详读 · TVL(触觉-视觉-语言多模态对齐数据集 + 语言对齐触觉编码器)¶
卡片版见 卡片-TVL。本页是全文精读:动机 → 数据集(采集/清洗/标注) → 方法(逐模块) → 实验(全表) → 消融 → 洞见/局限 → 对我们。 来源:arXiv 2402.13232(2024-02-20,ICML 2024)· 项目页 · 代码 Max-Fu/tvl 作者:Letian Fu、Gaurav Datta、Huang Huang、William Chung-Ho Panitch、Jaimyn Drake(UC Berkeley)+ Joseph Ortiz、Mustafa Mukadam、Mike Lambeta(Meta AI)+ Roberto Calandra(TU Dresden)+ Ken Goldberg(Berkeley)
0. 一句话定位¶
触觉至今没被接进多模态生成式语言模型。难点有二:① 触觉数据很难拿到自然语言标注;② 把触觉同时对齐到视觉 + 语言很复杂。TVL 的解法是:自制手持设备同步采 44K「视觉-触觉」对,只人工标 10%(SSVTP 子集)、其余 90% 用 GPT-4V 伪标注(HCT 子集);据此用三模态两两对比学习训一个语言对齐的触觉编码器(开放词表分类),再微调 LLaMA2-7B 得 TVL 模型,能从触觉+视觉生成自然语言触感描述。
1. 问题与动机(图1)¶
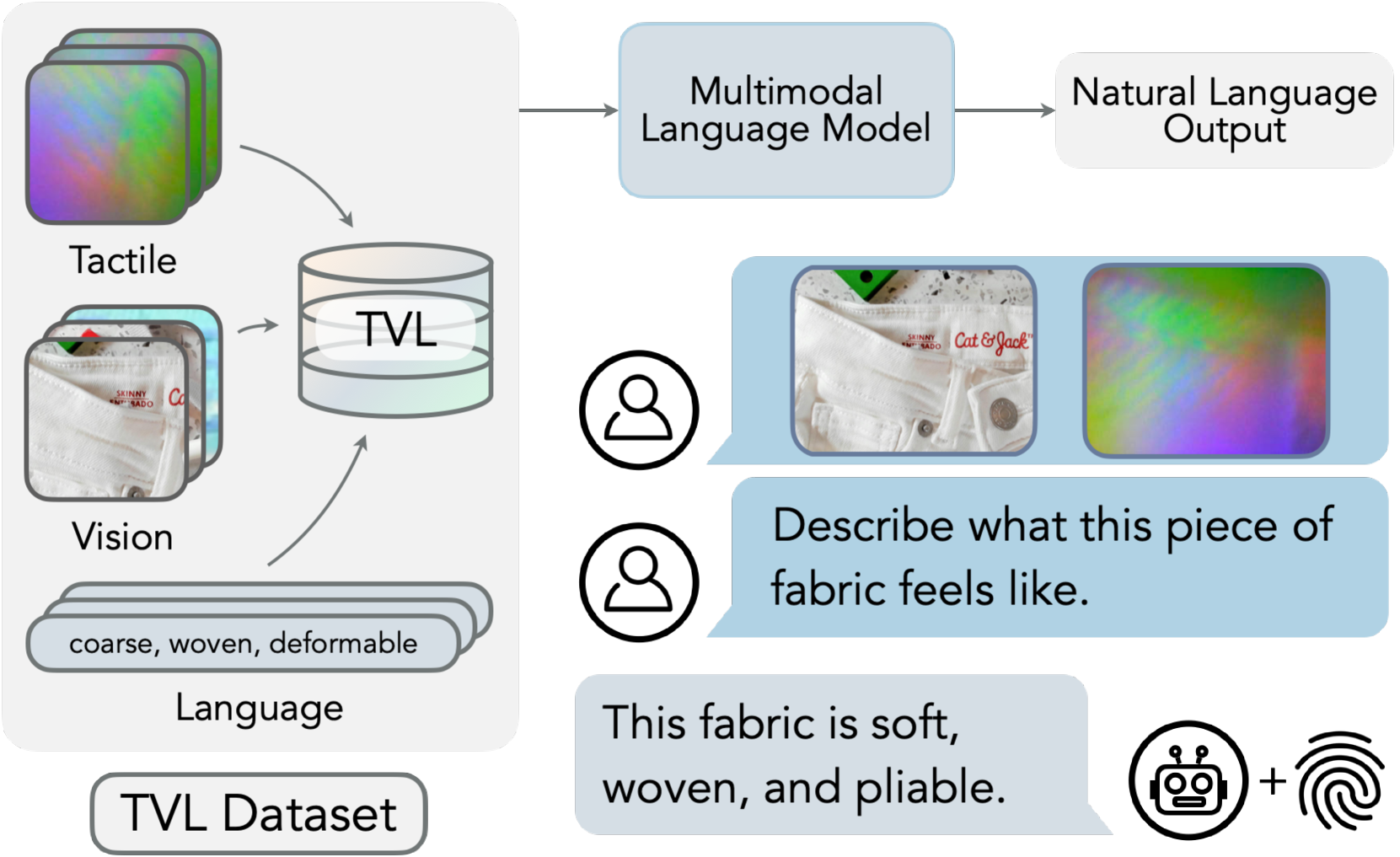
- 几乎所有生物感知都天生多模态;多模态表征学习已链起视觉、语言、音频、温度、机器人动作(CLIP / ImageBind / RT-2 等),唯独触觉仍欠开发。
- 触觉能让人区分表面纹理、材质、尺寸、接触力,在接触密集型操作里尤其有用。
- 前人多做"触-视关联"或在闭集词表上分类材质/纹理/布料(GelSight、Yang 2022 等)——但人类触觉的语义远不止"触-视配对",它与语言深度耦合。据作者所知,此前没有任何带开放词表语言标注的触觉数据集。
- 两大障碍:① 数据稀缺(要"野外"采集,不在受控实验室);② 人工标注贵、且触感描述主观、因人而异。→ 解法:借鉴 LLM/VLM 用"自己或现成大模型合成的数据"训练的思路,用现成 GPT-4V 当 captioner,把视觉观测翻译成触感描述,缓解触觉-语言标注稀缺。
2. TVL 数据集(图2、图3)¶
2.1 硬件与采集(图2)¶
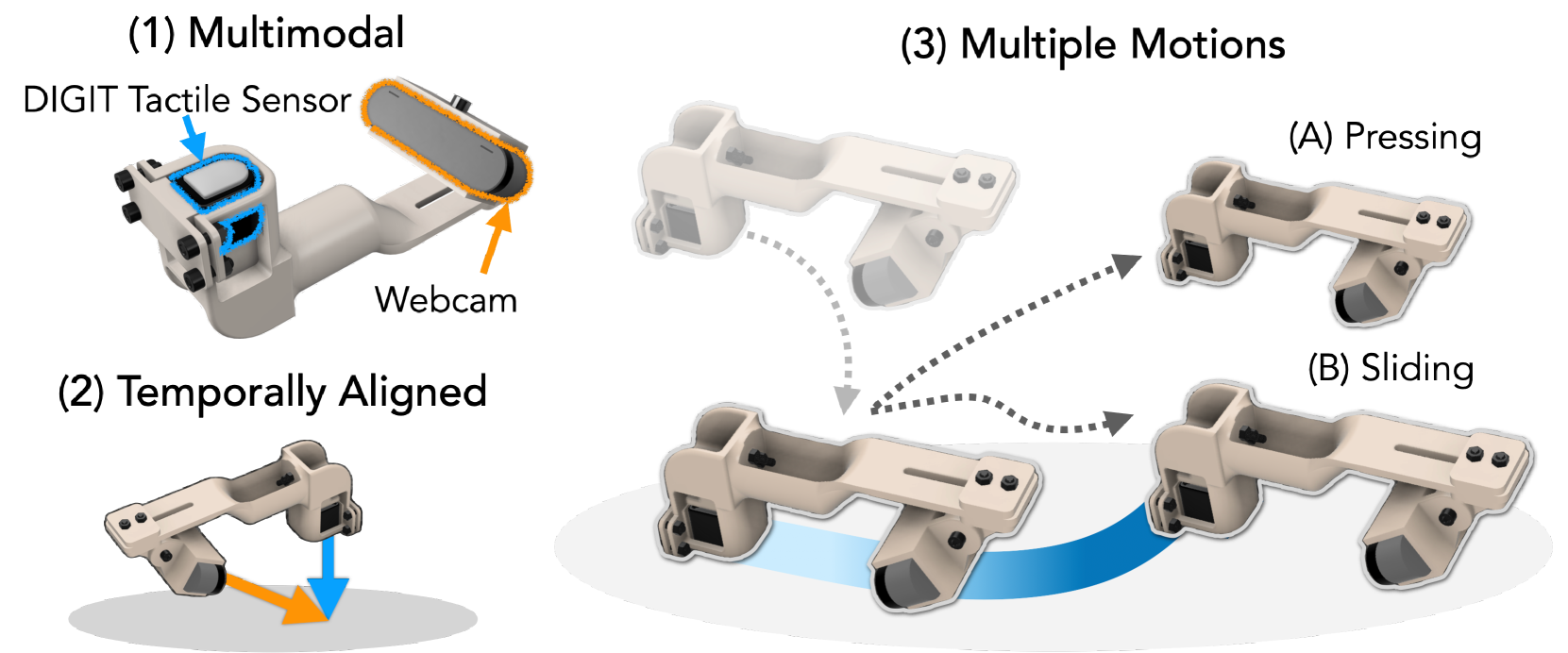
- 视觉:Logitech BRIO 网络摄像头;触觉:DIGIT(低成本、紧凑、开源的视觉式触觉传感器,输出内部可形变面的 RGB 触觉图)。
- 原始数据由两个子集拼成:
- SSVTP(沿用 Kerr 2023):4,587 对图-触;由 UR5 机器人采——先俯拍工作面上预排的物体,再把 DIGIT 压到对应位置。两个缺陷:① 实验室环境物体多样性受限;② 触觉与视觉异步采集易错位(机器人可能碰动物体)。
- HCT(Human Collected Tactile,本文新采):5 名采集者、共 20 小时、用图2 的手持 3D 打印设备采。设备以 30 Hz 同步记录视觉+触觉。数据按"触摸轨迹"组织(接近→接触→滑动→离开),按是否接触分 in-/out-of-contact。视觉以斜角拍,使传感器与接触点始终在视野内以保同步性。鼓励采集者找有趣纹理/边缘。HCT 留 1% 做手标测试集,其余 GPT-4V 伪标。
2.2 清洗:判断"是否接触"¶
- 用 SSVTP 预训练触觉编码器区分 in-/out-of-contact:假设每条轨迹首尾帧为非接触,取其均值作背景参考帧并编码;对每帧算其触觉隐向量与背景的余弦相似度,< 0.6 即判为接触。
- 清洗后得 43,741 对接触帧 + 169,292 对非接触帧。
2.3 语言标注(图3)¶

- 人工标注(SSVTP):因 SSVTP 触-视对齐强,用它当"触-语"对齐基础;给标注者一份 400 词的触觉词表,每条选至多 5 个最贴切的形容词描述材质/触感。
- GPT-4V 伪标注(HCT 接触部分):经验发现同时给全图 + 接触点局部裁剪图,能让 GPT-4V 产出更贴近人工的标签(全图杂物多易跑偏)。
- 失败兜底:GPT-4V 对运动模糊/弱光图会失败或拒答 → 先尝试同轨迹其它帧;仍缺则从同轨迹其它接触帧的词集里随机采样补;若整条轨迹都标不出,则整条剔除训练集。处理后剩 39,154 张伪标图。
2.4 数据集统计(全量数字)¶
- SSVTP:4,587 独立图-触对(每点一条独立触摸轨迹)。
- HCT:39,154 接触图-触对 + 169,292 非接触对;非接触为 1,486 条连续轨迹(每条含一或多次接触事件)。
- 人工+GPT-4V 合计用了 254 个不同触觉形容词。
- 99%-1% 训练-测试划分(两子集都切),测试集 402 对图-触全部人工标注。
- 平均用词:GPT-4V 在 HCT 上 4.25 个形容词/条;人工 2.70 个/条。
3. 方法(图4)¶
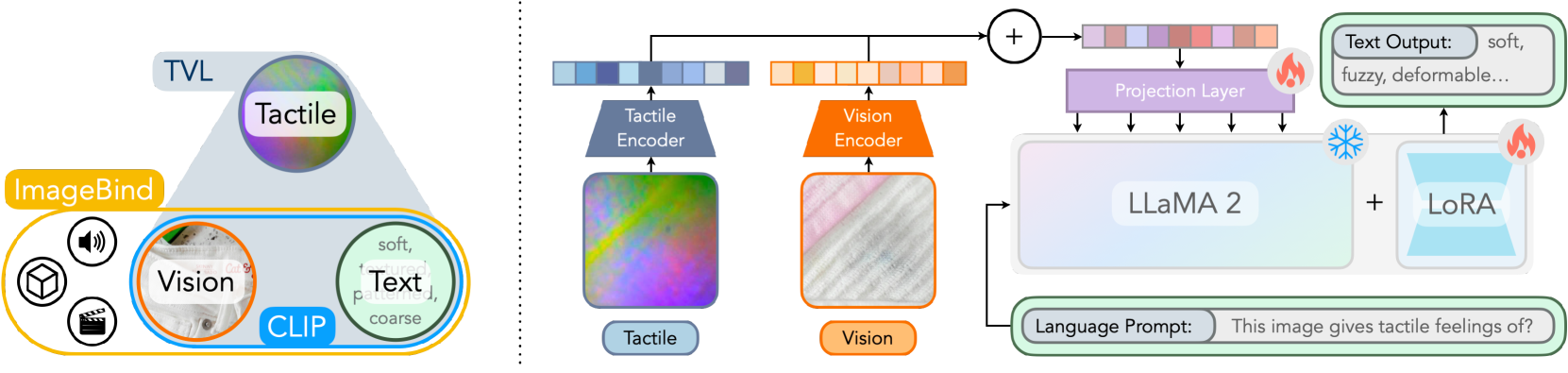
3.1 预备:ImageBind / ImageBind-LLM¶
- ImageBind:跨 6 模态(图像、文本、音频、深度、热成像、IMU)学联合嵌入;只用"视觉+某模态"的成对数据,把所有模态都绑到视觉。视觉/语言编码器取自 OpenCLIP 且冻结,其它模态编码器随机初始化,各接一个可训练 adapter 投到同维隐空间,用 InfoNCE 对比训练。
- ImageBind-LLM / LLaMA-Adapter:高效指令微调——(1) 把多模态观测平均成单个 token;(2) 用零初始化门控自适应融合多模态 token 与语言模型;先预训门控+投影器,再用 LoRA 微调语言模型。
3.2 触觉编码器(核心改动)¶
- 关键差异:不像 ImageBind 把所有模态都绑到视觉,TVL 对每一对模态都算对比损失——视觉-语言、触觉-语言、触觉-视觉,给触觉模态更强监督(尤其补上"触觉↔语言"这条直连)。
- 触觉编码器是随机初始化的 ViT,测三种尺寸:ViT-Tiny 5.7M / ViT-Small 22M / ViT-Base 86M 参数。
- 抗过拟合(44K 接触数据偏小,直接套 ImageBind 配方会过拟合):发现引入非接触(背景)数据能借提升视觉多样性缓解过拟合 → 让训练数据里 γ=10% 为非接触样本、标签设为 "background"。
- 去掉视觉/语言编码器的投影器,让触觉编码器直接投到原始 CLIP 的公共隐空间。
- 再对每张图的触觉描述词随机打乱并取子集,增加语言标签多样性。
3.3 与语言模型对齐(TVL-LLaMA)¶
- 沿用 ImageBind-LLM 的两阶段训练,把 ImageBind 编码器换成 TVL 编码器。
- 预训练:LLaVA Visual Instruct CC3M 595K 子集 + TVL 数据集(对 CC3M,触觉模态喂空白触觉图)。
- 微调:TVL + Alpaca + LLaVA Visual Instruct 150K 混合。
- 注意:经验上只用 TVL 自己的数据不足以越过 LLaMA2 的安全微调——模型会拒答触感问题,故须混入通用指令数据。
4. 实验¶
4.1 评测设置与指标¶
- 开放词表触觉分类:把 402 条人工标测试集当 402 类分类问题,量触觉编码器的 top-1/top-5(触-视、触-语)。
- 同义词处理:因触感可有多种近义表达、且 CLIP 语言嵌入非排列不变("soft, smooth" 与 "smooth, soft" 嵌入不同),作者让 GPT-4 为人工词表每词生 5 个同义词,得 799 个不同形容词;取原词与其同义词余弦相似度的最小值为阈值 φ=0.636,凡测试集中与某图原标签相似度 > φ 的标签都算"正确标签",据此算 top-1/top-5。
- TVL Benchmark(触觉语义描述):给模型全图 + 接触点裁剪图 + 触觉图,要求用≤5 个形容词描述触感;再用纯文本 GPT-4 按与人工真值的契合度打 1-10 分并解释。基线含多个开源 VLM 与 GPT-4V,外加 SSVTP-LLaMA(用 SSVTP 触-视编码器微调的语言模型)。
4.2 跨模态分类结果(表1,ViT-Tiny)¶

| 模型 | 触-语 Top-1 | 触-语 Top-5 | 触-视 Top-1 | 触-视 Top-5 | 视-文 Top-1 | 视-文 Top-5 |
|---|---|---|---|---|---|---|
| CLIP (OpenCLIP) | - | - | - | - | 28.4% | 64.9% |
| SSVTP | - | - | 0.2% | 0.3% | - | - |
| TVL | 36.7% | 70.3% | 79.5% | 95.7% | 28.4% | 64.9% |
关键读数:① TVL 触觉编码器触-语 top-1(36.7%)甚至高于 OpenCLIP 的视-文 top-1(28.4%),说明原始 CLIP 抓不好触觉语义;② SSVTP 因只在实验室小数据上训,在"野外"全集上触-视仅 0.2%,几乎不泛化 → 印证扩大触-视数据集的必要;③ TVL 的视-文分数与 OpenCLIP 相同(因直接复用其冻结编码器)。
4.3 触觉语义生成结果(表2,TVL Benchmark,GPT-4 打分 1-10)¶
| 模型 | 预训练模态(V/T/L) | SSVTP | HCT | TVL | p 值(vs GPT-4V, d.f.=401) |
|---|---|---|---|---|---|
| LLaVA-1.5 7B | V·L | 3.64 | 3.55 | 3.56 | 1.21×10⁻⁹ |
| LLaVA-1.5 13B | V·L | 3.55 | 3.63 | 3.62 | 1.49×10⁻⁹ |
| ViP-LLaVA 7B | V·L | 2.72 | 3.44 | 3.36 | 8.77×10⁻¹⁶ |
| ViP-LLaVA 13B | V·L | 4.10 | 3.76 | 3.80 | 1.72×10⁻⁶ |
| LLaMA-Adapter | V·L | 2.56 | 3.08 | 3.02 | 2.68×10⁻¹⁷ |
| BLIP-2 Opt-6.7b | V·L | 2.02 | 2.72 | 2.64 | 1.92×10⁻³¹ |
| InstructBLIP 7B | V·L | 1.40 | 1.30 | 1.31 | 1.07×10⁻⁸⁴ |
| InstructBLIP 13B | V·L | 1.44 | 1.21 | 1.24 | 4.64×10⁻⁸⁸ |
| GPT-4V | V·L | 5.02 | 4.42 | 4.49 | -(基准) |
| SSVTP-LLaMA | V·T | 2.58 | 3.67 | 3.54 | 1.79×10⁻⁹ |
| TVL-LLaMA (ViT-Tiny) | V·T·L | 6.09 | 4.79 | 4.94 | 4.24×10⁻⁵ |
| TVL-LLaMA (ViT-Small) | V·T·L | 5.81 | 4.77 | 4.89 | 6.02×10⁻⁴ |
| TVL-LLaMA (ViT-Base) | V·T·L | 6.16 | 4.89 | 5.03 | 3.46×10⁻⁶ |
关键读数:① 所有 TVL-LLaMA 版本都超过它的标签生成者 GPT-4V(TVL 列 5.03 vs 4.49,约 +12%),说明模型能泛化出超越那 10% 人工标的能力;② 开源 VLM 普遍弱于 GPT-4V(差距来源是它们的视觉训练数据缺人类触感聚焦);③ SSVTP-LLaMA(缺触-语对齐)分数明显更低(3.54),印证触-语对齐的必要;④ 所有对比在 α=0.05 下统计显著。
论文摘要里的三个"招牌数字":触觉编码器对齐 +29%(相对仅用两模态训的编码器/通用 OpenCLIP 的分类);TVL-LLaMA 比 GPT-4V +12%、比开源 VLM 至少 +32%。
4.4 消融与敏感性(表3,均用 ViT-Small;baseline=默认设置)¶
| 维度 | 设置 | 触-语 % | 触-视 % |
|---|---|---|---|
| (a) 模型尺寸 | ViT-Tiny | 36.7 | 79.5 |
| ViT-Small | 36.3 | 78.0 | |
| ViT-Base | 30.7 | 81.7 | |
| (b) 触-语损失 | Enabled | 36.3 | 78.0 |
| Disabled(≈ImageBind式) | 20.3 | 81.6 | |
| (c) 模态 | All | 36.3 | 78.0 |
| −Vision | 29.9 | 1.0 | |
| −Text | 21.5 | 85.8 | |
| (d) 接触数据混比 | 仅接触 | 36.2 | 80.1 |
| +10% 非接触 | 36.3 | 78.0 | |
| (e) prompt | Baseline | 36.3 | 78.0 |
| +Prompt | 37.7 | 78.7 | |
| (f) 训练数据 | 仅 SSVTP | 19.2 | 8.0 |
| 仅 HCT | 38.4 | 74.4 | |
| TVL(全) | 36.3 | 78.0 |
消融要点:① (b) 关掉触-语损失(退化成 ImageBind 式只绑视觉),触-语骤降 36.3→20.3——直接证明"用语言监督触觉"是关键贡献;② (c) 去掉视觉模态触-视塌到 1.0%,三模态全用才整体最好;③ (d) 加 10% 非接触数据对测试集触-视反略降(80.1→78.0),但作者称它防过拟合(附录),故仍保留;④ (f) 仅 HCT(纯伪标)就能逼近/超过全集(触-语 38.4 vs 36.3),说明伪标自监督能大幅降低对全量人工标注的依赖——这是"90% 伪标"配方的核心证据;⑤ (a) ViT-Base 验证集最高但测试集触-语反降(30.7),作者归因于分布漂移:GPT-4V 训练标签不如人工测试标签细致准确,大模型反而过拟合到伪标分布。
5. 诚实读数 / 局限(作者自陈 + 观察)¶
- 触觉标签源于视觉,天花板有限:触觉与视觉本质不同,仅凭视觉派生的触感标签准确度有上限。
- 采集硬件视角遮挡:相机未必能无遮挡看到传感器接触的面/物 → 加大触-视对齐难度、降低伪标质量(图3 第4行就是失败案例)。
- 伪标失效会被继承:TVL-LLaMA 学自 GPT-4V 伪标,会继承 GPT-4V 的同样失效模式(被非接触杂物带偏;对 GPT-4V 加触觉输入无改善,因属分布外)。
- 大模型在小伪标数据上反吃亏:ViT-Base 测试集触-语反降(见消融 a)。
- 单传感器 DIGIT:全数据基于 DIGIT,跨传感器泛化未覆盖(弱于 卡片-T3/卡片-AnyTouch)。
- 偏感知/描述,非操作策略:产出是"触觉编码器 + 触感描述模型",未直接做操作策略。
- 并发工作对照:Yang 2024 同期把触觉绑到视觉做开放词表分类、且无需微调 ImageBind-LLM 即对齐语言——与本文路线相近但取舍不同。
6. 核心洞见¶
- 把"触觉↔语言"直连进对比学习(而非像 ImageBind 全绑视觉),是把触觉接进语言模型最干净的一步;消融 (b) 用 16 个点的硬数字证明了它。
- "少量人工 + 大量 VLM 伪标"是可行降本配方:10% 人工 + 90% GPT-4V,且消融 (f) 显示纯伪标 HCT 单独就够强 → 把昂贵的触觉-语言标注成本压到极低。
- CLIP 不自带触觉语义:原始 OpenCLIP 视-文对齐反而打不过 TVL 的触-语对齐,说明触觉需要专门的对齐监督。
7. 对我们(深一层)¶
- 接语言的桥:TVL 是"把触觉接进 VLA 的语言侧"最干净的范本,与 卡片-Tactile-VLA("VLM 已有物理常识")同一条线——TVL 给的就是"触觉↔语言"对齐编码器。三张表征卡选型口径:跨传感器→卡片-T3/卡片-AnyTouch;接语言→TVL;有对齐多传感器数据→卡片-AnyTouch。
- 伪标注配方可直接抄:我们以后采机器人触觉/操作数据时,"10% 人工 + 90% VLM 伪标"能大幅降本,正呼应雷达"批注=数据标注"的思路(见 概念-机器人数据与标注)。其失败兜底(同轨迹补标、整条剔除)也是可复用的工程细节。
- 互为对照的成本结构:TVL 用现成 GPT-4V 当 captioner、把标注成本搬到"推理"侧;DexTeleop-0 那条线是把成本搬到"采集硬件(指尖力)"侧——采数降本两条不同路线(见 详读-DexTeleop-0)。
- 可直接用的资产:代码 + 44K 数据 + 编码器/模型全开源(github Max-Fu/tvl),接语言侧可直接拿来当"触觉→语义"模块;唯一硬约束是只支持 DIGIT 单传感器。