详读 · Diffusion Policy(用动作扩散做视觉运动策略学习)¶
卡片版见 卡片-DiffusionPolicy。本页是全文精读:动机 → 方法(逐模块公式直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2303.04137(v5, 2024-03-14,是 RSS 2023 会议版的期刊扩展版)· 项目页 · 代码 作者:Cheng Chi、Zhenjia Xu(哥伦比亚大学)+ Siyuan Feng、Eric Cousineau、Benjamin Burchfiel、Russ Tedrake(TRI / MIT)+ Yilun Du(MIT)+ Shuran Song(哥大 / 斯坦福)。*为共同一作。
0. 一句话定位¶
把机器人的视觉运动策略(observation → action)重写成一个条件去噪扩散过程:不直接回归一个动作,而是从高斯噪声出发、迭代 K 步去噪,生成一段未来动作序列。这一改造天然吃下多模态动作分布、扩到高维动作空间、且训练稳定——在 15 个任务 / 4 个基准上平均比此前 SOTA 高 46.9%。它是后续几乎所有扩散策略(卡片-3D-DiffusionPolicy、卡片-ConsistencyPolicy、卡片-EquivariantDiffusionPolicy、卡片-ReactiveDiffusionPolicy)的母本。
1. 问题与动机¶
- 从演示学策略,最朴素就是"观测→动作"的监督回归。但机器人动作有三个特殊难点:① 多模态(同一状态有多种合理走法);② 时序相关(动作要连贯);③ 高精度要求。
- 前人两条路都不够:
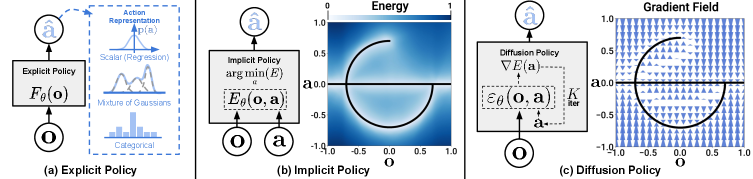
- 显式策略(图1a):直接回归动作。多模态处理弱——用混合高斯(MDN,如 BC-RNN/LSTM-GMM)易模式坍塌、对超参敏感;用离散化分类(如 BET)则 bin 数随动作维度指数增长。
- 隐式策略(图1b):用能量模型 EBM 表示动作分布(IBC),天然多模态,但训练要做负采样估计不可解的归一化常数
Z,训练不稳定。 - 本文切入:用扩散模型(图1c)——学习动作分布的score(梯度场),推理时沿梯度场做随机 Langevin 迭代。它同时拿到 EBM 的多模态表达力,又绕开了
Z的估计,因此既稳又强。
2. 核心公式(直觉版)¶
2.1 去噪扩散概率模型 DDPM¶
从高斯噪声 x_K 出发,做 K 次去噪得到 x_{K-1}…x_0,每步:
x_{k-1} = α( x_k − γ·ε_θ(x_k, k) + N(0, σ²I) ) …(1)
ε_θ是噪声预测网络(要学的参数 θ);α, γ, σ是随步数 k 变的噪声调度。- 关键直觉(式2):上式等价于一步带噪的梯度下降
x' = x − γ·∇E(x)——即ε_θ在预测能量函数的梯度场 ∇E(x),γ是学习率,噪声调度 = 学习率调度。α略小于 1 能提稳定性。
2.2 训练(出奇简单)¶
随机抽真实样本 x_0、随机选去噪步 k、加对应方差的噪声 ε_k,让网络把这个噪声预测出来:
L = MSE( ε_k, ε_θ(x_0 + ε_k, k) ) …(3)
最小化此 MSE 等价于最小化数据分布与生成分布 KL 散度的变分下界(Ho 2020)。没有负采样、没有 Z——这就是它比 IBC 稳的根本原因。
2.3 改造成视觉运动策略¶
两处改动:① 把输出 x 换成机器人动作;② 让去噪以观测 O_t 为条件。条件式推理与训练:
A_t^{k-1} = α( A_t^k − γ·ε_θ(O_t, A_t^k, k) + N(0, σ²I) ) …(4)
L = MSE( ε_k, ε_θ(O_t, A_t^0 + ε_k, k) ) …(5)
- 关键设计:把观测
O_t当条件(建模p(A_t|O_t))而非联合分布p(A_t, O_t)。视觉特征每帧只提一次、不参与 K 次去噪循环 → 大幅省算力、能实时,还让视觉编码器可端到端训练。
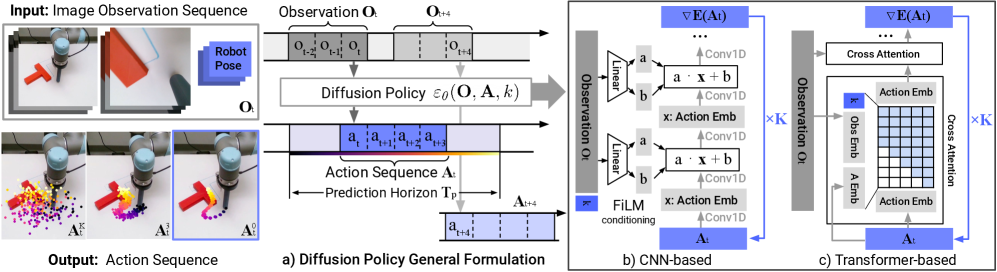
2.4 闭环动作序列 + receding horizon(图2a)¶
时刻 t:吃进最近 T_o 步观测 O_t,一次预测 T_p 步未来动作,但只执行前 T_a 步就重规划。
- T_o=观测时域,T_p=预测时域,T_a=执行时域。
- 这样既保时序一致/平滑(长时域规划),又保响应性(短时执行后即重规划);下次推理还能用上次预测热启动。
3. 关键设计决策¶
3.1 两种噪声预测网络 ε_θ¶
- CNN 版:借自 Janner 的 1D 时域卷积,用 FiLM(特征级线性调制)把观测特征
O_t和去噪步 k 逐通道注入每个卷积层。优点:开箱即用、几乎不用调超参。缺点:动作快速剧烈变化时表现差(如速度控制空间)——因时域卷积天生偏好低频信号、会过度平滑。 - Transformer 版(时序扩散 Transformer):用 minGPT 解码器,动作 token + 正弦编码的 k token 作输入,观测经共享 MLP 当交叉注意力的条件,因果注意力掩码。优点:减轻过平滑,状态任务下多数最优、尤其任务复杂/动作变化快时。缺点:对超参更敏感、更难训。
- 作者建议:新任务先上 CNN 版;若因复杂/高频动作表现差,再换 Transformer 版(代价是多调超参)。
3.2 视觉编码器¶
标准 ResNet-18(不预训练),两处改:① 全局平均池化 → 空间 softmax 池化(保空间信息);② BatchNorm → GroupNorm(与 DDPM 常用的 EMA 配合时才稳)。不同相机各用独立编码器。
3.3 噪声调度 & 加速推理¶
- 噪声调度:实测 iDDPM 的 Square Cosine Schedule 在控制任务上最好。
- 加速:用 DDIM 解耦训练/推理步数——训练 100 步、推理只 10 步,在 Nvidia 3080 上实现 0.1s 推理延迟,满足闭环实时。
4. 有意思的性质(机理)¶
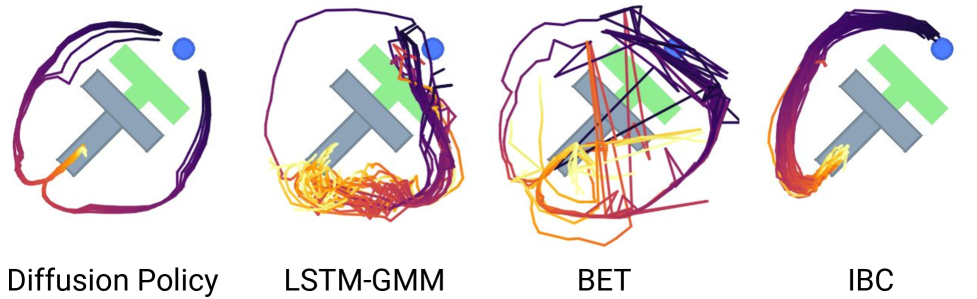
- 多模态从哪来:① 每次采样从标准高斯抽不同初值
A_t^K(落入不同收敛盆地);② 迭代中持续加高斯扰动。图3 Push-T 中,DP 学到"从左/右两种推法"且每次 rollout 只承诺一种;LSTM-GMM/IBC 偏向一边,BET 因缺时序一致而在两模式间抖动。
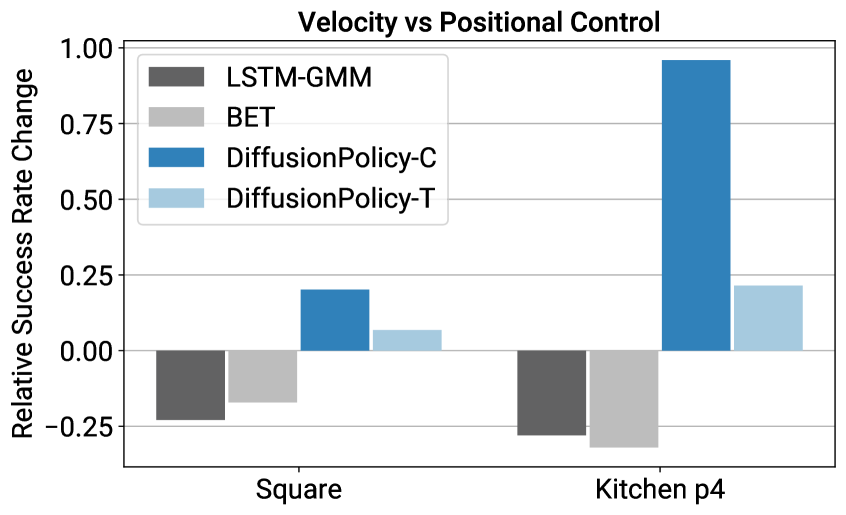
- 与位置控制的协同(反直觉):DP 用位置控制一致优于速度控制,而基线(BC-RNN/BET)反而靠速度控制更好。原因:位置控制下多模态更突出(DP 正好擅长),且位置控制受累积误差影响小、更适合序列预测。
- 动作序列预测的好处:① 时序一致——避免逐步独立采样导致的左右模式跳变抖动;② 抗 idle 动作——演示中的停顿(倒液体等)会让单步策略过拟合卡住,序列预测更鲁棒。
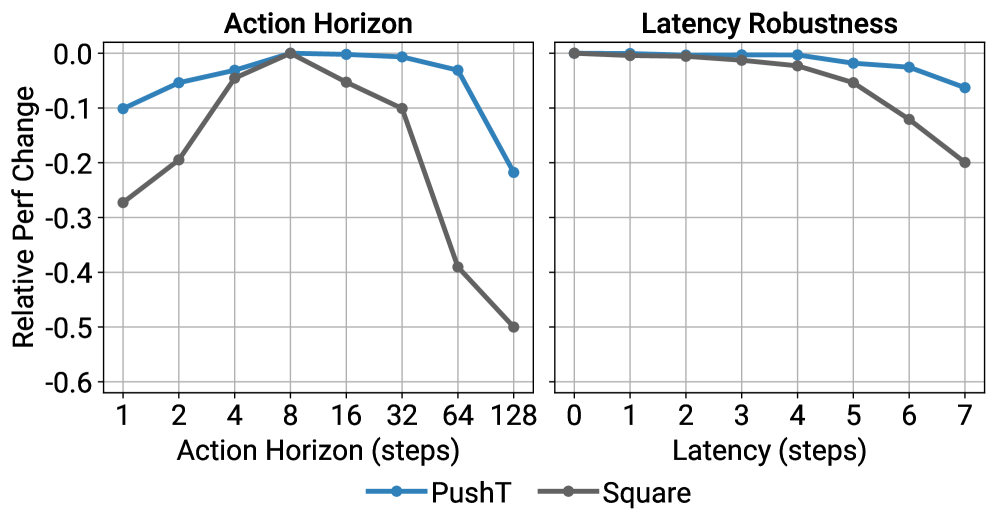
- 动作时域权衡 + 抗延迟(图5):
T_a太短响应快但不一致,太长则反应慢;实测 8 步最优。位置控制 + receding horizon 让它抗延迟到 4 步仍保持峰值性能。
- 训练稳定性:IBC 训练 loss 平滑下降,但动作推断精度不升、评测成功率剧烈振荡,难选 checkpoint。DP 通过学 score function 绕开
Z(式8:ε_θ ≈ −∇_a log p(a|o),∇_a log Z = 0),训练稳、最优超参跨任务基本一致。 - 与控制论的联系(扩展版新增):在线性系统 + 线性反馈
a=−Ks的简单情形,T_p=1时最优去噪器恰好收敛到a=−Ks;T_p>1时为完美克隆依赖状态的行为,学习器必须隐式学到任务相关的动力学模型。
5. 实验¶
5.1 设置¶
- 15 个任务 / 4 个基准:Robomimic(Lift/Can/Square/Transport/ToolHang,含 PH 熟练人 + MH 混合人演示,共 9 个变体)、Push-T、Block Push(来自 BET)、Franka Kitchen。覆盖仿真+实机、2~6 DoF、单/多任务、刚体/流体。
- 基线:LSTM-GMM(即 RoboMimic 的 BC-RNN,作者复现得分略高于原文)、IBC、BET。
- 两版:DiffusionPolicy-C(CNN)、DiffusionPolicy-T(Transformer)。
- 报告口径:(最大性能) / (最后 10 个 checkpoint 平均),每个 3 个训练种子 × 50 个环境初值。Push-T 用目标覆盖率(IoU)而非成功率。
5.2 仿真 · 状态观测(表1)¶
| 任务·变体 | LSTM-GMM | IBC | BET | DP-C | DP-T |
|---|---|---|---|---|---|
| Lift ph/mh | 1.00/1.00 | 0.79/0.15 | 1.00/1.00 | 1.00/1.00 | 1.00/1.00 |
| Can ph/mh | 1.00/1.00 | 0.00/0.01 | 1.00/1.00 | 1.00/1.00 | 1.00/1.00 |
| Square ph/mh | 0.95/0.86 | 0.00/0.00 | 0.76/0.68 | 1.00/0.97 | 1.00/0.95 |
| Transport ph/mh | 0.76/0.62 | 0.00/0.00 | 0.38/0.21 | 0.94/0.68 | 1.00/0.62 |
| ToolHang ph | 0.67 | 0.00 | 0.58 | 0.50 | 1.00 |
| Push-T ph | 0.67 | 0.90 | 0.79 | 0.95 | 0.95 |
(数值为 max 性能;ph=熟练人演示, mh=混合人演示。)
5.3 仿真 · 视觉观测(表2)¶
| 任务·变体 | LSTM-GMM | IBC | DP-C | DP-T |
|---|---|---|---|---|
| Lift ph/mh | 1.00/1.00 | 0.94/0.39 | 1.00/1.00 | 1.00/1.00 |
| Can ph/mh | 1.00/0.98 | 0.08/0.00 | 1.00/1.00 | 1.00/1.00 |
| Square ph/mh | 0.82/0.64 | 0.03/0.00 | 0.98/0.98 | 1.00/0.94 |
| Transport ph/mh | 0.88/0.44 | 0.00/0.00 | 1.00/0.89 | 0.98/0.73 |
| ToolHang ph | 0.68 | 0.00 | 0.95 | 0.76 |
| Push-T ph | 0.69 | 0.75 | 0.91 | 0.78 |
复杂任务(Transport、ToolHang)提升最明显;IBC 在视觉高维任务几乎全军覆没。
5.4 多阶段任务(表4 · 状态观测)¶
| 指标 | LSTM-GMM | IBC | BET | DP-C | DP-T |
|---|---|---|---|---|---|
| BlockPush p1 | 0.03 | 0.01 | 0.96 | 0.36 | 0.99 |
| BlockPush p2 | 0.01 | 0.00 | 0.71 | 0.11 | 0.94 |
| Kitchen p1 | 1.00 | 0.99 | 0.99 | 1.00 | 1.00 |
| Kitchen p2 | 0.90 | 0.87 | 0.93 | 1.00 | 0.99 |
| Kitchen p3 | 0.74 | 0.61 | 0.71 | 1.00 | 0.99 |
| Kitchen p4 | 0.34 | 0.24 | 0.44 | 0.99 | 0.96 |
长时多模态上优势巨大:BlockPush p2 比次优 +32%;Kitchen p4 比次优 +213%。注意 BlockPush 上 DP-T(0.94) 远好于 DP-C(0.11)——这是 Transformer 版价值最突出的反例任务。
5.5 视觉编码器消融(表5 · robomimic Square ph)¶
| 架构(预训练集) | 从头训 | 冻结预训练 | 微调预训练 |
|---|---|---|---|
| ResNet-18 (in21k) | 0.94 | 0.58 | 0.92 |
| ResNet-34 (in21k) | 0.92 | 0.40 | 0.94 |
| ViT-B/16 (CLIP) | 0.22 | 0.70 | 0.98 |
结论:冻结预训练编码器最差(DP 偏好与主流预训练不同的视觉表征);小学习率微调最好,CLIP-ViT-B/16 仅 50 epoch 就到 0.98;从头训 ViT 因数据少很难(0.22)。各架构差距其实不大。
5.6 实机 · Push-T(表6)¶
真实 Push-T 比仿真难:多阶段(推 T 块→末端撤到 end-zone)、末步才测 IoU。DP 以 10Hz 出指令、线性插值到 125Hz 执行。
| 方法 | IoU | 成功率 | 时长(s) |
|---|---|---|---|
| 人类演示 | 0.84 | 1.00 | 20.3 |
| IBC(最优变体) | ≤0.25 | 0.00 | — |
| LSTM-GMM(最优变体) | ≤0.24 | 0.20 | — |
| DP (R3M 预训练) | 0.66 | 0.80 | 31.7 |
| DP (端到端) | 0.80 | 0.95 | 22.9 |
DP 端到端接近人类水平(0.95 succ);R3M 版会抖动、易卡。基线最常见失败在阶段切换处(LSTM 20 次有 8 次卡 T 块旁,IBC 6 次过早离开)。端到端训练视觉编码器是最有效方案。 抗扰动(图8,文中):遮挡前置相机 3 秒仍在轨;推动阶段移动 T 块会立即从反方向重新推;去 end-zone 途中移动 T 块会立即折返纠正——出现了演示中从未有过的新行为。
5.7 实机 · 其他单臂¶
- 6DoF 翻杯:DP 90%(20 次),LSTM-GMM 0%(全部抓取失败)。演示高度多模态(抓 vs 推、正手/反手),DP 还能自发多次推/掉落后重抓(未演示过)。
- 倒酱:DP IoU 0.74 / 成功率 0.79(人类 0.79/1.00);LSTM-GMM 0(20 次有 15 次舀到酱后抬不起勺)。
- 铺酱(周期动作):DP 覆盖率 0.77 / 成功率 1.00(人类 0.79/1.00);LSTM-GMM 覆盖 0.27 / 成功率 0。两个酱任务都用 Push-T 同一套超参、第一次尝试就成功。
5.8 实机 · 双臂(扩展版新增)¶
扩展观测/动作到双末端位姿 + 双夹爪宽度,双场景相机 + 双腕相机。DP 无需调超参开箱可用。
| 双臂任务 | 演示数 | 成功率(20 次) |
|---|---|---|
| 打蛋器 Egg Beater | 210 | 55% |
| 铺垫子 Mat Unrolling | 162 | 75% |
| 叠衬衫 Shirt Folding | 284 | 75% |
打蛋器特别说明力觉反馈对采数的重要性:无力反馈时专家 10 次演示 0 次成功(5 次把曲柄拉脱、3 次脱手、2 次触发力矩限);有力反馈则 10/10。叠衬衫长达 9 个离散步,靠中层控制器显式避碰才行。
6. 核心洞见¶
- 策略结构本身是瓶颈:作者强调,除了数据质量/数量、机器人能力、预训练,策略表示对模仿学习性能影响极大——把回归/分类/EBM 换成扩散,就在同样数据上大幅涨点。
- 三大优势同时拿到:多模态表达(来自 score + Langevin 采样)、高维输出(来自扩散的可扩展性 → 做动作序列)、训练稳定(来自绕开
Z)。 - 系统设计同样关键:receding-horizon 闭环、末端位置控制、视觉只作条件+端到端、DDIM 加速——缺一不可才能上真机实时。
7. 局限 / 存疑(作者诚实点的 + 精读补充)¶
- 继承模仿学习的根本缺陷:演示不充分/次优时性能差;本身不利用负样本(未来可接 RL)。
- 算力/延迟高:比 LSTM-GMM 等慢,序列预测只部分缓解,高频控制任务可能不够快——指向后续 Consistency/一步扩散的方向。
- 基准评测有 bug:robomimic 任务实际只用了 22 个环境初值(非 50),作者已注明、因所有方法同条件故不改变结论。
- CNN 版高频动作弱:velocity-control / 周期高频任务要换 Transformer 版且更难调。
- 双臂任务成功率仅 55~75%:长时操作、布料/工具等仍有明显失败(初始抓取、出域初值、末端停不下来)。
8. 对我们¶
- 整条扩散策略线的源头:本库已有的 卡片-3D-DiffusionPolicy、卡片-ConsistencyPolicy、卡片-EquivariantDiffusionPolicy、卡片-ReactiveDiffusionPolicy 都从它派生——读懂这张是读懂后续派生工作的前提。
- 力觉/触觉的接口:本文双臂打蛋器的"无力反馈 0/10、有力反馈 10/10"直接说明接触密集任务对力反馈的依赖,与 卡片-ReactiveDiffusionPolicy(把触觉接进扩散策略)、卡片-NeuralFeels 同一条问题线;也呼应遥操作采数效率(见 详读-DexTeleop-0、概念-机器人数据与标注)。
- 可复用范式:动作序列 + 去噪扩散 + receding horizon + 位置控制 + DDIM 实时,是策略层成熟基线;代码开源、被广泛复现,证据等级 A。