详读 · LaWAM(隐空间世界-动作模型 / Latent World Action Model)¶
卡片版见 卡片-LaWAM。本页是全文精读:动机 → 方法(逐模块讲直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2606.15768(2026-06-14, cs.RO)· 项目页/开源未发现 作者:Jialei Chen、Kai Wang、Chao Yu(通讯)、Yuanbo Xu(通讯) 等(清华 + 吉大 + 南开 + 北大 + 哈工大 + 中关村学院 + Striding.AI + Infinigence/无问芯穹)
0. 一句话定位¶
主流 latent-action 预训练(LAPA、UniVLA 等)训出一个"逆动力学编码器"拿到潜动作 z,然后把配套的前向 decoder 扔掉。LaWAM 的核心洞见——这个 decoder 本身就是一个现成的、以潜动作为条件的世界模型。把它留下来叫 LaWM,用它一次前向把策略预测的潜动作展开成"隐视觉子目标"(未来观测的 DINO 特征),再拿这个子目标去条件化动作生成。于是:既不生成像素、也不迭代 rollout,又快又准——LIBERO 98.6%、187ms/动作块、比像素级世界模型快至 24×。
1. 问题与动机¶
- VLA 的盲点:VLA(OpenVLA、π0、GR00T 等)把大规模图文预训练迁到动作生成,语义很强(知道"该做什么"),但只从当前视觉-语言上下文直接预测动作,不显式建模"场景在候选动作下会怎么变"(缺乏 foresight)。
- 世界-动作模型(WAM)补这一刀,但三个低效:
- 像素冗余:很多 WAM 去预测未来图像/视频,把大量算力花在像素合成上,而不是紧凑的、与动作相关的动力学。
- 迭代延迟爆炸:迭代式未来生成很慢——同一评测设定下 LingBot-VA 单次策略推理要 4482ms,而代表性 VLA π0.5 只要 220ms。
- 粒度不对:对操作而言,有用的"未来"应是下一个动作块对应的那点场景变化,而不是"视觉上看起来合理的整段未来视频"。
- LaWAM 的切入:保留 WAM"以未来为条件"的结构,但把"未来"表示在冻结视觉编码器的特征空间里——预测一个紧凑的隐子目标,绕开昂贵/迭代的像素生成。
2. 核心思想:把"被丢弃的 decoder"捡回来当世界模型(图2)¶
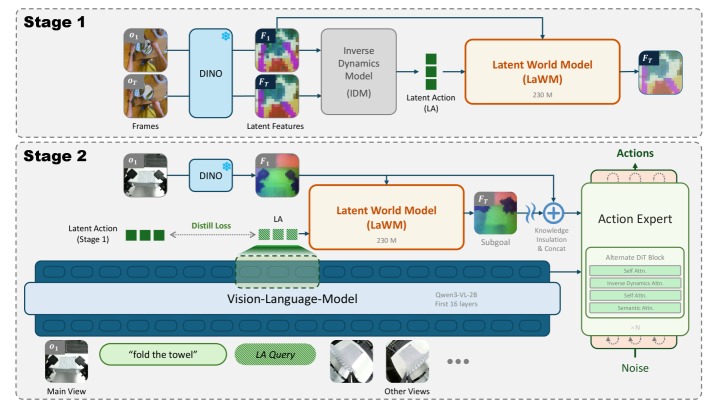
- latent action model (LAM) = 一个逆动力学编码器(从"当前帧→未来帧"的转移里推断潜动作 z)+ 一个前向 decoder(给定当前隐状态和 z,预测未来隐状态)。
- 以前的 latent-action VLA(LAPA/UniVLA 这类)只把 LAM 当成"学跨形态动作表示"的辅助件,预训练完就把 decoder 丢了。
- LaWAM 反其道:decoder 才是宝——它实现的就是"以潜动作为条件的世界模型"。留下来叫 LaWM,让它把潜动作展开成未来观测特征,作为动作生成的隐视觉子目标。(作者注:Garrido et al. 的并行工作也观察到"LAM 的 decoder 即一个潜动作世界模型"。)
3. 方法详解¶
3.1 问题形式化(为什么要"先预测潜动作")¶
- 记当前观测
o、指令l、动作块a₁:T(固定物理时长 τ)。标准 VLA 直接建p(a₁:T | o, l)。 - WAM 的通用分解(式1):
| 项 | 公式 | 含义 |
|---|---|---|
| 联合 | p(a₁:T, o_T \| o, l) |
同时预测未来观测+动作 |
| 未来预测 | = p(o_T \| o, l) |
先想象未来 |
| 逆动力学 IDM | · p(a₁:T \| o, o_T) |
由"想要的未来画面"反推动作 |
- 像素级 WAM 卡在"
p(o_T|o,l)要生成稠密未来图像/视频"。LaWAM 把未来表示在冻结编码器 fψ 的特征空间:u=fψ(o)、u_T=fψ(o_T)。 - 训练时学一个 latent-action 模型(式2):
z ~ qφ(z|u, u_T)(潜动作后验=隐空间逆动力学),ũ_T = LaWM_ω(u, z)(decoder 预测未来特征)。 - 推理时没有未来特征
u_T,所以策略必须先预测潜动作,再让 LaWM 解出子目标。于是动作生成被分解为(式3):
| 项 | 公式 | 角色 |
|---|---|---|
| 策略先验 | p_θ(ẑ \| o, l) |
从当前看,先猜潜动作 ẑ |
| LaWM | · p_ω(û_T \| u, ẑ) |
一次前向把 ẑ 展开成隐子目标 û_T(确定性 decode) |
| 动作专家 | · p_η(a₁:T \| o, l, u, û_T) |
在"当前+预测未来"双上下文下出动作块 |
直觉:潜动作 z 是"抽象的转移意图",LaWM 把它落地成"当前这个本体/场景下未来该长什么样"的具体特征。单用潜动作当策略接口偏弱,经 LaWM 展开成"接地的隐子目标"才好用(§4.4 的跨本体实验正是这一点的证据)。
3.2 Stage 1:训 LaWM(隐空间世界模型)¶
- 每个训练样本:当前观测
o与间隔物理时长 τ 后的未来观测o_T,编码成(u, u_T)。IDM 编码器推z ~ qφ(z|u,u_T);decoder 用(u, z)预测ũ_T。 - 目标函数(式4):
L_LAM = L_wm + L_aux + β·D_KL(qφ(z|u,u_T) ‖ N(0,I)) L_wm = ‖ũ_T − u_T‖²:让 decoder 预测的未来特征对上真未来特征(这是 LaWM 的本职)。L_aux = ‖g(s,z) − s_T‖²:一个轻量预测器 g 用"当前末端状态 s + 潜动作 z"去预测未来末端状态 s_T → 逼 z 编码"具身运动"而非只是视觉外观变化。训完即丢弃这个辅助头。- KL 正则:把潜动作空间规整到可被 Stage2 策略先验建模。β=1e-5(很小)。
- 关键设计:用同一个物理时长 τ 定义
u_T和s_T→ 学到的子目标对应"固定的真实流逝运动量",而不是"数据集特定的帧偏移"。这是后面混频对齐的地基。 - 架构(附录C.1):在冻结 DINOv3 ViT-B/16 特征上工作;IDM 编码器和 decoder 都是 24 层 transformer;编码器走 V-JEPA2 式时空设计(把当前/未来帧 patch 拍平成一条 token 序列联合处理)。decoder 用 adaptive LayerNorm (adaLN) 把 z 注入,而非 Genie 那种加法注入——作者发现跨本体设定下加法注入会让"潜动作范数波动→视觉 token 全局漂移→loss 尖峰",adaLN 更稳。
3.3 Stage 2:训 LaWAM(把 LaWM 变成测试期策略接口)¶
- 部署时不能用 Stage1 的 IDM 编码器(它要未来特征
u_T)。所以训一个策略先验p_θ(ẑ|o,l)从当前观测+指令预测潜动作,再过 预训练好的、被冻住的 LaWM 解出û_T——给策略一个"未来视觉的隐预测",不生成任何像素。 - 动作专家 = Alternate-DiT:一条流携带 VLM 主干的语义上下文,另一条流携带由
(u, û_T)组成的潜动力学上下文;交替处理两条流,让专家在去噪动作块时把"任务意图"和"预测的场景演化"结合。
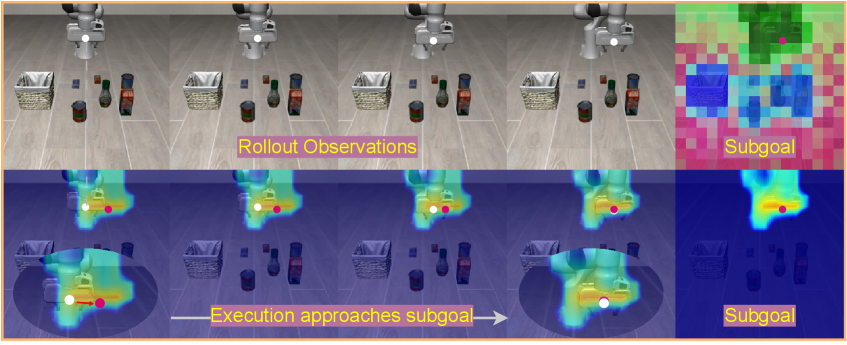
- Stage2 目标(式5):
L_LaWAM = λ_distill·L_distill + λ_wm·L_wm + L_act L_distill = E‖ẑ − z‖²:latent-action 蒸馏——用 Stage1 LAM 后验的 z 当 teacher,逼策略先验预测的 ẑ 对齐。让策略学会"正确驱动 LaWM"。L_wm = ‖û_T − u_T‖²:监督策略驱动下的子目标。L_act:动作块的条件流匹配(flow-matching)损失。- λ_distill = λ_wm = 0.1。
- Knowledge Insulation (KI):阻止动作专家的梯度回流污染已预训练的 LaWM 动力学(即 LaWM 既要被对齐的潜动作"驱动",又要被"保护"不被 action-expert 梯度覆盖)。消融证实这一招重要。
- 架构(附录C.2):VLM 主干 = Qwen3-VL 前 16 层;动作专家 = 4 个 Alternate-DiT 块(共 16 层 transformer);hidden dim 1024。输入序列 = 主视图观测 + 指令 + latent-action query tokens + 可选辅助视图 + action-query tokens,配因果注意力掩码:latent-action query 聚信息去驱动 LaWM,action query 仍能 attend 全语义上下文。RGB-only、图像 256×256、不喂本体状态(proprioception)——作者引文献称去掉本体状态可避免过拟合到轨迹特定状态、提升空间泛化。
3.4 混频对齐:物理时间编码(附录C.3,被低估的工程点)¶
- 不同数据集/本体的控制频率不同,同一个"动作 token 索引"对应的真实流逝时间不一样。
- 做法:每个分支保持原生控制频率,但每个动作块由固定物理时长 τ 定义。分支 b 的离散动作步数
H_b = round(τ·h_b)(式6)——5Hz 分支 token 比 20Hz 少,但都对齐到同一物理时长 τ 后的未来视觉状态。 - 再给每个动作 token 加正弦物理时间编码
φ(t_{b,i}),其中t_{b,i}=i/h_b(式7)→ "相同流逝时间的 token 拿相同时间码,相同索引但频率不同的 token 拿不同码"。 - 受控实验(附录C.4, 图7):把 20Hz LIBERO 降采样出 10Hz/5Hz 一起 co-train。不加物理时间编码会显著掉点;加上后几乎恢复到 20Hz-only 上界。证明它确实解决了混频歧义。
4. 实验¶
4.1 设置¶
- 预训练数据:约 3,000 小时机器人视频 + 1,500 小时第一人称人类视频(EgoDex、Ego4D、AgiBot-World、RoboMIND、RoboCoin、Open X-Embodiment、DROID 等开源数据)。人类视频只通过 LaWM 的动力学先验贡献,不直接参与策略整合(因为常缺任务描述)。
- 训练算力:LaWM = 16× H100 / 100k 步(AdamW, lr 3e-4, wd 1e-2, batch 1024, β=1e-5;τ=机器人 1.2s / 人类 0.4s)。策略整合预训练 = 64× H100 / 200k 步(batch 1024;动作专家 lr 1e-4、其余 3e-5)。各基准再 post-train。
- 延迟测量:A100 上跑 1000 次重复动作块预测取均值;默认 10 步去噪。WAM 参数计数不含 video-diffusion 的 VAE 和文本编码器(可达 10B)。
4.2 LIBERO(4 套件,每任务 50 试 / 共 2000 试、40 任务)¶
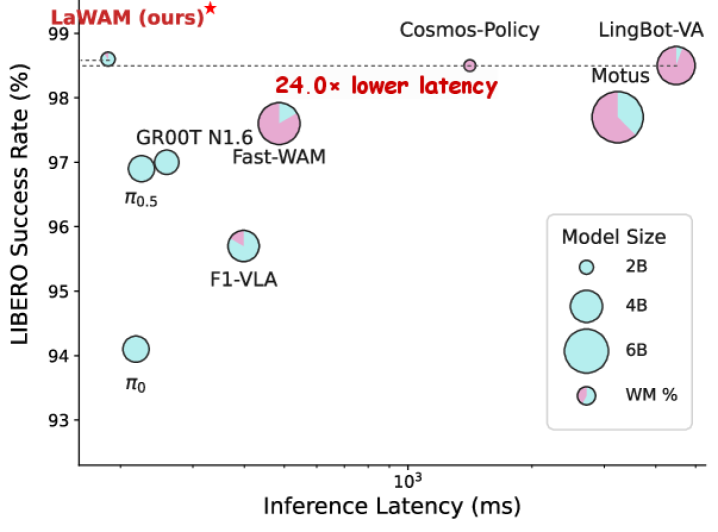
| 方法 | 类别 | 规模 | 延迟(ms) | Long | Goal | Object | Spatial | 均值 |
|---|---|---|---|---|---|---|---|---|
| OpenVLA-OFT | 主流VLA | 7B | — | 94.5 | 97.9 | 98.4 | 97.6 | 97.1 |
| π0 | 主流VLA | 3.5B | 220 | 88.4 | 94.4 | 96.8 | 98.0 | 94.4 |
| π0.5 | 主流VLA | 3.5B | 220 | 92.4 | 98.0 | 98.2 | 98.8 | 96.9 |
| GR00T-N1.6 | 主流VLA | 3.3B | 259 | 94.4 | 97.5 | 98.5 | 97.7 | 97.0 |
| LAPA | 潜动作 | 7B | — | 55.4 | 58.8 | 74.6 | 73.8 | 65.7 |
| UniVLA | 潜动作 | 7B | — | 92.0 | 95.6 | 96.8 | 96.5 | 95.2 |
| Mantis | 潜动作 | 5.8B | — | 94.2 | 94.4 | 99.2 | 98.8 | 96.7 |
| VLA-JEPA | 潜动作 | 3B | — | 95.8 | 97.2 | 99.6 | 96.2 | 97.2 |
| F1 | 像素WAM | 4B | 399 | 91.3 | 95.4 | 97.8 | 98.2 | 95.7 |
| Motus | 像素WAM | 8B | 3231 | 97.6 | 96.6 | 99.8 | 96.8 | 97.7 |
| Cosmos-Policy | 像素WAM | 2.1B | 1413 | 97.6 | 98.2 | 100.0 | 98.1 | 98.5 |
| LingBot-VA | 像素WAM | 5.5B | 4482 | 98.5 | 97.2 | 99.6 | 98.5 | 98.5 |
| Fast-WAM | 像素WAM | 6B | 486 | 95.2 | 97.0 | 100.0 | 98.2 | 97.6 |
| LaWAM | 隐WAM | 2.3B | 187 | 97.0 | 98.4 | 99.6 | 99.4 | 98.6 |
读法:LaWAM 以 2.3B / 187ms 拿下最高均值 98.6%。和它打平的 Cosmos-Policy(98.5)/LingBot-VA(98.5) 延迟分别是 1413ms / 4482ms(慢 7.5×/24×)。比潜动作基线(VLA-JEPA 97.2、UniVLA 95.2)高 → 作者解读:紧凑的动作 token 被展开成空间结构化的隐视觉子目标后才更有效。
4.3 RoboTwin 2.0(双臂协同, 50 任务, 每任务 100 试, clean/随机两设定)¶
摘录 Table 2/4 部分任务 + 全表均值(Fast-WAM、LingBot-VA 用其开源权重在 H100 重测;其余取自 Fast-WAM / GigaWorld-Policy 原文):
| 任务 | Fast-WAM C/R | GigaWorld C/R | LingBot-VA C/R | π0.5 C/R | Motus C/R | LaWAM C/R |
|---|---|---|---|---|---|---|
| Move Can Pot | 95/92 | 76/78 | 93/93 | 51/55 | 34/74 | 98/93 |
| Move Stapler Pad | 84/63 | 92/82 | 59/71 | 56/42 | 83/85 | 94/87 |
| Open Laptop | 100/100 | 96/98 | 96/90 | 90/96 | 95/91 | 100/100 |
| Hanging Mug | 65/56 | 16/12 | 21/33 | 18/17 | 38/38 | 51/43 |
| Place Container Plate | 98/100 | 98/96 | 97/98 | 99/95 | 98/99 | 100/100 |
| Scan Object | 96/86 | 60/64 | 90/89 | 72/65 | 67/66 | 96/90 |
| Stack Bowls Two | 90/96 | 96/92 | 98/99 | 95/96 | 98/98 | 100/99 |
| Open Microwave | 46/34 | 74/66 | 56/80 | 34/77 | 95/91 | 41/43 |
| Turn Switch | 66/56 | 82/84 | 54/57 | 62/54 | 84/78 | 47/56 |
| 50 任务均值 | 91.98/90.52 | 86.36/85.04 | 91.50/90.92 | 82.74/76.76 | 88.66/87.02 | 92.64/89.80 |
读法:LaWAM clean 均值 92.64 最高(超 Fast-WAM 91.98、LingBot-VA 91.50);随机场景 89.80 略低于 Fast-WAM 90.52、LingBot-VA 90.92,但很接近。摘要里"RoboTwin 91.22%"= clean/rand 两均值的平均 (92.64+89.80)/2。也有短板任务:Open Microwave、Turn Switch、Hanging Mug 明显弱于个别基线(Motus 在微波炉/开关上更强)→ 不是每个任务都第一。
4.4 真机(30 试/任务, 两平台:Franka Panda 单臂 + Quanta X1 双臂)¶

| 方法 | Pick-and-Place | Open Drawer | Fold Towel | 均值 |
|---|---|---|---|---|
| π0.5 | 86.7 | 80.0 | 83.3 | 83.3 |
| GR00T-N1.6 | 83.3 | 76.7 | 46.7 | 68.9 |
| Fast-WAM | 56.7 | 63.3 | 70.0 | 63.3 |
| LingBot-VA | 76.7 | 83.3 | 0.0 | 53.3 |
| LaWAM | 93.3 | 86.7 | 90.0 | 90.0 |
读法:LaWAM 三任务全第一、均值 90.0%。最亮的是叠毛巾(长程、可形变、需对布料动态及时响应):高延迟的 LingBot-VA 在生成下一动作时毛巾还在动 → 动作对不上当前布料状态 → 0.0%(彻底失败)。这是"低延迟世界模型"价值的最直观证据。任务设置含分布外初始构型(probe 空间泛化);不喂本体状态也意在提升空间泛化。
4.5 LaWM 动力学分析:它真在建模动力学, 不是摆设¶

- 图10(500 条轨迹聚合):rollout 预测的未来特征与真未来的余弦相似度始终高(蓝),与初始状态的相似度逐步下降(绿) → LaWM 在建模非平凡的隐动力学,没有偷懒"复制当前帧"。
- 图5(跨本体开环 rollout):从源视频抽一条潜动作轨迹,只给目标环境/本体一帧初始观测,套用同一组潜动作就能生成"上下文特定"的隐 rollout(含未见截图)。→ 说明潜动作捕捉的是与本体无关的视觉转移,而 LaWM 用当前隐状态把它接地到具体本体。这也解释了"为什么单用潜动作当策略接口偏弱、要经 LaWM 展开成子目标"。
4.6 消融(图6, LIBERO)¶
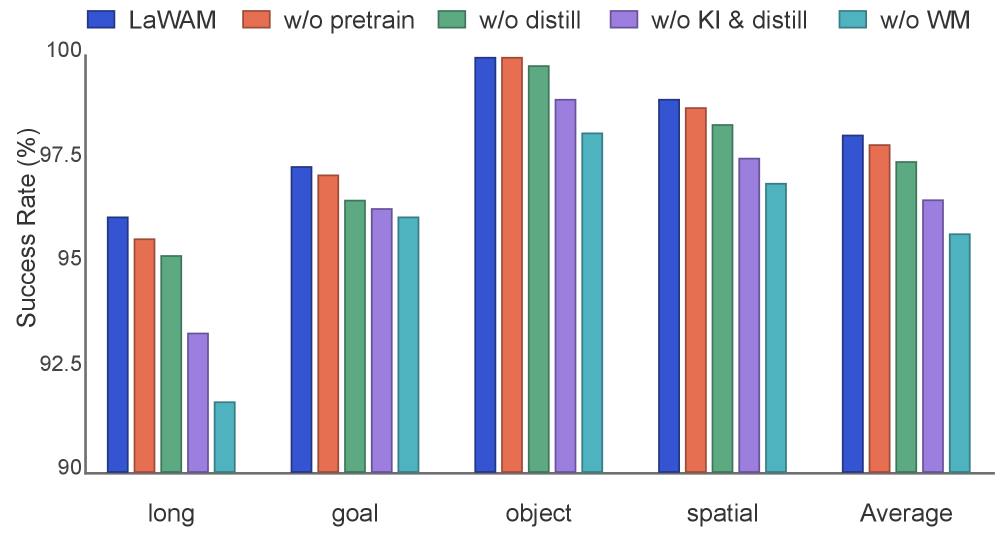
- 去掉 LaWM(w/o WM)掉点最多,尤其 LIBERO-Long → "显式隐子目标条件"是主要增益来源,不是参数堆出来的。
- 去掉 latent-action 蒸馏也明显伤性能 → 策略需要 LAM 后验的直接监督才能可靠驱动 LaWM。
- w/o KI & distill 进一步退化 → LaWM 既要被对齐潜动作驱动、又要被保护不被动作专家梯度覆盖。
- 去预训练(w/o pretrain)也降 → 预训练有用。
5. 诚实读数 / 局限(论文 §5 + 表里能读到的)¶
- 怕相机运动(作者自己点的硬约束):当相机自身运动主导观测变化(第一人称剧烈抖动、视角大跳变)时,LaWM 学不出连贯的潜动作空间。→ 当前形态不适合人形/移动机器人(其观测被自运动强烈塑形)。
- 可形变物体分辨率不足:LaWM 当前特征分辨率不够精,细微布料形变难以可靠建模(虽然叠毛巾仍拿 90%,靠的是"准确预测机械臂子目标"而非精建布料)。
- 不是每个指标都第一:RoboTwin 随机场景均值(89.80)略低于 Fast-WAM/LingBot-VA;Open Microwave/Turn Switch/Hanging Mug 等任务弱于个别基线。卖点是"高成功 + 低延迟 + 小世界模型"的综合,不是处处屠榜。
- 开源未确认:未发现项目页/代码仓库 → 复现性待定;目前主要能借思路,不一定拿得到模型。
- 规格中"待核"项(正文未给、勿当结论):Jetson 部署、30Hz、TensorRT、显存占用等均非论文原文,属推断或外部说法(详见卡片的"分三档重标")。
6. 核心洞见¶
- 真正聪明的是方法/洞见,不是 187ms:效率是结果,关键一步是"repurpose 被丢弃的 LAM decoder 作 LaWM"——一个几乎免费的、以潜动作为条件的世界模型。
- 一步非迭代 = 24× 延迟优势的来源:相对像素级 WAM 反复 rollout 未来帧,LaWAM 每个动作块只一次前向出一个隐子目标。
- 在"语义指令跟随"与"物理接地控制"之间,未来预测可以只是一个紧凑的隐接口——不必重建像素。
- 物理时间编码让混频多源数据可以一起训而不打架,是个被低估的工程贡献。
7. 对我们(深一层)¶
- 视觉那条腿:LaWAM 是视觉隐空间一步预测世界模型,与触觉侧的 卡片-TacForeSight 同构,视觉/触觉两条隐空间路线天然可对照。两者同构:隐空间一步预测 + 小推演器 + gating/条件化。对照细节见 TacForeSight×LaWAM-对照。
- decoder 废物利用思路可迁移:触觉侧是否也有"训完被扔的模块"能当世界模型?值得想(参 卡片-VT-WM、卡片-OmniVTA 视触觉世界模型路线)。
- 相机自运动是公认难点:LaWAM 明说没解决自运动下的潜动作学习——这是该范式落到移动/人形平台前必须先解决的问题。
- 谱系关联:latent-action 一脉承自 卡片-LAPA(LAPA 把 decoder 丢了,LaWAM 捡回来);架构基础见 概念-模型架构基础(Qwen-GR00T 式 VLM 主干 + Alternate-DiT 动作专家 + flow matching)。基线里的 卡片-π0.5、卡片-GR00T-N1 是本库已有卡片;评测口径见 基准-LIBERO。
- 数据视角:3000h 机器人 + 1500h 人类视频,人类视频只喂 LaWM 动力学先验——"无动作标注的人类视频也能贡献世界模型"这条路与 概念-机器人数据与标注 相关。
8. 来源¶
- arXiv 2606.15768(全文精读 2026-06-29)· 本地
papers/LaWAM-2606.15768.pdf - 图均取自 arXiv HTML v1(
assets/lawam/x{1,2,3,4,6,10}.png)