详读 · UMI(Universal Manipulation Interface)¶
卡片版见 卡片-UMI。本页是全文精读:动机 → 方法(逐模块) → 实验(全表数字) → 洞见/局限 → 对我们。 来源:arXiv 2402.10329 v3(2024-03-06)· 项目页 作者:Cheng Chi、Zhenjia Xu(共一)、Chuer Pan、Eric Cousineau、Benjamin Burchfiel、Siyuan Feng、Russ Tedrake、Shuran Song(Stanford + Columbia + Toyota Research Institute)
0. 一句话定位¶
用一只 $73 的 3D 打印手持平行夹爪 + 一台 GoPro,让人在任意环境(in-the-wild)直接演示操作;靠 Fisheye 广角 + 侧反射镜(隐式立体) + IMU 视觉惯性 SLAM 把演示精确恢复成 6DoF 末端轨迹;再靠 推理时延对齐 + 相对轨迹动作表示 + Diffusion Policy,把数据学成硬件无关、可跨机器人本体零样本部署的策略。核心主张:采数时不需要真机,只换训练数据就能解锁动态/双手/精密/长程任务。

1. 问题与动机¶
机器人学操作技能的数据,过去走两条路、都不够: - 真机遥操作采数(in-the-lab):硬件+专家操作员成本高,且数据/策略绑定具体本体,换机器人不能复用,难以"在野"采集。 - 人类视频(in-the-wild, 如 YouTube):和机器人有巨大 embodiment gap——多数视频无显式动作信息、人手↔机器人形态差、观测分布失配。
带传感的手持夹爪(前作 [41]/[50]/[36] 等)是中间路线:既缩小 embodiment gap 又便携直观。但前作动作多样性差——视觉上覆盖了上百环境,采到的动作却被限制在简单抓取 / 准静态 pick-and-place,无法迁成有效策略。UMI 诊断出四个"动作迁不过去"的细节病因:
- 视觉上下文不足:腕载相机虽对齐观测、利便携,但太靠近物体→严重遮挡,信息不够规划动作。
- 动作不精确:多数手持设备用单目 SfM 恢复动作,受尺度歧义/运动模糊/纹理不足影响,精度差。
- 时延不匹配:手持采数时观测与动作"零时延";真机推理时有传感/推理/执行时延 → 策略遇到分布外输入、动作不同步,对快动作尤其致命。
- 策略表达不足:前作常用 MLP+回归损失,抓不住人类数据的多模态;采数人越多、动作越多模态,问题越糟。
UMI 的解法 = 演示接口设计(补 1、2)+ 策略接口设计(补 3、4)。
2. 方法 A:演示接口设计(硬件侧,图2)¶

设备形态:扳机驱动的手持 3D 打印平行夹爪 + 软手指,唯一传感器/记录设备是一台 GoPro。双手任务再加一只即可。六个关键设计(HD1–HD6):
- HD1 腕载相机为唯一观测:部署到真机时把 GoPro 放在与手持端完全相同的位置(相对同一套 3D 打印手指)。好处:① 人/机观测几乎无法区分(缩小观测 gap);② 相机与手指机械固连→免相机-机器人-世界标定、抗机械冲击;③ 无外部相机/板载算力→高度便携;④ 运动相机带来自然数据增广(类似随机裁剪→策略更抗干扰物)。
- HD2 Fisheye 广角补视觉上下文:155° 鱼眼镜头。策略直接吃原始鱼眼图、不做去畸变——鱼眼天然中心保分辨率、边缘压缩;若校正成针孔模型会严重拉伸边缘、压缩中心关键信息(图3),不适合学习。鱼眼还提升 SLAM 鲁棒(特征/重叠更多)。
- HD3 侧反射镜做隐式立体:在相机外围视野放一对物理镜子,在同一张图里得到等效于"沿镜面反射的额外虚拟相机"视角→隐式深度,零额外成本/重量(图4)。用法:把镜中内容数字翻转 + 左右镜对调后再喂策略,效果最好(否则镜中物体朝向相反会让视觉编码器混淆)。
- HD4 IMU 感知追踪:GoPro 把 IMU(加速度计+陀螺)写进标准 mp4。基于 ORB-SLAM3 的惯性-单目 SLAM 联合优化视觉+惯性约束,即使视觉短暂失效(运动模糊/低头看桌面无特征)也能维持追踪→可采高动态动作(如抛掷);且直接恢复真实米制尺度,对动作精度与双手相对位姿本体感知(PD2.3)至关重要。
- HD5 连续夹爪宽度控制:不用前作的二值开/合,而是连续指宽(用 fiducial marker 追踪)。配合串联弹性末端原理,通过软手指形变隐式记录/控制夹持力;连续宽度对抛掷这种需精准释放时机、物体宽度各异的任务是必需。
- HD6 运动学数据过滤:采数本身与机器人无关;已知某机器人底座位姿与运动学后,用 SLAM 恢复的绝对末端位姿对演示做运动学/动力学可行性过滤,保证策略符合该本体的关节约束。
硬件规格(诚实数字):
| 项 | 数值 |
|---|---|
| 夹爪重量 | 780 g |
| 外形尺寸 | L310 × W175 × H210 mm |
| 手指行程 | 80 mm |
| 3D 打印夹爪 BoM 成本 | $73 |
| GoPro 相机+配件 | $298 |
| Fisheye 视野 | 155° |
| SLAM | ORB-SLAM3 惯性-单目 |
3. 方法 B:策略接口设计(学习侧,图5)¶
策略:吃同步观测序列(RGB 图 + 6DoF 末端位姿 + 夹爪宽度),输出动作序列(末端位姿+夹爪宽度)。本文全用 Diffusion Policy(注:ACT 等可直接替换)。目标是接口与底层硬件无关,使"一份手持数据"能直接部署到不同机器人。两大挑战 → 三个设计:
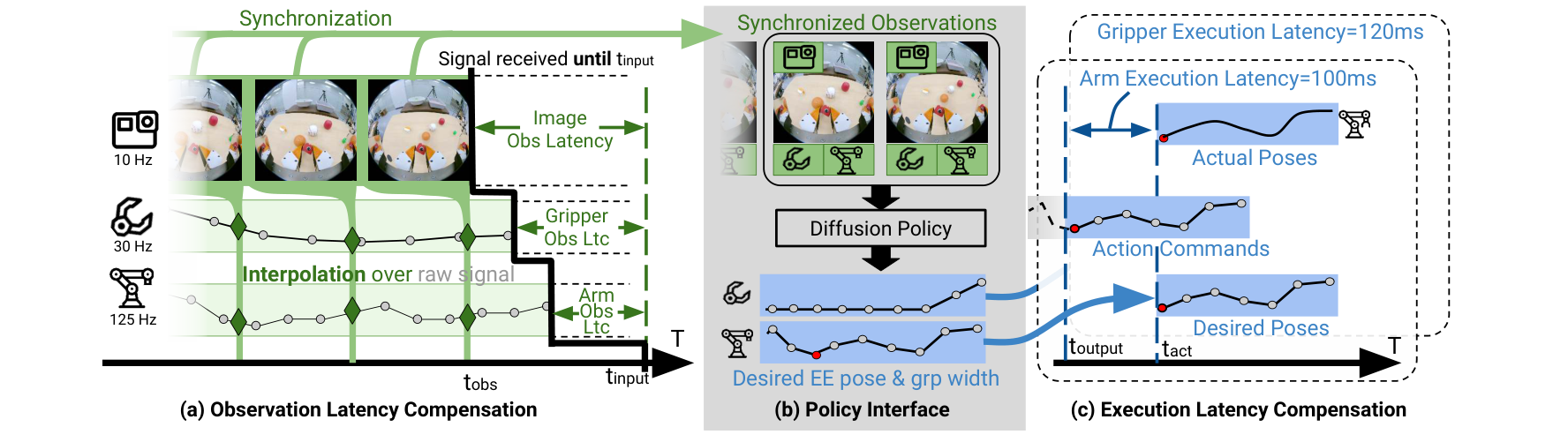
- PD1 推理时延匹配(关键):手持端各流"零时延",真机各硬件时延从个位数到几百毫秒不等,不处理会让动态任务掉点。
- PD1.1 观测时延对齐:逐流物理测量时延,推理时全部对齐到时延最高的流(通常相机);先把 RGB 降采到目标频率(常 10–20Hz),再用每帧的采集时间戳
t_obs对夹爪/本体感知做线性插值。双目双手系统用最近邻帧软同步(最多偏 1/60 秒)。 - PD1.2 动作时延补偿:机器人/夹爪只能滞后地跟踪目标位姿,故提前下发指令抵消执行时延;预测序列里前几步因观测+推理+执行时延已过期 → 丢弃,只执行
t_act之后的动作。 - PD2 相对末端位姿(去本体/部署坐标依赖):所有末端位姿都相对当前末端位姿表示。
- PD2.1 相对轨迹作动作表示:动作序列 = 从
t0起一串相对初始位姿的 SE(3) 变换。比绝对动作更抗采数追踪误差/相机位移,比 delta 动作不累积误差(图6)。 - PD2.2 相对轨迹作本体感知:历史位姿也用相对轨迹;观测步长=2 时等效提供速度信息。配合腕载相机 → 系统免标定:执行中移动机器人底座(只要物体仍在可达范围)不影响性能 → 可用于移动机械臂。
- PD2.3 相对双夹爪本体感知:双手时给策略两夹爪相对位姿对协同至关重要(尤其两相机视觉重叠小时)。靠 map-then-localize 采集方案:每个新场景先录一段建图视频,该场景所有演示重定位到同一张地图→共享坐标系,从而能算两夹爪相对位姿。
4. 实验:能力(窄域,图7/图8)¶
四个真实任务,均在采数同环境评估但随机化机器人/物体初态,各方法用完全相同初态对齐。

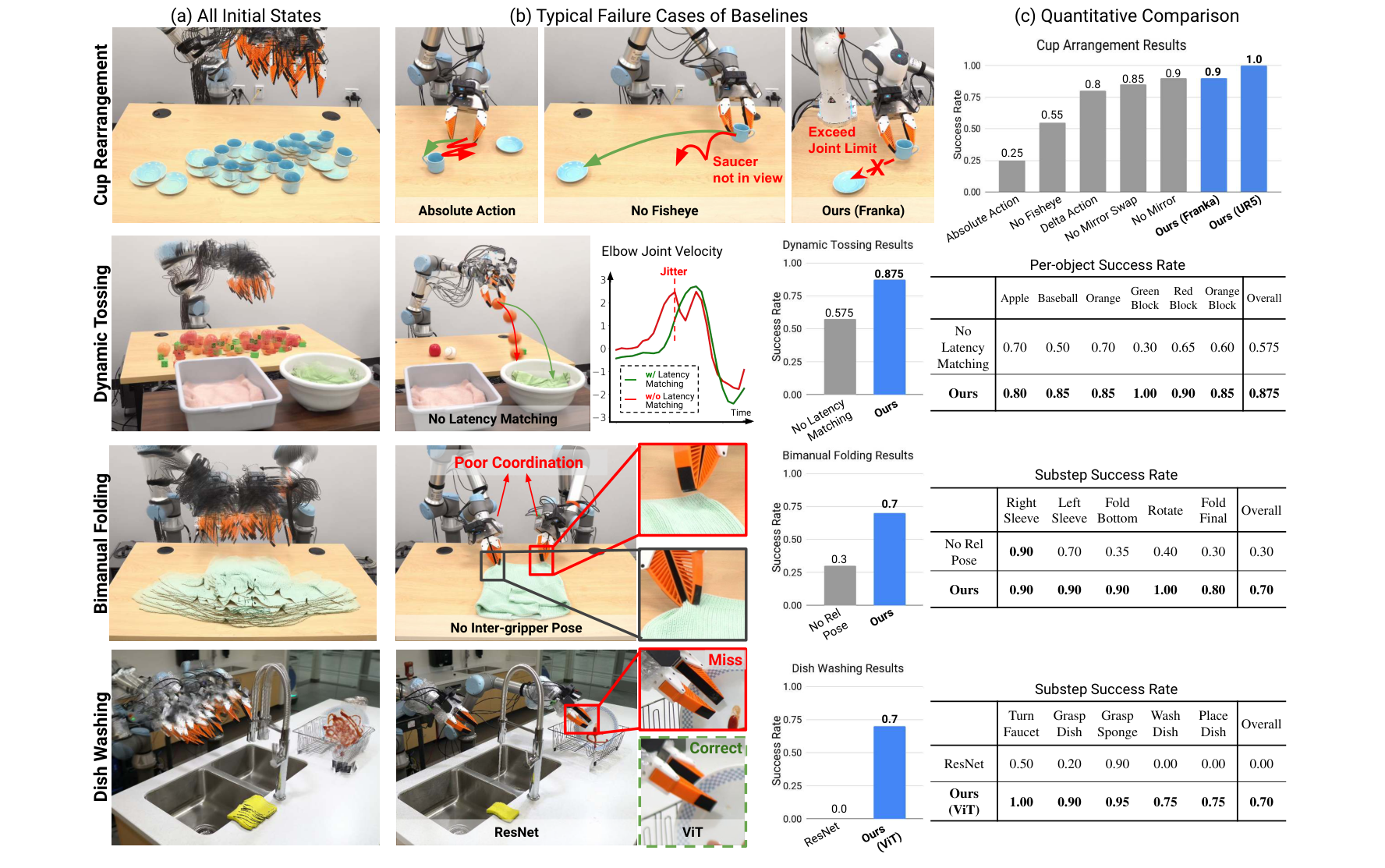
4.1 杯子摆放(Cup Arrangement)¶
把咖啡杯正立放到碟上、手柄朝机器人左侧 ±15° 内算成功。考验 prehensile(抓放)+non-prehensile(推转向)+多模态(顺/逆时针等价解)+单目/侧镜测相对深度。 训练 305 episodes / 2 名演示者,20 个测试初态。
| 配置 | 成功率 |
|---|---|
| UMI(完整) | 20/20 = 100% |
| 跨本体:同 checkpoint 部署到 Franka FR2 | 18/20 = 90%(2 例关节限位) |
| 去 Fisheye(裁成 69° 方形,类比 RealSense D415/iPhone) | 11/20 = 55% |
| Delta 动作表示 | 16/20 = 80% |
| 绝对(Absolute)动作表示 | 5/20 = 25% |
| 侧镜:不用镜 | 18/20 = 90% |
| 侧镜:直接给镜像(不翻转/对调) | 17/20 = 85% |
| 侧镜:数字翻转+左右对调(完整) | 20/20 = 100% |
读数:绝对动作仅 25%——即便在受控实验室,获取带绝对坐标的动作仍很难(SLAM↔机器人基座标定误差导致明显偏置),反衬"相对轨迹"的价值。去鱼眼掉到 55%,且即使物体可见也抖动(作者推测差视野逼策略变得不必要地多模态)。
4.2 动态抛掷(Dynamic Tossing)¶
把桌上 6 个 YCB 物体抛进对应箱:3 个球形(棒球/橙子/苹果)→圆箱,3 个乐高 Duplo→方箱;箱子放在机器人可达范围外强调必须动态。训练 280 episodes。考验快动作迁移+手眼协调+臂/夹爪时机对齐。
| 配置 | 总成功率 | 苹果 | 棒球 | 橙子 | Green块 | Red块 | Orange块 |
|---|---|---|---|---|---|---|---|
| UMI(含时延匹配) | 105/120 = 87.5% | 0.80 | 0.85 | 0.85 | 1.00 | 0.90 | 0.85 |
| 关时延匹配(全设 0) | 69/120 = 57.5% | 0.70 | 0.50 | 0.70 | 0.30 | 0.65 | 0.60 |
关时延匹配后运动抖动、释放时机错位 → 掉 30 个百分点;时延匹配对动态任务是硬刚需。
4.3 双手叠衣(Bimanual Cloth Folding)¶
双臂叠袖→叠下摆→转 90°→对折。训练 250 demos / 2 名演示者,单一中心化策略出双臂双夹爪动作。
| 配置 | 总成功率 | 右袖 | 左袖 | 叠下摆 | 旋转 | 终折 |
|---|---|---|---|---|---|---|
| UMI | 14/20 = 70% | 0.90 | 0.90 | 0.90 | 1.00 | 0.80 |
| 去双夹爪相对位姿(PD2.3) | 6/20 = 30% | 0.90 | 0.70 | 0.35 | 0.40 | 0.30 |
没有 inter-gripper 位姿,抬下摆时两臂常异步漏抓;UMI 先到 pre-grasp、等两臂就位再同时抓。
4.4 洗碗(Dish Washing)¶
7 步顺序依赖:开龙头→抓盘→拿海绵→洗擦至番茄酱去净→放盘→放海绵→关龙头。训练 258 demos / 1 名演示者,用 CLIP 预训练 ViT-B/16 视觉编码器微调。考验超长程+流体(牛顿水/非牛顿番茄酱)+软工具+受约束铰接物(龙头,靠软手指顺应)+"干净"语义鲁棒(中途加酱需回到洗的阶段)。
| 配置 | 总成功率 | 开龙头 | 抓盘 | 抓海绵 | 洗盘 | 放盘 |
|---|---|---|---|---|---|---|
| UMI(ViT) | 14/20 = 70% | 1.00 | 0.90 | 0.95 | 0.75 | 0.75 |
| ResNet-34 从零训练 | 0/10 = 0% | 0.50 | 0.20 | 0.90 | 0.00 | 0.00 |
ResNet-34 从零学出非反应式行为、无视盘/海绵位置 → 任务级 0%。视觉复杂的长程任务需要预训练大编码器。
5. 实验:在野泛化(图9)¶
把杯子摆放扩到新环境+新物体。12 人时 / 3 名演示者,采 1400 demos,覆盖 30 个真实地点(家/办公室/餐厅/户外),含 15 个不同颜色/形状/材质(陶瓷/玻璃/金属)的咖啡杯;编码器升到 CLIP 预训练 ViT-L/14。在两个未见环境测试:
- Cafe table(繁忙咖啡馆户外金属桌,行人作天然干扰):5 训练杯+2 未见杯,各 5 初态,共 35 次。
- Water fountain(黑色立方喷泉,顶面持续流水,强 OOD):3 训练杯+2 未见杯,各 5 初态,共 25 次。
| 数据/配置 | Cafe Table | Water Fountain | 成功率 |
|---|---|---|---|
| CLIP ViT 仅用窄域数据微调 | 0/10 | 0/10 | 0.0 |
| 在野数据 · 训练集杯 | 16/25 | 12/15 | 0.7 |
| 在野数据 · 未见杯 | 6/10 | 9/10 | 0.75 |
| 在野数据 · 合计 | 22/35 | 21/25 | 0.72 |
汇总:训练杯 28/40 = 70%、未见杯 15/20 = 75%、合计 43/60 = 71.7%(摘要称约 70% OOD 成功率,行为克隆框架罕见)。只用窄域数据(同预训练骨干)在未见环境机器人根本不朝杯子动 → 0%。结论:光靠大预训练模型+窄域微调不够,采集多样的在野数据才是泛化关键。
6. 实验:采数吞吐 & SLAM 精度(图11/图12)¶

吞吐(15 分钟内可采演示数,含复位/随机化/排障时间):
| 任务 | 裸手 | UMI 夹爪 | Spacemouse 遥操作 |
|---|---|---|---|
| 杯子摆放 | 231 | 111 | 35 |
| 动态抛掷 | 237 | 149 | 0(15 分钟一条成功演示都做不出) |
杯子摆放:UMI 比遥操作快 >3×、是裸手速度的 48%(裸手在复位/随机化上更快,因离物体近);抛掷:UMI 是裸手的 64%,遥操作根本做不了。
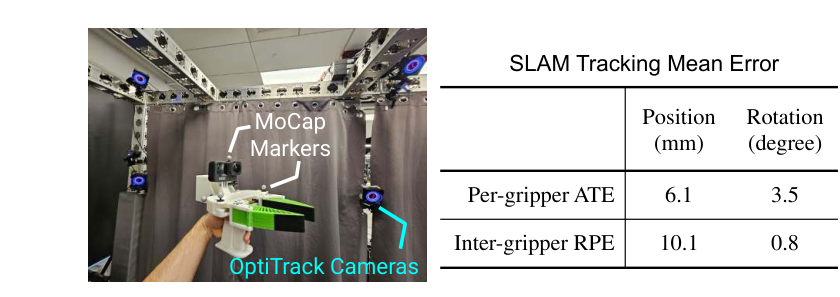
SLAM 精度(MoCap 真值,7 单夹爪+7 双手任务,含可动物体与快速人手动作):
| 指标 | 位置 | 旋转 |
|---|---|---|
| 单夹爪 ATE(绝对轨迹误差) | 6.1 mm | 3.5° |
| 双夹爪 RPE(相对位姿误差) | 10.1 mm | 0.8° |
整体 < 1 cm、< 4°;两夹爪共享同一地图 → 能算双夹爪相对位姿(支撑 PD2.3)。
7. 核心洞见¶
- 真正卡住"动作迁移"的是细节:视觉上下文(鱼眼)、深度(侧镜)、尺度+鲁棒追踪(IMU-SLAM)、时延对齐、相对动作表示、可表达策略(Diffusion)——任何一个缺位都让"看似采到了动作"的数据废掉。UMI 的贡献是把这套组合做对、做到可复现可开源。
- 相对轨迹 + 腕载相机 = 免标定、跨本体:策略不依赖全局坐标/具体本体,因此同一 checkpoint 能在 UR5 与 Franka FR2 间迁移,也适配移动机械臂。
- "换数据即换技能":四个能力迥异的任务用同一框架,仅换训练数据;泛化则靠在野数据多样性而非更大骨干。
- 标准 mp4 单文件记录一切(图像/IMU/夹爪宽度),便于互联网分发、地理分布式众包采集——指向"机器人数据民主化"。
8. 局限 / 存疑(作者诚实点出)¶
- 采数时不知下游机器人运动学限→只能靠 HD6 数据过滤事后裁掉不可行轨迹(浪费部分数据)。未来想做"本体感知"的学习框架,把"有效但当前本体不可行"的动作也迁过去。
- 依赖视觉 SLAM → 需足够纹理:纯白墙等弱纹理环境会失效。未来可加第三人称静态相机 + 夹爪上 fiducial marker 补救。
- UMI 仍慢于裸手(夹爪偏重/笨重、自由度少于人手)。未来探更轻材料/更好人机工程,或直接做能从人手动作迁移的灵巧手。
- 这是采数+策略学习框架,不是新感知硬件创新;价值在"把在野采数→可部署策略"这条链路打通并开源。
9. 对我们¶
- 同一战场:数据护城河。UMI 与 卡片-DexTeleop-0 都在攻"高质量操作数据采集",但路线互补:UMI 走无真机、在野、视觉 SLAM 恢复动作的手持夹爪;DexTeleop-0 走真机/仿真 + 指尖力闭环的遥操作。两者可长期对照,见 概念-机器人数据与标注。
- 机制可借:① 相对轨迹动作表示 + 腕载同构相机 = 免标定跨本体,是低成本采数→可部署策略的关键工程范式;② 推理时延匹配对动态任务的重要性(掉 30 点)值得记;③ 侧镜做隐式立体、鱼眼直接喂策略是零成本补信息的巧思。
- 与采集手套思路对照:UMI 用"手持夹爪 + 单 GoPro"压成本到 ~$370、单 mp4 文件可众包,这条"便携在野采数"主线与 追踪-Sunday-Memo 里的采集手套方向是同类问题的不同硬件答案,可并置评估。
- 可复现性强:硬件+软件开源(项目页),BoM 透明($73 夹爪),是搭建自有采数链路时的现成参照基线。