详读 · Octo(开源通用机器人策略 Generalist Robot Policy)¶
卡片版见 卡片-Octo。本页是全文精读:动机 → 方法(逐模块) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2405.12213v2(2024-05-26,RSS 2024)· 项目页 · 代码 作者:Octo Model Team(Dibya Ghosh、Homer Walke、Karl Pertsch、Kevin Black、Oier Mees 等共同一作)—— UC Berkeley · Stanford · CMU · Google DeepMind
0. 一句话定位¶
把 Open X-Embodiment 中精选的 80 万条机器人轨迹喂进一个"Transformer 优先"的策略,用扩散动作 head 出连续多模态动作;核心卖点不是某个零件新,而是分块注意力 + 模块化 token 接口让它能在几小时内、消费级单卡上微调到新观测(力/触觉)、新动作空间(关节控制)、新本体(双臂)——并且训练管线/权重/数据全开源。
1. 问题与动机¶
- 机器人学习老路:每个机器人/任务从零采数、从零训练 → 采数贵、泛化窄。
- 跨机器人大数据本可救场,但要做"通用机器人策略 (GRP)"很难:得同时吃下不同本体、传感器、动作空间、任务规格、环境、算力预算。
- 前人 GRP(RT-1-X、RT-2-X、RoboCat、GNM)虽是大步,但有三个共同短板:① 锁死输入(通常只接固定的单路相机流);② 不支持高效微调到新域;③ 最大的模型不开源。
- Octo 的切入:不声称单个组件是发明,而是把"transformer 主干 + 语言/目标图双任务规格 + 扩散动作 head"组合成一个可灵活增删输入输出、可廉价微调、全开源的通用底座。
2. 模型架构(图1)¶
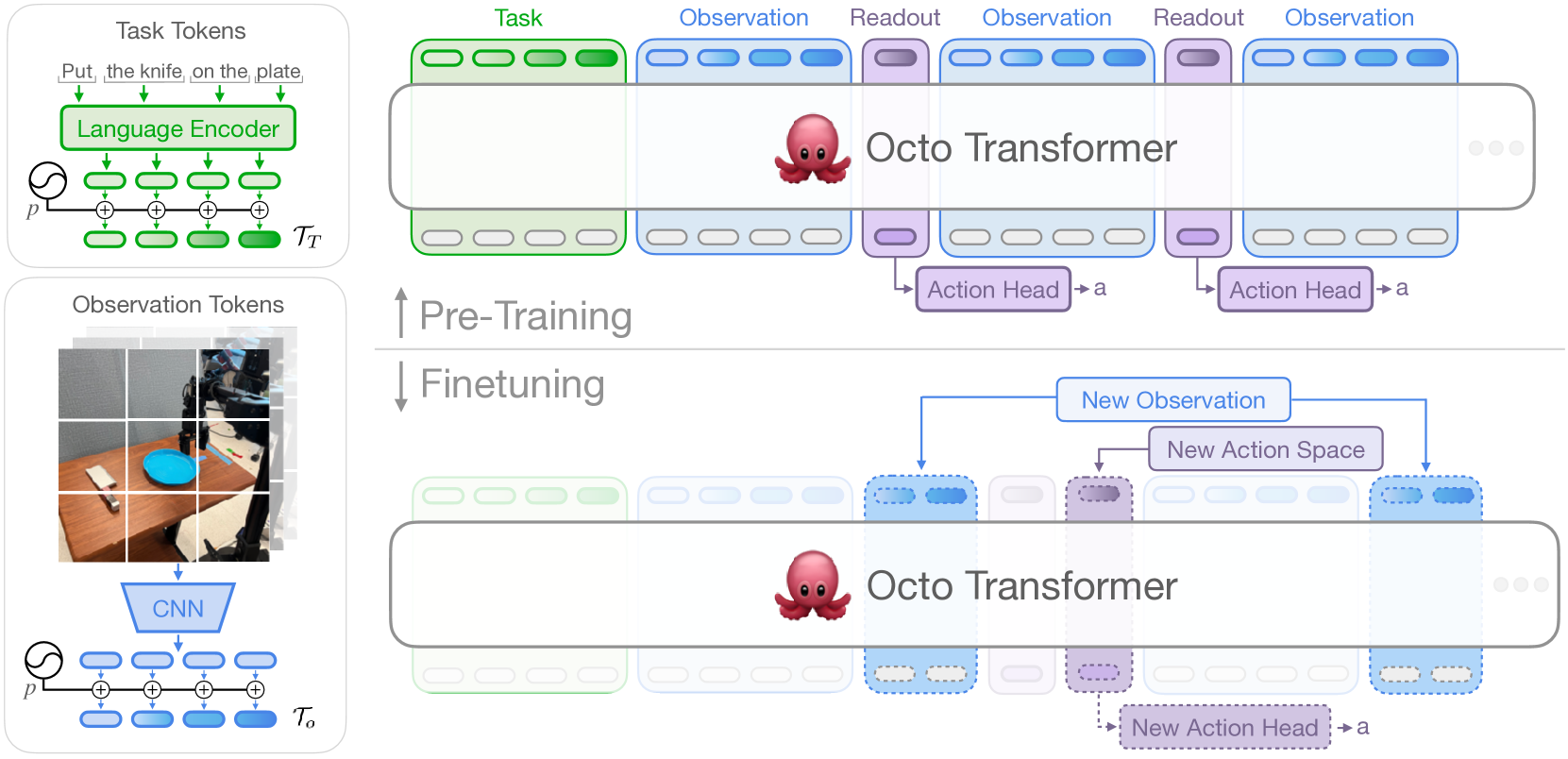
策略 π 三部件:输入 tokenizer → Transformer 主干 → readout head。
2.1 任务 / 观测 tokenizer(模态各一)¶
- 语言:先分词,再过冻结的 t5-base(111M) 编码器 → 16 个语言 embedding token。
- 图像(观测 & 目标图):过很浅的卷积栈,再切成 16×16 patch 展平成序列 → 第三人称相机(256×256)出 256 token,腕部相机(128×128)出 64 token。
- 任务/观测 token 加可学习位置编码后顺序拼成输入序列。
2.2 Transformer 主干 + readout head(关键设计)¶
- 分块掩码注意力(block-wise):观测 token 只能因果地attend 到同时刻或更早的观测 token,以及任务 token;不存在的模态(如无语言)整块 mask 掉。→ 这是"能增删输入"的根。
- readout token(类比 BERT 的 [CLS]):它能读前面的任务/观测 token,但不被任何 token attend → 只被动汇总、不污染主干表示。轻量 diffusion action head 接在 readout embedding 上。
- 动作分块(action chunking):一次预测未来连续若干步动作,动作更连贯。
- 微调时的灵活性(图1下半):加新任务/观测/loss 时,预训练权重整段保留,只新增位置编码、轻量 encoder 或新 head 的参数。对比 RT-1/GNM 这类——换个相机或任务规格就得重初始化/重训大块模型。
设计取向:"transformer 优先"——用极浅 CNN patch encoder,把绝大多数参数/FLOPS 放进 transformer 主干(仿标准 ViT),而非主流的"大 ResNet 编码器 + 小 transformer"。
3. 训练数据(图2)¶
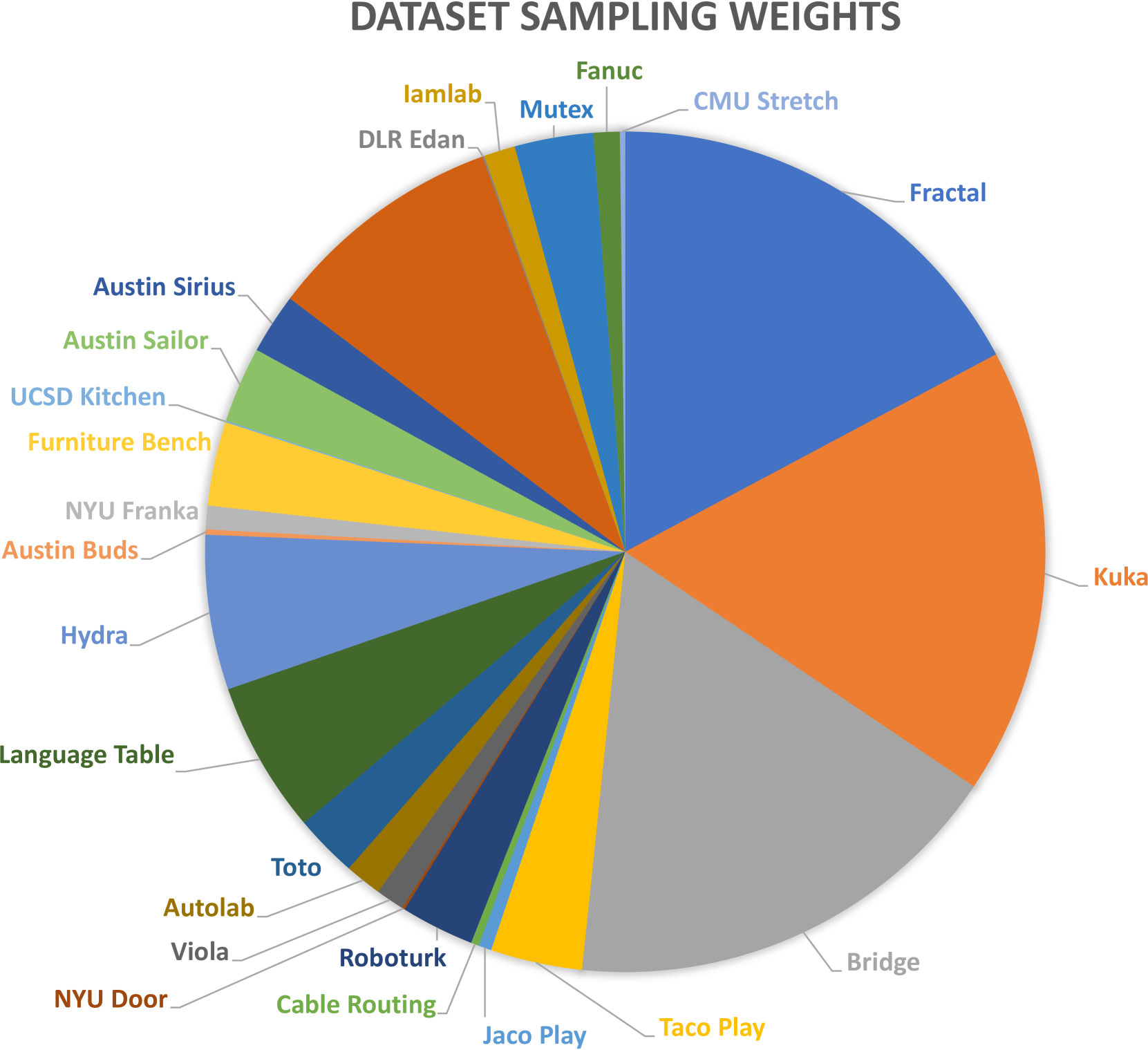
- 取自 Open X-Embodiment(约 150 万条 episode),精选 800k 用于 Octo 训练(RT-X 只用了更受限的 350K / 11 个数据集子集)→ 作者称这是当时最大的机器人操作演示数据集。
- 精选规则:去掉无图像流、非 delta 末端执行器控制、太重复、分辨率太低、任务太小众的数据集;剩下按"更多样/较单一"粗分,更多样的训练权重翻倍,重复多的降权。
- 统一处理:缺失相机通道零填充;夹爪动作对齐为 +1=开、0=闭(绝对表示,见 §7 消融)。
- 数据混合占比(前几名,附表 III):
| 数据集 | 采样占比 |
|---|---|
| Fractal | 17.0% |
| Kuka | 17.0% |
| Bridge | 17.0% |
| BC-Z | 9.1% |
| Stanford Hydra | 6.0% |
| Language Table | 5.9% |
| Taco Play | 3.6% |
| Furniture Bench | 3.3% |
| UTAustin Mutex | 3.0% |
| Austin Sailor | 2.9% |
| (余 15 个数据集合计) | ≈ 约 20% |
4. 训练目标与超参¶
4.1 扩散动作 head(DDPM)¶
- 用条件扩散解码 head 出连续、多模态动作分布;主干每次动作只前向一次,多步去噪全在小 head 内部完成。
- 去噪迭代式(论文式 1):
x_{k-1} = α(x_k − γ·ε_θ(x_k, e, k) + N(0, σ²I)),e为 readout embedding;用标准余弦噪声调度、标准 DDPM 目标训练去噪网络 ε_θ。 - head 结构:3 层 MLP,hidden 256,带残差 + LayerNorm;20 步扩散。
- 微调时同一扩散目标 + 更新全模型(比冻结部分参数更好)。
4.2 关键超参(附表 IV/V)¶
| 项 | 值 |
|---|---|
| 学习率 | 3e-4(倒数平方根衰减 + 线性 warmup 2000 步) |
| Weight decay | 0.1 |
| 梯度裁剪 | 1.0 |
| Batch size | 2048 |
| 优化器 | AdamW |
| 观测历史 | 2 帧(更长无明显增益) |
| 扩散步数 | 20 |
| 变体 | 层数 | hidden D | MLP | heads | 参数量 |
|---|---|---|---|---|---|
| Octo-Tiny | — | — | — | — | 10M |
| Octo-Small | 12 | 384 | 1536 | 6 | 27M |
| Octo-Base | 12 | 768 | 3072 | 12 | 93M |
4.3 算力账(很实在的卖点)¶
- 预训练:Octo-Base 训 300k 步、batch 2048、TPU v4-128 pod、14 小时。
- 微调:同模型在单张 NVIDIA A5000(24GB)约 5 小时,~100 条演示、50k 步、余弦衰减 + 线性 warmup,所有任务同一套超参。
- 训练用 hindsight 目标重标注(从未来均匀取一帧当目标图),按样本随机置零语言或目标图 → 一个模型可被语言或目标图任一条件化;无语言标注的数据集一律用目标图条件。
5. 实验¶
评测覆盖 4 个机构、9 个真机平台(图3):既测"匹配预训练数据的开箱即用零样本",也测"微调到新观测/新动作空间/新本体"。

5.1 开箱即用多机器人控制(零样本,图4)¶
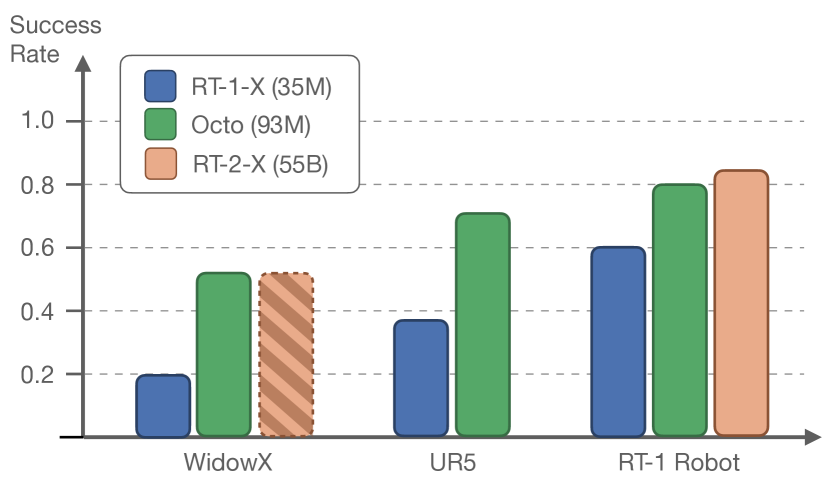
- 对比对象:RT-1-X(35M)(同样 Open-X 预训练,最佳公开 GRP)与 RT-2-X(55B,VLM 微调)。
- 每个机器人选 2 个语言任务、每任务 10 次试验(变初始物体位置/光照/背景/干扰物)。
- 结论:Octo 平均成功率比 RT-1-X 高 29%;在 WidowX 与 RT-1 Robot 上与 RT-2-X(550 亿参数)相当(WidowX 的 RT-2-X 为引用值,虚线柱)。
- 目标图条件 vs 语言条件:在 WidowX 上目标图条件比语言条件高 25%(目标图给的"怎么做"信息更多)。
零样本泛化拆解(附表 VII,Octo-Small,WidowX,每条 20 次):
| 泛化类型 | 任务 | 成功率 | 平均 |
|---|---|---|---|
| 分布内 | Put carrot on plate / eggplant in pot | 80% / 90% | 85% |
| 新物体 | Put bread on plate / spoon on glove | 70% / 90% | 80% |
| 新环境 | Put mushroom in pot / spoon on cloth | 20% / 60% | 40% |
| 新技能 | Flip cup / Put block in slot | 10% / 0% | 5% |
即:换物体几乎不掉,换场景明显掉,换"没见过的技能"(翻转、精插)几乎崩。
5.2 数据高效微调(表 I)¶
每域 ~100 条演示、同一套超参、每域 20 次试验。*=新观测(力/力矩本体感知);†=新动作空间(关节位置控制)。
| 域 | Scratch(ResNet+Transformer) | VC-1 | Octo |
|---|---|---|---|
Berkeley Insertion * |
10% | 5% | 70% |
| Stanford Coffee | 45% | 0% | 75% |
| CMU Baking | 25% | 30% | 50% |
Berkeley Pick-Up † |
0% | 0% | 60% |
| Berkeley Coke(新本体) | 20% | 10% | 100% |
Berkeley Bimanual †(新本体双臂) |
20% | 50% | 80% |
| 平均 | 20% | 15% | 72% |
Octo 平均比次优基线高 52%。同时印证:能吃新观测(力/力矩)、新动作空间(关节)、新本体(ViperX/ALOHA 双臂)。双臂任务用了 chunk=64 训练、测试时 receding horizon 执行 12 步再重规划。
5.3 设计消融(表 II / VI,WidowX,40 次试验)¶
| 维度 | 配置 | 聚合成功率 |
|---|---|---|
| 本方法 | Octo-Small(ViT + 扩散 + 全数据) | 83% |
| DATA | RT-X 数据混合(11 集) | 60% |
| DATA | 单机器人数据(Bridge) | 43% |
| POLICY | 离散动作预测 | 18% |
| POLICY | 连续动作(MSE) | 35% |
| ARCH | ResNet-50 + Transformer | 70% |
三条结论:数据越宽越好(25 集 > 11 集 > 单集,且暗示再加更多集仍可能涨);扩散 head 完胜 MSE/离散(多模态 + 连续精度);ViT"transformer 优先"在大数据上胜 ResNet(但小数据从零训反而 ResNet 更好 → 大 transformer 策略是"为大数据而生")。
5.4 模型缩放(图5)¶
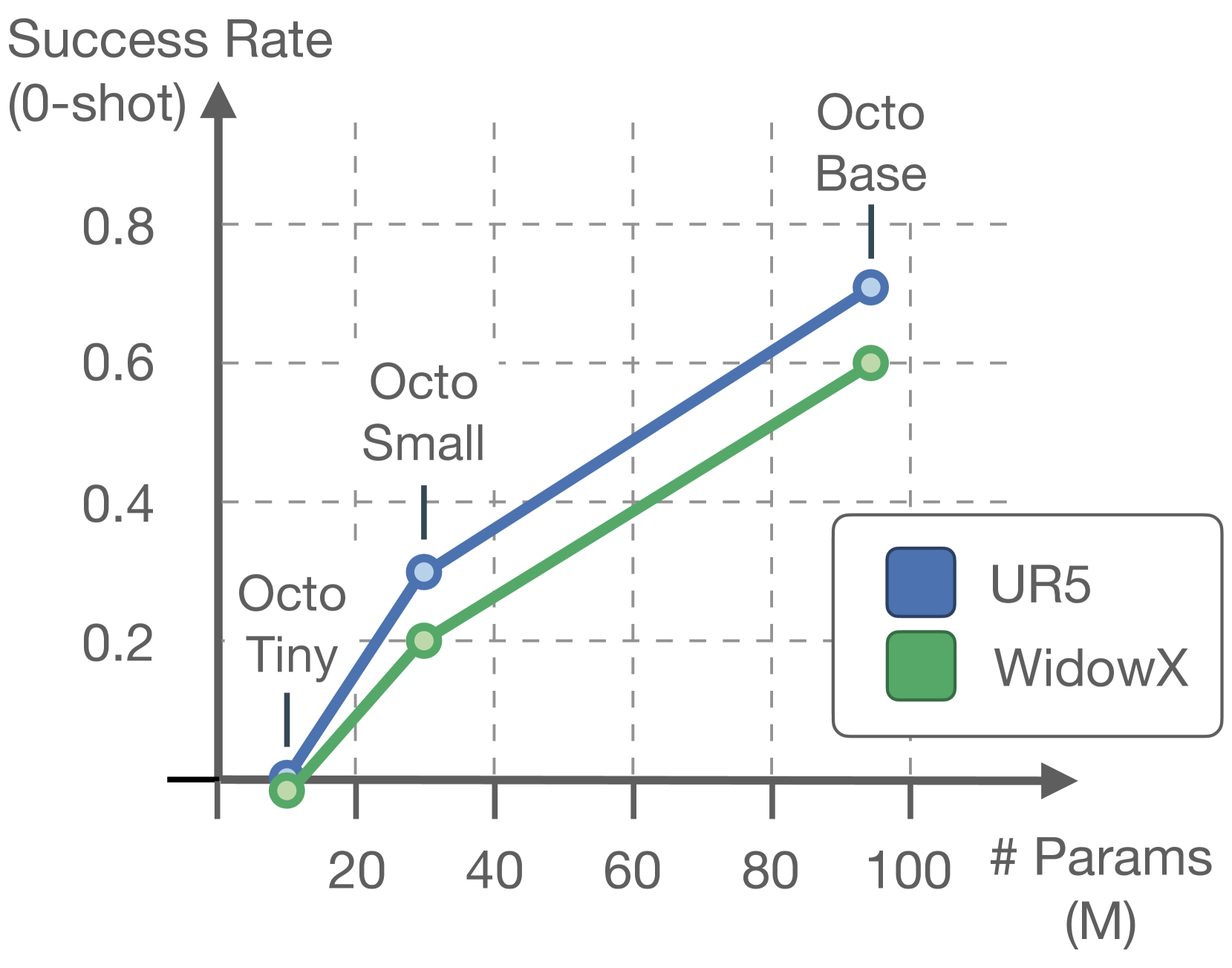
- Tiny(10M) → Small(27M) → Base(93M),零样本成功率随规模单调上升;Base 对初始场景更鲁棒、更少"过早抓取",说明大模型视觉场景感知更好。
6. 诚实的"有用 / 没用"清单(附录 E,作者亲点)¶
有用: - 预训练带 1 帧历史 > 无历史(但再加更多帧无明显增益); - 动作分块让动作更连贯(但 receding horizon 之外的"时间集成"无额外收益); - patch 16×16 > 32×32(抓取等精细任务更好,但 token 数 ×4、算力涨); - 大 shuffle buffer(500k)至关重要——小 buffer(20k)+轨迹级交错会显著掉零样本;每条轨迹最多抽 100 步以防长 episode 挤爆 buffer。
没用 / 还没成(诚实局限): - MSE head:策略"对冲"、动作极慢、WidowX 里不转夹爪; - 离散 head:更果断但欠精度、常抓空; - ResNet 编码器:大数据上不如 ViT(但小数据从零训更好); - ImageNet 预训练编码器:零样本无收益; - 相对夹爪动作表示:开合更少、抓失败后不重试 → 最终更差,故选绝对表示; - 加本体感知(proprio)输入:普遍更差,疑似 state 与未来动作因果混淆; - 微调语言模型 / 换更大 T5(small 30M / base 111M / large 386M、微调末两层):都没更好,冻结的 t5-base 最佳——归因于多数数据集缺乏丰富自由文本标注。
7. 局限 / 存疑(§5 讨论 + 全文)¶
- 腕部相机处理不好:很多微调"只用第三人称"反而比"第三人称 + 腕部"更强 → 因只有 27% 数据含腕部相机。
- 语言条件明显弱于目标图条件 → 因只有 56% 预训练数据有语言标注。
- 只学最优演示(纯模仿):Open-X 全是最优 demo,未用次优/在线交互数据。
- 只覆盖单臂 + 双臂操作,未涉导航/移动操作。
- 评测规模有限(多为每任务 10–20 次试验);泛化到新技能很弱(表 VII 新技能仅 5%)。
8. 核心洞见¶
- "组合 + 接口"也是创新:组件(transformer、扩散 head、目标图/语言)都不新,但分块注意力 + readout token + 模块化 tokenizer 让"增删输入输出而不动预训练权重"成为可能——这才是把通用策略变成可复用底座的关键。
- scale + 少归纳偏置 + 富表达目标三件套:最好的模型来自最宽数据混合 + 最少限制的架构(ViT) + 能拟合多样行为的策略目标(扩散)。
- 大策略要配大数据:ViT 在大数据胜、在小数据(从零)输 ResNet——印证"大 transformer 策略是为 scale 而生"。
- 全开源是它区别于 RT-2-X/RoboCat 的最大资产:权重(27M/93M) + 训练/微调管线(JAX) + 兼容 JAX/PyTorch 的 Open-X 数据加载器都放出。
9. 对我们¶
- 开源底座对照:与 卡片-OpenVLA 同属 Open-X 系开源通用策略,但走"扩散动作 head + 灵活 token 接口"而非"VLM 离散动作"路线 → 两个底座可在概念-模型架构基础层面长期对照(架构/动作表示/微调成本)。
- 数据是命门:Octo 的腕部相机/语言短板都直接来自数据占比(27% / 56%),印证 概念-机器人数据与标注 里"数据构成决定能力边界"。
- 接新模态的现成钩子:其"微调时加新观测/新动作 head 不动预训练权重"的机制,是把额外传感观测接入通用策略的公开范式,可作 概念-机器人数据与标注 相关方向的参考实现。
- 与触觉/接触线:表 I 中"Berkeley Insertion 加力/力矩输入微调到 70%"是公开证据,说明通用策略可吸收接触类信号——与 卡片-ReactiveDiffusionPolicy、卡片-NeuralFeels 同处"接触感知 + 策略"战场,可互为对照。