详读 · DreamerV3(潜空间想象的通用世界模型 RL)¶
卡片版见 卡片-DreamerV3。本页是全文精读:动机 → 方法(逐模块公式直觉) → 鲁棒性技巧 → 实验(全表) → 消融/缩放 → 洞见/局限 → 对我们。 来源:arXiv 2301.04104("Mastering Diverse Domains through World Models",v2 2024-04-17) 作者:Danijar Hafner、Jurgis Pasukonis、Jimmy Ba、Timothy Lillicrap(Google DeepMind + University of Toronto)
0. 一句话定位¶
学一个潜空间世界模型(RSSM),actor-critic 完全在世界模型"想象"出来的抽象轨迹里训练;靠一组归一化/平衡/变换的鲁棒性技巧,做到单一套固定超参跨 8 域 150+ 任务全部跑赢各自调好的专家算法;并首次从零(无人类数据/课程)在 Minecraft 挖到钻石。每个 agent 只用单张 A100。
1. 问题与动机¶
- RL 算法换域(如游戏→机器人)往往要大量调参/专家经验/算力才能用,脆弱性是把 RL 推广到新问题的瓶颈。PPO 通用但性能常输给专用算法;专用算法(连续控制/离散动作/稀疏奖励/图像/空间/棋类)各调各的。
- 世界模型(Dyna / 视觉前瞻 / World Models 谱系)直觉上很美——模型预测动作后果、critic 判价值、actor 选动作——但稳健地学好并用好世界模型一直是开放难题。
- DreamerV3 的切入:不是新范式,而是用一组鲁棒性技巧把"latent imagination"这套范式做到开箱即用、跨域固定超参。
2. 整体范式:三网络在"想象"里闭环(图3)¶
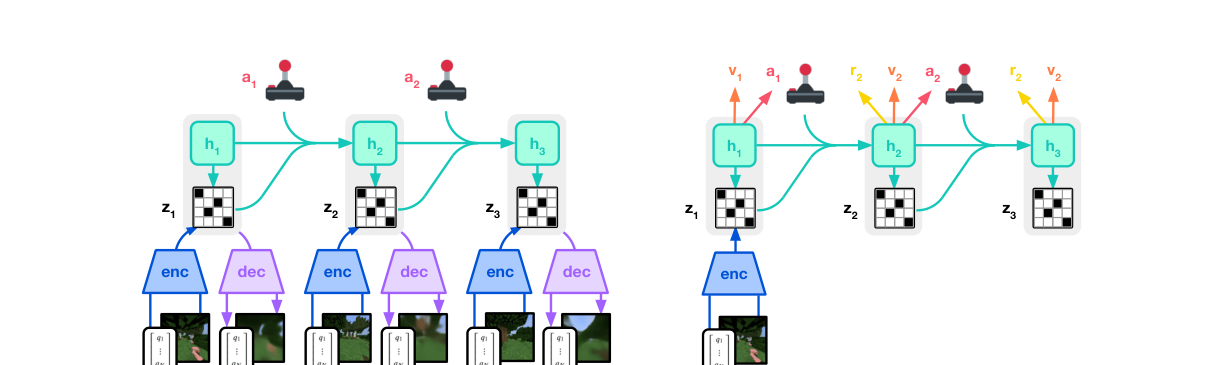
三个神经网络并发从回放经验里训练,同时 agent 与环境交互: - 世界模型:预测潜在动作的后果(下一表征+奖励+是否继续)。 - critic:判断每个状态(在当前 actor 行为下)的回报分布。 - actor:选能到最有价值后果的动作。
关键:actor/critic 只在世界模型 rollout 出来的抽象表征轨迹上学,与环境交互时直接从 actor 采样、不做前瞻搜索(no lookahead planning)。
3. 世界模型 = RSSM(Recurrent State-Space Model)¶
模型状态 s_t = {h_t, z_t}:h_t 是 GRU 的确定性递归状态,z_t 是随机离散表征。各组件(公式1):
- 序列模型:
h_t = f_φ(h_{t-1}, z_{t-1}, a_{t-1}) - 编码器:
z_t ~ q_φ(z_t | h_t, x_t) - 动力学预测器:
ẑ_t ~ p_φ(ẑ_t | h_t)(想象时只靠它,不看真实输入) - 奖励/继续/解码器:
r̂_t, ĉ_t, x̂_t ~ p_φ(· | h_t, z_t)
细节: - 图像走 CNN(stride-2 卷积到 6×6 或 4×4),向量走 MLP(先 symlog 变换);动力学/奖励/继续头都是 MLP。 - 表征从一组 softmax 分布采样(离散 latent),采样步用 straight-through 直通梯度。 - 序列模型是 block GRU(块对角递归权重,8 块)——可放更多记忆单元而不让参数/FLOPs 二次增长。
3.1 世界模型损失(公式2–3)¶
总损失按权重相加:L(φ) = E[ Σ_t (β_pred·L_pred + β_dyn·L_dyn + β_rep·L_rep) ],权重 β_pred=1, β_dyn=1, β_rep=0.1。
- 预测损失 L_pred:解码器+奖励头用后述 symlog 平方损失,继续头用 logistic 回归。
- 动力学损失 L_dyn =
KL( sg(q_φ(z|h,x)) ‖ p_φ(z|h) )——训序列模型去预测下一表征(stop-grad 在编码器侧)。 - 表征损失 L_rep =
KL( q_φ(z|h,x) ‖ sg(p_φ(z|h)) )——让表征变得更可预测(stop-grad 在动力学侧)。 - free bits:把 dyn / rep 两个 KL 截断在 1 nat ≈ 1.44 bits 以下不再下压——已经压够就停手,把学习重心交给预测损失。这一招配上小的表征损失权重(0.1),解决了前代"复杂 3D 场景要强正则、像素敏感游戏要弱正则"的两难,从而跨域固定超参。
- 1% unimix:编码器/动力学的类别分布参数化成 99% 网络输出 + 1% 均匀分布,杜绝退化成确定性、避免 KL 爆 spike。
- 向量观测做 symlog 变换,防大输入/大重构梯度。
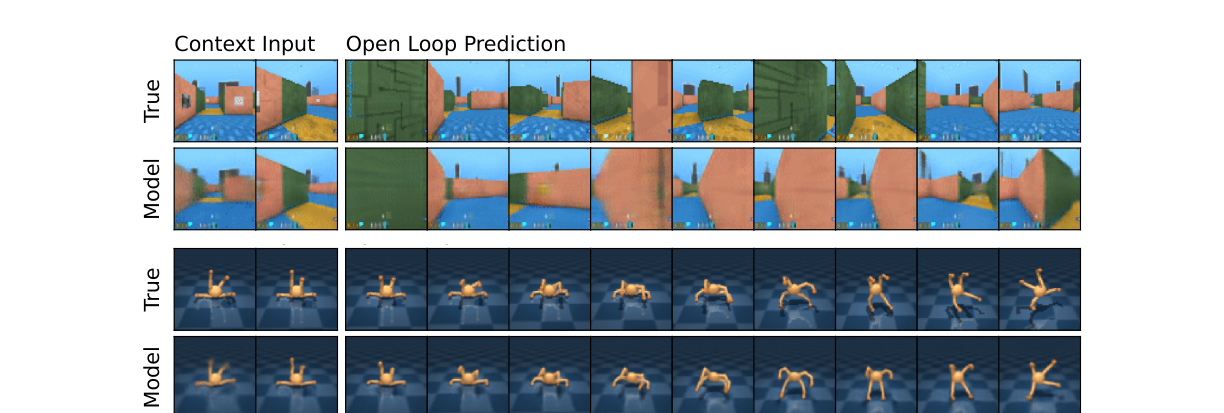
图4 展示世界模型给 5 帧上下文 + 完整动作序列后开环预测 45 帧(DMLab 迷宫 / 四足机器人),说明它学到了环境底层结构:
4. Critic 学习(公式4–5)¶
- actor/critic 操作模型状态
s_t={h_t,z_t},受益于递归世界模型的马尔可夫表征。 - 目标回报
R_t = Σ γ^τ r_{t+τ},折扣 γ=0.997(折扣视界 1/(1-γ)=333)。预测视界 T=16;为顾及视界外奖励,critic 学回报分布。 - bootstrapped λ-return:
Rλ_t = r_t + γc_t[(1-λ)v_t + λ·Rλ_{t+1}],Rλ_T = v_T,λ=0.95。critic 用最大似然L(ψ) = -Σ ln p_ψ(Rλ_t | s_t)。 - critic 不是高斯,而是指数间隔分箱的类别分布(distributional)——把梯度尺度和预测目标解耦,应对多峰且跨数量级的回报。
- critic 损失同时作用于想象轨迹(β_val=1)与回放轨迹(β_repval=0.3):回放项用想象 rollout 起点的 Rλ 作 on-policy 价值标注,再在回放奖励上算 λ-return。
- EMA 自正则:critic 向自身参数的指数滑动平均靠拢(类 target network,但可用当前网算回报);EMA decay 0.98,正则权 1。
- 奖励头与 critic 输出权重零初始化——防训练初期随机大奖励/价值"幻觉"拖慢启动。
5. Actor 学习(公式6–7)¶
- Reinforce 估计器(离散+连续动作统一用),加熵正则鼓励探索:
L(θ) = -Σ sg[(Rλ_t - v_ψ(s_t))/max(1,S)] · log π_θ(a_t|s_t) + η·H[π_θ(·|s_t)] - 固定熵尺度 η = 3×10⁻⁴ 跨域可用,关键在回报归一化:把回报缩到约 [0,1]。
- 归一化分母 S:用回报 batch 的第 95 与第 5 百分位差、再 EMA 平滑:
S = EMA(Per(Rλ,95) - Per(Rλ,5), 0.99)。用百分位而非最大最小 → 抗离群。 - 只缩大不缩小:分母取
max(1, S),小于阈值 L=1 的小回报不放大 → 稀疏奖励下不放大函数逼近噪声、保住探索。 - 作者明确对比:归一化 advantage(PPO 式)/按标准差归一化/约束式固定熵——这些他们都找不到跨域稳定的超参;带分母下限的回报归一化才同时做到"稀疏快探索、稠密高收敛"。
6. 鲁棒预测:symlog 与 symexp twohot(公式8–11)¶
核心难题:重构/奖励/回报的尺度跨域差很多。大目标用平方损失会发散,绝对/Huber 损失学得慢,按 running stats 归一化又引入非平稳。
- symlog 平方损失:网络预测
symlog(y),读出时反变换ŷ = symexp(f(x))。 symlog(x) = sign(x)·ln(|x|+1),symexp(x) = sign(x)·(exp(|x|)-1)。- 对称压缩大正/大负值,原点附近≈恒等(不干扰本就小的目标),且保号、能预测负值。
- symexp twohot 损失(用于奖励头与 critic 这类随机目标):网络对指数间隔的分箱
B = symexp(linspace(-20, +20))输出 softmax logits,读出为按概率加权的箱位置(可落在两箱之间);训练目标是 twohot 编码(只有最近两个箱非零、线性分权、和为1)的交叉熵。 - 妙处:损失只依赖箱上的概率、不依赖箱对应的连续值 → 梯度大小与目标大小彻底解耦。
- 对比同类方案:symlog 既不像 Huber 那样截断大目标、也不像归一化那样引入非平稳、也不像 PopArt 那样在见到新极值时改网络权重。
7. 工程配置(鲁棒性的另一半)¶
- 优化器:AGC(自适应梯度裁剪)——逐张量裁剪,超过对应权重矩阵 L2 范数的 30% 才裁,默认 ε=10⁻³;把裁剪阈值与损失尺度解耦。再用 LaProp(先 RMSProp 归一化再动量,ε=10⁻²⁰,β1=0.9, β2=0.99)——比 Adam 能用更小 ε、避免偶发不稳。
- 激活/归一化:RMSNorm + SiLU。
- 不用任何超参退火、优先回放、权重衰减、dropout。
7.1 核心超参(Table 4,全域统一)¶
| 名称 | 符号 | 值 |
|---|---|---|
| 回放容量 | — | 5×10⁶ |
| Batch size | B | 16 |
| Batch length | T | 64 |
| 学习率 | — | 4×10⁻⁵ |
| 梯度裁剪 | — | AGC(0.3) |
| 优化器 | — | LaProp(ε=10⁻²⁰) |
| 重构损失权 | β_pred | 1 |
| 动力学损失权 | β_dyn | 1 |
| 表征损失权 | β_rep | 0.1 |
| latent unimix | — | 1% |
| free nats | — | 1 |
| 想象视界 | H | 15 |
| 折扣视界 | 1/(1-γ) | 333 (γ=0.997) |
| λ-return | λ | 0.95 |
| critic 损失权(想象/回放) | β_val / β_repval | 1 / 0.3 |
| critic EMA 衰减 | — | 0.98 |
| actor 熵正则 | η | 3×10⁻⁴ |
| 回报归一化 | S / L | Per(R,95)-Per(R,5) / 1,EMA 0.99 |
7.2 模型尺寸(Table 3,12M–400M)¶
| 参数量 | 12M | 25M | 50M | 100M | 200M | 400M |
|---|---|---|---|---|---|---|
| 隐藏维 d | 256 | 384 | 512 | 768 | 1024 | 1536 |
| 递归单元 8d | 1024 | 3072 | 4096 | 6144 | 8192 | 12288 |
| 基础 CNN 通道 d/16 | 16 | 24 | 32 | 48 | 64 | 96 |
| 每 latent 编码数 d/16 | 16 | 24 | 32 | 48 | 64 | 96 |
层数与 latent 数跨尺寸固定;学习率/batch 也固定。默认用 200M,两个控制套件用更快的 12M 即可达同等性能。
8. 实验结果¶
8.1 基准总览(图1)¶
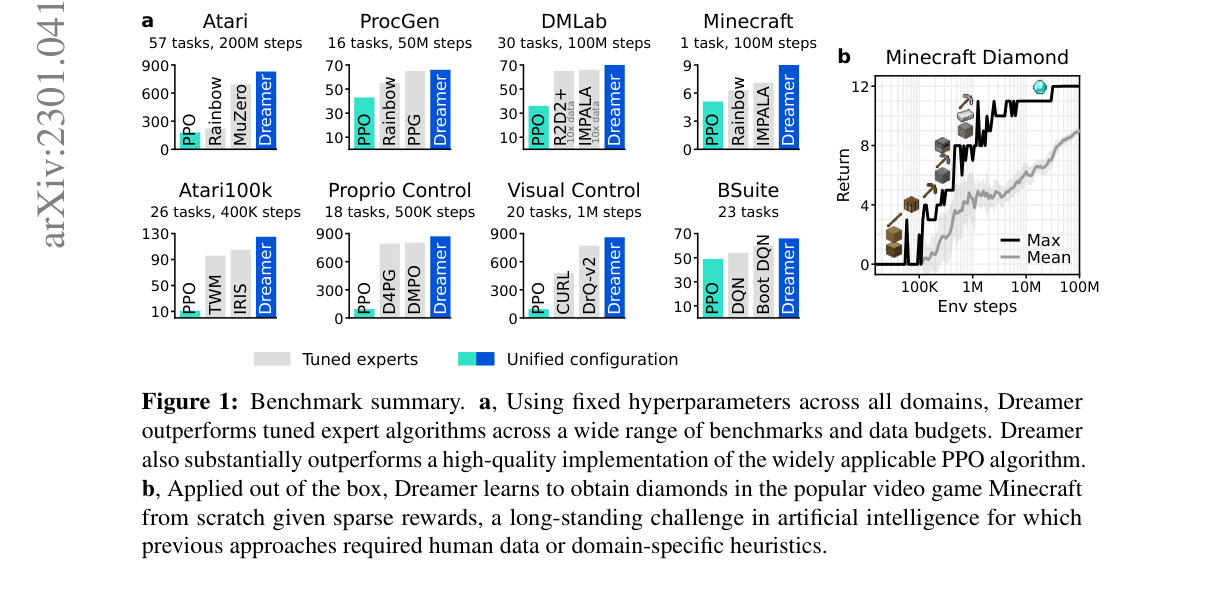
8 个域 / 150+ 任务,固定超参,每个 agent 单张 A100。各域结论:
| 域 | 任务×预算 | 结论 |
|---|---|---|
| Atari | 57×200M帧 | 跑赢 MuZero(且算力只用一小部分)、Rainbow、IQN |
| ProcGen | 16×50M帧 | 持平调优专家 PPG,胜 Rainbow;自家固定超参 PPO 复现了官方调优 PPO |
| DMLab | 30×100M帧 | 100M 步超过 IMPALA/R2D2+ 在 1B 步的成绩 → >1000% 数据效率(10×) |
| Atari100k | 26×400K帧(2小时) | 胜 IRIS、TWM、SPR、SimPLe(EfficientZero 因用早重置等技巧,作者认为难直接比) |
| Proprio Control | 18×500K步 | 新 SOTA,胜 D4PG/DMPO/MPO |
| Visual Control | 20×1M步 | 新 SOTA,胜 DrQ-v2/CURL(它们靠数据增广专做视觉) |
| BSuite | 23 环境/468 配置 | 新 SOTA,胜 Boot DQN,尤其"尺度鲁棒性"类 |
8.2 各基准训练协议(Table 2)¶
| 基准 | 任务 | 环境步 | 动作重复 | 环境实例 | 回放比 | GPU-天 | 模型 |
|---|---|---|---|---|---|---|---|
| Minecraft | 1 | 100M | 1 | 64 | 32 | 8.9 | 200M |
| DMLab | 30 | 100M | 4 | 16 | 32 | 2.9 | 200M |
| ProcGen | 16 | 50M | 1 | 16 | 64 | 16.1 | 200M |
| Atari | 57 | 200M | 4 | 16 | 32 | 7.7 | 200M |
| Atari100K | 26 | 400K | 4 | 1 | 128 | 0.1 | 200M |
| BSuite | 23 | — | 1 | 1 | 1024 | 0.5 | 200M |
| Proprio Control | 18 | 500K | 2 | 16 | 512 | 0.3 | 12M |
| Visual Control | 20 | 1M | 2 | 16 | 512 | 0.1 | 12M |
种子:每基准 Dreamer/PPO 各 5 种子(ProcGen 因算力 1 种子,BSuite 10,Minecraft 10)。
8.3 Minecraft 挖钻石(图5、Table 5)¶
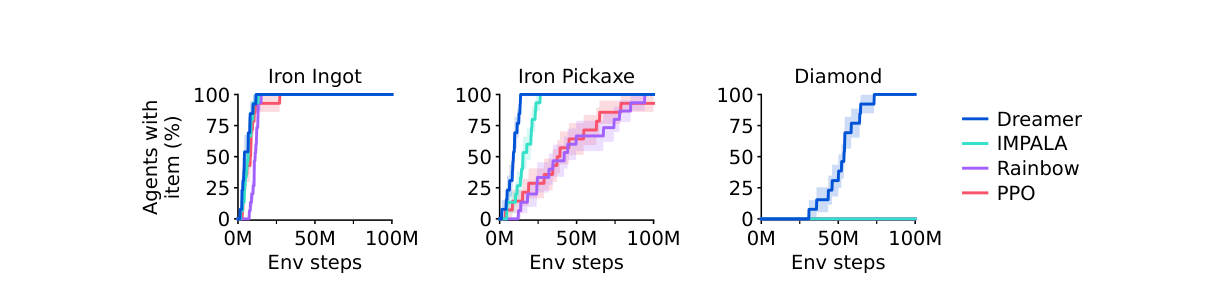
- 每局独立随机生成无限 3D 世界;最长 36000 步 = 30 分钟@20Hz;要从稀疏奖励里依次拿到通往钻石的 12 个里程碑(原木→木板→棍→工作台→木镐→圆石→石镐→铁矿→熔炉→铁锭→铁镐→钻石),每里程碑 +1。观测 64×64×3 第一视角图 + 物品栏(>400 项)等。
- 采用 block-breaking 设定(原动作空间要长按键,对随机策略不友好);用 MineRL v0.4.4,Minecraft 1.11.2。
100M 步回报(Table 5):
| 方法 | 回报 |
|---|---|
| Dreamer | 9.1 |
| IMPALA | 7.1 |
| Rainbow | 6.3 |
| PPO | 5.1 |
- 首个从零(无人类数据/课程)挖到钻石的算法;训练过程中 100% 的 Dreamer agent 至少挖到 1 颗钻石,基线 0%。在 100M 步预算处,钻石出现在 0.4% 的 episode 里(留给后续研究的挑战)。
- 对比 VPT:用人类键鼠数据行为克隆 + RL 微调、720 GPU × 9 天才拿钻石;Dreamer 1 GPU × 9 天、无人类数据。
8.4 消融与缩放(图6)¶
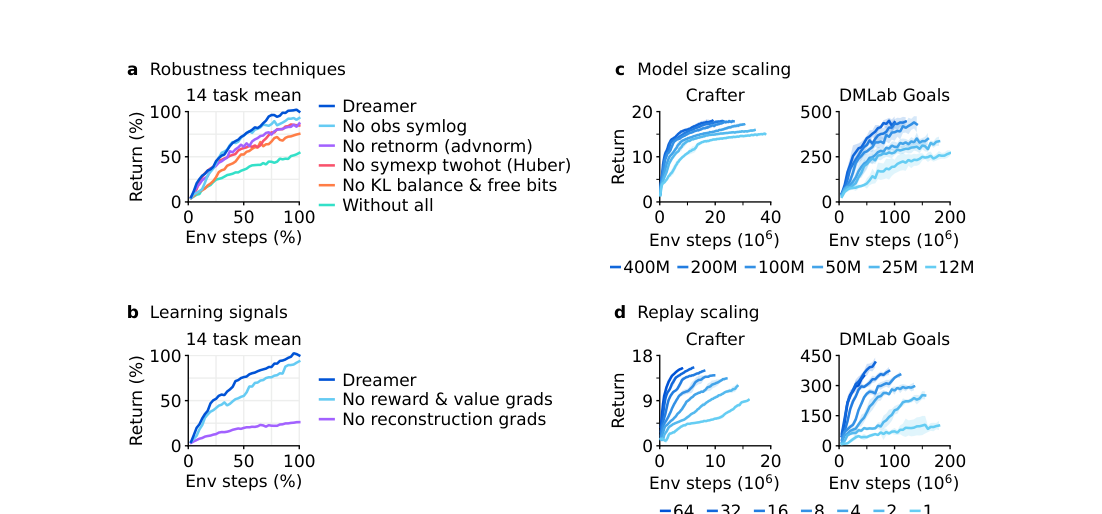
- (a) 鲁棒性技巧:每个技巧都贡献(在某子集任务上关键、对其他任务可能无感)。影响最大的是世界模型的 KL 目标(KL balance & free bits),其次回报归一化,再次 symexp twohot。去掉全部("Without all")明显塌。
- (b) 学习信号:Dreamer 性能主要靠世界模型的无监督重构损失,而非像多数 RL 那样靠奖励/价值梯度——停掉重构梯度比停掉奖励/价值梯度掉得多。这暗示未来可用无监督数据预训练。
- (c) 模型尺寸 12M→400M:性能单调上升,且更大模型不仅分更高、还更省交互(数据效率也涨)。
- (d) 回放比:更高回放比(更多梯度更新)可预测地提升性能。→ 给从业者一条"加算力换性能/数据效率"的可预测路径。
9. 核心洞见¶
- 把范式做稳 > 发明新范式:latent imagination 早有(Dreamer V1/V2),V3 的贡献是一组归一化(symlog/RMSNorm)+平衡(KL free bits、回报百分位归一化)+变换(symexp twohot)的工程组合,换来"开箱即用、固定超参跨域"。
- 尺度无关化是主线:symlog、twohot、百分位回报归一化、AGC——全都在把"未知数量级的量"变得可稳定回归。
- 世界模型的无监督信号是性能主体(消融 b),这是和主流 model-free RL 最不同的结论,也指向"用海量无标注视频预训练世界模型"的未来。
- 可预测缩放:模型越大/回放越多→越好且越省交互,给出工程上确定的提升旋钮。
10. 局限 / 存疑(诚实)¶
- 钻石仍稀:100M 步处只 0.4% episode 拿到钻石——"能挖到"≠"高频可靠",作者自己点为遗留挑战。
- 比较口径:DMLab 的"10×数据效率"是拿 Dreamer 100M 步对基线 1B 步(那些基线本就非为数据效率设计);Atari100k 把 EfficientZero 排除在直接对比外(因其用早重置/树搜索等)——读数要带着这些前提看。
- 算力:Minecraft 仍要 8.9 GPU-天;虽单卡可跑,但非廉价。
- 领域:全是游戏/控制 benchmark,机器人真机的本体接入与数据自采不在本文范围(范式可借,落地要自己补)。
- Minecraft 用了改造过的 block-breaking 动作空间与若干环境修正,非完全原生设定。
11. 对我们(深一层)¶
- 世界模型范式的底座参考:DreamerV3 是"在脑内 rollout 再决策"的 model-based RL 代表作,放进 综述-世界模型 的"预测未来"轴最典型;理解它有助于读后续机器人世界模型。
- 与本库世界模型卡互参:隐空间预测谱系见 卡片-LaWAM、卡片-DINO-WM、卡片-VT-WM、卡片-iVideoGPT、卡片-NWM;视频/生成式世界模型见 卡片-Genie、卡片-Cosmos、卡片-UniSim、卡片-VPP;世界模型+VLA 见 卡片-WorldVLA。DreamerV3 与这些的差异在于它是离散 latent RSSM + 在想象里做 RL,而非纯生成或纯表征。
- 可借的工程招式:symlog / symexp-twohot / 百分位回报归一化 / free-bits KL / AGC,是任何"跨尺度目标稳定回归"场景(含 概念-模型架构基础 讨论的训练稳定性)都能参考的通用技巧。
- 对照视角:它的核心结论"性能主要来自世界模型的无监督重构损失",与 综述-世界模型 里"理解世界 vs 预测未来"的划分相呼应——DreamerV3 同时吃两端,但重心在重构(理解)。