详读 · Cosmos(NVIDIA 面向 Physical AI 的世界基座模型平台)¶
卡片版见 卡片-Cosmos。本页是全文精读:动机 → 逐模块方法(数据管线 / tokenizer / 扩散 WFM / 自回归 WFM / 后训练)→ 全量数字表 → 局限 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2501.03575(v3, 2025-07-09)· 作者:NVIDIA(平台架构师 Ming-Yu Liu,贡献者数十人)· 开源 github.com/NVIDIA/Cosmos,权重以 NVIDIA Open Model License 开放(Cosmos-Predict1)。 论文很长(75 页),本页抓主干:tokenizer / 扩散与自回归 WFM / 数据管线 / 机器人后训练。
0. 一句话定位¶
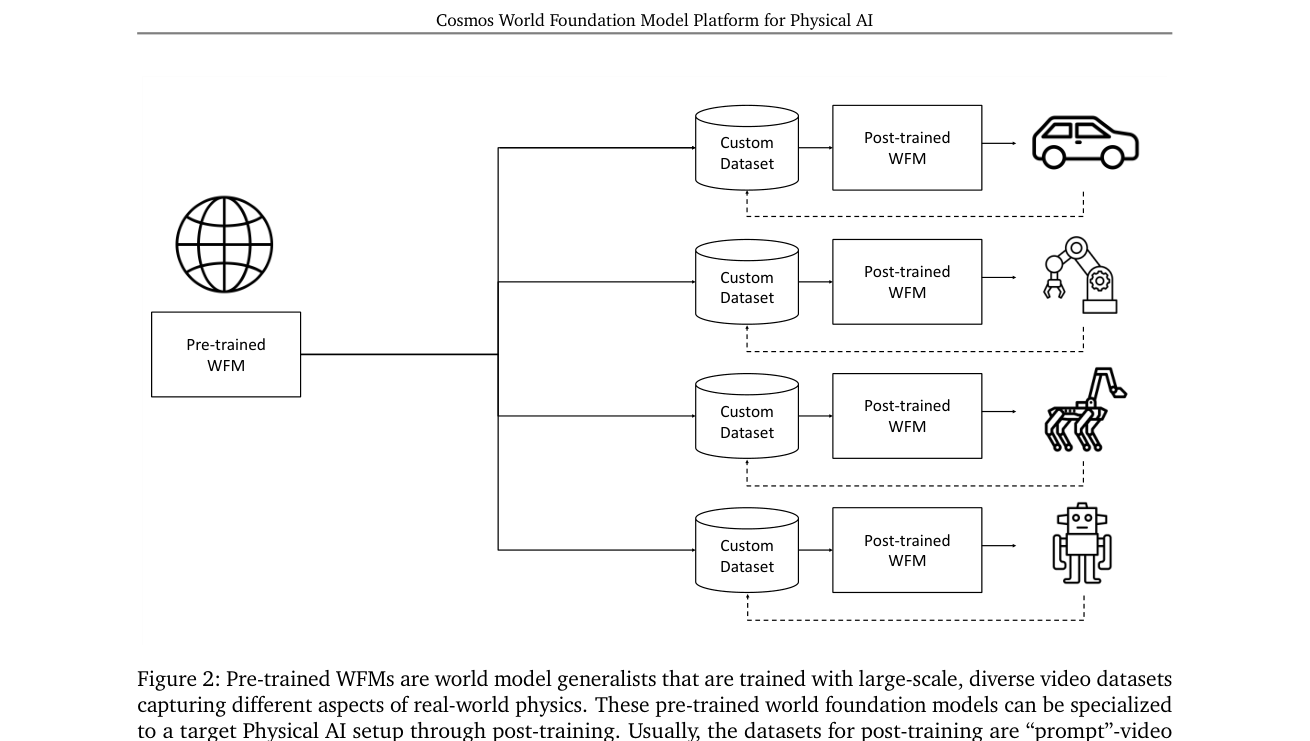
Cosmos 不是单个模型,而是一个"世界基座模型(World Foundation Model, WFM)平台":用海量真实视频预训练一个"会预测未来画面"的通用世界模型,再让开发者用各自机器人/车的小数据后训练成定制世界模型。平台五件套:视频整理管线 + 视频 tokenizer + 预训练 WFM(扩散 & 自回归两族)+ 后训练样例 + 安全护栏。类比:OpenVLA 之于 VLA,Cosmos 想当"世界模型那一层"的可下载底座。
形式化:WFM 是一个函数 𝒲,给定过去观测 x_{0:t}(RGB 视频)+ 当前扰动 c_t(动作 / 文本 / 随机扰动),预测下一帧 x̂_{t+1}。
1. 动机:Physical AI 的数据墙¶
- Physical AI=带传感器+执行器、能观察并改变世界的 AI(机器人、车)。它进展慢,因为采数难且危险:要"观测-动作"交错序列,而探索性动作可能损坏系统/环境。
- WFM = 物理世界的数字孪生,让策略可以在"数字世界"里安全交互,绕开真机采数的成本与风险——这是长期梦想的"数据扩展难题"解药。
- 论文聚焦视觉 WFM:观测是视频,扰动可多种形式。范式 = 先预训练(通才)→ 后训练(专才)。
WFM 对开发者的 5 类用途(论文只列举、未做实证,明确说留待 future work): 1. 策略评估:在 WFM 里跑策略,比真机便宜快;能在不可得的环境里测;快速淘汰差策略。 2. 策略初始化:WFM 学到的世界动态可当策略的好初始化,缓解数据稀缺。 3. 策略训练:WFM + 奖励模型 = 强化学习的环境代理。 4. 规划 / MPC:模拟不同动作序列的未来,挑最优执行(WFM 精度上界=决策上界)。 5. 合成数据生成:生成训练数据;可条件化于深度/语义图做 Sim2Real。
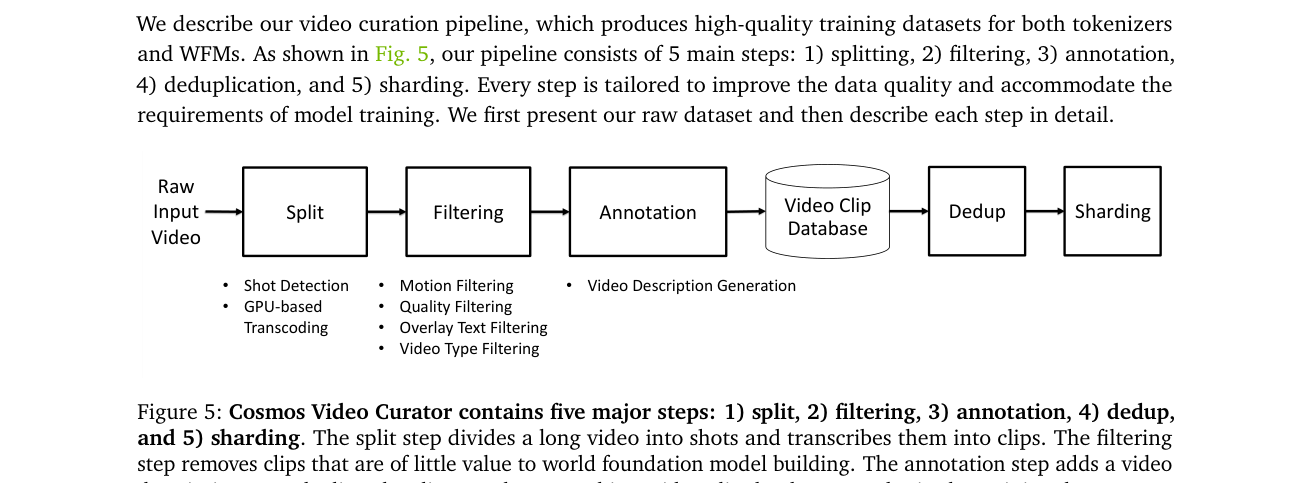
2. 数据整理管线(Sec.3)¶
数据决定模型天花板。管线 5 步:切分 → 过滤 → 标注 → 去重 → 分片。
- 原始库:约 20M 小时原始视频(720p–4k)→ 切出约 10⁸(≈1亿)个 2–60s 片段用于预训练,约 10⁷ 用于微调。
- 切分:镜头边界检测,对比 PySceneDetect / Panda70M / TransNetV2 / AutoShot;选 TransNetV2(端到端神经网络,能上 GPU 加速、对复杂镜头切换更稳)。自建基准 ShotBench。
- 转码:统一成高码率 mp4。L40S 比 H100 吞吐高 ~17%(0.0674 vs 0.0574 videos/s,因 L40S 有 NVENC,H100 只有 NVDEC);用 PyNvideoCodec 替代 ffmpeg 转码吞吐 0.3702 vs 0.1026;组合优化后 ≈6.5× 提速。
- 过滤:运动过滤(光流分类器,去静止/乱抖;标注 pan/zoom/tilt);质量过滤(DOVER 去底部 15%,美学阈值 3.5);叠字过滤(InternVideo2 嵌入 + MLP,去后期加的字幕);类型过滤(去掉游戏/动画/抽象画面,上采样人/物交互类)。
- 标注:用 VILA-13B(FP8 TensorRT-LLM,比 PyTorch FP16 快 10×)每片生成描述,平均 559 字符 / 97 词;每 256 帧一条 caption。
- 去重:SemDeDup + InternVideo2 嵌入 + GPU k-means(k=10,000),去掉约 30% 数据。
- 基础设施:基于 Ray 的流式管线,跨地理分布集群,解耦数据搬运与计算。
视频类别分布(占比):
| 类别 | 占比 |
|---|---|
| 自然动态(Nature dynamics) | 20% |
| 手部动作/物体操作(Hand motion & object manipulation) | 16% |
| 空间感知与导航(Spatial awareness & navigation) | 16% |
| 驾驶(Driving) | 11% |
| 人体动作/活动(Human motion & activity) | 10% |
| 第一视角(First-person POV) | 8% |
| 动态镜头运动(Dynamic camera movements) | 8% |
| 其它(Others) | 7% |
| 合成渲染(Synthetically rendered) | 4% |
注意:与机器人最相关的"手/物操作 16% + 第一视角 8%"加起来仅约 1/4,自然风光/驾驶等占大头——这点后面"对机器人有多大用"会回来谈。
3. 视频 Tokenizer(Sec.4)¶
把视频压成紧凑 token(像视频编解码器),是 WFM 训练的前置瓶颈。Cosmos Tokenizer 一套架构同时支持连续/离散、图像/视频、各压缩率。
- 架构:编码器-解码器,时序因果(只看当前+过去帧)→ 既能当图像 tokenizer(单帧)又能当视频 tokenizer,且贴合 Physical AI 的因果世界。先做 2 级小波变换(在小波空间去像素冗余),再用因果 3D 卷积(空间 1×k×k + 时间 k×1×1,左 padding 保因果)+ 因果时空注意力;Swish 激活、LayerNorm。
- 连续 tokenizer:vanilla AE,latent 维 16。离散 tokenizer:FSQ 量化,6 维 latent,levels (8,8,8,5,5,5) → 词表 64,000。
- 压缩率:图像 8×8 / 16×16;视频 4×8×8 / 8×8×8 / 8×16×16(T×H×W)。
- 训练:图像/视频交替小批;两阶段损失(L1 + VGG 感知 → 加光流损失 + Gram 矩阵 + 对抗损失);不用 KL/commitment 辅助损失。
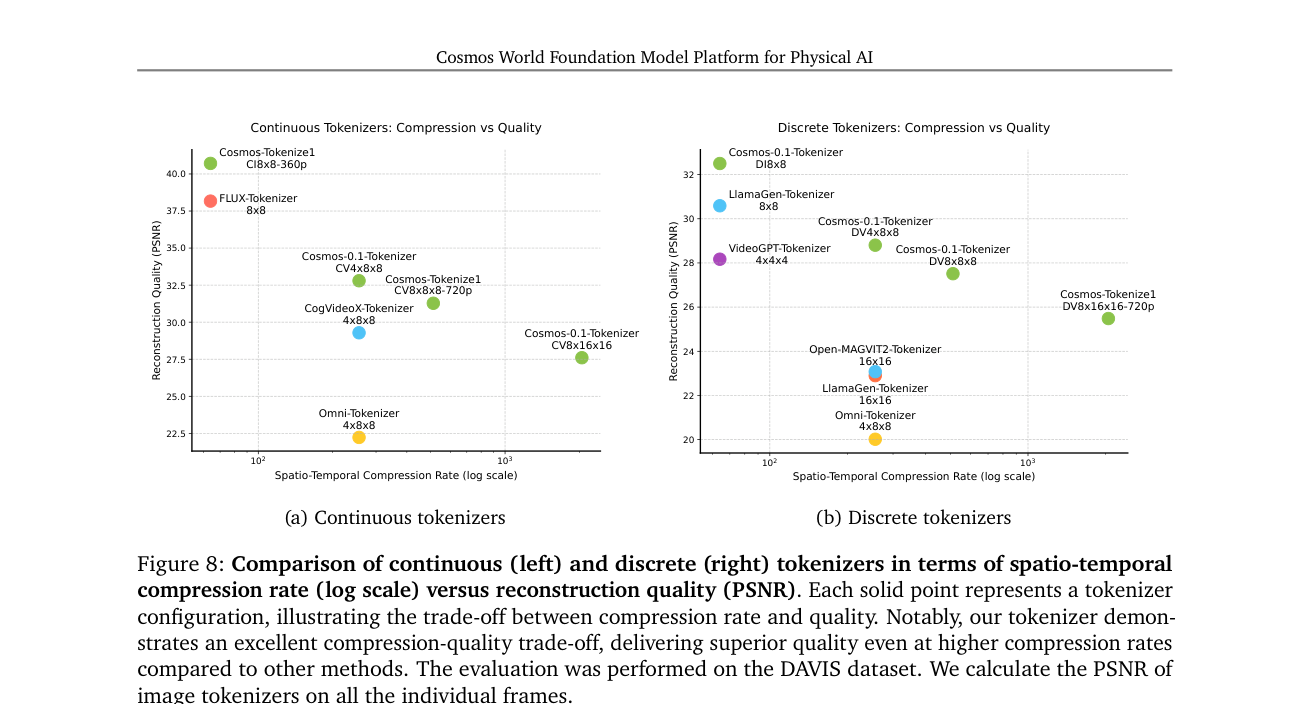
- 结果:DAVIS 上比前作 +4 dB PSNR;速度 2×–12×,且模型最小;单张 A100 80GB 一次可编码 8s@1080p 或 10s@720p。
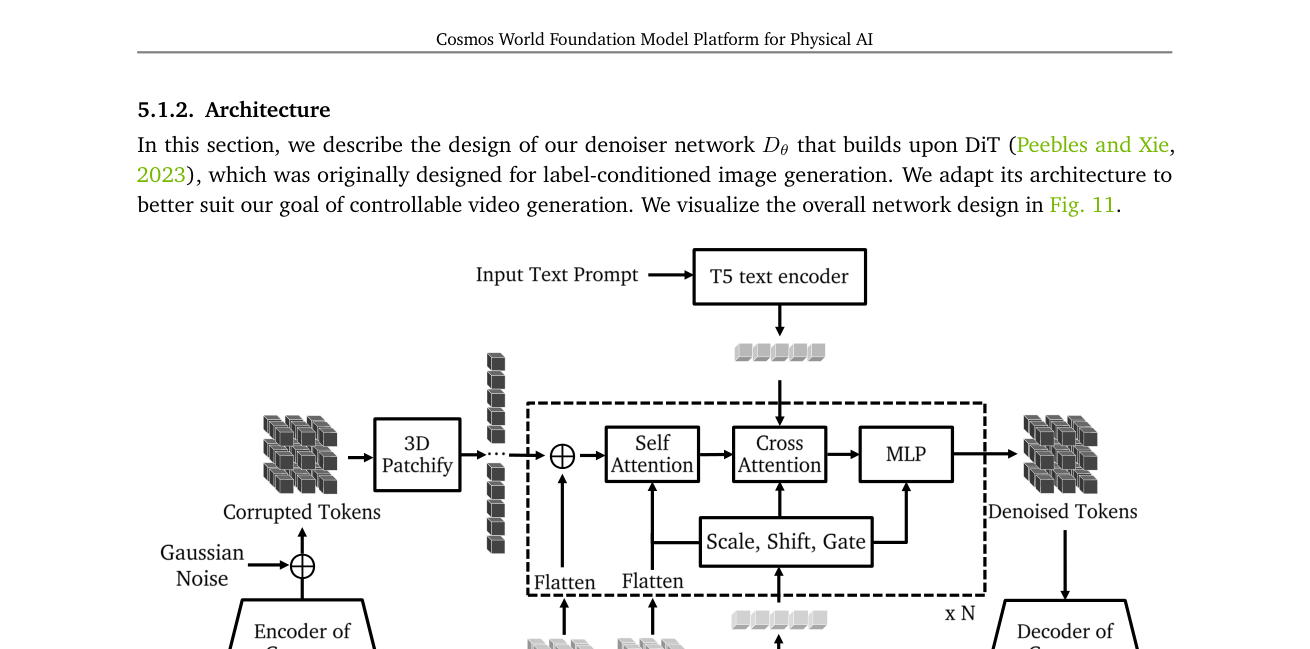
4. 扩散式 WFM(Sec.5.1)¶
潜空间扩散模型,在 tokenizer(Cosmos-Tokenize1-CV8×8×8-720p,连续 token)的潜空间里去噪生成。
- 公式:采 EDM 去噪分数匹配;用不确定性加权把各噪声级当多任务学。
- 架构:基于 DiT。3D patchify(p_t=1, p_h=p_w=2)→ token 序列;3D 分解 RoPE(FPS-aware)+ 可学习绝对位置嵌入(减少 morphing 伪影);T5-XXL cross-attention 注入文本;QK-Norm(RMSNorm) 稳训练;AdaLN-LoRA 把 AdaLN 低秩化,参数从 11B→7B(减 36%)不掉点。
- 两步预训练:① Text2World(文本→视频)② Video2World(过去视频+文本→未来视频,条件帧沿时间维拼接 + 加噪增强 + 二值掩码)。
- 配套:提示升采样器(Cosmos-UpsamplePrompt1-12B,基于 Mistral-NeMo-12B-Instruct,把用户短提示扩成训练分布的长描述);Video2World 提示用 Pixtral-12B 零样本。
- 训练工程:混合精度(BF16+FP32),渐进训练 512p→720p、57→121 帧,多宽高比分桶(1:1/3:4/4:3/9:16/16:9);14B 模型参数+梯度+优化器约 280GB + 激活 310GB,用 FSDP(分片 64)+ Context Parallelism(CP=8) 摊到多卡(参数降到 ~4GB/卡,激活 ~40GB/卡)。刻意不用 TP/SP 也达到可比 MFU。
5. 自回归式 WFM(Sec.5.2)¶
把世界生成当下一个 token 预测(像语言模型),用离散 tokenizer(Cosmos-Tokenize1-DV8×16×16-720p)。
- 架构:Llama3 风格 GPT,从零训(无语言理解能力)。3D RoPE(时间维用 YaRN 外推上下文)+ 3D 正弦绝对位置嵌入;T5-XXL cross-attention(每个自注意力后加)注入文本;QK-Norm + z-loss(λ=3e-4) 稳定大规模训练。词表 64,000。
- 两步预训练:① 纯下一 token(仅凭过去视频做"前瞻生成")② 文本条件 Video2World。多阶段加长上下文(17→34 帧),固定 640×1024,最后 30,000 步 cooling-down(高质量数据,学习率线性降到 0)。
- 重压缩补救:DV8×16×16 压得狠会失真 → 额外训一个扩散解码器(Cosmos-Predict1-7B-Decoder,把离散 DV token 映回连续 CV token 提质)。
- 工程:12B 模型约 192GB,用 TP + SP;不用 MQA/GQA,尽量对齐 LLM 架构以便复用。
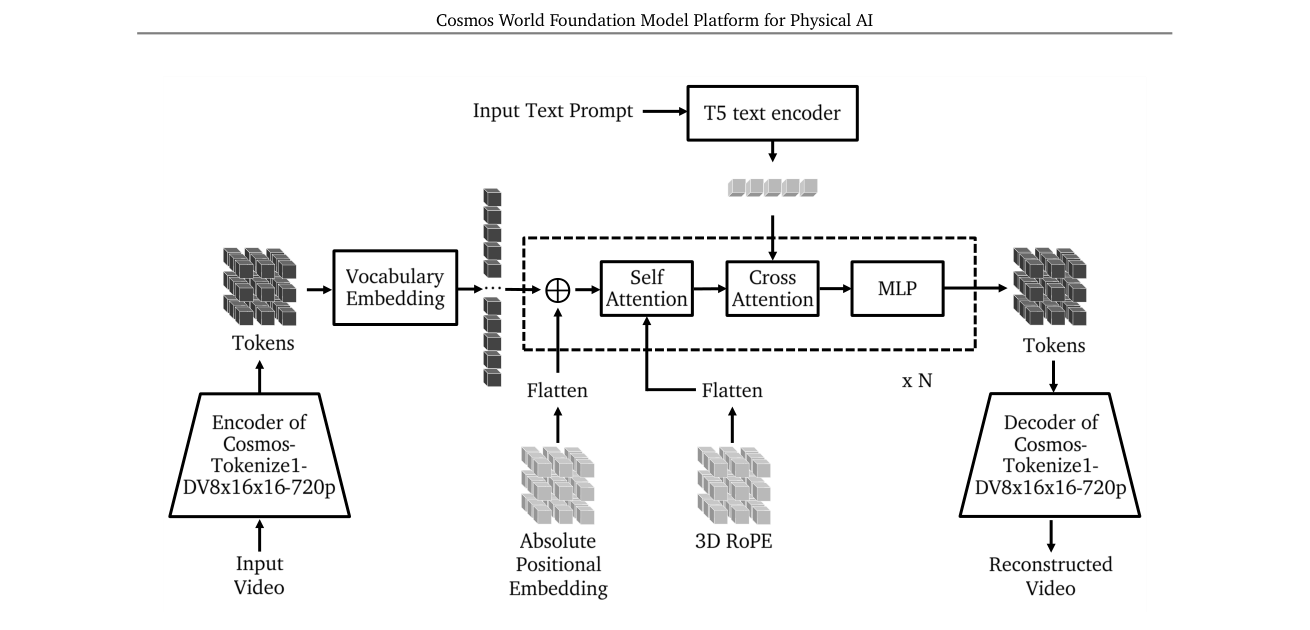
模型家族(Tab.10):
| 族 | 基座 | → 衍生(Video2World) | tokenizer | 增强件 |
|---|---|---|---|---|
| 扩散 | 7B / 14B-Text2World | 7B / 14B-Video2World | CV8×8×8-720p(连续) | 提示升采样器 12B |
| 自回归 | 4B / 12B | 5B / 13B-Video2World | DV8×16×16-720p(离散) | 扩散解码器 7B |
总算力:所有 WFM 在 10,000 张 H100 上训了 3 个月。
6. 预训练 WFM 评测(Sec.5.3)¶
只评了两个面:3D 一致性与物理对齐(作者承认这远不够全面,留待 future work)。
- 3D 一致性(500 段 RealEstate10K 静态场景):极线几何 Sampson 误差 + 相机位姿估计成功率 + 新视角合成。Cosmos 显著优于 VideoLDM 基线,接近真实视频水平——是其"能当世界模拟器"的主证据。
- 物理对齐(自建 PhysX/IsaacSim 8 类场景:自由落体、斜坡滚动、U 形坡、稳定/不稳定堆叠、多米诺、跷跷板、陀螺;共 800 段 1080p):把 WFM rollout 和仿真 GT 比 PSNR/SSIM/DreamSim/物体 IoU。结论很诚实——所有 WFM 都在物理遵守上挣扎,更大模型画质更好但物理对齐没更好;常见失败:物体凭空出现/消失(object impermanence)、形变、违反重力、不合理运动学。

7. 后训练应用(Sec.6)——机器人是重点¶
三类下游:相机控制(可导航 3D 世界)/ 机器人操作 / 自动驾驶(多视角)。机器人部分(Sec.6.2)两个任务:
- 指令式视频预测:输入当前帧 + 文本指令 → 预测机器人执行指令的视频。数据 = 内部 Cosmos-1X 数据集(1X.Tech 的 EVE 人形机器人第一视角,约 200 小时、~12,000 段 1–9s、30fps、512×512,每段一句指令)。微调出 7B/5B-Video2World-Sample-Instruction。
- 动作式下一帧生成:输入当前帧 + 动作向量 → 预测下一帧;给定动作序列可自回归出整段视频。数据 = 公开 Bridge(~20,000 段、320×256、5fps,7 维动作
(Δx,Δy,Δz,Δθr,Δθp,Δθy,ΔGripper),同 OpenVLA)。动作是新模态,加 action embedder MLP(5B 走 cross-attention,7B 加到 DiT 的时间步嵌入)。
⚠️ 关键认知:后训练评的是"生成的预测视频质量好不好/像不像/能不能让机器人据此规划",并没有训出/评测一个真正去执行任务的策略,也没有真机成功率。它产出的是"会做梦的世界模型",不是"会干活的策略"。
8. 安全护栏(Sec.7)¶
- Pre-Guard:关键词屏蔽 + Aegis 护栏(拦有害输入)。
- Post-Guard:视频内容安全过滤 + 人脸模糊(拦有害输出/隐私)。
- 配 red team。
9. 全量数字表(关键数字一处看全)¶
数据来源均为论文正文/表格;标"待核"者为文中未显式给出。
| 项目 | 数字 |
|---|---|
| 原始视频库 | ~20M 小时(720p–4k) |
| 预训练片段 / 微调片段 | ~10⁸ / ~10⁷ |
| 去重移除比例 | ~30% |
| 标注模型 | VILA-13B(FP8 TRT-LLM,10× 提速),平均 559 字符/97 词 |
| 转码提速 | 组合后 ≈6.5×;L40S 比 H100 高 ~17% |
| 离散 tokenizer 词表 | 64,000(FSQ levels 8,8,8,5,5,5;6 维) |
| 连续 tokenizer latent 维 | 16 |
| Tokenizer 质量/速度 | DAVIS +4 dB PSNR;2×–12× 提速;A100 一次编码 8s@1080p / 10s@720p |
| 扩散族 | 7B / 14B(Text2World→Video2World) |
| 自回归族 | 4B / 12B(→5B / 13B Video2World) |
| 扩散配置 | 7B: 28 层 / dim 4096 / 32 头;14B: 36 层 / dim 5120 / 40 头 |
| 自回归配置 | 4B: 16 层 / dim 4096;12B: 40 层 / dim 5120 |
| AdaLN-LoRA 省参 | 11B→7B(减 36%) |
| 训练算力 | 10,000× H100 × 3 个月 |
| 14B 显存 | ~280GB(参/梯/优化器)+ 310GB(激活);FSDP 64 + CP 8 |
| 12B(AR)显存 | ~192GB;TP+SP |
| z-loss 系数 λ | 3×10⁻⁴ |
| AR cooling-down | 30,000 步 |
| 3D 一致性(Tab.19) | Cosmos-7B-Text2World:Sampson 0.355、位姿成功率 62.6%;VideoLDM 基线 0.841 / 4.4%;真实视频 0.431 / 56.4% |
| AR 失败率(Tab.18,图条件) | 4B 15% → 12B 2%;视频条件(9帧)普遍 0–2% |
| 物理对齐(Tab.20,33 帧) | PSNR ~17–21、Avg IoU 0.33–0.60;更大模型未更好;9 帧条件下扩散像素级优于自回归 |
| 机器人指令式人评(图24) | Cosmos-7B 总体偏好 78.3% vs VideoLDM-Instruction 13.0% |
| 机器人动作式(Bridge,Tab.23) | Cosmos-7B:PSNR 21.14 / SSIM 0.82 / FVD 190;IRASim 基线 19.13 / 0.64 / 593 |
10. 局限(作者自己点的,很诚实)¶
- 当前模型(含本作)都还不是可靠的物理模拟器:缺物体永久性、接触密集动态不准、指令遵守不一致;画面真实 ≠ 遵守重力/光照/流体等物理。
- 评测难:人评物理保真度受主观偏见影响,且可能与下游 Physical AI 指标不正相关 → 方向是自动化多模态 LLM 评测器 + 物理仿真器辅助。
- 自回归 vs 扩散:当前扩散画质更好、控制信号更灵活(相机/末端位姿/车轨迹/多视角);自回归潜力在于可继承 LLM 权重 + 推理可加速(KV cache、因果注意力),更适合交互/实时规划,但目前画质落后。边界正在模糊(扩散可蒸馏成因果学生;自回归可加扩散头)。
- WFM 用途 1–5(评估/初始化/训练/规划/合成数据)论文全部只列举、零实证。
11. 核心洞见¶
- "工业化底座"打法:Cosmos 真正的贡献不是单点 SOTA,而是把数据管线 + tokenizer + 两族 WFM + 后训练 + 护栏整条链工程化、开源开放权重,降低别人造世界模型的门槛。GPU 厂商卖"铲子"的自然延伸。
- tokenizer 是真硬货:因果 + 小波 + FSQ,质量/速度/通用性都领先,且可独立复用——可能是平台里最"即插即用"的部分。
- 诚实区分了"画得像"和"算得对":用 IsaacSim 造受控物理基准来量化物理对齐,并直说"都没及格、更大也不行",这比很多 demo 式世界模型论文务实。
🗣️ 外部评价¶
检索 "NVIDIA Cosmos world foundation model review/discussion" 与 "Cosmos physical AI critique" 后,公开结果几乎全是 NVIDIA 官方口径与转述,独立第三方深度批评在检索结果中未见(如实记录)。
- 🌐 NVIDIA 官方/CEO 口径:黄仁勋称"正如大模型革新了生成式与 agentic AI,Cosmos 世界基座模型是 Physical AI 的突破";强调 9,000 万亿 token 规模训练、3D 一致性与物理对齐评测、可微调到自动驾驶/人形。NVIDIA Newsroom、NVIDIA 技术博客
- 🌐 官方亦承认局限(与论文一致):当前模型仍不足以做可靠模拟器,缺物体永久性、接触密集动态不准、指令遵守不一致;常见失败含时序不一致、相机/物体运动不稳、声画不对齐、物体形变、3D 结构不准、物理不合理。NVIDIA 技术博客
- 🌐 后续演进:NVIDIA 已推出 Cosmos 3(2026-06-22 技术报告),主张"感知与生成分离从根本上受限,必须统一成单一可扩展框架",转向 omnimodal 世界模型——侧证本文这代在统一性/物理性上仍有大缺口。Cosmos 3 技术报告
- 🧑 同行学术收录:本工作进入 ACM RichMedia/GenAI workshop 论文集(出处级,非批评)。ACM DL
🤔 我的判断(🤖,尤其:它对机器人到底有多大用、是不是噱头)¶
- 不是纯噱头,但被市场叙事放大了。硬货是确实存在的:tokenizer 领先、整条数据/训练/后训练链工程化且开源开放权重、物理评测做得诚实。这些对"想造世界模型的人"是真省力。
- 但对"机器人到底有多大用",要泼三盆冷水:
- 它给的是"会做梦的世界模型",不是"会干活的策略"。 后训练只证明了"生成的预测视频更像、人更偏好、像素/FVD 更好"(Bridge FVD 190 vs 593、指令偏好 78.3%),没有任何真机任务成功率。论文列的 5 大用途(策略评估/初始化/训练/规划/合成数据)全部零实证——这恰恰是机器人真正想要的东西,却整篇没兑现。
- 物理对齐自己都承认没及格(Avg IoU 0.33–0.60、更大模型不更好、违反重力/物体闪现)。机器人最吃的就是接触密集动力学,而这正是它最弱的一环(作者明说"contact-rich dynamics 不准")。拿它当 MPC/RL 的环境,模型误差会直接成为决策上界的天花板。
- 数据分布偏科:手/物操作 16% + 第一视角 8%,机器人相关不到 1/4,大头是自然/驾驶/风光。通用 WFM 不等于机器人 WFM,垂直适配仍要大量自采数据后训练。
- 它真正能用的地方(现在就能用):① Cosmos Tokenizer 当通用视频压缩件复用;② Video2World 当合成数据/数据增强引擎(生成多样未来、相机控制视角)喂模仿学习——这与我们 概念-机器人数据与标注 的"数据护城河"主线直接咬合;③ 当定性的可视化/直觉验证工具,而非定量可信的物理模拟器。
- 一句话:Cosmos 是"世界模型的安卓底座",工程价值高、机器人即战力有限;把它当数据/可视化基础设施用是稳的,把它当可信物理模拟器或策略训练环境用,目前是过度承诺。后续看 Cosmos 3 是否补上"统一性 + 物理性"这两课。
12. 对我们¶
- 与 卡片-UniSim 互为对照:UniSim 是"统一动作-视频交互模拟器"的学术原型,Cosmos 是同一思路的工业化、开源、可微调放大版(数据/tokenizer/两族模型/护栏全配齐)。两者都押注"视频世界模型当机器人模拟器",但都还卡在物理保真这一关——可长期对照演进。详读可对照 详读-UniSim。
- 与 概念-机器人数据与标注 直接相关:Cosmos 的最现实落点不是"模拟器"而是"合成数据生成 + tokenizer"。Video2World/动作条件生成可作为数据增强手段,和我们关注的"采数效率 / 数据护城河"战场(遥操作、手套、UMI、详读-DexTeleop-0)形成"造数据"的另一条供给线。
- 机制可借:因果小波 tokenizer、FSQ 离散化、AdaLN-LoRA 省参、扩散↔自回归的取舍框架,都是可单独借用的工程点。
- 采购视角(给老板的话):要它当"省采数的合成数据/可视化工具"——值;要它当"机器人脑子里可信的物理沙盘"——还早,论文自己都没敢声称。