详读 · OmniVTA(视触觉世界模型 + 21k 轨迹对齐数据集,接触密集操作)¶
卡片版见 卡片-OmniVTA。本页是全文精读:动机 → 数据集(OmniViTac) → 方法(四模块逐个拆) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2603.19201(v2,2026-03-23)· 项目页(data/models/code 承诺开源,未发布) 作者:Yuhang Zheng、Songen Gu(共同一作)… 通讯:Yupeng Zheng、Shuicheng Yan(颜水成)、Wenchao Ding。机构:TARS Robotics、新加坡国立 NUS、复旦、中科院自动化所 CASIA、清华、中关村学院、北航。
0. 一句话定位¶
一篇"数据集 + 方法"双交付的论文:① 放出 OmniViTac——21,879 条视觉-触觉-动作完全对齐轨迹、86 任务、6 种"物理接地"接触模式的大规模数据集;② 在其上提出 OmniVTA——一个 world-model 式视触觉操作框架,把"预测未来接触(前馈) + 高频反射式纠偏(反馈)"两件人类感觉运动控制的关键能力,做进一个慢-快(slow-fast)分层策略里。核心论点:准确预测触觉未来,比把触觉当被动观测更能稳住接触密集任务。
1. 问题与动机¶
作者把"视触觉操作"的瓶颈拆成数据和方法两条: - 数据侧:现有公开视触觉数据集规模小、任务窄——完全对齐(视觉/触觉/动作三流同步)的演示太少、高频触觉数据不够,覆盖的接触机制单一,学不出可泛化的视触觉表征与接触动力学。 - 方法侧:现有方法只把触觉当"辅助观测"喂进策略网络(用于接触状态识别/补视觉遮挡),不显式建模接触动力学;控制上多用 action chunking 开环执行短动作序列,对滑移/错位/外扰这类快速接触变化反应不及。 - 人类参照(神经科学[11-14]):靠的是"紧耦合多模态感知 + 预测式内模型 + 快速触觉反馈控制"——预测 + 反射这套,恰是当前视触觉策略缺的。OmniVTA 就是照这条思路补齐。
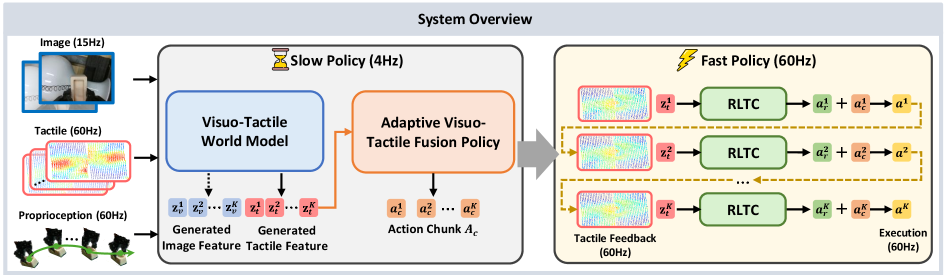
2. 系统总览(图1)¶
 左中右三件套:数据集打底 → world-model 框架统一了"触觉表征学习 + 预测式多模态建模 + 自适应融合 + 反射式触觉控制" → 真机实验证明强鲁棒/强泛化。
左中右三件套:数据集打底 → world-model 框架统一了"触觉表征学习 + 预测式多模态建模 + 自适应融合 + 反射式触觉控制" → 真机实验证明强鲁棒/强泛化。
3. OmniViTac 数据集¶
3.1 规模与构成¶
- 21,879 条同步轨迹,86 任务,100+(表中 126)操作物体,RGB-D + 高频触觉 + 动作三流时间对齐。
- 六种物理接地接触模式:擦拭 Wiping、剥皮 Peeling、切割 Cutting、抓取 Grasping、装配 Assembly、手内调整 In-hand Adjustment。
- 五类语义场景:厨房、果蔬店、工业工位、化学实验室、办公室;含刚性/可变形/透明/铰接物体 → 视觉干扰、光照、物性多样。
- 类别分布:抓取最大 9,200 条;其余每类约 3,000 或 1,000 条,量级一致(均衡,利于预训练 + 微调)。
3.2 采集系统(图2)¶
 - 双本体跨形态采集(平衡"贴近机器人"与"采得快"):
- 7-DoF 机械臂 xArm-7:两种模式——重力补偿示教(kinesthetic) 适合精细力感知(擦/插);GELLO 主从遥操作[44] 适合大空间运动(取放)。
- TacUMI 手持采集器(借鉴 FastUMI[47]):RealSense T265 输出 200Hz 6-DoF 位姿估轨迹;采后自动查漂移,位置误差 >8mm 直接丢弃。
- 同构末端:两本体都用同款平行二指夹爪 + 模块化可换触觉指尖 → 抓取几何/接触力学一致,压本体域差。夹爪开口归一化到 [0,1]。
- 四种触觉传感器(多原理/多分辨率):
- 双本体跨形态采集(平衡"贴近机器人"与"采得快"):
- 7-DoF 机械臂 xArm-7:两种模式——重力补偿示教(kinesthetic) 适合精细力感知(擦/插);GELLO 主从遥操作[44] 适合大空间运动(取放)。
- TacUMI 手持采集器(借鉴 FastUMI[47]):RealSense T265 输出 200Hz 6-DoF 位姿估轨迹;采后自动查漂移,位置误差 >8mm 直接丢弃。
- 同构末端:两本体都用同款平行二指夹爪 + 模块化可换触觉指尖 → 抓取几何/接触力学一致,压本体域差。夹爪开口归一化到 [0,1]。
- 四种触觉传感器(多原理/多分辨率):
| 传感器 | 触觉图像 | 形变/位移场分辨率 | 频率 |
|---|---|---|---|
| Xense (Quark N1) | RGB 700×400 @30Hz | 3D 位移 35×20 @60Hz | 主力 |
| Daimon (Tac-WL) | 灰度 640×480 @30Hz | 3D 位移 320×240 @60Hz | — |
| Tac3D-A1 | — | 稠密 3D 位移 20×20 @30Hz | — |
| GelSight Mini | RGB 320×240 @25Hz | 3D 位移 9×7 @25Hz | — |
Xense 是主力(大规模采集鲁棒):分析与真机评测主要用 Xense;其余三种用于触觉表征学习 / 跨传感器泛化研究。
3.3 数据管线与质检¶
- 所有流各自原生频率异步记录,后处理按时间戳对齐(时间误差 <10ms)。
- 单人采集:脚踏控制(启/录/停);每 25 条自动重启防传感器漂移;每 50 条随机抽 3 条可视化在线质检;离线再筛除异常。
- 预处理:去首尾静止冗余帧 → 时间戳对齐 → 切成训练片段。
3.4 数据集统计分析(图4)——发现触觉两大结构性质¶
 - 有效接触比 Effective Contact Ratio(轨迹中真有接触的时段占比):Adjustment 0.67(最高,手内调整要持续接触监滑移) > Wiping 0.49 > Peeling 0.41 > Cutting 0.27(最低且方差大,切割前长时间视觉对位、接触瞬时高force)。
- 接触面积 / 力强度二分:
- 精度主导(Assembly/Grasping/Adjustment):66% 落在 0–10% 接触面积区间 + 低力 → 指尖局部轻触。
- 表面/力主导(Cutting/Peeling/Wiping):接触面积峰在 70%–90%(满贴维持摩擦);Cutting 力强度峰在 40%–50%(穿透材料)。
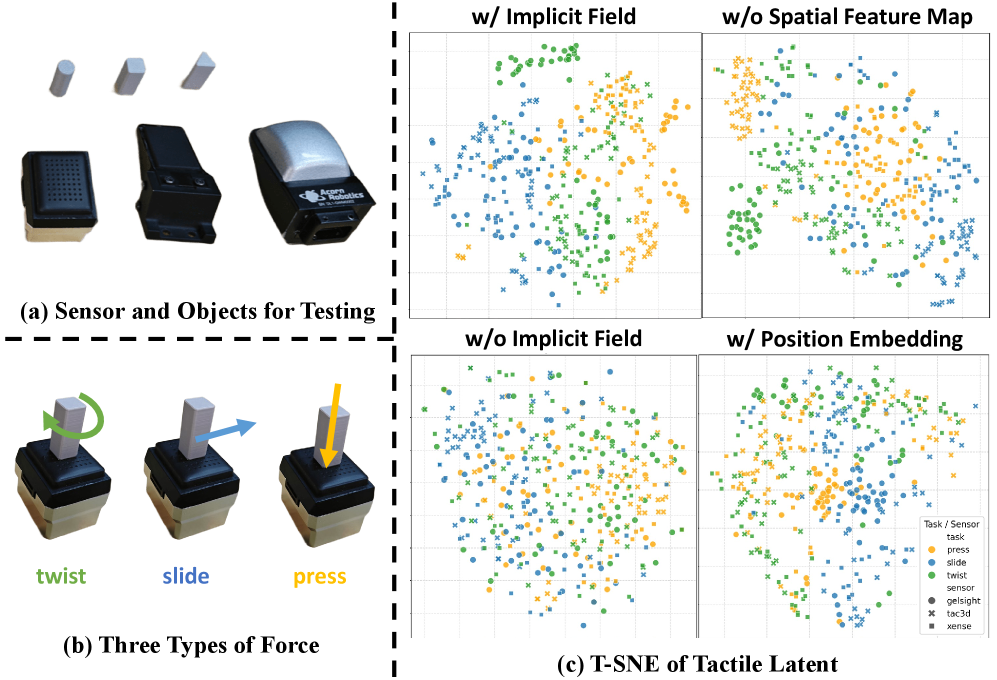
- t-SNE(图4f):六模式触觉信号在隐空间语义可分——Wiping/Peeling 相邻(共享剪切+动态法向)、Assembly 独立成簇(静态法向+局部几何)、Grasping 占大区(类内最多样)。→ 证明数据集捕到了"模式特异的接触动力学",不是随机/噪声接触。
- 由此提炼触觉信号两大性质(指导了 OmniVTA 架构设计):① 空间局部性 spatial locality;② 接触驱动动态 contact-driven dynamics(接触前几乎不激活,接触发生才有信息)。
- 有效接触比 Effective Contact Ratio(轨迹中真有接触的时段占比):Adjustment 0.67(最高,手内调整要持续接触监滑移) > Wiping 0.49 > Peeling 0.41 > Cutting 0.27(最低且方差大,切割前长时间视觉对位、接触瞬时高force)。
- 接触面积 / 力强度二分:
- 精度主导(Assembly/Grasping/Adjustment):66% 落在 0–10% 接触面积区间 + 低力 → 指尖局部轻触。
- 表面/力主导(Cutting/Peeling/Wiping):接触面积峰在 70%–90%(满贴维持摩擦);Cutting 力强度峰在 40%–50%(穿透材料)。
- t-SNE(图4f):六模式触觉信号在隐空间语义可分——Wiping/Peeling 相邻(共享剪切+动态法向)、Assembly 独立成簇(静态法向+局部几何)、Grasping 占大区(类内最多样)。→ 证明数据集捕到了"模式特异的接触动力学",不是随机/噪声接触。
- 由此提炼触觉信号两大性质(指导了 OmniVTA 架构设计):① 空间局部性 spatial locality;② 接触驱动动态 contact-driven dynamics(接触前几乎不激活,接触发生才有信息)。
4. OmniVTA 方法:慢-快分层世界模型策略(图5)¶
 把操作显式拆成 慢规划 + 快反射:
- 慢策略 Slow Policy(约 4Hz)=视触觉世界模型 VTWM + 自适应视触觉融合策略 AFP,从低频视觉(15Hz)、高频触觉(60Hz)、本体(60Hz)规划长程动作块 A_c。推理时世界模型只预测未来触觉、不生成视觉(提速)。
- 快策略 Fast Policy(60Hz)=反射式潜触觉控制器 RLTC,据预测触觉 + 实测触觉出单步细粒度纠偏 a_r。
- 末端动作 = 慢规划 + 快纠偏 的加权求和(快策略贡献乘一预设系数)。四模块依次见 §4.1–4.4。
把操作显式拆成 慢规划 + 快反射:
- 慢策略 Slow Policy(约 4Hz)=视触觉世界模型 VTWM + 自适应视触觉融合策略 AFP,从低频视觉(15Hz)、高频触觉(60Hz)、本体(60Hz)规划长程动作块 A_c。推理时世界模型只预测未来触觉、不生成视觉(提速)。
- 快策略 Fast Policy(60Hz)=反射式潜触觉控制器 RLTC,据预测触觉 + 实测触觉出单步细粒度纠偏 a_r。
- 末端动作 = 慢规划 + 快纠偏 的加权求和(快策略贡献乘一预设系数)。四模块依次见 §4.1–4.4。
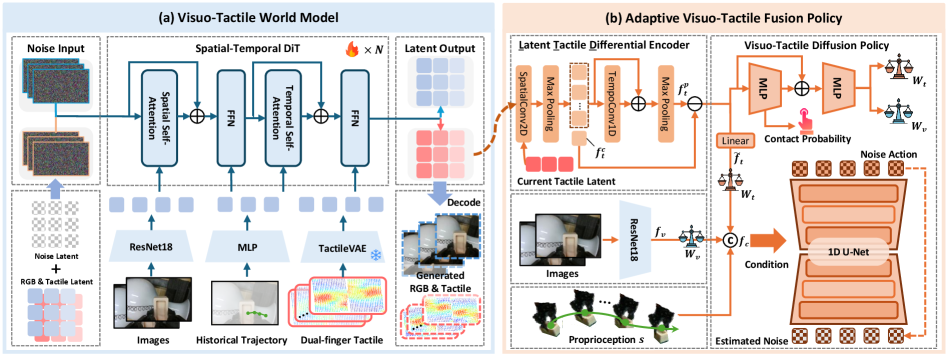
4.1 TactileVAE:自监督触觉编码器(图6)¶
 - 输入用 3D marker 位移(H×W×3,非高分辨率触觉图):抓住接触形变、分辨率低 → 高频推理。
- 编码器:因果 3D 卷积 VAE,M 个下采样模块,把 H×W 压到 (H/s)×(W/s)×C,s=2^M。因果卷积保证 t 时刻 latent 只依赖当前/过去 → 训练-部署一致。
- 解码器:不重建像素,用隐式神经表示 INR[51] 解码——把形变建成连续函数
- 输入用 3D marker 位移(H×W×3,非高分辨率触觉图):抓住接触形变、分辨率低 → 高频推理。
- 编码器:因果 3D 卷积 VAE,M 个下采样模块,把 H×W 压到 (H/s)×(W/s)×C,s=2^M。因果卷积保证 t 时刻 latent 只依赖当前/过去 → 训练-部署一致。
- 解码器:不重建像素,用隐式神经表示 INR[51] 解码——把形变建成连续函数 d(x)=D_θ(γ(x), Φ(z_t,x)),x 为空间坐标、γ 位置编码、Φ 空间插值取局部特征、D_θ 是 MLP 预测 3D 形变向量。
- 损失:重建 + KL:L=‖d(x)−d̂(x)‖² + λ_KL·L_KL,λ_KL=1e-6。
4.2 视触觉世界模型 VTWM:两流条件生成(图7a)¶
 - 两流架构:视觉、触觉各一条 spatial-temporal 扩散 Transformer (DiT)[57];取过去 c 帧为条件、迭代去噪生成多帧未来 → 概率式未来动力学。视觉分支用 SD-VAE[58] 取图像 latent,触觉分支用上一步预训好的 TactileVAE。扩散目标见式(3),mask m 做时间条件(逼模型用历史预测未来)。
- 多模态观测 conditioner:分别抽取并时间聚合 视觉/触觉/动作,动作用"3D 末端位置在图像平面的 2D 投影"表示(对操作位置变化更鲁棒),再在共享线性空间融成定长条件向量,同时注入两条流对齐跨模态。
- 动态感知加权损失 Dynamic-aware Weighted Loss(对应触觉"接触驱动动态"性质):
- 动态权图
- 两流架构:视觉、触觉各一条 spatial-temporal 扩散 Transformer (DiT)[57];取过去 c 帧为条件、迭代去噪生成多帧未来 → 概率式未来动力学。视觉分支用 SD-VAE[58] 取图像 latent,触觉分支用上一步预训好的 TactileVAE。扩散目标见式(3),mask m 做时间条件(逼模型用历史预测未来)。
- 多模态观测 conditioner:分别抽取并时间聚合 视觉/触觉/动作,动作用"3D 末端位置在图像平面的 2D 投影"表示(对操作位置变化更鲁棒),再在共享线性空间融成定长条件向量,同时注入两条流对齐跨模态。
- 动态感知加权损失 Dynamic-aware Weighted Loss(对应触觉"接触驱动动态"性质):
- 动态权图 w_dyn=resize(clip[0,1](‖X_{i+1}−X_i‖))(突出时变剧烈处);
- 幅度权图 w_amp=resize(clip[0,1](‖X_i‖))(突出强接触处);
- 总损失 L_VTWM = L_diffusion + λ_1·L_dyn + λ_2·L_amp,λ_1=λ_2=1.0。
- 注:训练时联合生成视觉+触觉(消融证明视觉预测给互补全局线索、提升触觉预测精度),但推理与策略输入不用生成的视觉(见 §5.3 消融,省一半算力)。
4.3 自适应视触觉融合策略 AFP(图7b)¶
- LTD 编码器 (Latent Tactile Differential):触觉空间局部、接触前不激活 → 不能简单拼历史触觉。LTD 把当前触觉 f_t^c、预测未来触觉 f_t^p、二者之差通道拼接:
f_t = concat(f_t^c, f_t^p, f_t^p − f_t^c)。差分项凸显"预测 vs 当前"的偏差 → 潜在接触事件线索。f_t^c 由 2D 卷积+max pool 空间聚合;f_t^p 由 1D 卷积+max pool 时间聚合。 - 门控自适应融合(借鉴 FoAR[59]):先用 MLP+sigmoid 据 f_t 预测未来接触概率(标签由触觉形变幅度阈值自动生成,BCE 损失);门控网(两层 FC,输入=接触 logit + f_t)输出逐通道模态权重 W_t, W_v 且 W_t+W_v=1。融合:
f_vt = concat(W_v⊙f_v, W_t⊙f̃_t),f_v 是 ResNet-18 视觉特征。门控不需视觉输入(触觉表征已含未来动态)→ 省算力。 - 视触觉扩散策略:条件去噪扩散(DDPM),条件
f_c=concat(f_vt, s)(s=本体),FiLM 调制 CNN,输出 H 步动作块 A_c。 - 损失:
L_AFP = L_act + λ_ct·L_bce,λ_ct=0.2。
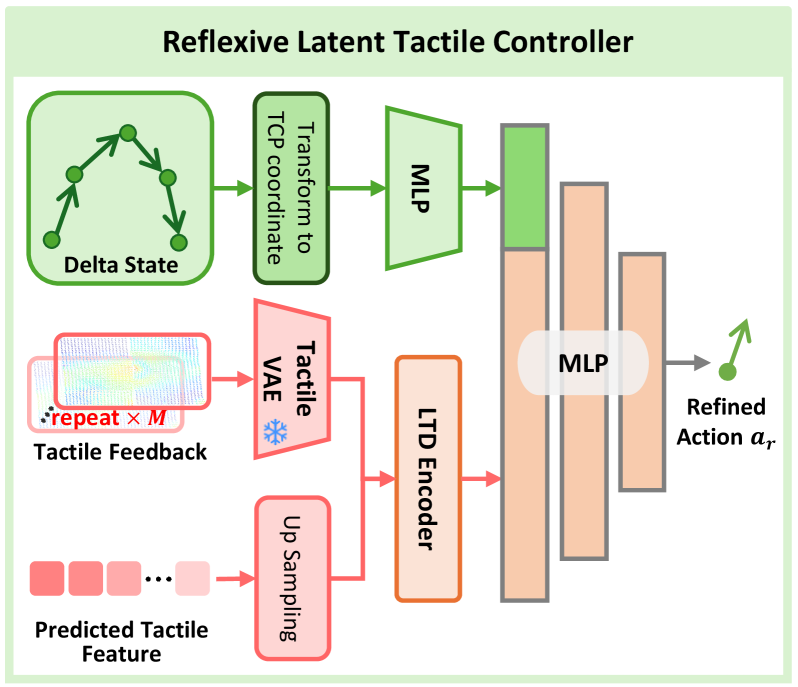
4.4 反射式潜触觉控制器 RLTC(图8)¶
 - 输入:单帧触觉反馈(因 TactileVAE 沿时间压 M 倍,把单帧重复 M 次再编码) + 世界模型预测触觉(最近邻上采样对齐到观测频率,逐帧一一对应,经 LTD 编码) + 机器人过去 h 步 delta 动作(转到 TCP 系)+ delta 夹爪 → 三层 MLP → 单步纠偏 a_r,60Hz。
- 训练(关键且巧):先按每类任务从人类轨迹估正常触觉分布(均值±方差);落在分布外(力过大/过小)=异常态;抽取"异常→正常"的恢复段作为人类纠偏示范,对每步构造(当前触觉, 预测触觉, 纠偏动作 â_r)对,MSE 训练
- 输入:单帧触觉反馈(因 TactileVAE 沿时间压 M 倍,把单帧重复 M 次再编码) + 世界模型预测触觉(最近邻上采样对齐到观测频率,逐帧一一对应,经 LTD 编码) + 机器人过去 h 步 delta 动作(转到 TCP 系)+ delta 夹爪 → 三层 MLP → 单步纠偏 a_r,60Hz。
- 训练(关键且巧):先按每类任务从人类轨迹估正常触觉分布(均值±方差);落在分布外(力过大/过小)=异常态;抽取"异常→正常"的恢复段作为人类纠偏示范,对每步构造(当前触觉, 预测触觉, 纠偏动作 â_r)对,MSE 训练 L_RLTC=‖a_r−â_r‖²。
5. 实验(全为真机,xArm7 + 二指夹爪 + 两指尖 Xense)¶
5.1 设置与协议¶
- 观测:视觉 15Hz、触觉 60Hz、本体 60Hz;策略输入 = 当前+上一视觉帧(共 2 帧)+ 同窗 8 触觉帧 + 2 本体;动作块预测未来 6 步,执行时插值到 60Hz;相对动作表示。
- 训练:四阶段。TactileVAE 用 20% 轨迹 + 10 个额外物体 ≈ 1.2M 触觉样本、50 epoch、8×A100;VTWM 每类 5–6 物体×150 轨迹、90/10 划分、AdamW lr=1e-4、batch 5/GPU、100k 步、20k 步后梯度裁剪 0.1;AFP 训 250k 步(其它基线 350k 步以补缺感知模块)。
- 任务与物体(各物体 150 条):擦花瓶 / 剥(黄瓜山药萝卜) / 切(黄瓜山药辣椒香蕉) / 装配(USB/充电头) / 抓(蓝莓草莓葡萄樱桃番茄) / 调整(长方体圆柱)。
- 基线:DP[60]、DP+tactile(PCA 触觉)、KineDex[66]、ForceMimic[65]、RDP5、OmniVTA w/o RLTC(开环消融)、OmniVTA(全)。
- 评测三视角:物体多样性 O(每类 2–4 物体,各 10 次)、泛化 G(位置/未见高度 + 工具:换未见刀)、扰动鲁棒 P(操作中突然上下移动物体打断接触,各 10 次)。指标=任务成功率(且不损坏传感器)。
5.2 主结果(表III,成功率;O=物体多样 G=泛化 P=扰动)¶
| 方法 | Wipe O/G/P | Peel O/G/P | Cut O/G/P | Assembly O/G/P | Grasp O | Adjust O/G |
|---|---|---|---|---|---|---|
| DP | 0.12/0.05/0 | 0.06/0/0 | 0.28/0.10/0 | 0.10/0/0.05 | 0.20 | 0/0 |
| DP+tactile | 0.36/0.28/0 | 0.32/0.20/0.08 | 0.33/0.15/0.13 | 0.30/0.10/0.10 | 0.48 | 0.25/0.15 |
| KineDex | 0.40/0.25/0 | 0.24/0.13/0.05 | 0.38/0.30/0.20 | 0.30/0.15/0.15 | 0.65 | 0.30/0.20 |
| ForceMimic | 0.33/0.20/0 | 0.27/0.18/0 | 0.50/0.25/0.05 | 0.35/0.15/0.10 | 0.60 | 0.10/0 |
| RDP | 0.50/0.38/0.42 | 0.48/0.36/0.45 | 0.65/0.50/0.43 | 0.60/0.50/0.35 | 0.88 | 0.50/0.50 |
| OmniVTA w/o RLTC | 0.66/0.40/0.25 | 0.40/0.30/0.20 | 0.50/0.50/0.20 | 0.40/0.35/0.20 | 0.70 | 0.40/0.30 |
| OmniVTA | 0.80/0.58/0.60 | 0.55/0.48/0.63 | 0.85/0.83/0.60 | 0.60/0.50/0.40 | 0.90 | 0.65/0.65 |
要点(作者读数): - OmniVTA 六任务全部最佳;加 RLTC 普遍比开环变体(w/o RLTC)显著提升 → 高频反馈对接触稳定关键。 - 力更轻柔:接触相平均切向形变 0.35(max 0.72);RDP 的 reactive 控制器常过度接触损坏传感器,平均 0.56(max 1.1)。→ OmniVTA 用"预测触觉作目标"调节运动,既稳触又防过力。 - 泛化:未见高度上,RDP 中度下降、其它基线大幅退化,而 OmniVTA 开环版就已超 RDP;换未见刀对切割几乎无影响 → 学到的是触觉相关结构而非记轨迹。 - 扰动:OmniVTA 全程最高,闭环远超开环 → RLTC 能快速恢复稳定接触。
5.3 组件分析与消融¶
(a) TactileVAE 重建(表IV,L2↓ / cos↑,六任务)
| 方法 | Wipe | Peel | Cut | Assembly | Grasp | Adjust |
|---|---|---|---|---|---|---|
| PCA | 0.091/0.810 | 0.085/0.430 | 0.109/0.400 | 0.071/0.720 | 0.036/0.600 | 0.069/0.560 |
| PointNet-AE | 0.059/0.910 | 0.067/0.850 | 0.062/0.840 | 0.058/0.900 | 0.028/0.750 | 0.047/0.760 |
| Ours | 0.038/0.930 | 0.033/0.880 | 0.031/0.940 | 0.022/0.910 | 0.011/0.720 | 0.017/0.850 |
L2 全面最低;唯一例外:Grasp 的 cos 0.720 < PointNet-AE 的 0.750(作者未单独解释,诚实标注)。
(b) TactileVAE 设计消融(表V,L2↓,三传感器)
| 设计 | GelSight-Mini | Tac3D-A1 | Xense-QN1 |
|---|---|---|---|
| w/o 隐式解码器 | 0.126 | 0.098 | 0.038 |
| w/ 位置嵌入 | 0.102 | 0.085 | 0.035 |
| w/o 空间特征图(单 token) | 0.107 | 0.084 | 0.071 |
| w/ 隐式解码器 | 0.047 | 0.058 | 0.034 |
隐式神经解码器 + 保留局部空间特征图(而非单一全局 token)是低分辨率传感器(GelSight 9×7)上提升最大的两点。
(c) 触觉预测精度(表VI,节选 L2_avg / cos_avg;我们 vs 基线 UVA/exUMI/KineDex/ForceMimic)
| 方法 | Wipe | Peel | Cut | Adjust | Assembly | Grasp |
|---|---|---|---|---|---|---|
| UVA[64] | 0.088/0.66 | 0.097/0.61 | 0.077/0.71 | 0.083/0.69 | 0.074/0.68 | 0.080/0.65 |
| exUMI[41] | 0.101/0.58 | 0.097/0.62 | 0.086/0.72 | 0.083/0.61 | 0.096/0.53 | 0.081/0.65 |
| KineDex[66] | 0.082/0.81 | 0.066/0.79 | 0.096/0.73 | 0.053/0.70 | 0.047/0.78 | 0.017/0.59 |
| ForceMimic[65] | 0.091/0.68 | 0.077/0.76 | 0.090/0.71 | 0.082/0.65 | 0.071/0.68 | – |
| Ours | 0.059/0.93 | 0.036/0.87 | 0.050/0.88 | 0.025/0.85 | 0.030/0.89 | 0.010/0.68 |
短/长时段(第 2/4/6 个 latent 帧 = 解码后第 8/16/24 帧)都最优;cos 相似度尤其大幅领先(方向一致性强)。
(d) 世界模型设计消融(表VII,L2↓/cos↑):动作表示用 2D 投影 > 3D 相对(0.056/0.88) > 3D 绝对(0.075/0.72)(未见位置上 2D 0.042/0.91 最好);动态加权 + 联合生成均有正贡献(Seen 位置:0.041/0.90 → +联合生成 0.038/0.92 → +动态加权 0.035/0.93)。
(e) 融合策略消融(表VIII,成功率 Wipe/Peel/Avg)
| 配置(预测长度/LTD/门控/视觉生成) | Wipe | Peel | Avg |
|---|---|---|---|
| 0 / × / × / × | 0.12 | 0.06 | 0.09 |
| 2 / × / × / × | 0.40 | 0.26 | 0.33 |
| 4 / × / × / × | 0.45 | 0.30 | 0.38 |
| 6 / × / × / × | 0.50 | 0.30 | 0.40 |
| 6 / ✓ / × / × | 0.57 | 0.36 | 0.47 |
| 6 / ✓ / ✓ / × | 0.66 | 0.40 | 0.53 |
| 6 / ✓ / ✓ / ✓(加视觉生成) | 0.70 | 0.38 | 0.54 |
① 预测触觉越长越好(0→6 步:0.09→0.40),证明"预测未来触觉"本身就涨点;② LTD 优于直接拼接(0.40→0.47);③ 门控比直接拼接 平均 +约 7%(0.47→0.53),且模态权重与接触状态强相关(无接触触觉权≈0,预测接触概率升则触觉权升);④ 加生成视觉特征几乎无增益(0.53→0.54),反而拖慢推理 → 最终只用当前视觉、丢弃生成视觉。
(f) 触觉预测精度对策略的影响(图16):把世界模型退化到 80/60/40/20% 预测性能,策略成功率随之显著下降(60% 时已估不准接触概率、模态加权错乱)。→ 准确触觉预测是策略可靠的关键前提。
(g) 推理耗时(表IX,RTX 4090D):慢策略 230ms;慢策略+视觉生成 480ms(翻倍,故弃用);快策略 3.5ms(支撑 60Hz 反射)。
6. 核心洞见¶
- "预测 + 反射"双系统是主张:慢系统用世界模型做前馈接触预测,快系统(RLTC)用预测+实测触觉做60Hz 反馈纠偏——把人类感觉运动控制的两件事工程化进一个策略。
- 世界模型的价值不在"生成像素"而在"提供未来触觉作目标/特征":训练时联合生成视觉帮收敛,推理却不用生成视觉、只预测触觉(省一半算力)——一个很务实的取舍。
- 数据分析反哺架构:从数据里量化出触觉的"空间局部性 + 接触驱动动态"两性质,直接落到 LTD 差分编码、动态感知加权损失、门控(接触前触觉权≈0)的设计上。
- 泛化来自触觉而非记轨迹:换未见刀/未见高度仍稳,说明学到的是接触相关结构。
7. 局限 / 存疑(诚实)¶
- 代码/数据/模型尚未发布(仅承诺 mrsecant.github.io/OmniVTA) → 复现性、数据集真实可得性待核;本卡证据级别仍为 B。
- 全为真机、无仿真对照;每个评测点样本量偏小(每物体 10 次 / 泛化每高度 5 次),绝对成功率对难任务仍不高(Peel 0.55、Assembly 0.60)。
- RLTC 依赖"每类任务的人类恢复段":要先估正常触觉分布、标异常态、抽恢复段 → 标注/数据工程成本不小,跨任务迁移性未验证。
- Grasp 的 TactileVAE 重建 cos(0.720) 反低于 PointNet-AE(0.750),作者未解释。
- 主力评测只用 Xense 一种传感器;多传感器泛化只在 TactileVAE/表征层面验证,未到真机策略层面。
- 慢策略 230ms(约 4Hz)规划——长程能力靠 60Hz 快策略插值/纠偏撑,规划频率本身偏低。
8. 对我们(深一层)¶
- 两流/联合视触觉世界模型的代表。OmniVTA "两流分别预测视觉与触觉未来"——是必读正面对照。与 卡片-VT-WM(视触觉世界模型)、卡片-TacForeSight / 详读-TacForeSight(触觉预测/前馈世界模型)同一战场,可三方对照:谁预测什么、在像素级还是 latent 级、预测怎么进策略。
- 残差差异点(供我们定位差异化):OmniVTA 偏条件生成(DiT 在 VAE latent 上扩散生成未来帧);若我们走纯 latent 预测/不生成像素,正好与它互补。它推理弃用生成视觉这一点,反过来支持"预测触觉 latent 才是策略真正需要的"——值得我们借鉴(别浪费算力生成视觉)。
- 机制可借:① LTD 差分编码(当前/预测/差分三拼)——把"预测未来触觉"变成策略可用特征的轻量做法;② 动态感知加权损失(动态权图+幅度权图)针对触觉稀疏激活;③ 慢-快 + 加权求和的反射纠偏范式(与 RDP / 卡片-AdapTac-PredictiveForceAttention 同源,但用"预测触觉作目标"防过力是其差异化卖点)。
- 数据集设计可借:跨本体(臂+手持 UMI)同构末端、多传感器、严格时间戳对齐 + human-in-the-loop、按"物理接地的接触模式"而非视觉外形分类任务——这套数据方法论对我们自建视触觉数据有参考价值(参 卡片-LaWAM / 详读-LaWAM 同库其它世界模型路线)。
- 对照"省触觉"路线:OmniVTA 是"加高频触觉 + 预测"把接触做精;另一类思路用更少/更廉价的力触觉,两条路线可对照(同 详读-TacForeSight 的对照逻辑)。