 25.0 |
| DP3 | 0 | 0 | 0 | 0 | 0.0 |
图/深度策略常发"乱指令"(撞地/打结)需人工急停;DP3 几乎零违规。直觉解释:直接在 3D 空间观测有助避碰。作者明确说此评估是定性的、机理待未来研究。

4. 局限 / 存疑(诚实)¶
- 作者自陈:① 控制的"最优 3D 表征"仍未找到(点云只是当前最好);② 未涉及极长程任务。
- 真机任务偏少(4 个)、每任务仅 10 trial、单相机单视角;安全结论仅定性。
- 依赖相机标定 + 点云分割/裁剪:要把深度反投影到世界系、靠包围盒裁剪(cropping 是增益最大的一步)→ 换场景/移动相机需重标定。这点被其后续工作 iDP3 直接点名(见外评)。
- 视角泛化需手动变换点云,大幅变视角仍失效;外观泛化靠"丢颜色"换来——也意味着用不上颜色线索的任务才占优。
5. 核心洞见¶
- 真正的贡献是"证伪复杂性":用一个十几行的 MLP 编码器 + 稀疏无色点云,就压过精心设计的 2D 扩散策略和复杂 3D 策略——说明表征模态(3D)比编码器容量更重要,且简单小编码器 > 预训练大编码器(呼应作者前作 [On pre-training for visuo-motor control])。
- 3D 表征自带"安全先验":直接观测 3D 几何让策略少出危险动作 —— 对真机落地比成功率数字更值钱。
- 样本效率来自几何泛化:点云对空间/视角/外观/实例的天然不变性,使 10–40 条示范足够。
🗣️ 外部评价¶
- 🌐 RSS 2024 录用(会议程序页、OpenReview KwwJuZIBXH)。OpenReview 论坛存在,但逐条审稿意见未能抓取到公开正文(如实标注,未引述具体评分)。开源代码高关注,社区复现/二次开发活跃。
- 🌐 同团队后续 iDP3(Improved 3D Diffusion Policy, arXiv 2410.10803)的"反向背书式批评":明确指出原 DP3 依赖精确相机标定 + 点云分割,因此无法直接用于通用机器人(人形/移动操作)——这类机器人相机不固定、标定/分割不现实。iDP3 改用自我中心(egocentric)相机坐标系表征绕开标定/分割。这是对 DP3 落地边界最具体的公开批评。(来源:arXiv 2410.10803、Moonlight 评述)
- 🌐 后续工作的普遍共识性批评:DP3 在复杂任务上的精度仍待提升;对物体位置/形状的分布外变化适应有限——这推动了 AffordDP(加可迁移 affordance)、等变表征(卡片-EquivariantDiffusionPolicy 一类)、FP3/3D 基础策略等后续。(来源:AffordDP arXiv 2412.03142、FP3 arXiv 2503.08950)
🧑⚖️ 审稿人视角(🤖)¶
- 新颖性偏"工程组合"而非新模型:把点云编码器塞进 Diffusion Policy 条件位,方法论增量有限——但作者用72 任务 + 充分消融把"3D 重要性"这个 claim 做扎实,属于"简单但说服力强"的好实验论文。
- 基线公平性可质疑:主基线只跟图像/深度版 Diffusion Policy;与同期更强 3D 策略(3D Diffuser Actor 等)只在脚注/不同设定下比较,缺正面同台对比。作者已诚实标注设定差异。
- 真机证据偏薄:4 任务、每任务 10 trial、单视角,安全违规率这一最吸睛结论是定性统计,统计显著性不足,易受实现/调参影响。
- "点云≈Oracle 状态"值得追问:是否任务本身物体状态可从单视点云近乎完全恢复?换强遮挡/多物体堆叠场景能否成立存疑。
- 泛化测试条件温和:视角泛化需人工变换点云、"轻微"改视角;外观泛化靠去色——边界条件下的鲁棒性未充分压测。
6. 对我们¶
- 基线首选:若走点云/深度路线,DP3 是把 卡片-DiffusionPolicy / 详读-DiffusionPolicy 升到 3D 的最简、最强、可直接复用的基线(代码开源,DP3 Encoder 十几行)。
- 可直接借的工程点:稀疏 FPS 点云 + Crop + 去色 + 极简 MLP 编码器 + LayerNorm + sample-prediction 这一套"配方"几乎零成本,且消融逐项交代了每个选择的收益。
- 落地警示:DP3 的世界系点云依赖标定+裁剪;若我们目标是移动/人形/相机不固定平台,应直接看 iDP3 的 egocentric 方案,别照搬原 DP3。
- 对照线:与同走点云统一表征的 卡片-RobotSynesthesia 呼应;与靠等变性提泛化的 卡片-EquivariantDiffusionPolicy 是两条不同的"提泛化"路线,可长期对照。