详读 · GR-1(大规模视频生成预训练 → 视觉机器人操作)¶
卡片版见 卡片-GR-1。本页是全文精读:动机 → 方法(逐模块) → 实验(全表) → 消融 → 诚实局限 → 洞见 → 对我们。 来源:arXiv 2312.13139v2(2023-12-21,Preprint;后中 ICLR 2024)· 项目页 作者:Hongtao Wu、Ya Jing(共同一作)、Chilam Cheang、Guangzeng Chen、Jiafeng Xu、Xinghang Li、Minghuan Liu、Hang Li、Tao Kong(通讯)—— 字节跳动 Research(ByteDance Research)
0. 一句话定位¶
一个朴素的 GPT 式 transformer,先在大规模人类第一视角视频上做语言条件的"预测下一帧"生成式预训练,再无缝迁移到机器人数据微调;同一个模型同时输出动作 + 未来图像。核心主张:视频生成预训练(学会"预判接下来会发生什么")能显著提升多任务、语言条件的视觉操作学习,尤其在长程、零样本泛化、小数据场景。
1. 问题与动机¶
- 生成式预训练在 NLP/CV 已被反复验证(GPT、iGPT、MAE、LLaMA):大规模预训练学到通用模式 → 易迁移、带来泛化与鲁棒。
- 机器人数据本身也是"生成式"的(动作执行后才揭示下一观测),但有两大难点:① 稀疏——采集需昂贵耗时的人类演示;② 多模态——图像、机器人状态、动作、语言混在一起。
- 作者论点:机器人轨迹本身就含一段视频,所以"据过去帧+语言预测未来帧"与"学动作"是高度相关的任务——能预判未来事件,就能生成贴切动作。
- 与前人区别:VPT/VIPER 用的是任务环境内视频;本文用域外、非机器人的大规模人类视频;且统一一个模型做视频预测与动作预测(不像 model-based 拆成视频模型 + MPC/逆动力学)。
2. 总览(图1)¶
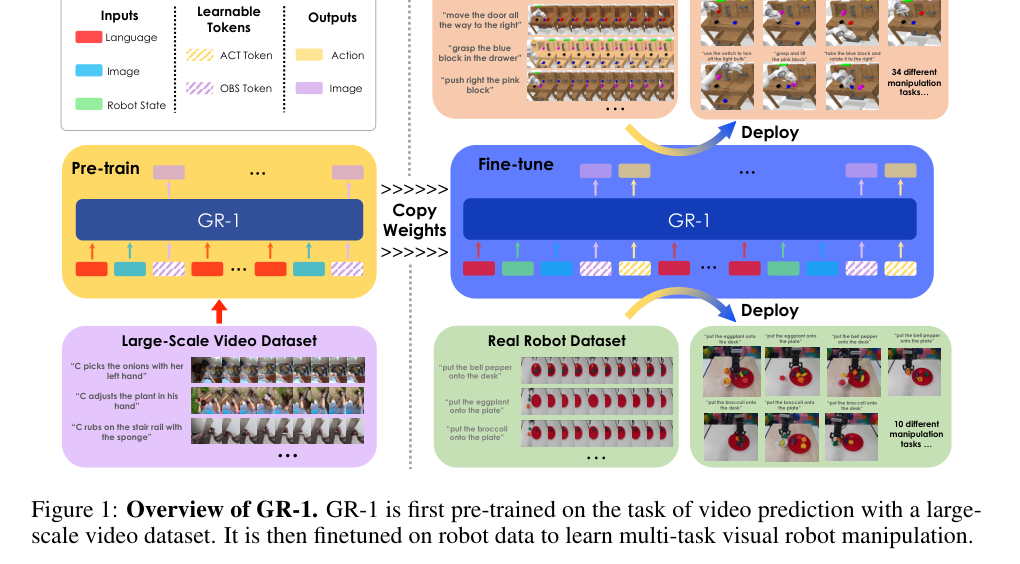
左:在 Large-Scale Video Dataset 上做视频预测预训练;中:"Copy Weights" 把权重复制过去;右:在 CALVIN 基准数据与真机数据上 Fine-tune 再 Deploy。输入是「语言 + 图像 + 机器人状态」,输出是「动作 + 图像」,分别由可学习的 [ACT] token 与 [OBS] token 承载。
3. 问题形式化(§3.1)¶
- 视频生成预训练:模型 π 据视频语言描述 l 与过去帧
o_{t-h:t},预测未来帧o_{t+Δt}:π(l, o_{t-h:t}) → o_{t+Δt}。数据是「视频 + 语言描述」对。 - 多任务视觉操作:π 据语言指令 l、观测序列
o_{t-h:t}、状态序列s_{t-h:t}输出动作a_t,并额外预测未来帧:π(l, o_{t-h:t}, s_{t-h:t}) → o_{t+Δt}, a_t。状态 s = 末端执行器位姿 + 二值夹爪状态。轨迹τ = {l, o_1,s_1,a_1, ...}。
4. 架构(图2,逐模块)¶
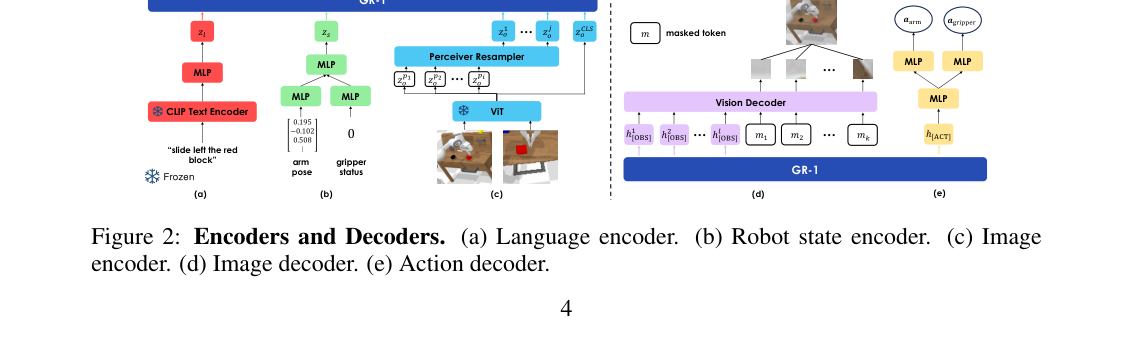
4.1 输入编码器¶
- 语言:CLIP 文本编码器(全程冻结),编码指令如"slide left the red block"。
- 视觉:MAE 预训练的 ViT(全程冻结)。输出 CLS token 作全局表示,patch tokens 作局部表示,再经 Perceiver Resampler 压缩 token 数量。
- 机器人状态:6D 末端位姿
s_arm ∈ SE(3)+ 二值夹爪s_gripper ∈ {0,1},各用线性层编码。 - 各模态嵌入再过线性层对齐维度。动作用一个可学习 [ACT] token 预测;视频用若干 [OBS] token 预测未来帧。
4.2 token 序列与因果注意力¶
- 预训练序列:
(l, o_{t-h}, [OBS], l, o_{t-h+1}, [OBS], ..., l, o_t, [OBS])。 - 微调序列:
(l, s_{t-h}, o_{t-h}, [OBS], [ACT], l, s_{t-h+1}, ..., l, s_t, o_t, [OBS], [ACT])。 - 语言 token 在每个时间步重复(防止被其它模态淹没);加可学习的相对时间步嵌入(同一时间步各模态共享)。
- 因果注意力:token 可注意所有前面位置,但预训练时屏蔽 [OBS]、微调时屏蔽 [ACT] 和 [OBS](它们是输出 token,不被别人注意)。
4.3 输出解码器与损失¶
- 视频预测:接一个 transformer 解码器(self-attention + MLP),在 [OBS] token 与 mask token 上工作;每个 mask token(共享可学嵌入 + 位置编码)重建未来图像的一个 patch。损失
L_video= 像素 MSE(按 patch 归一化,沿用 MAE)。 - 动作预测:[ACT] 输出过线性层预测臂动作和夹爪动作。臂动作连续 → Smooth-L1(L_arm);夹爪 → BCE(L_gripper)。
- 微调总损失:
L_finetune = L_arm + L_gripper + L_video。
5. 训练细节(§3.3 + 附录A.1)¶
- 两段式:先视频预测预训练,再机器人数据微调;两段都冻结 CLIP 文本 + MAE 图像编码器。
- 预训练数据:Ego4D(>3,500 小时人-物交互第一视角视频,每段带自然语言标注)。从每段裁 3 秒短片 → 共 80 万段 clip、800 万帧(8M frames)。预训练
Δt=1,相邻采样帧间隔 1/3 秒(保证足够视觉差异)。 - 微调:机器人数据更密 → 设
Δt=3;同时预测静态相机 + 夹爪相机两路图像。输入序列长度 10。 - 优化器 AdamW + 余弦学习率衰减 + dropout + 随机平移增强。
- 模型规模:因果 transformer 12 层、12 头、hidden=384;总参 195M,其中可训练仅 46M(其余在冻结的 CLIP/ViT 里)。动作头是 3 层 MLP(最后一层两个 head 分预测臂/夹爪)。
下表是超参(附录表3):
| 超参 | 预训练 | 微调(CALVIN) |
|---|---|---|
| batch size | 1024 | 512 |
| learning rate | 3.6e-4 | 1e-3 |
| dropout | 0.1 | 0.1 |
| optimizer | AdamW | AdamW |
| lr schedule | cosine decay | cosine decay |
| warmup epochs | 5 | 1 |
| training epochs | 50 | 20 |
6. 实验¶
6.1 CALVIN 设置¶
- CALVIN:长程、语言条件操作基准;34 个任务,Franka Emika Panda + 平行夹爪,桌面有滑门/抽屉/不同色积木/LED/灯泡。
- 训练用 2 万+ 条带语言标注的专家轨迹;注意 CALVIN 含 24h 遥操作无序 play 数据,只有 1% 带众包语言标注——GR-1 只训这 1%。
- 两个划分:ABCD→D(四环境全训、D 评估)、ABC→D(训 A/B/C、评估未见过的 D;四环境桌色与物体配置不同)。
- 评估协议:1000 条序列指令链,每条要连续完成最多 5 个任务,单任务 360 步内未完成即失败,完成当前才给下一个。指标含每行完成 1~5 个的成功率与 平均长度 Avg.Len.(5 连任务平均完成数)。
- 基线:MCIL、RT-1(SOTA,卷积+transformer+FiLM 语言条件)、HULC(分层、先生成隐 plan)、MT-R3M(R3M 也在 Ego4D 预训练、冻结编码器 + GPT 式动作头,可训练参数与 GR-1 相同——这是"视频预训练 vs 表征预训练"的关键对照)。MCIL/HULC 用全量数据(含无标注),RT-1/MT-R3M/GR-1 只用 1% 带语言的数据。
6.2 CALVIN 主结果(表1)¶
| 设置 | 方法 | 1 | 2 | 3 | 4 | 5 | Avg.Len. |
|---|---|---|---|---|---|---|---|
| ABCD→D | MCIL | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| RT-1 | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 | |
| HULC | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 | |
| MT-R3M | 0.752 | 0.527 | 0.375 | 0.258 | 0.163 | 2.08 | |
| GR-1 | 0.949 | 0.896 | 0.844 | 0.789 | 0.731 | 4.21 | |
| ABC→D | MCIL | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| RT-1 | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 | |
| HULC | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 | |
| MT-R3M | 0.529 | 0.234 | 0.105 | 0.043 | 0.018 | 0.93 | |
| GR-1 | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 | |
| 10% 数据 | RT-1 | 0.249 | 0.069 | 0.015 | 0.006 | 0.000 | 0.34 |
| HULC | 0.668 | 0.295 | 0.103 | 0.032 | 0.013 | 1.11 | |
| MT-R3M | 0.408 | 0.146 | 0.043 | 0.014 | 0.002 | 0.61 | |
| GR-1 | 0.778 | 0.533 | 0.332 | 0.218 | 0.139 | 2.00 | |
| 未见语言 | RT-1 | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| HULC | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 | |
| MT-R3M | 0.512 | 0.249 | 0.106 | 0.040 | 0.017 | 0.92 | |
| GR-1 | 0.764 | 0.555 | 0.381 | 0.270 | 0.196 | 2.17 |
读数(均为表内真实值): - 多任务 ABCD→D:首任务成功率 88.9%(HULC)→94.9%(GR-1);Avg.Len. 3.06→4.21。 - 零样本未见场景 ABC→D:首任务 53.3%(最佳基线)→85.4%(GR-1);Avg.Len. 0.93→3.06。 - 小数据(10%):仅采 66 条/任务 × 34 = 2244 条(占总 22,966 的 ~10%);GR-1 77.8% / 2.00 vs 最佳基线 HULC 66.8% / 1.11。 - 未见语言:用 GPT-4 为每任务生成 50 条同义指令评测;GR-1 76.4% / 2.17,仍领先全部基线。
6.3 真机实验(图5、表2)¶

- 平台:7-DoF Kinova Gen2,末端装 RealSense,外加 Kinect Azure 提供静态视角。
- 数据:物体搬运 1775 条演示(用 HTC Vive VR 采集,茄子/西兰花/甜椒在盘↔桌互搬);抽屉开关 2856 条轨迹。
- 三档泛化:Seen Objects(训练见过的三物,含加干扰物/换背景两种扰动场景)、Unseen Instances(新实例的茄子/西兰花/甜椒)、Unseen Categories(番茄、黄桃——类别都没见过)。
| 方法 | 搬运·可见物 | 搬运·未见实例 | 搬运·未见类别 | 铰接物体(抽屉) |
|---|---|---|---|---|
| RT-1 | 0.27 | 0.13 | 0.00 | 0.35 |
| MT-R3M | 0.15 | 0.13 | 0.10 | 0.30 |
| GR-1 | 0.79 | 0.73 | 0.30 | 0.75 |
读数:GR-1 三档全面领先;可见物 0.79、未见实例仅小幅降到 0.73(强实例泛化);最难的未见类别仅 0.30(典型失败:把甜椒和颜色相近的黄桃混淆)。抽屉操作 0.75,典型失败是"关不严"或"开门时没勾住把手"。
6.4 视频预测质量(图6)¶
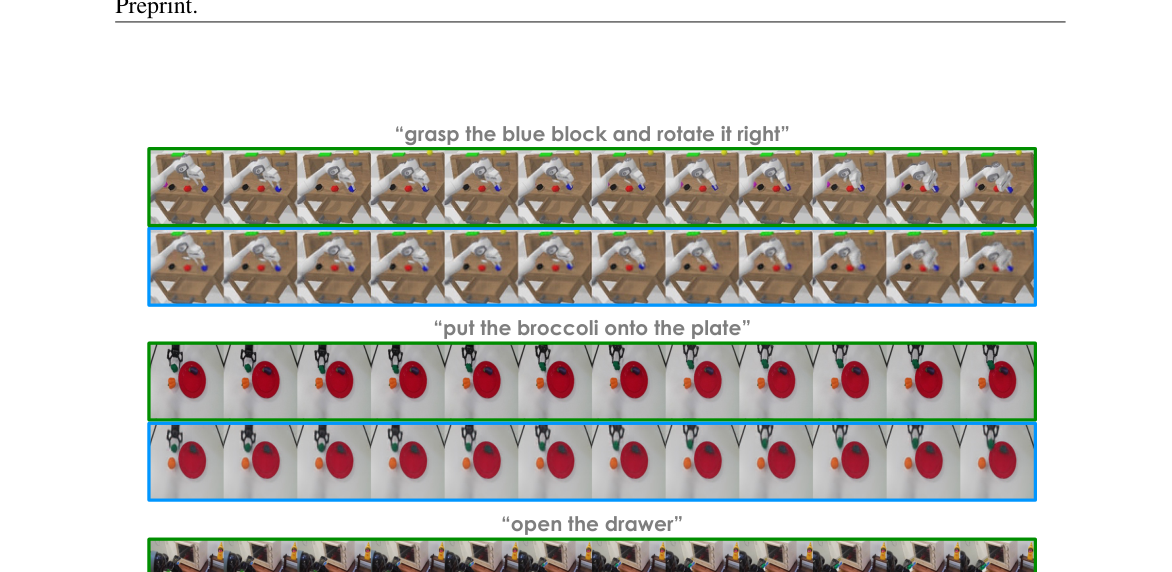
GR-1 在 CALVIN 与真机数据上都能正确重建未来帧(部分遮挡物细节缺失)。作者强调:这个视频预测信号正是动作预测的"强路标"。
7. 消融(附录A.4)¶
视频预测 + 预训练逐项剥离(CALVIN,Avg.Len.;✗/✓ 分别表示是否预训练 / 是否做视频预测):
| 预训练 | 视频预测 | 设置 | 1 | 2 | 3 | 4 | 5 | Avg.Len. |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ABCD→D | 0.889 | 0.775 | 0.661 | 0.549 | 0.459 | 3.33 |
| ✗ | ✓ | ABCD→D | 0.918 | 0.833 | 0.761 | 0.685 | 0.619 | 3.82 |
| ✓ | ✓ | ABCD→D | 0.949 | 0.896 | 0.844 | 0.789 | 0.731 | 4.21 |
| ✗ | ✗ | ABC→D | 0.823 | 0.609 | 0.425 | 0.318 | 0.225 | 2.40 |
| ✗ | ✓ | ABC→D | 0.815 | 0.651 | 0.498 | 0.392 | 0.297 | 2.65 |
| ✓ | ✓ | ABC→D | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 |
| ✗ | ✗ | 10% | 0.526 | 0.288 | 0.138 | 0.061 | 0.022 | 1.04 |
| ✗ | ✓ | 10% | 0.698 | 0.415 | 0.223 | 0.133 | 0.052 | 1.52 |
| ✓ | ✓ | 10% | 0.778 | 0.533 | 0.332 | 0.218 | 0.139 | 2.00 |
结论:"加视频预测"与"加大规模预训练"是两个独立增益、且可叠加。以 ABCD→D 为例 3.33 →(+视频预测) 3.82 →(+预训练) 4.21;小数据档增益更明显(1.04→1.52→2.00)。
未来帧步长消融(不用预训练,Avg.Len.):
| Future Step | Avg.Len. |
|---|---|
| 1 | 3.61 |
| 3 | 3.82 |
| 5 | 3.67 |
读数:从预测 1 步 →3 步有提升(相邻帧太像、预远点能"懂未来"),但很快饱和,预 5 步反而略降(预太远对当下局部动作指导有限)。故微调取 Δt=3。
8. 诚实局限 / 存疑¶
- 未见类别泛化弱:真机仅 0.30,靠颜色易混(甜椒↔黄桃)——说明它更像"实例/外观鲁棒",语义级类别迁移仍有限。
- 视频预测丢遮挡细节:预测帧在被遮挡物处会缺细节;作为"路标"够用,但不是精确世界模型。
- 预训练数据是域外人类视频(Ego4D),未系统比较"任意视频 vs 仅操作相关视频"——作者明确把这列为 future work。
- 未来步增益快饱和:长视野预测对局部动作帮助有限。
- 仍是行为克隆 + 单一模型:评估集中在 CALVIN(仿真)+ 单臂 Kinova 的少量真机任务;机器人数据规模、技能数仍待 scale up(作者列为未来)。
- 评估口径需注意:CALVIN 是长程连续链指标,真机是分设置成功率,二者不可直接跨表比较。
9. 核心洞见 / 未来¶
- 关键结论:把视频生成预训练(预测未来帧)作为机器人操作的前置任务,能同时改善长程多任务、零样本场景泛化、小数据效率、语言泛化——一个统一 GPT 式 transformer 即可承载视频预测与动作预测两件事。
- 为什么有效(作者假设):预训练让模型学到"给定语言+历史,未来该长什么样"的准确视频模型 → 这成为动作生成的强路标;冻结 CLIP/MAE 保住了强文本/视觉表征带来的泛化。
- 未来:①混合"有/无语言"的视频一起训;②研究"任意视频 vs 操作相关视频"的预训练差异;③扩大机器人数据(更多环境、更多技能)。
10. 对我们(深一层)¶
- 范式定位:GR-1 是"视频预测预训练当世界先验 + 动作头微调"这条两段式路线的早期代表,与 卡片-VPP 思路同源(都把"预测未来"当成动作学习的前置/先验)。值得作为该家族的起点基线对照。
- GR 系列脉络:作为 GR 家族的第一代,后续演进可与 卡片-GR-2 串起来看"版本叙事"——本库已有 GR-2 卡片,可据此追问"GR-1→GR-2 改了什么、为什么"。
- 可借的机制:①统一模型同时出动作 + 未来图像(视频预测作辅助监督/路标);②冻结大模态编码器(CLIP/MAE)、只训中间因果 transformer——可训练参数仅 46M/195M,是低成本迁移的范式;③[ACT]/[OBS] 可学习 token + 因果屏蔽的多模态序列化做法。
- 数据视角:它用域外人类第一视角视频(Ego4D)补机器人数据稀疏,与本库"机器人数据与标注"主线相关,可与其它"用人类视频/低成本演示补数据"的路线长期对照(参见本库相关领域 MOC)。