详读 · DexTeleop-0(力觉驱动的双手灵巧遥操作)¶
卡片版见 卡片-DexTeleop-0。本页是全文精读:动机 → 方法(逐模块公式直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2606.23431(2026-06-22)· 项目页 作者:Haichao Liu、Yuyao Jiang、Yuanjiang Xue、Ziwei Wang(通讯)(南洋理工 NTU)+ Hyunsun Park(OOJU, US)
0. 一句话定位¶
在普通 VR 遥操作之上加一个 30Hz 实时优化环:用指尖力觉估计接触点/接触力,经操作空间雅可比把"人手粗略意图"实时修正成多指力平衡、力顺应的机器人指令 q_final = q_tele + Δq。作者把目标明确定位为——提升接触密集任务的"高质量数据采集效率"(喂给模仿学习/VLA)。
1. 问题与动机¶
- 多指灵巧手能做夹爪做不了的精细接触操作,但强依赖触觉(局部压力、瞬时滑移、多点接触动态)。
- 采数是瓶颈:① embodiment gap(人手↔机器人手形态不同→运动学映射不准);② 遥操作普遍没有力/触觉反馈→操作员感知不到细微接触状态 → 高精接触任务采数效率极低。
- 前人都不够:leader-follower 机械臂(GELLO/ALOHA)对夹爪精准但不scale到高 DoF 手;机械外骨骼笨重;纯视觉重定向遮挡/抖动漂移;VR/AR(Vision Pro、Quest)给了第一视角追踪但只有视觉、无力。
- DexTeleop-0 的切入:不声称感知硬件是创新,而是在现成 VR 追踪上加一层闭环力优化补上"物理感知"。
2. 核心思想:触觉平衡(图1)¶
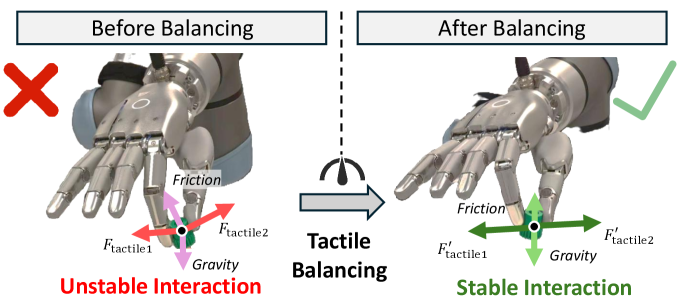 纯视觉遥操作只给运动学意图,接触时各指受力失衡(抵不过摩擦+重力)→ 物体打滑/被夹坏。DexTeleop-0 据实时指尖力动态微调手姿,把多指接触力调到平衡(稳定抓握)——这是其修正项的核心目标。
纯视觉遥操作只给运动学意图,接触时各指受力失衡(抵不过摩擦+重力)→ 物体打滑/被夹坏。DexTeleop-0 据实时指尖力动态微调手姿,把多指接触力调到平衡(稳定抓握)——这是其修正项的核心目标。
3. 系统架构(图2)¶
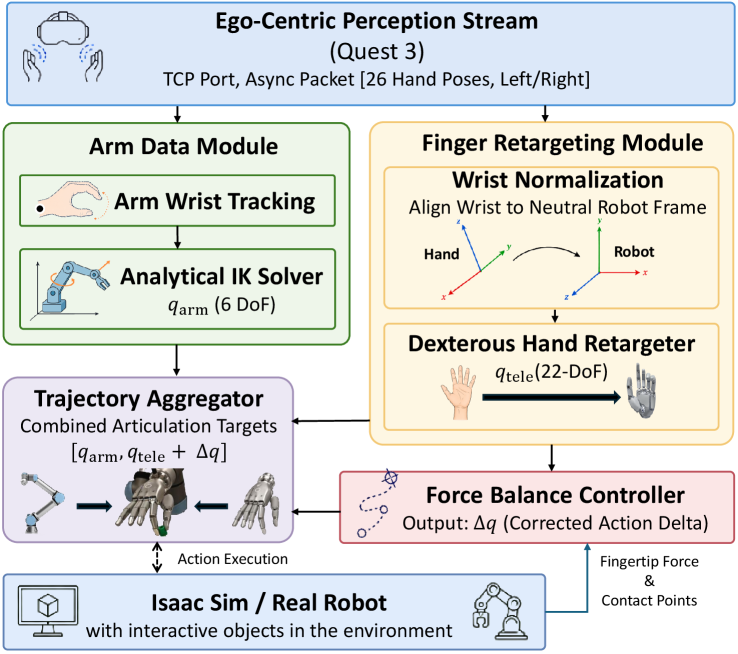 Quest3 异步发来左右手各 26 个手部位姿 → 臂:解析 IK 出 6-DoF
Quest3 异步发来左右手各 26 个手部位姿 → 臂:解析 IK 出 6-DoF q_arm;手:向量式重定向出 22-DoF q_tele → 力平衡控制器据指尖力/接触点算 Δq → 执行 [q_arm, q_tele+Δq],闭环回到 IsaacSim/实机。
4. 硬件(图3)¶
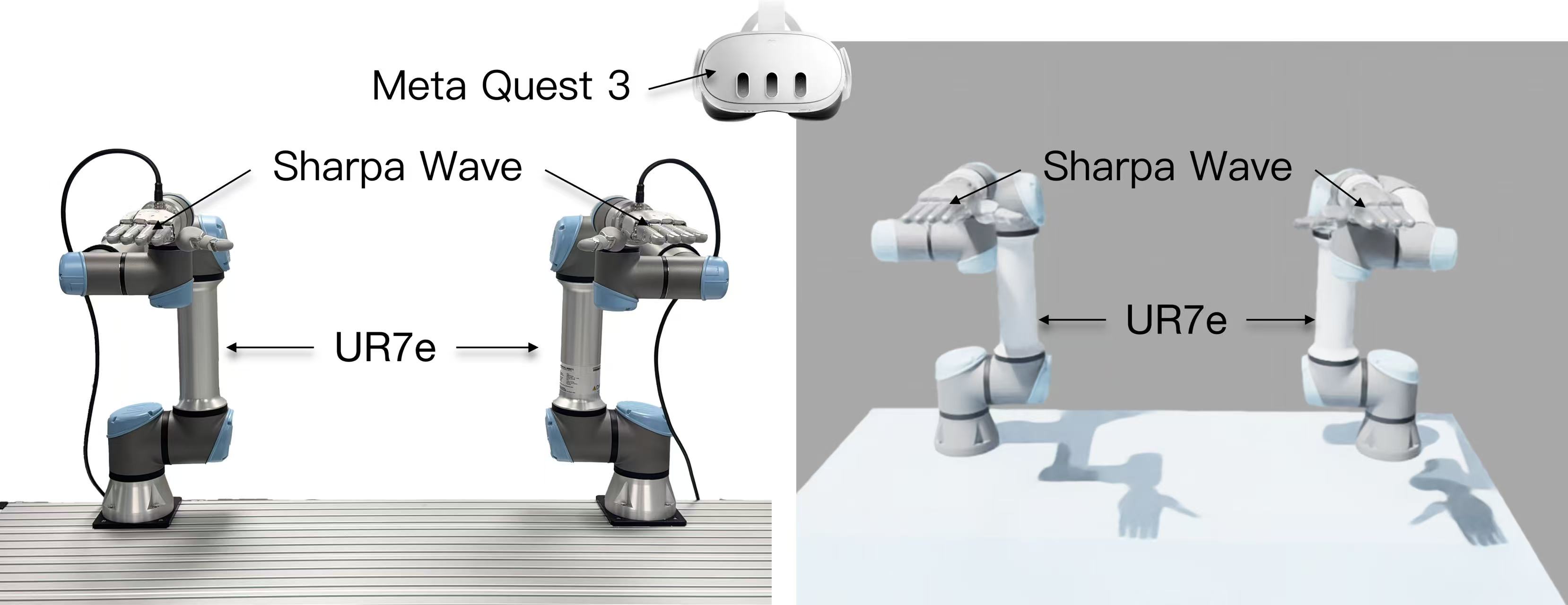 - 双臂:2× Universal Robots UR7e(各 6-DoF)
- 灵巧手:Sharpa Wave,每只 22-DoF → 全系统 56 并发自由度
- 力觉:指尖力传感,输出世界系接触力
- 双臂:2× Universal Robots UR7e(各 6-DoF)
- 灵巧手:Sharpa Wave,每只 22-DoF → 全系统 56 并发自由度
- 力觉:指尖力传感,输出世界系接触力 f_i 与接触点
- 感知:Meta Quest 3(第一视角手追,无外部动捕)
- 仿真:NVIDIA IsaacSim 4.5 数字孪生(与实机一致,便于 sim↔real)
5. 方法详解¶
5.1 灵巧手重定向(运动学层)¶
- 向量式(借鉴 DexPilot)而非对齐绝对关节角——避开人/机手形态失配;从 VR 取 K 组"指间/指到掌"关键向量,机器人侧用正运动学算对应向量去逼近。
- project-and-escape 滞回:对指尖对指尖向量,长度 <
d_project判为"要捏合"→ 投影到接触距离并加大权重w_high强约束接触几何;>d_escape才松开。防止该捏的时候捏不住。 - 优化(SLSQP, <15ms):
min Σ w_k·Huber(‖v_k−v_ref_k‖) + λ‖q_h−q_last‖²,Huber 抗 VR 测量离群,λ 正则贴上一帧→压高频抖动;带关节上下限。
5.2 触觉处理与接触状态估计¶
- 每指估世界系接触力
f_i与接触点p_i^w;物体参考中心p_obj = mean(p_i^w)(不需物体模型),相对位置p_i = p_i^w − p_obj。 - 滞回 logistic 激活权
w_i∈[0,1]:力 ≤f_release取 0、≥f_contact取 1、中间 sigmoid 平滑过渡(死区中点 m)。→ 每指按接触可靠度平滑参与优化(防抖、非接触不参与)。
5.3 局部力跟踪 ℓ_F(单指安全)¶
- 目标:让指尖力落在
[f_min, f_max]。交互矩阵A_F = Σ w_i(−J_i(q))(J_i=接触雅可比;负号让关节微调抵消过大力)。 - 力误差经虚拟刚度
K_F投影到位移域ρ_F = r_F / K_F;代价ℓ_F = λ_F‖A_F·Δq + ρ_F‖²(权重随接触权w_i放大)。
5.4 多指力矩平衡 ℓ_B(协同抓稳)¶
- 只修单指力会引入使物体打滑/旋转的净力矩。故评估物体中心净力
F=Σw_i f_i、净矩τ=Σw_i(p_i×f_i),对目标F*,τ*求偏差,加死区 ε 避免和单指安全项抢。 - 力矩用反对称叉积
A_τ = Σ w_i[p_i]×(−J_i(q));ℓ_B = λ_fb‖A_FΔq+ρ_F‖² + λ_tb‖A_τΔq+ρ_τ‖²。
5.5 统一力平衡 QP(@30Hz)¶
min ½Δqᵀ H₀ Δq + g₀ᵀΔq + ℓ_F(Δq) + ℓ_B(Δq),约束:关节物理限 q_min≤q+Δq≤q_max + 变化率(slew-rate)上限 δ(由最大关节速度定)。盒约束 QP、投影梯度求解。→ 保留 VR 主意图的同时,把执行指令投影到力顺应、物理稳定的流形上。
6. 实验¶
6.1 设置¶
- 基线:
No-Residual(纯运动学映射、不修正)、Joint-Level PD(指关节 PD 阻尼)、Single-Force Tracking(消融:只 ℓ_F、去掉多指平衡 ℓ_B)、DexTeleop-0(全)。 - 指标:多阶段成功率(把长任务拆成阶段,非顺序阶段不连带罚) + 接触力统计(拇指接触力均值±方差,越小越轻柔;注意它与成功率非单调——目标是"力小且稳")。
- 协议:仿真=同一遥操作轨迹回放、随机化物体质量/摩擦(同试次各方法一致);实机=7 名操作员(5 新手+2 熟练),每任务每方法各 5 次。
6.2 仿真结果(Ball Assembly / Stir in Cup)¶
| 任务 | 方法 | S1 | S2 | S3 | 接触力↓(N) |
|---|---|---|---|---|---|
| Ball Assem. | No Residual | 99 | 10 | 4 | 31.58±10.48 |
| PD | 100 | 6 | 1 | 29.96±9.75 | |
| Force Tracking(消融) | 84 | 78 | 78 | 11.03±5.01 | |
| DexTeleop-0 | 100 | 98 | 97 | 11.15±5.01 | |
| Stir in Cup | No Residual | 100 | 100 | 60 | 15.56±6.59 |
| PD | 100 | 100 | 6 | 12.45±5.28 | |
| Force Tracking | 100 | 100 | 49 | 8.01±2.50 | |
| DexTeleop-0 | 100 | 100 | 59 | 7.93±2.67 |
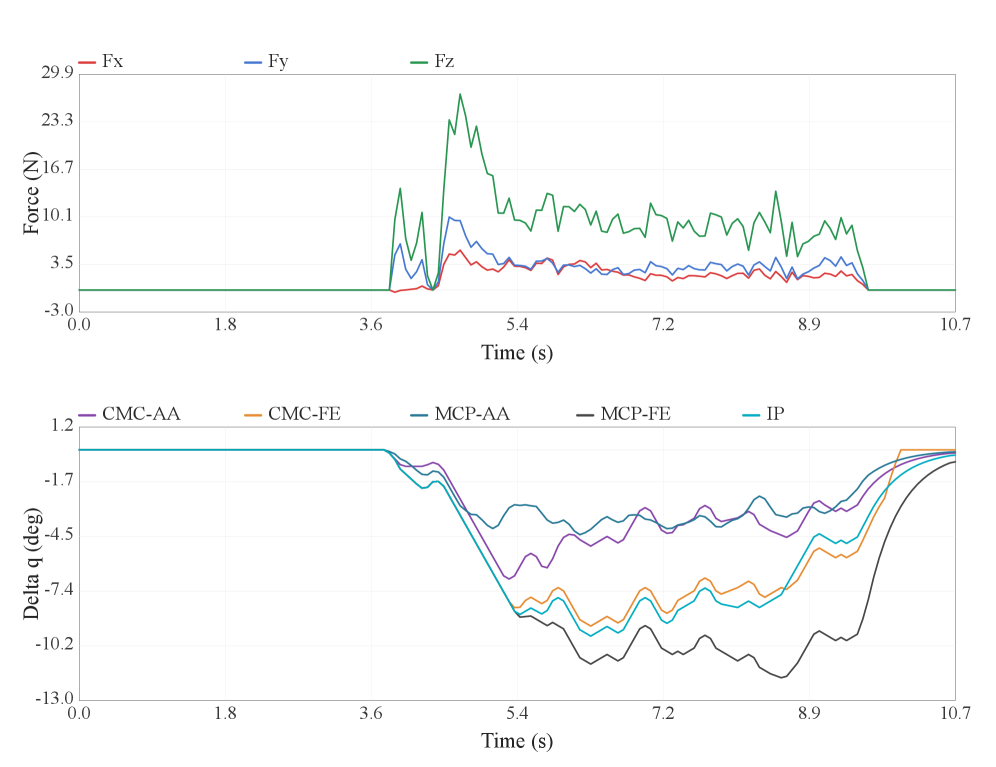
Ball Assembly:纯映射/PD 在 S1 后崩到 4%/1%(力高达 31.58N,球被挤飞);DexTeleop-0 把力压到 11.15N、S3 成功率 97%。
6.3 实机结果(齿轮/插孔/分拣/试管)¶
| 任务(关键阶段) | No Residual | PD | Force Tracking | DexTeleop-0 |
|---|---|---|---|---|
| Gear Mesh(S2 啮合) | 11.43 | 37.14 | 42.86 | 57.14 |
| Peg Insertion(S2 插入) | 25.71 | 34.29 | 62.86 | 60.00 |
| Food Sorting(S4 分拣完成) | 48.57 | 51.43 | 57.14 | 74.29 |
| Tube Operation(S3) | 34.29 | 25.71 | 57.14 | 77.14 |


相对纯遥操作/PD,成功率普遍大幅提升;多指平衡 ℓ_B 在双手任务(分拣/试管)对比消融"Force Tracking"再加一截。
6.4 诚实读数(作者自己点的)¶
- Stir in Cup:No-Residual S3(60%) 比本方法(59%)略高,但它用了2 倍接触力(15.56 vs 7.93N)——实机会撞坏东西;DexTeleop-0 用"微小成功率"换"力安全"。
- Peg Insertion:本方法接触力不是最低(5.17N,高于消融 3.72)——作者归因于操作员保守。→ 即:它的卖点是"力安全 + 成功率",不是每个指标都第一。
7. 核心洞见 / 未来¶
- 关键结论:把局部触觉修正 + 力平衡直接放进"追踪优化环",比单纯提高追踪分辨率更能闭合 embodiment gap、保证接触安全。
- 未来:加预测式滑移检测;用 DexTeleop-0 采到的视触觉演示训练通用模仿学习策略(工业/实验室装配)。
8. 局限 / 存疑(诚实)¶
- 依赖指尖力传感(成本/标定/易损)——也是"用更低成本硬件做接触感知"这一问题的反面。
- 开源未明确:有项目页,代码/数据是否放出文中未声明 → 复现性待定。
- 成功率是分阶段(非端到端整任务);力指标只用拇指。
- 仍是遥操作采数工具,不是自主策略——价值在"采得又快又好"。
9. 对我们(深一层)¶
- 数据护城河:直接攻"接触任务遥操作采数效率低",与 追踪-Sunday-Memo 手套、UMI 同一战场(见 概念-机器人数据与标注)。
- 同生态:参考文献含 UMI、DexCap、ALOHA、Diffusion Policy、Reactive Diffusion Policy(卡片-ReactiveDiffusionPolicy 我们有)、NeuralFeels(卡片-NeuralFeels 我们有)、GelSight——和本库高度重叠。
- 机制可借:力平衡 + 操作空间雅可比实时修正"人手→机器人"映射误差,补 embodiment gap。
- 互为对照:它加指尖力传感把采数做精;另一类思路用更少/更廉价的力触觉做接触感知——两条路线可长期对照。