详读 · Equivariant Diffusion Policy(把 SO(2) 等变性灌进扩散策略)¶
卡片版见 卡片-EquivariantDiffusionPolicy。本页是全文精读:动机 → 方法(逐模块+表示论直觉) → 实验(全表) → 局限/外评/审稿人视角 → 对我们。 来源:arXiv 2407.01812 v3(2024-10-15)· 项目页 · 代码 · OpenReview 作者:Dian Wang¹、Stephen Hart²、David Surovik²、Tarik Kelestemur²、Haojie Huang¹、Haibo Zhao¹、Mark Yeatman²、Jiuguang Wang²、Robin Walters¹、Robert Platt¹²(¹东北大学 Northeastern,²Boston Dynamics AI Institute)
⚠️ 术语纠正:本工作用的是 SO(2)(绕世界系 z 轴/重力轴的平面旋转)对称性,不是 SO(3)。它的贡献恰恰是把这个 SO(2) 对称性用在完整 6-DoF / SE(3) 闭环动作空间里(前人只用在 SE(2) 闭环或 SE(3) 开环)。下文一律按论文写 SO(2)。
0. 一句话定位¶
在 Diffusion Policy 的去噪网络里嵌入 SO(2) 等变结构(用 escnn 的可操控 CNN/等变 MLP 实现),让"去噪函数"自带"旋转任务→旋转动作"的归纳偏置。结果:MimicGen 12 任务、100 条演示下平均成功率比基线 Diffusion Policy 高 21.9%,且200 条演示就追平所有基线的 1000 条演示——数据效率是核心卖点。
1. 问题与动机(图1)¶
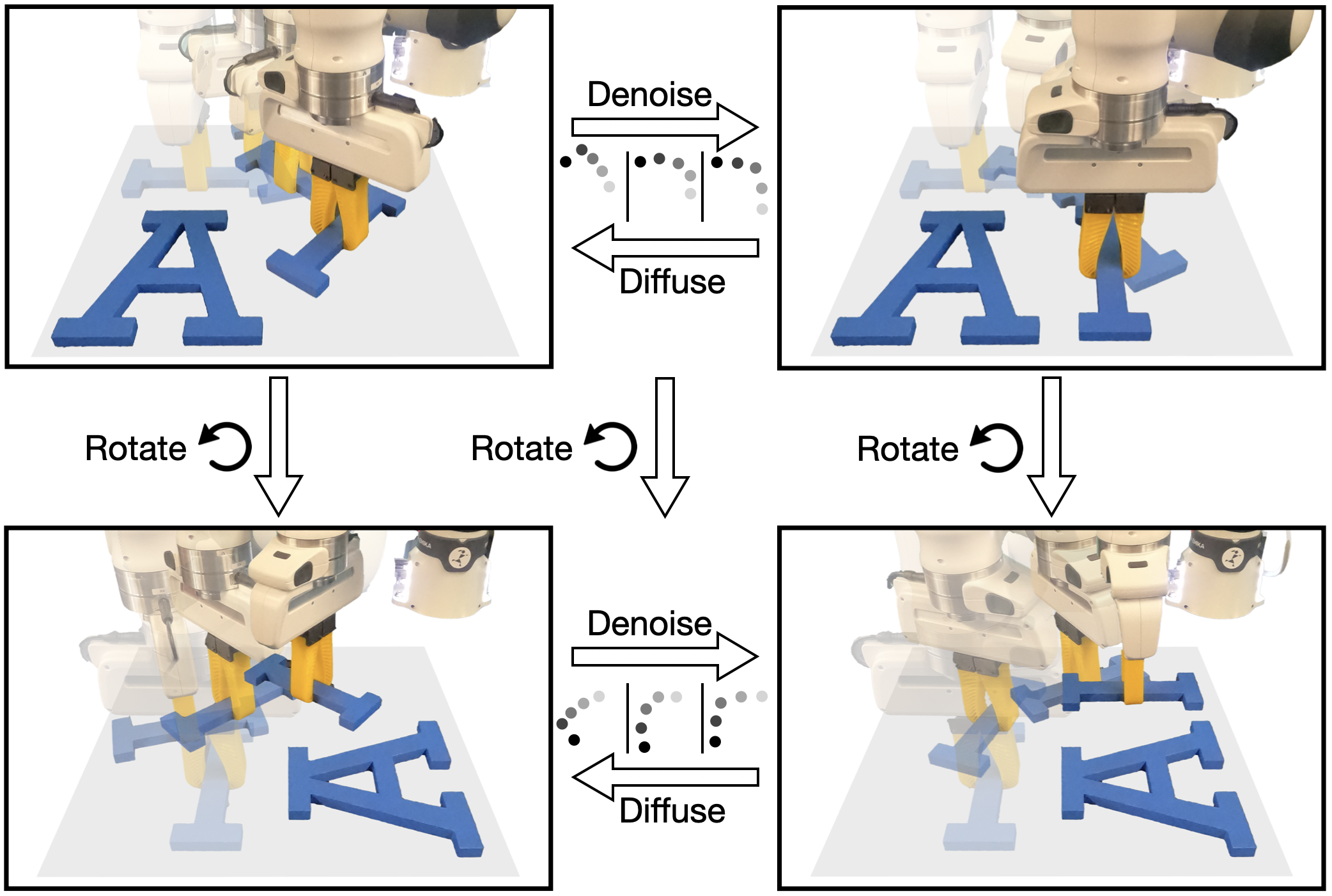
- Diffusion Policy 把动作预测建模成"条件去噪",能抓多模态分布、常胜过基线,但致命缺点:要学的是去噪函数
(s, a+εₖ, k) ↦ εₖ,对所有 k 和所有噪声 εₖ 都要拟合——比直接学显式策略s↦a难得多、更吃数据。 - 机器人操作天然有几何对称性:把桌面场景绕重力轴转一个角度,专家轨迹也应跟着转(图1)。把这个对称性当成网络的硬约束,去噪函数就更好学、更省样本、泛化更好。
- 切入点:等变扩散此前只在分子生成 [Hoogeboom]、规划 [EDGI]、开环 SE(3) 操作 [Diffusion-EDFs] 里做过;本文是第一个把等变性引入"视觉运动闭环策略学习(visuomotor policy)"的扩散过程。
四点贡献:① 提出 Equivariant Diffusion Policy(基于等变扩散的 BC 方法);② 分析"去噪函数在什么条件下等变";③ 在 6-DoF 控制里理论化 SO(2)-等变(前人 [SO(2)-RL]、[SEIL] 只用在表达力更弱的 SE(2));④ 仿真(MimicGen 12 任务)+真机(6 任务)充分验证。
2. 理论:去噪函数何时等变¶
命题 1(核心理论支点):设专家策略 π:o↦a、对应的真值噪声预测函数 ε:(o,aₖ,k)↦εₖ,且 g∈SO(2) 作用在噪声上的方式与作用在动作上一致。当专家策略本身 SO(2)-等变(π(go)=gπ(o))时,噪声预测函数 ε 也 SO(2)-等变(ε(go,gaₖ,k)=gε(o,aₖ,k))。
- 含义:既然真值去噪函数等变,那用等变网络去拟合它就有正确的归纳偏置——这是用等变网络的合法性依据(证明见附录 A,靠 π 等变 + ε 线性逐步代换)。
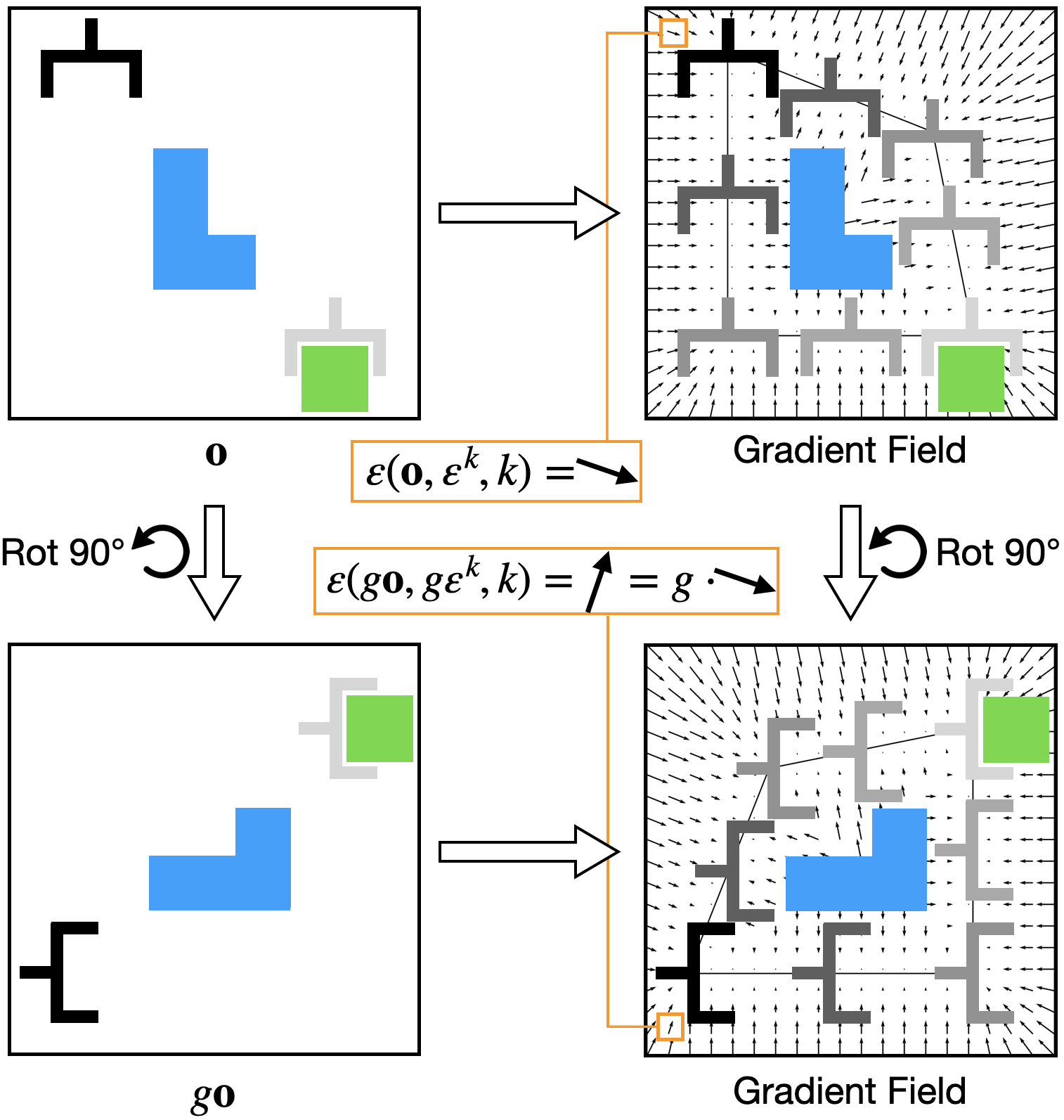
直觉(图2):把动作空间里每个点的 ε 都画出来,就得到一个"指向专家轨迹的梯度场"。专家策略等变 ⇒ 这个梯度场整体等变 ⇒ ε 等变。
3. 方法:SO(2) 如何作用在 6-DoF 动作上¶
表示论速记(论文用到 SO(2) 及其离散子群 Cᵤ 的三种表示):
- 平凡表示 ρ₀:作用在不变标量上(如夹爪开合宽度),ρ₀(g)x=x。
- 不可约表示 ρ_ω:作用在 2D 向量上的频率为 ω 的旋转矩阵(ρ₁=普通 2D 旋转,ρ₂=2 倍角旋转)。
- 正则表示 ρ_reg:Cᵤ 通过 u×u 置换矩阵循环移位(网络内部 embedding 用这个)。
命题 2:存在不可约表示刻画 SO(2) 如何作用在 SE(3) 夹爪动作 aₜ 上。
- 绝对位姿控制(position control,Tₜ₊₁=Aₜ):按列展平位姿 aₜ=Vec_c(Aₜ),则 g·aₜ=(ρ₁⊕ρ₀²)⁴(g)·aₜ。用 6D 旋转表示 [Zhou] 简化后,动作向量 = R⁶(6D 旋转) × R³(平移) × R(开合),群作用为 (ρ₁³⊕(ρ₁⊕ρ₀)⊕ρ₀)(g)。
- 相对位姿控制(velocity control,Tₜ₊₁=AₜTₜ):g 同时作用于当前位姿和位姿增量 ⇒ gAₜ=TgAₜTg⁻¹(共轭)。按行展平 Vec_r,求解 16×16 的 ρ_A 并经定基变换 P 块对角化为 P⁻¹(ρ₀⁶⊕ρ₁⁴⊕ρ₂)(g)P(推导见附录 B/C;分解 SE(3)=SO(3)×R³ 后旋转部分得 ρ₀³⊕ρ₁²⊕ρ₂,再加平移 ρ₁⊕ρ₀、开合 ρ₀ ⇒ ρ_a=ρ₀⁵⊕ρ₁³⊕ρ₂)。
- 关键点:相对控制下出现了频率 2 的表示 ρ₂(因为共轭让旋转分量"转两次"),所以网络输出必须支持 ρ₂——这正是等变网络相比简单数据增广能精确刻画的地方。
4. 网络实现(图7)¶
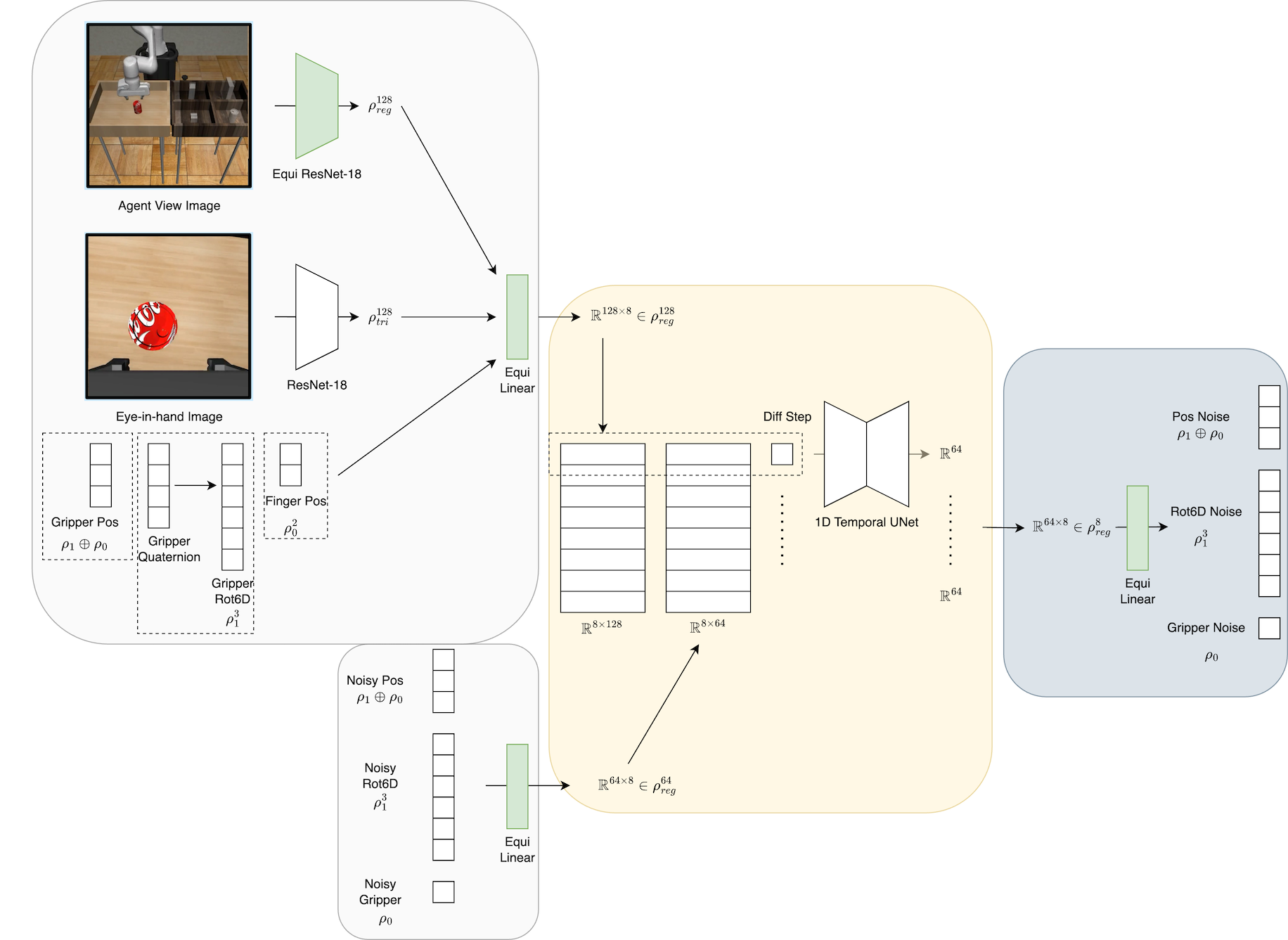
用 escnn 库实现,群取 C₈(8 个离散旋转)。三段式:
- 编码:① agent-view 图 → 等变 ResNet-18 出 128×8 正则表示;② 手眼(eye-in-hand)图 → 普通 ResNet-18(手眼图旋转不变,用平凡表示)出 128 维;③ 夹爪状态(位置 ρ₁⊕ρ₀、6D 朝向 ρ₁³、双指位置 ρ₀²)。拼成混合表示 → 等变 Linear → 128×8 正则表示观测 embedding;噪声动作经等变 Linear → 64×8 动作 embedding。
- 去噪:把观测/动作 embedding 中对应同一群元素 g 的那一片配对 zg=U(e_o^g, e_aₖ^g, k),喂同一个 1D Temporal UNet(隐藏维 [512,1024,2048],沿用 Diffuser/DP)。对所有 8 个 g 共享同一 UNet ⇒ 输出天然是正则表示的等变噪声 embedding。
- 解码:等变 Linear 解出噪声 εₖ。
- voxel 版:agent-view 图换成 4×64³ voxel 网格(1 通道占用 + 3 通道 RGB),等变 ResNet 换成 8 层 3D 等变卷积编码器,UNet 隐藏维 [256,512,1024]。voxel 版好处:voxel 旋转与真值状态旋转严格对齐(图像版因 agent-view 非正上方俯视而有"对称性错配")。真机版去掉手眼图、只用 voxel。
5. 实验¶
5.1 设置¶
- 仿真:MimicGen [11] 12 个操作任务,分别用 100 / 200 / 1000 条演示训练;报告训练全程 50 次评估的最高成功率,3 个随机种子平均。
- 基线:DiffPo-C(原始 Diffusion Policy,1D UNet,与本方法同 UNet 但无等变结构)、DiffPo-T(Transformer 版)、DP3(3D Diffusion Policy,PointNet 编码点云)、ACT(Action Chunking Transformer / CVAE)、BC RNN。voxel 版与 DP3 用 4 相机 3D 输入;图像版与其余基线用 2 相机 RGB。
- 真机:Franka Emika + fin-ray 软指 + 3× Realsense D455;3DConnexion 6-DoF 鼠标采演示,5Hz 记录;评估用 DDIM 16 步去噪。
5.2 仿真主结果(绝对位姿控制,节选自表 1/6;数字真实)¶
成功率(%),括号内为相对最佳基线的差值;EquiDiff(Vo)=voxel 版,EquiDiff(Im)=图像版:
| 任务 | demos | EquiDiff(Vo) | EquiDiff(Im) | DiffPo-C | DP3 | ACT |
|---|---|---|---|---|---|---|
| Stack D1 | 100 | 99 (+23) | 93 | 76 | 69 | 35 |
| Stack Three D1 | 100 | 75 (+37) | 55 | 38 | 7 | 6 |
| Square D2 | 100 | 39 (+31) | 25 | 8 | 7 | 6 |
| Threading D2 | 100 | 39 (+22) | 22 | 17 | 12 | 10 |
| Three Pc. Assembly D2 | 100 | 37 (+33) | 15 | 4 | 0 | 0 |
| Coffee Preparation D1 | 100 | 80 (+15) | 77 | 65 | 10 | 32 |
| Hammer Cleanup D1 | 100 | 70 (+16) | 65 | 52 | 54 | 38 |
| Pick Place D0 | 100 | 58 (+23) | 42 | 35 | 12 | 7 |
Hammer Cleanup D1 是唯一绝对控制下 voxel 版没拿全场最好的任务(在 1000 demos 时 DP3 达 86.7 更高)。
5.3 12 任务平均(表 2;核心数字)¶
| 控制 | 方法 | 100 demos | 200 demos | 1000 demos |
|---|---|---|---|---|
| Abs | EquiDiff (Vo) | 63.9 (+21.9) | 72.6 (+14.8) | 77.9 (+6.5) |
| Abs | EquiDiff (Im) | 53.7 (+11.7) | 68.5 (+10.7) | 79.7 (+8.3) |
| Abs | DiffPo-C | 42.0 | 57.8 | 71.4 |
| Abs | DiffPo-T | 29.0 | 43.0 | 64.9 |
| Abs | DP3 | 23.9 | 35.1 | 56.8 |
| Abs | ACT | 21.3 | 38.2 | 63.3 |
| Rel | EquiDiff (Vo) | 48.8 (+15.5) | 58.0 (+10.7) | 70.2 (-0.1) |
| Rel | EquiDiff (Im) | 35.4 (+2.1) | 50.4 (+3.1) | 74.0 (+3.7) |
| Rel | DiffPo-C | 33.3 | 47.3 | 63.2 |
| Rel | BC RNN | 22.9 | 41.2 | 70.3 |
样本效率铁证:EquiDiff(Vo) 用 200 demos(72.6)就超过所有基线用 1000 demos 的成绩(最高 DiffPo-C 71.4)。低数据区优势最大,数据越多差距越小(符合直觉:数据多了基线也能覆盖更多位姿)。 相对控制下图像版几乎无优势(+2.1/+3.1/+3.7),voxel 版仍明显领先——印证"图像旋转与真值旋转错配"会吃掉等变收益。
5.4 等变性强弱与收益的关系(图5)¶

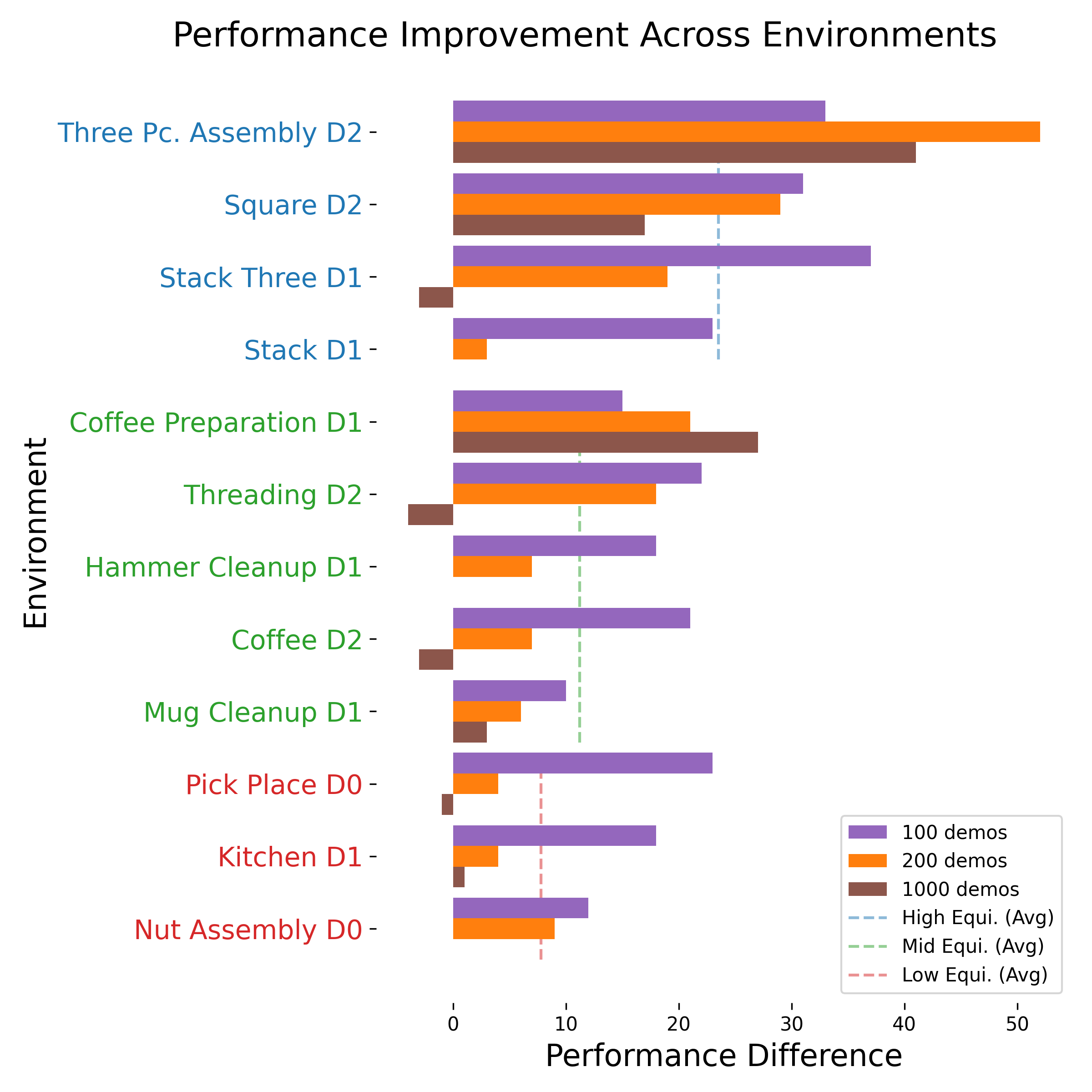
把任务按初始物体位姿随机程度分三档:高等变(工作区内完全随机,蓝)、中等变(一定范围内随机,绿)、低等变(位置/朝向无随机,红)。结论:初始位姿越随机(越等变),灌对称性收益越大;但中/低等变任务上本方法依然强,说明"部分对称"时对称先验也有用、稳健。
5.5 真机(表 3;核心数字)¶
| 任务 | #Demos | EquiDiff(Vo) | DiffPo-C(Vo) |
|---|---|---|---|
| Oven Opening | 20 | 95% (19/20) | 60% (12/20) |
| Banana in Bowl | 40 | 95% (19/20) | 30% (6/20) |
| Letter Alignment | 40 | 95% (19/20) | 0% (0/20) |
| Trash Sweeping | 40 | 90% (18/20) | 5% (1/20) |
| Hammer to Drawer | 60 | 85% (17/20) | 5% (1/20) |
| Bagel Baking(超长程) | 58 | 80% (16/20) | 10% (2/20) |
仅 20–60 条演示就学会全部 6 个任务,含超长程 Bagel Baking(开烤箱→拉托盘→抓贝果→放入→关托盘→关烤箱,80% 成功,失败全因机械臂关节限位);基线在这个低数据区几乎全崩。 泛化实验(附录 M):Bagel 任务训练只见 3 个烤箱朝向,测试 8 个未见朝向能零样本泛化(仅右下角因关节限位失败)——直接体现等变结构的威力。
5.6 三组消融/对照(核心,回应"凭啥归功等变")¶
- 消融(附录 H,表 7/8,平均 12 任务,绝对控制):完整 63.9 → 去 voxel(只 RGB) 53.7(-10.3) → 去等变(voxel+普通DP) 46.3(-17.6) → 都去(原始 DP) 42.0(-21.9)。等变结构比 voxel 输入更重要(去等变掉得更多)。注:voxel 版的 DiffPo-C(Vo) 略好于原版,故真机基线用的是 DiffPo-C(Vo) 这个更强基线。
- 等变网络 vs 数据增广(附录 I,表 9,100 demos):CNN+随机旋转增广平均 53.3,好于纯 CNN(46.3) 但显著差于等变网络(63.9);增广在简单任务(Stack)偶尔反超,但难任务(Three Pc. Asse. 7.3 vs 37.3)崩。→ 真等变网络 > 增广模拟等变。
- SE(3) vs SE(2) 动作空间(附录 J,表 10,200 demos):Coffee Preparation 上 SE(3) 85.3 而 SE(2) 0(任务需大量离面旋转,表4 显示其平均离面旋转达 59°);Threading SE(3) 40 vs SE(2) 12.7。→ 必须用 SE(3)(完整 6-DoF),SE(2) 解不了需要"歪着插"的任务,这是相对前人 SE(2) 工作的关键升级。
- Robomimic(附录 K,表 11):4 任务上 EquiDiff 平均 90.4 vs DP 87.9,仅略好——因 Robomimic 属低等变任务(初始随机性小),对称先验用武之地小。诚实读数。
5.7 训练超参(附录 F,留作复现指针)¶
AdamW(lr 1e-4,wd 1e-6)+ EMA;cosine 调度 500 warmup;DDPM 100 步去噪(训练&评估);2 步历史观测(voxel 版 1 步),预测 16 步动作、执行 8 步;batch 128;按 demo 数调 50000/n epoch 保持总步数大致一致。真机:batch 64、1 步观测、关 EMA、DDIM(训练 100 步 / 评估 16 步)。
6. 局限(论文自陈 + 精读补充)¶
- 对称性只被部分利用:视觉系统有"对称破坏"——agent-view 非正上方俯视、机械臂偶尔出现在 voxel 网格里、相机噪声,都会破坏严格等变。未来可设计"无对称污染"的视觉系统。
- "错误等变"风险 [Wang 57]:当模型强加的对称性与演示数据冲突时,反而可能损害性能。
- 理论未推广验证:4.2 的理论不限于扩散策略(也适用其他策略学习),但论文没做;尤其相对控制下 BC RNN 表现不错,做个"等变 BC RNN"或许有益。
- 只在机械臂操作上验证:导航/运动/移动操作未涉及。
- 离散群 C₈:用 8 个离散旋转近似连续 SO(2)。
🗣️ 外部评价¶
- 🌐 CoRL 2024 Oral,Outstanding Paper Award Finalist(杰出论文奖入围)。来源:CoRL 2024 program / 项目页。
- 🌐 OpenReview 三位审稿人评分(recommendation/confidence,来源 OpenReview forum,最终 Decision: Accept):
- 审稿人 R1:recommendation 4,confidence 2,clarity 5 —— "理论 sound、写得清楚、实验精心构造,最重要是证明了等变对低数据区样本效率的提升(演示学习的瓶颈)。图5 很好地总结了结论。"
- 审稿人 R2:recommendation 3,confidence 4(originality 3 / technical 3 / impact 3 / robotics 4 / limitations section 2)—— "数据效率方向重要、方法与实验扎实",但提出疑虑(见审稿人视角)。
- 审稿人 R3:recommendation 4,confidence 4,clarity 4 —— "动机有说服力、问题重要、框架合理、评估充分,会吸引 CoRL 广泛受众,建议接收。"
- 🌐 后续工作把它当强基线/出发点:EquiBot(SIM(3)-等变扩散策略)、SE(3)-Equivariant Diffusion Policy in Spherical Fourier Space (arXiv 2507.01723)、Symmetry-Aware Steering of Equivariant Diffusion Policies (arXiv 2512.11345) 等都对照/扩展本工作 —— 说明它已成为"等变扩散策略"这一子方向的奠基参考。来源:themoonlight review、arXiv 2512.11345。
🧑⚖️ 审稿人视角(🤖)¶
把审稿意见提炼成"如果我来挑刺"的清单(多数已被作者用附录回应): - 图像版 SO(2) 等变的合理性存疑(R2):对非俯视的 2D 图做 z 轴旋转,旋转图与旋转动作会失一致性 → 作者承认这是"对称破坏",并用 voxel 版规避、引 [Wang 52] 说明等变 CNN 仍能捕捉潜在对称(主结果也显示图像版收益确实小于 voxel 版,自洽)。 - 为何不直接用数据增广?(R2)→ 作者用附录 I 表 9正面回应:增广 < 等变网络,难任务尤甚。这是很关键的"凭啥归功等变"对照。 - 只有 8 个离散旋转,能否泛化到连续旋转/任意初始位姿?(R2,举例烤箱转 30°)→ 作者补附录 M 泛化实验(8 个未见朝向零样本泛化)部分回应,但 C₈ 离散化的连续性极限仍是开放问题。 - 缺误差棒(R3):表 1-2、图 5b 没给标准差 → 作者补附录 G 表 6(带 standard error),基本补齐。 - 只在机械臂操作验证(R3):导航/运动未做 → 作者列为 future work,未解决。 - limitations section 评分仅 2(R2):审稿人认为原文局限讨论偏薄——值得我们读时自己多补一层(见上"局限")。 - 置信度分布:给最高 recommendation(4) 的 R1 自评 confidence 仅 2(非等变专家),等变数学的严谨性主要由 R3(conf 4) 背书;整体仍是清晰的 accept,无强烈反对者。
7. 对我们(深一层)¶
- "几何归纳偏置→扩散策略"的标杆:与 详读-DiffusionPolicy 同源、与 DP3 同走"给扩散策略加结构先验"路线,但本文加的是对称性而非 3D 表示,且消融证明对称性比 3D 表示更管用。数据贵时这是高性价比的一招。
- 可直接借的工程件:开源代码(escnn 实现的等变 ResNet/3D 等变卷积/等变 Linear + 1D Temporal UNet 配对去噪),等变模块可移植到我们自己的策略骨干。
- 数据护城河视角:与 详读-DexTeleop-0、UMI 手套等"把采数做精/做多"是同一战场的另一端——它不改采数硬件,而是用先验把同样的数据榨出更高样本效率(200 demos 顶别人 1000)。两条路线(采更多 vs 学更省)可长期对照(见 概念-机器人数据与标注)。
- 落地提醒:① 收益强依赖任务"有多等变"——我们的任务若初始位姿随机性低(低等变),收益会缩水(Robomimic 仅 +2.5 即例);② 视觉端要尽量"对称友好"(俯视/voxel)才能吃满等变红利;③ 需要离面旋转的精细插装任务必须用 SE(3)(6-DoF)动作空间,别退化到 SE(2)。