详读 · AdapTac(力引导预测性注意力的自适应视触觉融合)¶
卡片版见 卡片-AdapTac-PredictiveForceAttention。本页是全文精读:动机 → 方法(逐模块公式直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2505.13982(v2,2025-07-21)· 项目页 作者:Jinzhou Li*、Tianhao Wu*、Jiyao Zhang†、Zeyuan Chen†、Haotian Jin、Mingdong Wu、Yujun Shen、Yaodong Yang、Hao Dong(通讯) 机构:北京大学(前沿计算研究中心 / PKU-Agibot Lab / 多媒体信息处理国家重点实验室)+ 蚂蚁集团(Yujun Shen)。
*/†为同等贡献。
0. 一句话定位¶
做一个力引导的交叉注意力融合模块:把接触力当 query、把视觉/触觉特征当 key/value,用注意力动态决定当前阶段该多看视觉还是多信触觉——不需人工标接触标签、不假设"视觉永远主导"。再配一个自监督"未来力预测"扩散辅助任务强化触觉、缓解数据不平衡。三个精细接触任务实机平均成功率 93%。
1. 问题与动机¶
- 人做事天然多模态:视觉全局、给上下文(快速定位物体);触觉局部、给精确接触反馈(微调指位、施力)。机器人要做精细接触操作也得同时懂"何时/何处/如何接触"。
- 现有融合两条路都有缺:
- 数据级融合(直接拼原始/预处理输入,如把点云和触觉塞进统一 3D 表征):保细节,但模态在空间分辨率、采样率、噪声分布上异构,直接 concat 难对齐。
- 特征级融合:努力学一个"当前状态的综合表征",却忽略了不同阶段各模态重要性不同——某些时刻多一个模态反而是干扰。
- 离 AdapTac 最近的对照是 FoAR(卡片-FoAR):用接触概率调力特征以避噪。但 FoAR ① 依赖预设阈值打接触标签;② 假设视觉永远主导——可扩展性受限。
- AdapTac 的切入:用接触诱发的力本身(它天然反映接触状态与交互动态)来引导融合,去掉人工阈值/标签、去掉视觉主导假设。
2. 核心思想(图1)¶
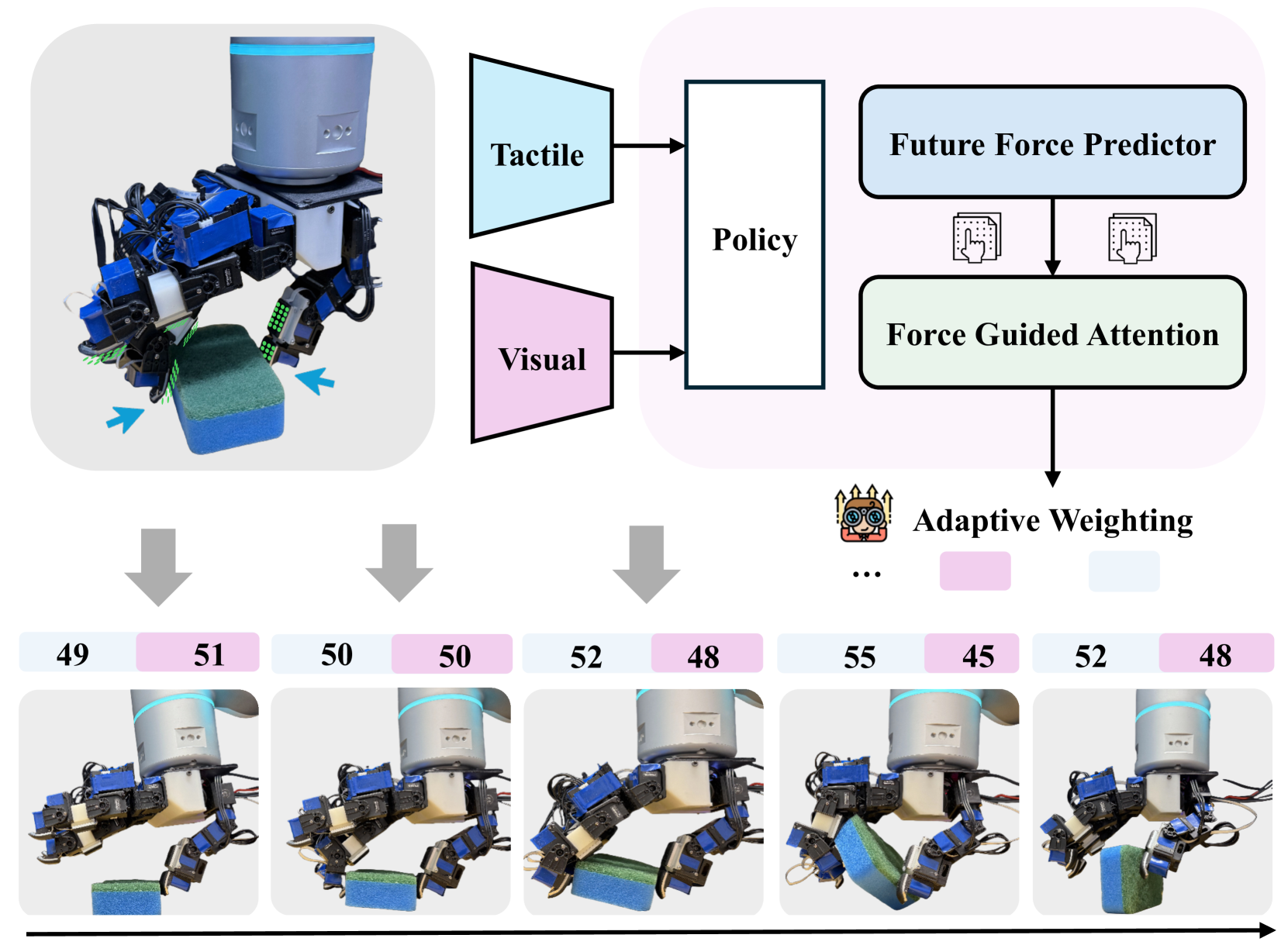
以"翻盘海绵(flip dish sponge)"为例:reach 阶段靠视觉快速定位;接触后靠触觉精调指位和施力。AdapTac 的策略预测未来力、与观测力结合,去逐阶段动态调整两个模态的注意力权重。
3. 系统与硬件(机器人系统设置)¶
- 机械臂:7-DoF Flexiv Rizon 4。
- 灵巧手:定制 16-DoF Leap Hand(4 指)。
- 触觉:PaXini 传感器,每指指尖 + 指腹各一片;每片 3×5 taxel 阵列,每个 taxel 测三轴力
F∈R³。 - 视觉:单个 Intel RealSense L515,斜装在机器人上。
- 采数(遥操作):另用 RealSense D415 + HaMeR 追人手姿态,经 DexPilot 重定向遥操作。
- 频率:采数与推理均 5 Hz。
- 动作/观测空间:观测
Oₜ = {点云 Oᵖᶜ∈R^{N×3}, 触觉 Oᵗᵃᶜ∈R^{120×12}};动作Aₜ∈R²⁵=平移t∈R³+ 旋转r∈R⁶(6D 表征) + 手关节q∈R¹⁶;历史 horizonh,预测未来n步动作。
4. 方法详解(图2)¶
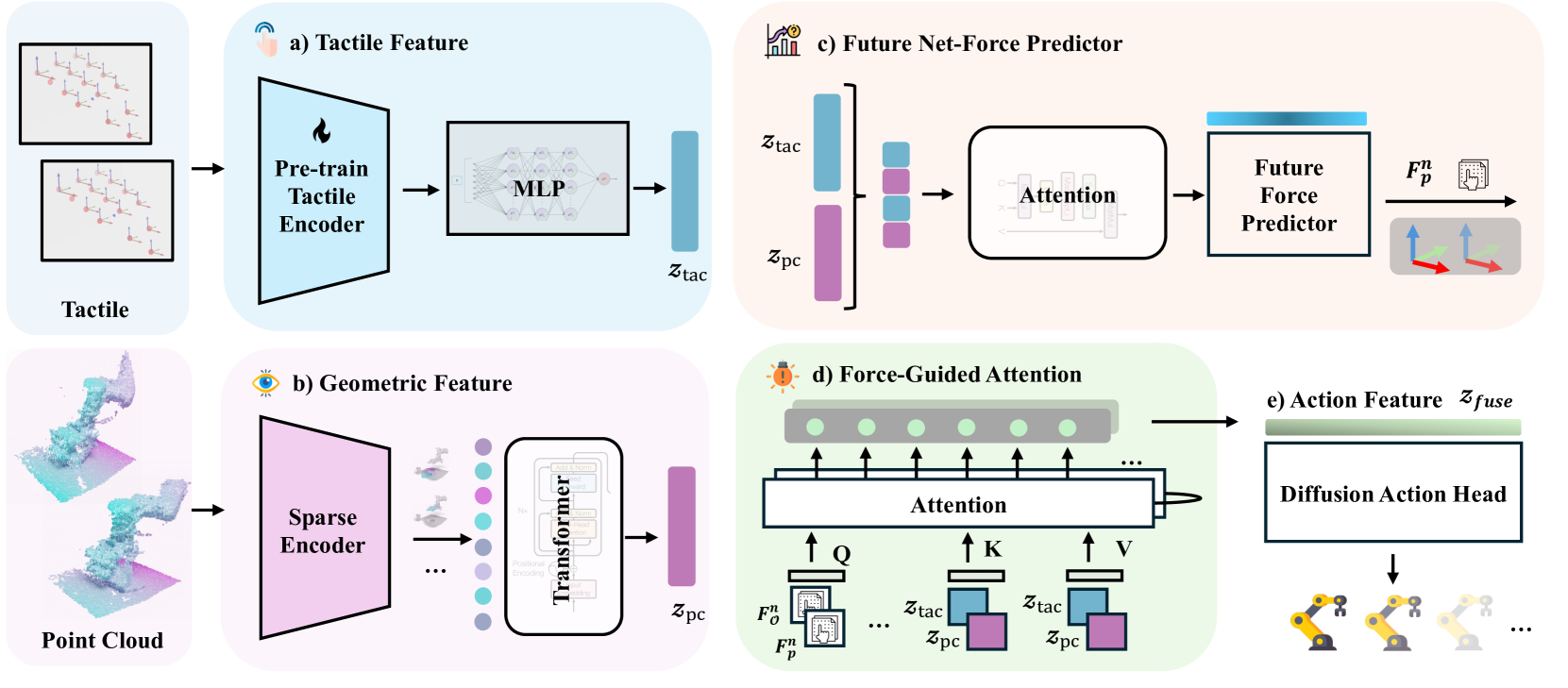
4.1 力引导注意力融合(IV-A)¶
- 编码:稀疏编码器取点云特征
Z^pc = φ_pc(O^pc);预训练触觉编码器(沿用 3DTacDex [3])取Z^tac = φ_tac(O^tac)。 - 力嵌入:观测净力
F^n_O(所有 taxel 三轴力先用各自 6D 位姿转到相机系再求和)经 MLPg_F→e_F。 - 维度对齐:分别 MLP 把视/触投到
e_pc, e_tac ∈ R^512。 - 力当 query,视/触当 key/value:
Q_F = e_F W_Q,K = [e_pc, e_tac]W_K,V = [e_pc, e_tac]W_V。- 注意力权重
α_pc, α_tac = softmax(Q_F K^T / √d_k)。 - 融合
Z_fuse = α_pc·V_pc + α_tac·V_tac。 - 直觉:让策略在需要时优先用触觉,而不是像以往那样总依赖视觉。
4.2 未来力预测与引导(IV-B)¶
- 问题:只有注意力模块、无显式监督时,因视觉信息更丰富,注意力会偏向视觉、触觉用不足(例:reorient 任务,reach 靠视觉,但 reorient 阶段视+触都关键)。
- 方案:训练期加一个 transformer 扩散头做自监督未来净力预测——吃视/触特征,预测未来
n步净力F^n_p。 - 引导力 = 观测力 + 预测力拼接:
F^n_g = [F^n_O, F^n_p],再投成 query:Q_F = g_F([F^n_O, F^n_p])W_Q。→ 用当前+未来接触信息共同引导注意力。
4.3 视触觉策略学习(IV-C)¶
- 基础策略:RISE(3D 扩散策略,[22])。流程:视/触特征 → 预测未来力
F^n_p→ 与观测力拼成引导力F^n_g→ 当 query 做跨模态注意力 → 融合特征喂扩散动作头出动作。 - 总损失:
L = L_π + α·L_ffp(策略损失 + 未来力预测损失,α为权重超参)。
5. 实验¶
5.1 设置¶
- 三个精细接触任务(图3):
- Open Box:拇/食/中指开盒,难点是抓稳上盖不松脱。成功=开后上盖留位。
- Reorientation:四指协同把杯子转到目标朝向(低摩擦、长 horizon、别推出工作区)。成功=终态朝向在目标 ±10°。
- Flipping:拇/食/中指翻盘海绵,用食指掀翻;难点是重度视觉遮挡下的指协同与施力。成功=翻立 90°。
- 协议:每任务约 30 条专家演示训练;评测每方法每任务 10 次,每次上限 300 步;初始物体位姿在 35×35 cm 平面内随机。
- 基线(共用同一点云编码器/U-Net 扩散策略/视觉观测/动作空间,只差融合方式):
- RISE:仅点云,纯视觉。
- 3DTacDex-P([3]):用其预训练触觉编码器,直接 concat 视+触(RGB 编码器换成稀疏编码器以对齐视觉特征)。
- FoAR([13]):手动设阈值标接触状态、训预测器估接触概率来加权触觉特征。
5.2 主结果:策略对比(表 I)¶

| 方法 | Open Box | Reorientation | Flip | 平均 |
|---|---|---|---|---|
| RISE(纯视觉) | 90% | 90% | 40% | 73% |
| 3DTacDex-P(直接拼接) | 30% | 60% | 30% | 40% |
| FoAR(阈值+接触概率) | 20% | 90% | 40% | 50% |
| AdapTac(本文) | 100% | 90% | 90% | 93% |
读数(作者分析): - RISE 在视觉强的任务(Open Box/Reorient)好,但 Flip 仅 40%——该任务靠触觉,纯视觉缺这条腿(与 3DTacDex 的发现一致)。 - 3DTacDex-P 整体最差(40%),甚至不如纯视觉 RISE。作者归因:训练时它手关节预测误差更低,疑似过拟合触觉模式(不同演示触觉相似而视觉因工作区大而多变)。 - FoAR 即便精心选阈值仍不稳:Reorient 好(90%),但 Open Box(20%)/Flip(40%)崩——专家数据里接触频繁变化使手动阈值不可靠、接触标签不一致。 - AdapTac 靠动态调权、无需人工标注避开触觉过拟合,三任务稳定。
5.3 消融一:力引导注意力融合是否有效(表 II)¶
| 方法 | Open Box | Reorientation | Flip | 平均 |
|---|---|---|---|---|
| 去掉 FFPG 和 FGAF(≈3DTacDex-P 直接拼) | 30% | 60% | 30% | 40% |
| 去掉 FFPG(只留注意力 FGAF) | 80% | 70% | 50% | 67% |
| AdapTac(全) | 100% | 90% | 90% | 93% |
注:FGAF = 力引导注意力融合;FFPG = 未来力预测与引导。只加注意力模块,平均从 40%→67%;且观察到策略确实逐阶段调权(非过拟合)。但因数据不平衡,视觉仍普遍被优先于触觉——这正解释了"只有注意力≈RISE",凸显未来力预测/引导的必要。
5.4 消融二:未来力预测(FFP)与引导(FFG)的重要性(表 III,Flip 任务)¶
新指标 AEL=所有 run 的平均 episode 长度(失败 run 记最大步长),越小越"一次成功"。
| 配置 | 力预测类型 FP-T | 引导力类型 GF-T | 成功率 SR | AEL |
|---|---|---|---|---|
| 去掉 FFP & FFG | - | - | 50% | 221 |
| 加观测力预测+引导(OFP+OFG) | 观测 | 观测 | 70% | 182 |
| 去 FFG、用未来力预测+观测引导 | 未来 | 观测 | 90% | 166 |
| AdapTac | 未来 | 观测+未来 | 90% | 113 |
读数:两者全无仅 50%;加观测力预测/引导→70%;把"观测力预测"换成"未来力预测"→90%。OFP/FFP 下接触时都把更多注意力给触觉,说明力预测确实强化了触觉、改善了平衡。FFG 的价值在效率/安全:去掉 FFG(
Ours w/o FFG)常需多次尝试,AEL 高达 166,且有"持续挤压板子"等冒险行为;完整 AdapTac 通常一次成功(AEL 113)。
5.5 注意力分析(图3)¶
所有任务 reach 阶段更多看视觉;手开始操作物体后注意力转向触觉——证明确有有效的阶段性调整。但 reorient 任务权重变化不大:触觉接触时确实涨,但视觉仍维持较高——因为 reorient 全程都要视觉判断"是否转到正确角度",不只 reach 时需要。
5.6 未见物体泛化(表 IV)¶

5 个不同颜色/几何的未见物体,每个换随机位姿测 4 次:
| 方法 | Open Box | Reorientation | Flip | 平均 |
|---|---|---|---|---|
| AdapTac | 85% | 75% | 65% | 75% |
即使几何差异大(reorient 用小纸杯、flip 用白板擦)仍达 75%,显示较强泛化。
6. 核心洞见 / 结论¶
- 关键结论:把"该多看视觉还是多信触觉"交给力信号去动态决定,比"固定视觉主导 + 人工阈值"(FoAR 路线)更通用、更稳——核心是用力当 query 做跨模态注意力,再用未来力预测这个自监督任务把触觉这条腿"扶起来",对抗数据不平衡。
- 两个真正起作用的点:① 注意力模块把平均 40%→67%(学会阶段性调权);② 未来力预测+引导再 67%→93%(强化触觉 + 一次成功)。两者缺一不可。
7. 局限 / 存疑(诚实)¶
- 作者自陈:方法虽泛化强,但不能保证所有任务全成;建议结合强化学习进一步提鲁棒(明确写进 Limitations)。
- 规模小:每任务仅约 30 条演示、评测每方法每任务 10 次——成功率粒度粗(10% 一档),统计噪声大,差异需谨慎解读。
- 任务少:仅 3 个任务、单臂单手单相机,未跨本体/跨相机验证。
- 依赖专用触觉硬件:PaXini 指尖+指腹阵列 + 预训练触觉编码器(3DTacDex)——迁到别的触觉传感器需重训编码器。
- 开源范围:项目页有视频与代码指引,但数据是否公开未在文中声明 → 复现性待核。
- 细节待核:
α(力预测损失权重)、n/h具体取值、扩散头层数等超参文中未给数值 → 待核。
8. 对我们(深一层)¶
- 直撞我们的"力引导/预测性触觉门控"主线:AdapTac 与 卡片-TacForeSight(详见 详读-TacForeSight)、卡片-FoAR 同属"用力/接触状态去门控视触觉"这条线,且 AdapTac 是其中去人工标注、连续自适应的最新一环——必读对照。
- 与 FoAR 的关键差异可借:FoAR=接触概率(标量、需阈值、假设视觉主导);AdapTac=力当 query 的多模态注意力(无阈值、不假设主导)。这套"信号当 query 去 attend 各模态"的范式,对我们设计轻量门控有直接参考。
- 预测力作"自监督副任务"很值得抄:在缺触觉/弱触觉场景,用未来力预测当辅助损失去强化弱模态、对抗数据不平衡——这个 trick 与本体硬件解耦,可迁移。
- 互为对照(路线差异):AdapTac 加密集指尖+指腹触觉阵列把融合做精;另一类思路是用更少/更廉价的力触觉做接触感知——两条路线可长期对照(亦可对照 卡片-OmniVTA、卡片-ReactiveDiffusionPolicy 的力反应式路线)。
- 同生态:基础策略 RISE、3D 扩散、DexPilot 重定向、Leap Hand、3DTacDex 预训练编码器——与本库触觉/灵巧操作方向高度重叠。