详读 · iVideoGPT(可交互、可扩展的自回归世界模型)¶
卡片版见 卡片-iVideoGPT。本页是全文精读:定位 → 动机 → 逐模块方法(压缩 tokenizer + 交互式预测) → 全量数字表 → 局限 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2405.15223 v3(NeurIPS 2024,2024-10-31 终版)· 项目页 · 代码 作者:Jialong Wu、Shaofeng Yin(共一)、Ningya Feng、Xu He、Dong Li、Jianye Hao、Mingsheng Long(龙明盛,通讯)——清华大学软件学院 BNRist + 华为诺亚方舟实验室 + 天津大学。
0. 一句话定位¶
把视觉观测 + 动作 + 奖励统一成一条 token 序列,用 GPT 式自回归 transformer 做下一 token 预测当世界模型。核心创新是一个压缩式 tokenizer(conditional VQGAN):把"上下文帧"和"未来帧的动态"解耦,未来帧只用极少 token 编码,使序列长度渐近降到 1/16,从而既保留逐步可交互(agent 能每步介入),又能在百万级机器人/人手操作轨迹上可扩展预训练。一个底座适配三类下游:动作条件视频预测、视觉规划(MPC)、视觉 model-based RL。
1. 问题与动机¶
世界模型要同时满足两个相互矛盾的诉求,前人各占一头:
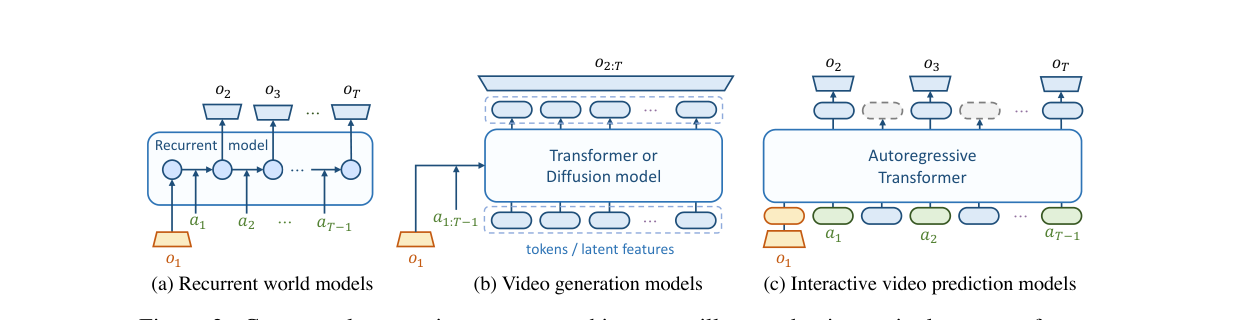
- (a) 循环世界模型(Dreamer、MuZero):每步以动作为条件做状态转移,逐步可交互,天然适合行为学习——但用 RNN,难在真实世界大规模数据上 scale,多停留在游戏/简单仿真。
- (b) 互联网级视频生成模型(VideoGPT、Stable Video Diffusion):能合成逼真长视频、可被文本/动作序列控制,可扩展——但用非因果的时序模块,只能在生成开头给条件,只有"轨迹级"交互,agent 无法在 rollout 中逐步介入学精细技能。
- 核心问题:如何把可扩展视频生成的进展,用来做逐步可交互的视觉世界模型?
- (c) 本文选择:用 GPT 式自回归 transformer——把每一步单独映射成一串 token,逐 token 因果生成,同时拿到可扩展 + 逐步可交互。相比同期的 diffusion 路线(UniSim)和 masked 路线(Genie),作者强调自回归的好处是无缝接入 LLM 生态、不需为不同条件加 adapter 等结构改动。
2. 方法¶
2.1 压缩式 tokenization(关键创新)¶
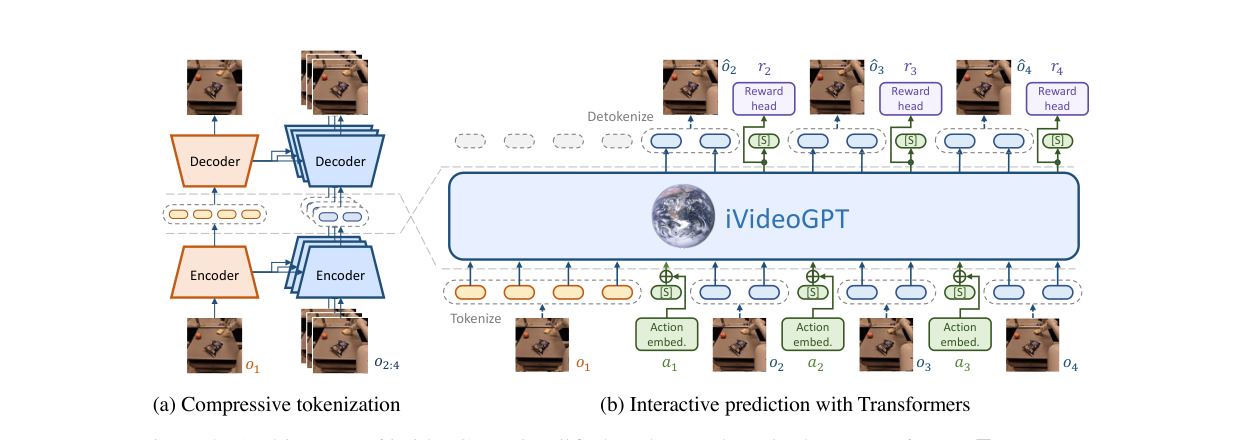
不逐帧独立 tokenize(序列爆长),也不用 3D tokenizer 时空压缩(牺牲交互性),而是用双编解码器的 conditional VQGAN {(Ec,Dc),(Ep,Dp)}:
- 上下文帧
o₁:T₀(信息丰富):独立 tokenize/重建,每帧 N 个 token:z_t = Ec(o_t),ô_t = Dc(z_t)。 - 未来帧
o_{T₀+1:T}:因为和上下文有大量时间冗余,只需编码动态信息(运动物体的位置/姿态),用条件编解码器,每帧只需 n 个 token(n≪N):z_t = Ep(o_t | o₁:T₀),ô_t = Dp(z_t | o₁:T₀)。 - 条件机制 = 多尺度特征图之间的 cross-attention(细节见原文 Appendix A.1)。
- tokenizer 损失:上下文项 + 未来项的
L_VQGAN,后者条件于o₁:T₀;L_VQGAN= L1 重建 + commitment + 感知损失 + 可选对抗损失。
两个量化好处:
- 本文取 N = 16×16 = 256,n = 4×4 = 16 → 渐近 16× 压缩序列长度,rollout/规划/RL 更快。
- 解耦上下文与动态:transformer 只管"动态",上下文一致性更易维持,预测质量更好。
2.2 交互式 transformer 预测¶
- token 拍平成序列:
x = (z₁⁽¹⁾…z₁⁽ᴺ⁾, [S], z₂…, …, [S], z_{T₀+1}⁽¹⁾…z_{T₀+1}⁽ⁿ⁾, …),总长 L = (N+1)·T₀ + (n+1)·(T−T₀) − 1。 - 插入特殊 slot token
[S]划分帧边界,并作为塞入动作等低维模态的位置。 - backbone:取 GPT-2 的体量,但用 LLaMA 架构改良——pre-norm + RMSNorm、SwiGLU 激活、旋转位置编码 RoPE。
2.3 预训练(action-free)¶
- 目标 = 纯视频预测的交叉熵:
L = −Σ log p(x_i | x_{<i}),只对要预测的未来帧 token 求和(不训练生成上下文帧,让容量集中在动态上)。 - 数据:Open X-Embodiment 里 35 个数据集 + Something-Something v2(SSv2,人手-物交互),合计 140 万条轨迹。OXE 异构机器人但能统一成 action-free 视频预测;SSv2 引人手知识迁移到机器人。
- 序列建模的灵活性:只把帧序列重排成
(o_T, o₁, …, o_{T−1}),不改架构/训练,就得到目标条件(goal-conditioned)视频预测变体。
2.4 微调(下游适配)¶
- 动作条件:线性投影后加到 slot token 的 embedding 上。
- 奖励预测:不另建预测器,而是在每个观测最后一个 token 的隐状态上加一个线性头,MSE 损失,与交叉熵多任务联合训练(让模型更关注任务相关信息)。
- tokenizer 适配:下游全量微调(含 tokenizer)优于 PEFT——因预训练数据多样性有限。关键发现:在未见的 BAIR 上,transformer 本体不微调、只微调 tokenizer,就能 zero-shot 迁移预测新机械手的运动(见图8),印证"动态知识跨场景共享、上下文/物体可换"的解耦假设。

3. 实验与全量数字¶
3.1 视频预测(BAIR / RoboNet,表1)¶
设置:BAIR 43k 训练 / 256 测试,单帧预测 15 帧;RoboNet 162k 视频/7 种机械臂,2 帧预测 10 帧(RoboNet 与 OXE 有重叠,已滤掉测试视频)。指标 FVD↓ / PSNR↑ / SSIM↑ / LPIPS↓(SSIM、LPIPS ×100 显示)。
| 数据集 / 设置 | 方法 | FVD↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|
| BAIR · action-free · 64² | VideoGPT | 103.3 | - | - | - |
| MaskViT | 93.7 | - | - | - | |
| FitVid | 93.6 | - | - | - | |
| MCVD | 89.5 | 16.9 | 78.0 | - | |
| MAGVIT | 62.0 | 19.3 | 78.7 | 12.3 | |
| iVideoGPT | 75.0 | 20.4 | 82.3 | 9.5 | |
| BAIR · action-cond · 64² | MaskViT | 70.5 | - | - | - |
| iVideoGPT | 60.8 | 24.5 | 90.2 | 5.0 | |
| RoboNet · action-cond · 64² | MaskViT | 133.5 | 23.2 | 80.5 | 4.2 |
| SVG | 123.2 | 23.9 | 87.8 | 6.0 | |
| GHVAE | 95.2 | 24.7 | 89.1 | 3.6 | |
| FitVid | 62.5 | 28.2 | 89.3 | 2.4 | |
| iVideoGPT | 63.2 | 27.8 | 90.6 | 4.9 | |
| RoboNet · action-cond · 256² | MaskViT | 211.7 | 20.4 | 67.1 | 17.0 |
| iVideoGPT | 197.9 | 23.8 | 80.8 | 14.7 |
读数:BAIR 上与 SOTA(MAGVIT)相当(FVD 略逊但 PSNR/SSIM/LPIPS 更好),且额外拥有交互+可扩展;加动作条件后 BAIR FVD 提升近 20%(75.0→60.8)。RoboNet 与最强的 FitVid 相当,并能直接扩到 256² 大幅超 MaskViT。
3.2 视觉规划(VP2 benchmark,图5)¶
VP2 = 视觉 MPC 评测,4 个 Robosuite + 7 个 RoboDesk 任务。按原协议训练:Robosuite 5k 轨迹、RoboDesk 35k 轨迹。
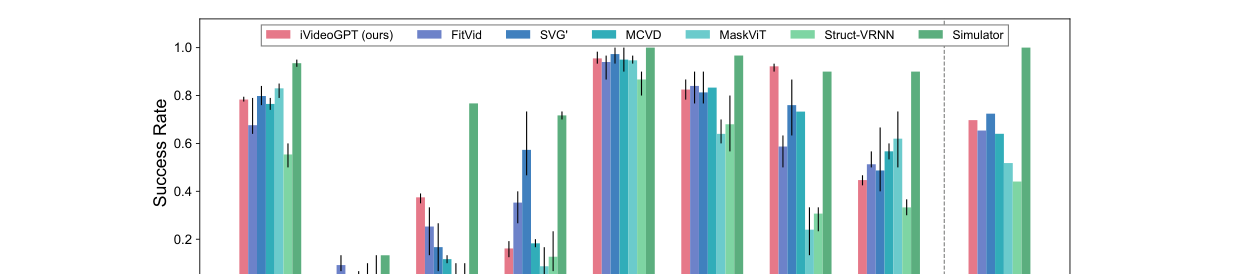
读数:在2 个 RoboDesk 任务上大幅领先所有基线,平均成绩与最强基线 SVG′ 相当。作者承认 open slide 任务表现欠佳(归因于离散化局限 + benchmark 内置奖励设计不完善)。
3.3 视觉 model-based RL(Meta-World,图7)¶
6 个不同难度的 Meta-World 操作任务。把 iVideoGPT 当世界模型,做一个改自 MBPO 的算法:用合成 rollout 扩充 replay buffer,再训标准 actor-critic(底层用 SOTA 的无模型方法 DrQ-v2)。对比 DreamerV3(带/不带预训练)。
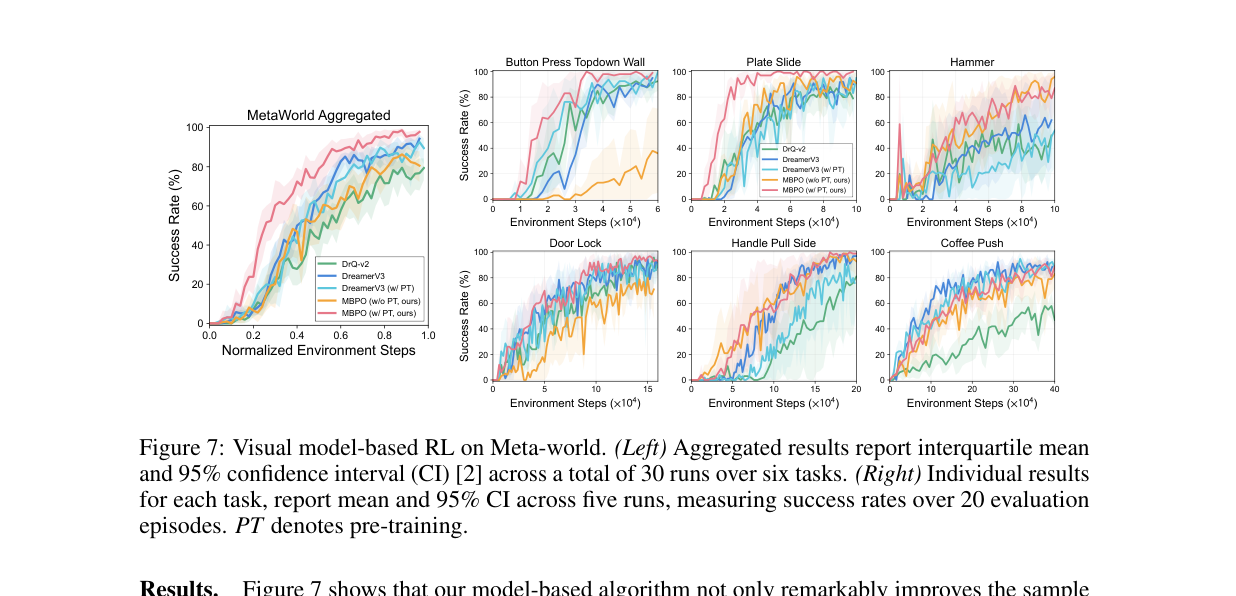
读数:本文的 model-based 法样本效率显著高于无模型基线,匹配或超过 DreamerV3;作者称这是首次把 MBPO 成功用于视觉连续控制。亮点论断:有了够强的世界模型,可以抛掉 latent imagination,把世界模型当"环境的即插即用替身",解耦模型与策略学习。对照实验:把 DreamerV3 XL(200M,与 iVideoGPT 同量级)在同一数据上预训练,预测模糊、无法从预训练获益——佐证"循环世界模型不适合大规模真实数据预训练"。
3.4 模型分析(图9)¶
- 少样本适配:数据充足时预训练增益小;数据稀缺(100/1000 条)时增益显著。用 1000 条 action-conditioned BAIR 适配 → FVD 82.3。
- 模型缩放:默认 138M(12 层、768 维);放大到 436M(24 层、1024 维)。验证 loss(perplexity)随训练持续下降,模型越大下降越快。
- tokenization 效率(图9c,RoboNet 同步数对比):
| tokenizer | LPIPS↓ | 时间 | 显存 |
|---|---|---|---|
| 4×4(普通) | 0.180(差) | 1.45s | 10.6 GB |
| 压缩式(本文) | 0.059 | 1.46s | 22.3 GB |
| 16×16(普通) | 0.036(最好) | 22.8s | 训练 OOM |
读数:压缩式重建质量略逊于 16×16 但远好于 4×4,关键是生成时间几乎与 4×4 持平(1.46 vs 22.8s)、显存可控(16×16 直接 OOM)——以"略降重建"换"能 scale"。 - 上下文-动态解耦可视化(原文图10):解码器去掉对上下文帧的 cross-attention 后,仍能重建出相同运动轨迹但几乎丢失视觉上下文——直接印证 token 只编码了动态。
4. 局限(作者自述 + 诚实读数)¶
- 数据多样性不足:公开机器人数据(含 OXE)多样性有限;引 SSv2 人手视频是初步弥补,仍需更大数据桥接人/机知识。
- 压缩 tokenizer 的假设:假定初始帧能为未来提供足够上下文——适合"看几十步"的低层控制,但长视频 / 大幅相机运动场景会失效(可用关键帧抽取缓解,留作未来)。
- 模态单一:目前主要 action-free 视频;多视角、本体感觉(proprioception)、动作等模态的统一融合尚未展开。
- 缩放收益未验证到底:下游控制任务的仿真视觉过于简单,更大模型的收益尚未观察到。
- 未做真实机器人:低层控制实验全在仿真(Meta-World/VP2)。
🗣️ 外部评价¶
- 🌐 NeurIPS 2024 录用(poster),OpenReview 4TENzBftZR。4 位审稿人评分 5 / 6 / 7 / 6(10 分制),整体正面偏中。
- 🧑 审稿人(rating 5, soundness 3):① 视觉规划只在 2 个设置上超过基线,质疑为何不更普遍领先;② 缺"需要多少机器人/动作数据"的消融——文章动机是"想用免费视频",但没验证对昂贵机器人数据的依赖度、人手视频到底帮了多少;③ 没有真机实验(低层控制只有 6 个仿真任务,其中 3 个仅打平);④ 缺人类用户研究。来源
- 🧑 审稿人(rating 6, soundness 2):① 缺计算效率的定量对比(不同 tokenizer 的训练/推理时间);② 质疑"循环世界模型不可扩展"的论断有多强(自回归每帧多 token 也有开销);③ 质疑"消除 latent imagination"的卖点——已有世界模型(IRIS)就用重建帧学行为,Dreamer 也能用解码器重建这么做。来源
- 🧑 审稿人(rating 7, soundness 4):肯定工作,但点出"技术新颖性偏有限"。来源
- 🧑 审稿人(rating 6, soundness 2):① 行文有过强/过宽的断言(如"获得 broad world knowledge"无证据支撑);② "interactive / scalable"的动机不够清晰——若"可交互"=动作条件,那 Dreamer 乃至更老的世界模型也算可交互;其它模型未必不可扩展。来源
- 🌐 themoonlight.io 的 AI 生成文献综述:肯定16× 压缩 tokenizer、140 万轨迹预训练、三任务通用;列出的局限是"感知模态可扩展、奖励建模仍受限于真实机器人落地"——基本复述作者自述,无独立批评,参考价值低。来源
🤔 我的判断(🤖)¶
- 最硬的贡献是 tokenizer,不是 transformer。把"上下文/动态"解耦做成 conditional VQGAN,用 cross-attention 让未来帧只花 16 token——这是让自回归世界模型"能 scale 又能逐步交互"的真正杠杆,也是图9c"时间几乎不变、16×16 直接 OOM"那组数最有说服力。transformer 侧就是 GPT-2 体量套 LLaMA 件,审稿人说"新颖性有限"是公允的。
- "可消除 latent imagination"是最大胆也最易被攻的论点。审稿人用 IRIS 反驳到位:用重建帧学策略不是 iVideoGPT 独有,把它当架构性优越性来卖偏强;更稳妥的表述是"够强的像素级世界模型让 MBRL 设计空间更简单"。
- 证据强度:A(NeurIPS + 开源代码/权重 + 全表对比),但实验都在仿真、视觉简单,真机与缩放上限都没碰——所以"scalable world model"目前是架构层面的可扩展性主张,不是已被大规模真实数据验证的事实。
- 与卡片一致:它是GPT 式自回归世界模型的代表,价值在"可作机器人世界模型的预训练承载体 + 序列化(obs+action+reward)范式"。
5. 对我们¶
- 三条世界模型路线的坐标系:iVideoGPT(自回归 token)↔ 卡片-UniSim(diffusion,UniSim 不开源)↔ 卡片-Genie(masked + 潜动作)。iVideoGPT 把动作/奖励直接进序列,最贴机器人控制闭环;Genie 走潜动作路线(无需动作标注,从纯视频学可控性)。三者正好覆盖"自回归 / 扩散 / 掩码 + 潜动作"三象限,是我们 radar 上世界模型方向的三个锚点。
- 可复现、可当底座:代码+预训练权重已开源(thuml/iVideoGPT),是我们要试"机器人世界模型预训练"时门槛最低的起点——尤其它证明了"只微调 tokenizer 即可跨域迁移 transformer",对自有数据量小的场景友好。
- 机制可借:①"上下文/动态解耦 + 条件 token 压缩"可迁到任何长序列视觉建模以省算力;② "在最后一个观测 token 上加线性头做奖励/多任务"是把世界模型接进控制的轻量手法。
- 数据视角呼应:它吃的是 OXE + SSv2 这类多本体/人手操作大数据,与本库数据线(详读-DexTeleop-0 谈的"接触密集遥操作采数"、概念-机器人数据与标注)互补——前者攻"怎么用海量异构视频预训练世界模型",后者攻"怎么采到高质量接触数据",两端拼起来才是 model-based 机器人的完整链路。