详读 · RDT-1B(双臂操作的扩散基础模型,1.2B)¶
卡片版见 卡片-RDT-1B。本页是全文精读:动机 → 方法(逐模块) → 数据 → 实验(全表数字) → 诚实局限 → 洞见 → 对我们。 来源:arXiv 2410.07864v2(ICLR 2025,2025-03-01 修订)· 项目页 · 代码 作者:Songming Liu、Lingxuan Wu(共一)等,Hang Su、Jun Zhu(通讯)—— 清华大学 TSAIL / 计算机系。
0. 一句话定位¶
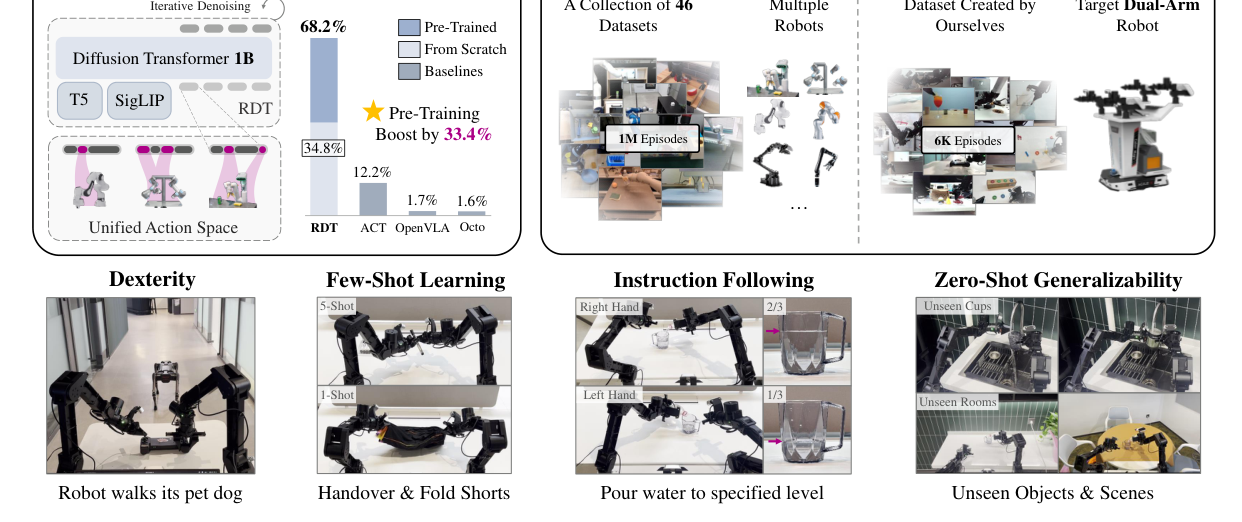
把 Diffusion Transformer(DiT) 当骨干、扩到 1.2B 参数,做一个语言条件的双臂视觉运动策略基础模型:先在 46 个机器人数据集(1M+ 轨迹、21TB)上预训练,再在自采 6K+ 条双臂数据上微调。核心两招——① 用扩散建模双臂动作的强多模态分布;② 用物理可解释统一动作空间把异构机器人塞进同一格式做跨本体预训练。当时是最大的扩散类机器人操作基础模型。
1. 问题与动机¶
- 双臂操作两难:① 双臂协同 → 动作分布强多模态(图2b:抓方块就有多种合法模式,演示者随机选一种 → 数据里多模态);② 双臂硬件贵 → 单本体数据极稀缺(
< 10K轨迹),与基础模型"吃数据"天然冲突。 - 现有路线都不够:要么靠任务专用基元/强归纳偏置(运动基元、体素、区分"稳定臂/功能臂")→ 缩小了动作空间但牺牲适用范围与多模态表达;要么是小模型小数据简单任务 → 泛化窄。
- VLA 离散化的毛病:RT-2 / OpenVLA 把动作离散化预测 → 量化误差、双臂时动作不协调。
- RDT 的切入:沿用单臂的"跨本体预训练→目标本体微调"思路,把数据量放大三个数量级抽取可迁移物理先验;但要解决两个 Challenge——Challenge 1 强架构(表达多模态 + 可扩展处理多模态输入)、Challenge 2 异构数据训练(不同机器人物理结构/动作空间差异大,硬训会负迁移)。
- 目标澄清(重要):作者明说目标是"用多机器人数据增强双臂泛化能力",不是做一个能控各种机器人的跨本体通用模型。
2. 方法:架构(对应 Challenge 1)¶
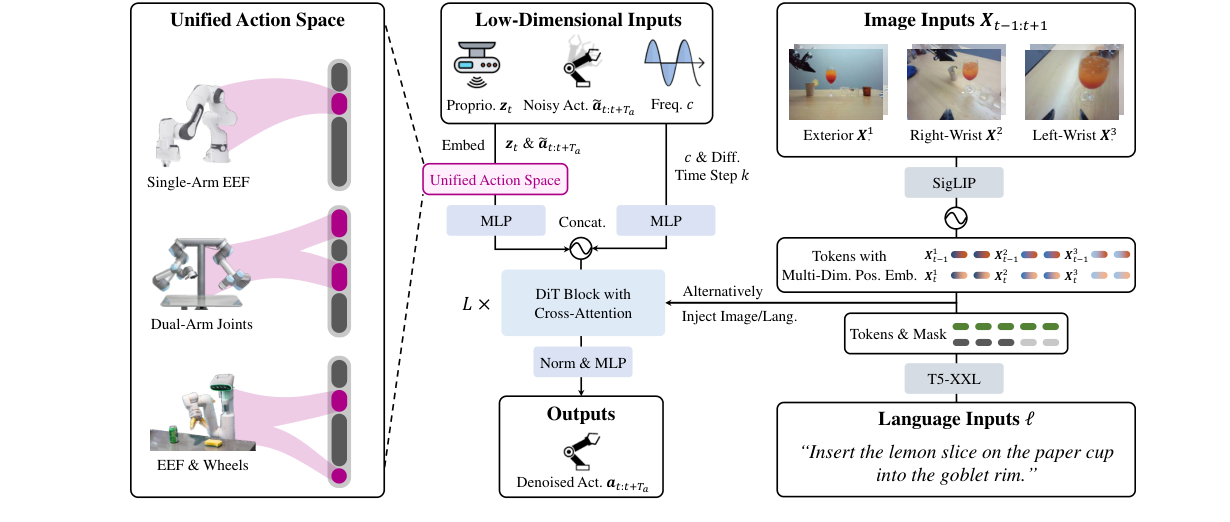
2.1 扩散建模(为什么不是回归)¶
- 给定
(ℓ, oₜ)有许多合法动作aₜ。若当成确定映射回归(ℓ,oₜ)↦aₜ,模型学到的是多个模式的"平均",可能落到完全不可行的均值动作上。故改为建模连续条件分布p(aₜ|ℓ,oₜ)。 - 动作维度远低于图像 → 扩散采样开销小,很适合做策略。预测动作块
a_{t:t+Ta}(chunk)以增强时间一致性、减少决策次数、抑制误差累积。 - 训练:网络
f_θ直接预测干净动作 a⁰(非预测噪声),MSE 去噪损失(式2)。
2.2 异构多模态输入编码¶
- 低维输入(本体感受 zₜ、噪声动作块、控制频率 c、扩散步 k):用带 Fourier 特征的 MLP编码,捕捉低维空间里的高频变化。
- 图像:冻结 SigLIP(图文对齐视觉编码器),加 MLP 投影;冻权省显存。
- 语言:冻结 T5-XXL,加 MLP 投影;冻权省显存。
- 抗"走捷径":训练时各模态以 10% 概率独立随机 mask,防止只盯外部相机而忽视腕部相机等细节。
2.3 对原版 DiT 的三处关键改造(图4 证明都重要)¶
| 改造 | 解决的问题 | 机制 |
|---|---|---|
| QKNorm + RMSNorm | 机器人物理量数值范围不稳 → 梯度不稳/溢出;LayerNorm 的中心化会破坏时间序列对称性 | 注意力里加 QKNorm 防数值不稳;用无中心化的 RMSNorm 替 LayerNorm。图4a:不改大规模预训练 loss 会震荡甚至爆炸。 |
| MLP 解码器 | 末端线性解码无法逼近非线性机器人动作 | 把最后的线性解码换成非线性 MLP,从隐空间投回物理空间。图4b:去掉则做不了精细灵巧任务。 |
| 交替条件注入 ACI | 图像 token 远多于文本 token,同层同时注入会淹没文本 → 指令跟随变差 | 用交叉注意力容纳变长条件;逐层交替注入图像/语言,而非每层都注两者。 |
- 图像位置嵌入扩展成多维网格
(Timg, Ncam, Npatch, D),编码视角+时序关系。

3. 方法:物理可解释统一动作空间(对应 Challenge 2)¶
- 动机:要在多机器人数据上训,需要一个共享的统一动作格式;映射须物理可解释,每一维有明确物理含义 → 鼓励模型跨机器人学共享物理规律。
- 两步设计:① 因
aₜ通常是期望z_{t+1}的子集,故用同一空间装本体感受 zₜ 与动作 aₜ;② 设计一个涵盖"带夹爪机械臂"绝大多数物理量的统一向量,按物理含义填入对应位、其余补padding。 - 维度 = 128(表4):右臂关节位[0,10)、右夹爪[10,15)、右臂关节速[15,25)…右末端位姿/6D旋转/速度/角速度…左臂对称[50,100)…底盘线速[100,102)/角速102,其余保留。单臂机器人映到"右臂";6-DoF 臂填前 6 位。
- padding 不用裸 0:因为"0"本身有物理含义(如速度0=静止)会让模型混淆"静止 vs 填充"。故拼一个 0-1 可用性掩码,动作/本体感受 → 256 维再编码。
- 不归一化到 [-1,1]/N(0,1):只统一物理单位(m, rad, m/s…),保留"1m 在各数据集是同一真实长度"这一可迁移属性;EEF 旋转用 6D 表示避免万向锁。
4. 数据¶
4.1 预训练(46 数据集 / 1M+ 轨迹 / 21TB)¶
- 采样权重
∝ √Nⱼ(防大数据集过采、保小数据集被采到),训练中再按收敛情况调权(慢收敛的加权)。 - 权重最高的几个(表5,%):
| 数据集 | 采样占比 |
|---|---|
| RH20T | 10.99 |
| DROID | 10.06 |
| RT-1 | 9.00 |
| BridgeData V2 | 7.44 |
| BC-Z | 6.91 |
| ManiSkill | 5.78 |
| ALOHA | 4.98 |
| Mobile ALOHA | 4.98 |
| RoboSet | 4.48 |
| Language Table / Calvin | 各 3.32 |
- 预处理:固定 3 视角(外部+右腕+左腕),单臂腕相机当右腕、缺失视角用背景色补;图像 padding 成方形 resize 384×384;历史
Timg=2;剔除历史本体感受(防止只用低维输入走捷径、固化动作)。
4.2 微调(自采,Mobile ALOHA)¶
- 300+ 任务、6K+ 轨迹、3M+ 帧、100+ 物体(刚/柔)、15+ 场景(不同光照,含变色灯光);号称当时最大的开源多任务双臂数据集之一。
- 3 个 RGB 相机(前 + 左右夹爪),记录双臂 6-DoF 关节位/速 + 夹爪角;人工标注指令,再用 GPT-4-Turbo 每任务生成 100 条扩写 + 1 条简化指令增广。借了开源 Songling 数据集 3 个任务/140 条。
- 各评测任务的微调样本数:洗杯 133(未见杯 0)、倒水 350(未见房间 0)、倒水水位 18(少)/19(半)/19(满)、交接 5、叠裤 1、机器狗 68。
5. 训练 / 推理配置(硬数字)¶
- 规模:1.2B 参数;DiT 28 层、hidden 2048、32 头;RDT token 维 2048,语言 token 4096,图像 token 1152,各模态用 GeLU adaptor 对齐到 2048。
- 动作块 Ta=64,图像历史 Timg=2。
- 预训练:48× H100 80GB,约 1 个月,1M 步;微调:3 天、130K 步。批 32×48,LR 1e-4 常数,bf16,warmup 500,AdamW。
- 诚实细节:因排程原因,微调没从 1M checkpoint 起,而是用 500K 的。
- 扩散:训练 DDPM、
squaredcos_cap_v2余弦表、1000 步;采样用 DPM-Solver++,仅 5 步(从 100 步压到 5)。 - 实时推理(机上 RTX 4090 24GB):动作块 6 Hz、单步动作 381 Hz。
- 增广:色彩抖动、图像损坏、本体感受加高斯噪声(SNR 40dB)。没用 CFG(发现无提升、反而让机械臂行为不稳)。
6. 实验¶
6.1 设置¶
- 目标机器人:Cobot Mobile ALOHA(agilex.ai,Mobile ALOHA 设计),14 DoF(7×2);只做静态双臂任务("mobile"仅用于搬运转场,训练/推理不用其自主移动)。
- 7 个任务覆盖 5 个维度:洗杯(未见物体 Q1)、倒水(未见场景 Q1)、倒水-左-1/3 & 右-2/3(指令跟随 Q2)、交接(5-shot Q3)、叠裤(1-shot Q3)、机器狗(灵巧 Q4)。
- 基线:ACT(VAE 建模,双臂 SOTA)、OpenVLA(7B,离散化)、Octo(扩散,最大版仅 93M)。指标=成功率(分子任务/阶段统计)。
6.2 总览数字(图1)¶
- 整体成功率:RDT 预训练版 68.2% vs 从零训 34.8% → 预训练增益 +33.4%;三基线很低(图1柱:12.2% / 1.7% / 1.6%)。
- 论文摘要主张:跨任务相对基线成功率提升约 56%。
6.3 主结果(表3,成功率 %,节选 RDT(ours) vs 基线)¶
| 任务(维度) | ACT | OpenVLA | Octo | RDT(scratch) | RDT(ours) |
|---|---|---|---|---|---|
| 洗杯 Total(未见杯,三杯) | 0 | 0 | 0 | 0 | 50 / 75 / 50 |
| 倒水-L-1/3 · Correct Amount | — | 0 | 0 | 12.5 | 75 |
| 倒水-L-1/3 · Correct Hand | — | 50 | 0 | 100 | 100 |
| 交接 Total(5-shot) | 0 | 0 | 0 | 16 | 40 |
| 叠裤 Total(1-shot) | 0 | 0 | 4 | 40 | 68 |
| 机器狗 Walk Straight(灵巧) | 32 | 0 | 0 | 32 | 48 |
读法:在未见物体/场景、未见指令措辞("one-third / two-thirds"训练里没出现过)、少样本新技能、灵巧操作四类上,基线大多几乎为零,RDT 明显领先;且预训练版 > 从零版处处成立。
6.4 消融(表2,成功率 %;除 scratch 外均先预训练)¶
| 变体 | 未见物体 | 未见场景 | 指令跟随 |
|---|---|---|---|
| RDT(regress)(去扩散,改回归) | 12.5 | 50 | 12.5 |
| RDT(small)(166M) | 37.5 | 62.5 | 25 |
| RDT(scratch)(无预训练) | 0 | 25 | 62.5 |
| RDT(ours) | 50 | 62.5 | 100 |
结论 Q5:大模型、大数据(预训练)、扩散建模缺一不可——去掉任一都大幅掉点;scratch 在未见物体/场景上尤其差,说明预训练知识是泛化关键。

7. 诚实局限 / 存疑¶
- 没用 CFG:作者实测无益且使机械臂行为不稳——和很多扩散策略默认开 CFG 不同。
- 消融无预训练(图4,资源所限):架构改造的重要性是在"无预训练"条件下证的,与最终 1.2B+预训练设定不完全同条件。
- 微调起点是 500K 而非 1M(排程原因)→ 报告性能不是"用满预训练"的结果。
- 成功率是分阶段统计(Total + 子目标),不是端到端整任务一锤定音;少样本绝对值仍不高(交接 Total 40%、叠裤 68%)。
- "灵巧"任务偏特定:机器狗任务本质是用 ALOHA 臂去推遥控器摇杆,价值在精度演示,场景偏窄。
- 统一动作空间只覆盖"带夹爪机械臂"(128 维表里是臂+夹爪+底盘),并非面向多指灵巧手等更异构本体;且作者明确不追求跨本体通用控制。
- 仅在 ALOHA 一种目标本体上做了实机评测。
8. 核心洞见¶
- 扩散 > 离散化/VAE:要表达双臂的强多模态、非线性动作,连续扩散建模在精度与表达力上都更优(对照 OpenVLA 离散、ACT 的 VAE)。
- "物理可解释 + 不归一化"的动作空间是跨本体迁移的关键工程:保留真实物理单位、用 0-1 掩码区分"填充 vs 真值 0",让多机器人数据能正向迁移。
- ACI(交替注入) 是个小而关键的设计:防图像 token 淹没文本,直接救回指令跟随能力。
- RMSNorm 去中心化 + QKNorm 是把 DiT 用到机器人时间序列上的稳定性前提。
- 预训练是泛化的主引擎:整体 +33.4% 的提升几乎全来自大规模多机器人预训练。
9. 对我们¶
- 扩散/流匹配底座对照:与 卡片-π0 同属"连续动作生成式策略"路线,可两边对照(扩散 DiT vs 流匹配),归入 概念-模型架构基础 的架构地图。
- 数据战场:其"跨本体预训练 + 目标本体微调放大数据三个数量级"的思路,与 概念-机器人数据与标注 的采数/标注主题直接相关;微调端"高质量双臂演示"与 详读-DexTeleop-0(提升接触任务遥操作采数效率)互补——一个解"怎么采得好",一个解"怎么把海量异构数据喂进一个模型"。
- 开源可用:代码 + 权重 + 微调数据集全开源,是双臂/扩散策略方向公开可复现的底座参考(见 卡片-RDT-1B 速判)。