详读 · VT-WM(Visuo-Tactile World Models 视觉-触觉世界模型)¶
卡片版见 卡片-VT-WM。本页是全文精读:动机 → 方法(逐模块讲直觉) → 实验(全表数字) → 洞见/局限 → 对我们。 来源:arXiv 2602.06001(preprint,2026-02-06)· 项目页未确认 作者:Carolina Higuera、Byron Boots(华盛顿大学 UW)+ Sergio Arnaud、Mustafa Mukadam、Francois Robert Hogan、Franziska Meier(FAIR / Meta)
0. 一句话定位¶
把指尖触觉图接进隐空间世界模型,给"机器人-物体接触"做物理锚定:纯视觉世界模型(V-WM)在遮挡/接触模糊时会"幻觉"(物体消失、瞬移、无受力却动);VT-WM 用触觉补上"看不见的接触状态",让想象中的 rollout 更守物理,从而零样本规划在接触密集任务上更可靠。作者明确定位为首个多任务视触觉世界模型。
1. 问题与动机¶
- 世界模型(WM)让机器人能在"想象"里推演动作后果、做规划(visual MPC / CEM)。但主流是纯视觉世界模型。
- 视觉的盲区:物体怎么动取决于力,而力对外部(exocentric)相机不可见;抓取/推/放时又常被手遮挡。结果 V-WM 在接触时产生伪影——物体瞬移(teleport)、消失(disappear)、不施力却变形/移动(违反牛顿第一定律)。
- 视觉混淆(aliasing):同一帧画面对应不同物理状态。例:手"搭在布上"——光看相机分不清是悬空、轻触还是压实;只有触觉能区分擦拭时布会不会被带动。
- 触觉补的正是"局部接触信号":力、滑移、细微位姿变化、接触/非接触。视觉给全局场景与运动学,触觉给局部接触动力学,二者互补。
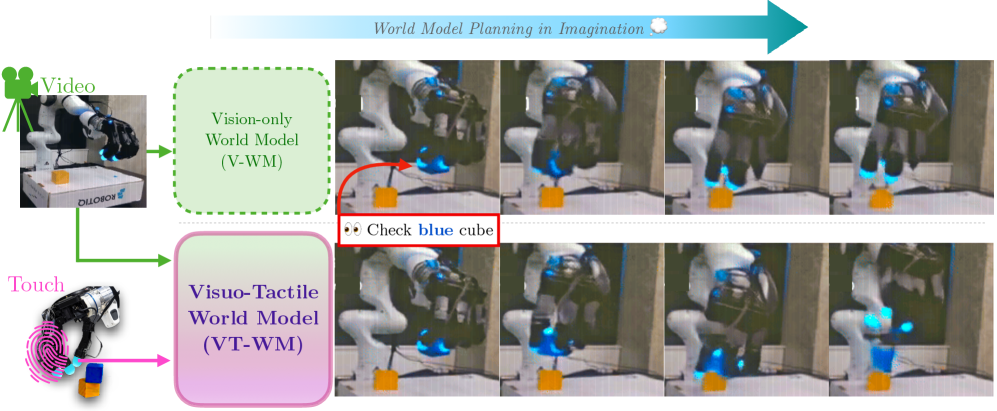
三点贡献(原文):① 首个把触觉并入视觉的多任务世界模型,同时建模全局上下文与局部接触动力学;② 接触锚定显著提升想象质量——物体恒存 +33%、守物理 +29%;③ 这些改进迁移到真机零样本规划,接触密集任务成功率最高 +35%。
2. 触觉提供了什么(图2)¶

- 视觉式触觉传感(GelSight / DIGIT / Digit 360):把软弹性体表面形变成像,30-60 FPS,含接触区的力、形状、纹理。
- 用途:区分"无接触 / 轻触 / 紧握"等从远处相机看一模一样的状态——这对接触密集操作是关键判别信息。
- 本文硬件:Franka Panda 臂 + Allegro 手,每个指尖一个 Digit 360(共 4 个)。
3. 方法详解¶
3.1 整体架构(图3)¶
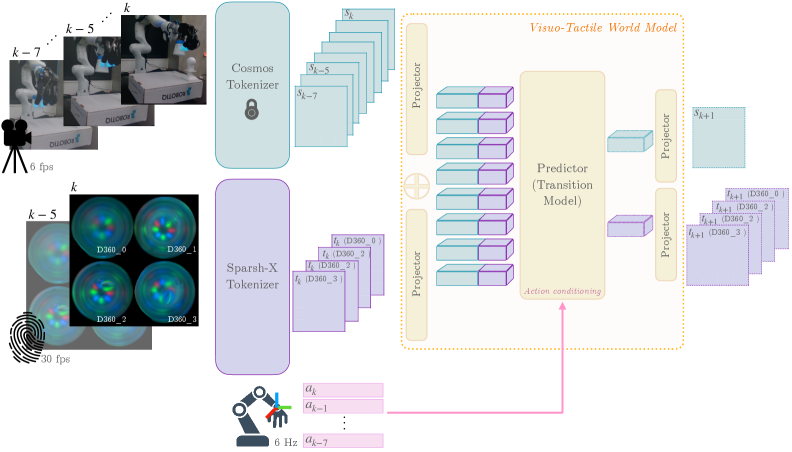
三大组件:视觉编码器 + 触觉编码器 + 自回归预测器。
- 视觉编码器:Cosmos Tokenizer(冻结),从外部视频抽视觉隐状态 sₖ(场景+机器人运动学)。
- 触觉编码器:Sparsh-X(微调,因传感器制造公差/弹性体磨损有个体差异),把高频接触反馈压成紧凑触觉隐状态 tₖ。
- 预测器(转移模型):把视觉/触觉隐状态 + 动作融合,估计下一步状态
(sₖ₊₁, tₖ₊₁) ∼ P_φ(sₖ, tₖ | aₖ)。
- 视觉与触觉 token 加正弦位置编码后投到统一表示 R(b,t,s,d),沿空间维拼接成统一序列。
预测器内部 = 12 层 transformer,交替两种注意力:
- 时空自注意力(分解式):先 spatial 让同一时刻所有 token 交互,再 temporal 跟踪每个 token 跨时间演化。分解是为了避开全时空注意力的 O((T·H·W)²) 复杂度。
- 动作条件 = 交叉注意力:每个自注意力块后,视觉-触觉 token cross-attend 到动作 token,把控制输入注入预测。自注意/交叉注意交替迭代精修隐状态。
- 所有注意力层用 RoPE(旋转位置编码)。最后经模态各自的输出头投回原维度,得 ŝₖ₊₁、t̂ₖ₊₁。
核心直觉:两帧画面看起来完全相同(手环着杯子),但触觉若指示"有接触"→想象出杯子被举起;若"无接触"→杯子留在桌上。触觉负责消解视觉歧义。
3.2 输入的时间尺度(关键设计)¶
- 视觉:1.5 秒外部视频片段,9 帧 @ 6 fps,分辨率 320×192,逐帧 Cosmos 编码。
- 触觉:每个 Digit 360 取 2 帧(4 个传感器),只覆盖最近 0.16 秒。——触觉频率高、局部性强,短时窗即可;与视觉的"慢、全局"互补。
- 动作:本体感觉增量(平移 + 四元数旋转) + 一个二值手开/合状态;把 30Hz 动作按 5 个一组分块,整块 delta 状态喂给预测器。
- 最大上下文:视觉/触觉各 9 帧。
3.3 训练目标(teacher forcing + 采样)¶
总损失 L = L_teacher + L_sampling(等权,均为 L1):
- Teacher Forcing 损失:用真值上下文做下一步预测,对 T 帧序列
L_teacher = Σ_{k=1}^{T-1} ‖ŝₖ₊₁ − sₖ₊₁‖₁ + ‖t̂ₖ₊₁ − tₖ₊₁‖₁。
监督密集、梯度稳,但自回归时有分布漂移。
- 采样损失:训练时自回归采样 H 步(典型 H=3~5)再预测,纠正长时漂移;采样状态不带梯度(防训练不稳)。
L_sampling = Σ_{k=1}^{H} ‖ŝ_sampled,ₖ₊₁ − sₖ₊₁‖₁ + ‖t̂_sampled,ₖ₊₁ − tₖ₊₁‖₁。
- 该"teacher forcing + 自回归采样"配方借鉴 V-JEPA-2(Assran et al. 2025)。
规模:总参数 173M,其中 96M 可训练(Sparsh-X 微调 + 预测器;Cosmos 冻结)。
3.4 在想象中规划(CEM)¶
预测器是动作条件的 → 可当模拟器跑 CEM(交叉熵法):
- 每步采样一群动作序列,预测器自回归生成未来隐状态,用代价函数(对目标图像的能量最小化)打分;取精英、更新采样分布、迭代收敛;最优序列在真机上开环执行。
- 代价 = 最终预测视觉隐 s_{k+H} 与目标图像隐 s_goal 的 L2 距离。
- 触觉不作为目标信号——规划目标纯视觉。触觉只在(a)训练时让 WM 学到接触物理、(b)初始上下文里指示"已接触/未接触"两处间接提升规划。
- CEM 超参(Algorithm 1):频率 f=6Hz、horizon H=2s、粒子 P=36、迭代 N=10、动作维 d=7([x,y,z,roll,pitch,yaw,gripper])、精英取 top-5、max-trials=3。
4. 实验¶
4.1 设置¶
- 对照:多任务 V-WM(纯视觉) vs 多任务 VT-WM(视+触),同动作、同上下文喂入。
- 数据集(附录B):遥操作采集 8 个接触密集任务(盘中取放、按按钮、推、布擦拭、灯罩插入、桌腿插入、叠方块、马克笔涂写),成功与失败都收。训练 124 条演示 / 112k 数据点(平均每条 40 秒),验证 26 条 / 17k 数据点;统一降到 6 FPS。
- 三个研究问题:① 接触感知(想象质量)、② 零样本规划迁移、③ 下游少样本适配。

4.2 接触感知 · 物体恒存(Object Permanence)¶
度量:用 CoTracker 跟踪物体关键点,算想象轨迹与真值轨迹的归一化 Fréchet 距离(越低越贴近真实运动);属 World Consistency Score 的子项。
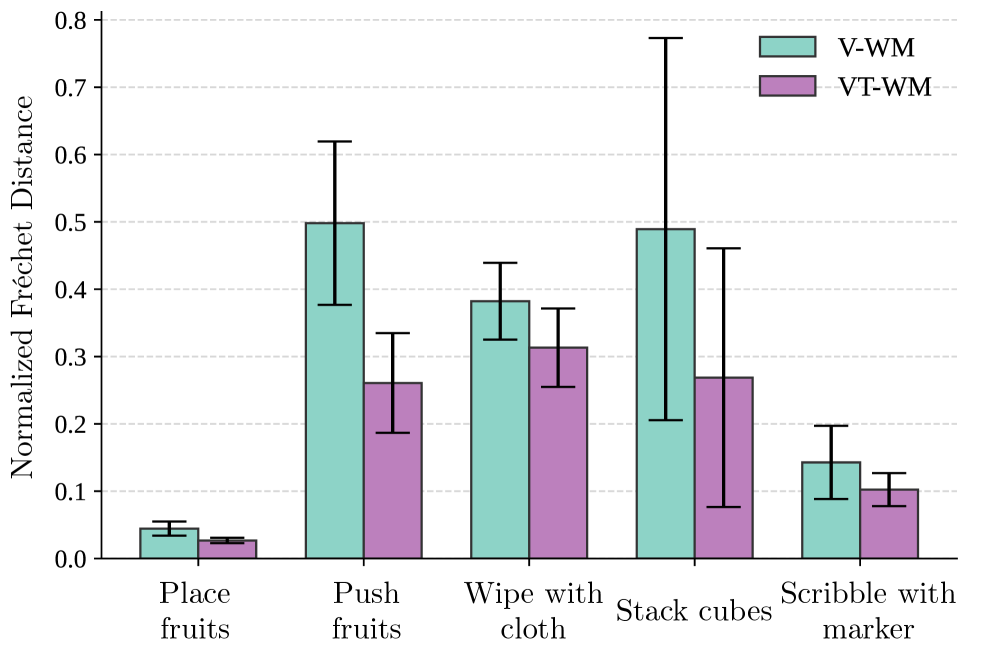
- 5 个任务上 VT-WM 把 Fréchet 距离降 18–47%,平均 ≈33%。
- 配对 t 检验显著性:
| 任务 | t 值 | p 值 | 是否显著(5%) |
|---|---|---|---|
| Place fruits | 4.38 | <0.001 | ✅ 显著 |
| Push fruits | 6.06 | <10⁻⁶ | ✅ 显著 |
| Stack cubes | 2.40 | <0.05 | ✅ 显著 |
| Wipe with cloth | 待核 | — | ❌ 不显著(同向下降) |
| Scribble with marker | 待核 | — | ❌ 不显著(同向下降) |
即:在"推/叠"这类强依赖物体恒存的任务上统计显著;擦布/涂写趋势一致但未达显著。
4.3 接触感知 · 因果守律(Causal Compliance)¶
度量:跟踪不受力、本应静止的物体关键点,算其想象轨迹误差(Fréchet 距离);越高=越爱幻觉(违反牛顿第一定律)。
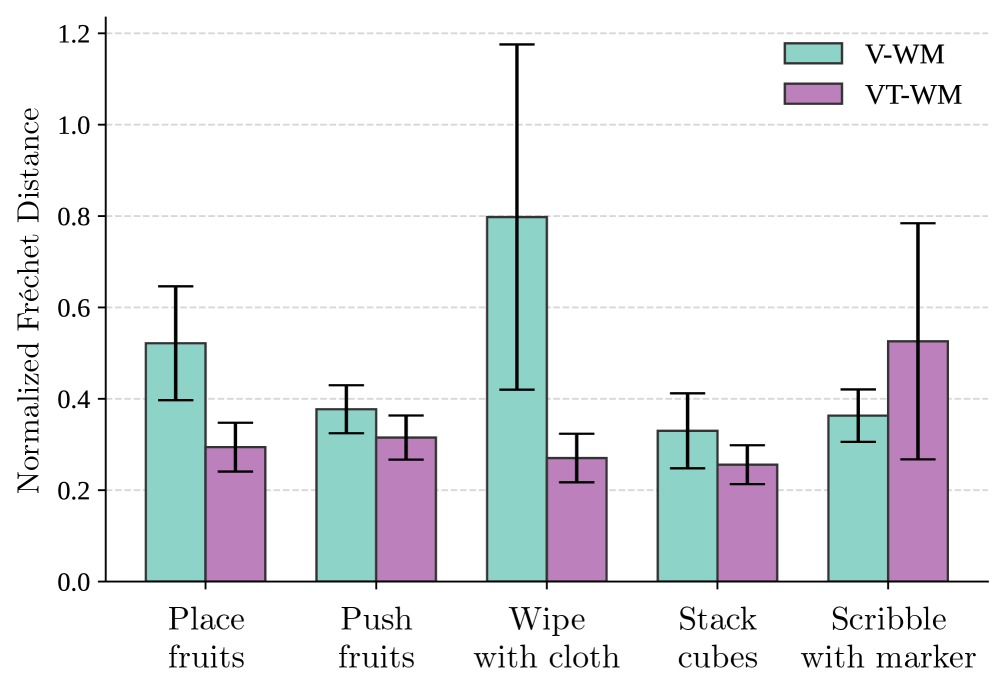
- 平均减少幻觉运动 ≈29%。逐任务相对降幅:
| 任务 | 相对改善 | t 值 | p 值 | 显著性 |
|---|---|---|---|---|
| Place fruits | −43.6% | 3.66 | <0.001 | ✅ 显著 |
| Push fruits | −16.4% | 2.28 | <0.05 | ✅ 显著 |
| Wipe with cloth | −66.1% | 2.99 | <0.01 | ✅ 显著 |
| Stack cubes | 较小改善(待核%) | 1.75 | 0.09 | ❌ 不显著 |
| Scribble with marker | 退化(变差) | −1.22 | 0.23 | ❌ 不显著 |
诚实读数:
Scribble with marker上 VT-WM 反而变差(t=−1.22),作者明写"a degradation in scribble with marker"。即并非每个任务都赢。

4.4 零样本规划迁移到真机(图7左)¶
CEM 规划解目标条件能量最小化;搜索空间 R⁷(腕位 3D 平移+3D 朝向 + 二值手开合)。开环零样本到真机,每任务 5 次试验、各异初始条件。5 个难度递增任务:reach button、push fruits、reach&push、wipe cloth、stack cubes(后三个多子目标)。
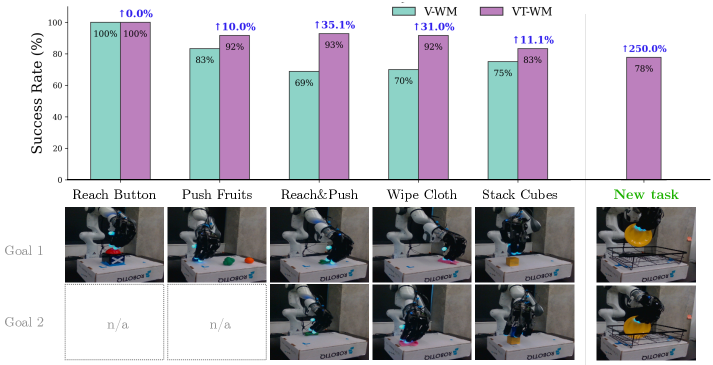
各任务 VT-WM 相对 V-WM 的成功率增益:
| 任务 | 类型 | VT-WM 相对 V-WM | 备注 |
|---|---|---|---|
| Reach button | 单目标·自由空间 | 0%(两者均 100%) | 纯运动学,视觉足够 |
| Push fruits | 单目标·接触 | +10% | 需持续轻接触 |
| Reach & push | 多子目标·接触 | +35% | V-WM 常悬空→推空 |
| Wipe cloth | 多子目标·接触 | +31% | V-WM 接触不稳→擦不动 |
| Stack cubes | 多子目标·接触 | +11% | V-WM 放置时丢方块 |
结论:自由空间(reach)两者持平;接触密集、多步任务 VT-WM 优势最明显(最高 +35%)。
4.5 下游通用性 · 少样本新任务(图7右)¶
- 新任务 place plate in dish rack(盘子放入碗架),仅 20 条演示继续训练;CEM 零样本迁真机,10 次试验随机化初始盘姿;任务分"对齐 + 插入"两子目标。
- VT-WM 规划 77% 成功率。主要失败模式是"把盘放到架旁"——属精度误差而非不理解任务空间结构。
- 说明多任务 WM 的数据效率:已有接触物理先验 → 少量演示即可适配新接触任务。
4.6 训练配置(附录B,便于复现判断)¶
| 项 | 取值 |
|---|---|
| 优化器 | AdamW(β₁=0.9, β₂=0.95, weight decay 0.01) |
| 学习率 | 线性 warmup 10k 步到峰值 3e-4,余弦衰减到 3e-7,共 80k 步 |
| 有效 batch | 64 |
| 算力 | 32× A100 GPU |
| 视觉编码器 | Cosmos Tokenizer(冻结) |
| 触觉编码器 | Sparsh-X(微调) |
| 总参/可训练参 | 173M / 96M |
5. 核心洞见¶
- 关键论点:补齐世界模型的不是"更高视觉分辨率",而是接触锚定(contact grounding)——把局部触觉并进隐空间动力学,直接治住"遮挡/接触模糊"下的视觉幻觉(消失/瞬移/无力却动)。
- 触觉的角色是"训练期物理先验 + 推理期初始消歧",而非规划目标本身(目标仍纯视觉)。这是个克制而聪明的设计:不需要"目标触觉图"也能让规划受益。
- 增益结构清晰:自由空间任务=持平(视觉够用);接触密集 + 多步=增益最大。证明它补的正是视觉的短板,而非全面碾压。
- 隐空间路线:用现成基础编码器(Cosmos 视觉 + Sparsh-X 触觉)在隐空间训动作条件动力学——173M 规模、可训练仅 96M,相对轻量。
6. 局限 / 存疑(作者自陈 + 诚实补充)¶
- 触觉模态单一:只用视觉式触觉(Digit 360);作者称框架可换其他触觉(需有对应预训练编码器),但未验证。
- 泛化范围窄:接触感知评估虽用"未见轨迹",但仍在训练分布内的任务;规划实验虽随机初始位姿,但同场景同物体,没测不同大小/形状/颜色的物体。→ 真正"新物体/新任务"泛化是开放问题。
- CEM 规划昂贵:每个粒子要跑多条自回归 rollout → 只能开环、分块执行,不像经典策略那样高频闭环。
- 退化案例存在:scribble with marker 上因果守律变差(见 4.3)——非全胜。
- 开源未确认:preprint,文中未声明代码/数据/项目页 → 复现性待定(卡片标"代码未确认")。
- 触觉不入规划目标:是优点也是约束——意味着它无法直接对"目标接触状态"做规划(只能靠视觉目标 + 初始触觉上下文)。
7. 对我们(深一层)¶
- 视触觉世界模型的标杆对照:它把"触觉补视觉幻觉"讲得最清,是这条线的参照系。与 卡片-OmniVTA 同属"视+触联合世界模型"方向。
- 路线差异(重要):VT-WM 走视觉式触觉图 + 像素/想象规划(CEM);而 卡片-TacForeSight × 卡片-LaWAM 走隐空间预测 / 潜动作路线。两条线正好对照——"图像化触觉 vs 抽象隐状态触觉"。
- 机制可借:① "触觉只做训练期物理先验 + 初始消歧、不进规划目标"这个克制接法很值得借鉴;② 分解式时空注意力 + 动作交叉注意力的多模态预测器结构(见 概念-模型架构基础);③ teacher forcing + 自回归采样的训练配方治长时漂移。
- 数据视角:124 条演示 / 112k 点就能撑起多任务 WM + 20 条演示适配新任务——数据效率对我们采数策略是正面信号。
- 互为镜子:它加指尖视觉式触觉把"想象"做实;VT-WM 提供了"触觉到底补了哪些幻觉、值多少分"的量化参照(物体恒存 +33% / 守律 +29% / 规划 +35%)。