详读 · Open X-Embodiment(22 本体汇聚的跨本体数据集 + RT-X 模型)¶
卡片版见 卡片-Open-X-Embodiment。本页是全文精读:动机 → 数据集汇聚 → RT-X 设计 → 实验全表 → 局限/洞见 → 对我们。 来源:arXiv 2310.08864(v9, 2025-05-14)· 项目页 作者:Open X-Embodiment Collaboration(Google DeepMind 牵头,21 家机构联署,数百名作者)
0. 一句话定位¶
把全球 21 家机构、34 个实验室的 60 个已有机器人数据集,统一转成一种标准格式(RLDS),汇聚成跨 22 种本体、1M+ 真实轨迹、527 项技能(160266 tasks)的 Open X-Embodiment(OXE) 数据集;并在其上把 RT-1 / RT-2 几乎原样训练成 RT-1-X / RT-2-X,用实验证明——直接在多本体数据上训练,无需任何专门弥合 embodiment gap 的机制,就能产生正迁移:单机器人能力被"别的机器人的经验"抬高。论文自陈目标不是发明新架构,而是给社区一套数据 + 工具 + 模型基座,点燃跨本体研究。
1. 问题与动机¶
- NLP / CV 的核心经验:大而多样的数据 + 高容量预训练模型能压过窄任务专用模型(CLIP、LLM)。机器人能不能也来一次这样的"模型整合"?
- 机器人的困境:① 单一机器人域太窄;② 不像网络图文那样有海量数据——最大的机器人采集也只是 CV(5–18M)/NLP(1.5–4.5B) 数据集的零头,且常在某个轴上很窄(单环境/单组物体/窄任务)。
- 论文立场:通用机器人策略需要 X-embodiment 训练——单个数据集都太窄,但所有数据集的并集能覆盖更广的环境/机器人变化。哪怕现在还达不到 LLM 那种泛化,现在就该让跨本体研究做起来。
- 两个目标:(1) 验证多机器人/多环境联训是否带来正迁移(强于只用本域数据训练);(2) 组织大规模数据集,为未来跨本体研究打地基。聚焦机器人操作(manipulation)。
2. 数据集汇聚(图1 + 图2)¶
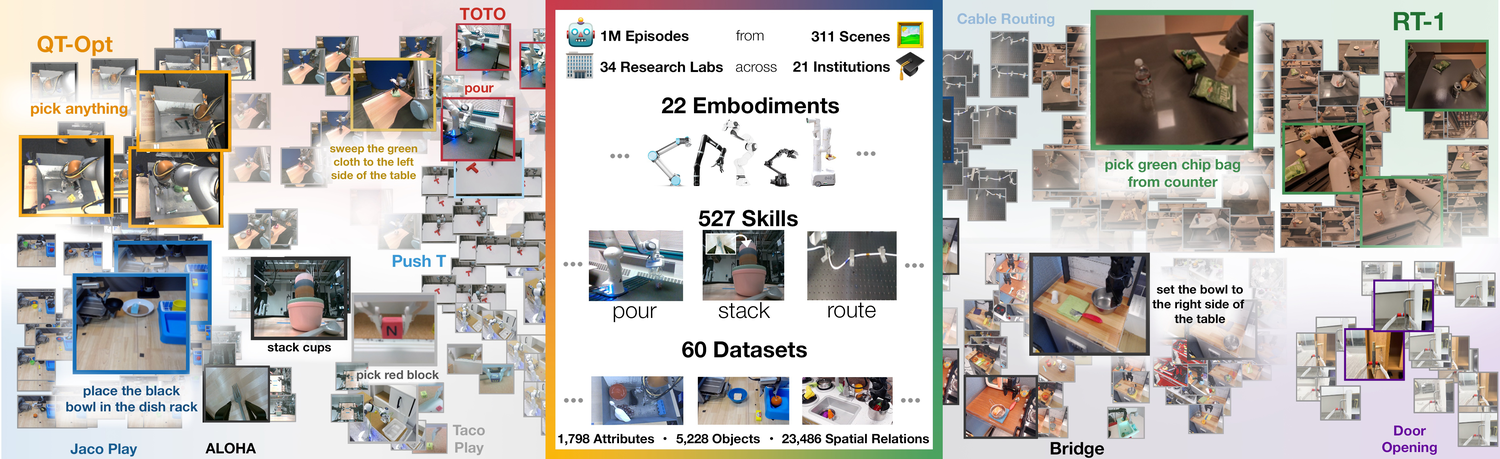
- 规模:1M+ 真实机器人轨迹;22 种本体(单臂、双臂、四足都有);由 60 个已有数据集、来自 34 个实验室汇聚而成;527 项技能,160266 tasks。
- 格式统一:采用 RLDS 格式(序列化 tfrecord),能容纳不同机器人各异的动作空间与输入模态(不同数量 RGB / 深度 / 点云相机),并支持各大深度学习框架的高效并行加载。统一格式 = "数据互通"的基建。
- 不弥合 gap:与大量前人(共享动作表征、表征学习、用本体信息做条件、解耦机器人/环境表征……)不同,本文直接在跨本体数据上训策略,不加任何专门缩小 embodiment gap 的机制,照样观察到正迁移。
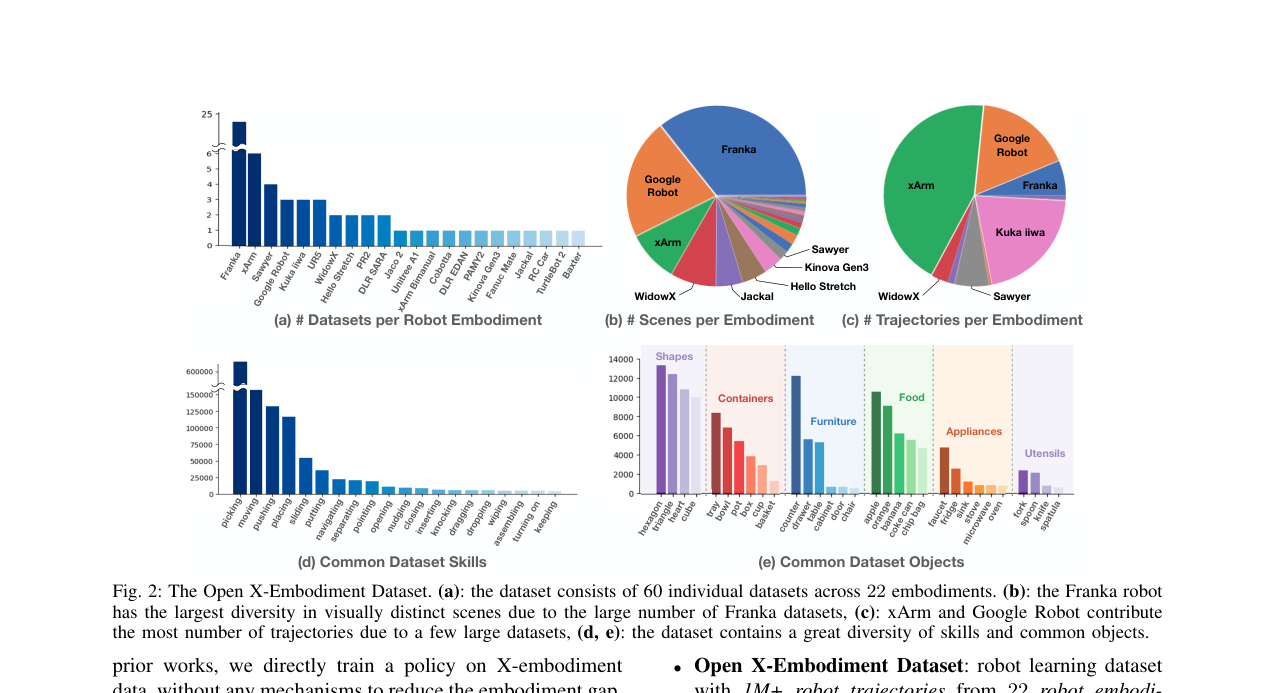
- (a) 各本体的数据集数:Franka 最多(贡献的数据集数量最大)。
- (b) 各本体的场景多样性:Franka 因数据集多,视觉上不同的场景也最多。
- (c) 各本体的轨迹数:xArm 与 Google Robot 因有几个大数据集,贡献的轨迹数最多。
- (d) 技能 / (e) 物体:用 PaLM 从语言标注里抽取动作与物体。绝大多数技能属于 pick-place 家族;长尾含 wiping、assembling 等;物体覆盖家电、食物、餐具等家居品。
- 本体名录(图2 出现):Franka、Google Robot、xArm、WidowX、Sawyer、Kuka iiwa、UR5、Hello Stretch、PR2、DLR SARA、Jaco 2、Unitree A1、xArm Bimanual、Cobotta、DLR EDAN、PAMY2、Kinova Gen3、Fanuc Mate、Jackal、RC Car、TurtleBot 2、Baxter(计 22 本体口径)。
3. RT-X 设计(图3)¶
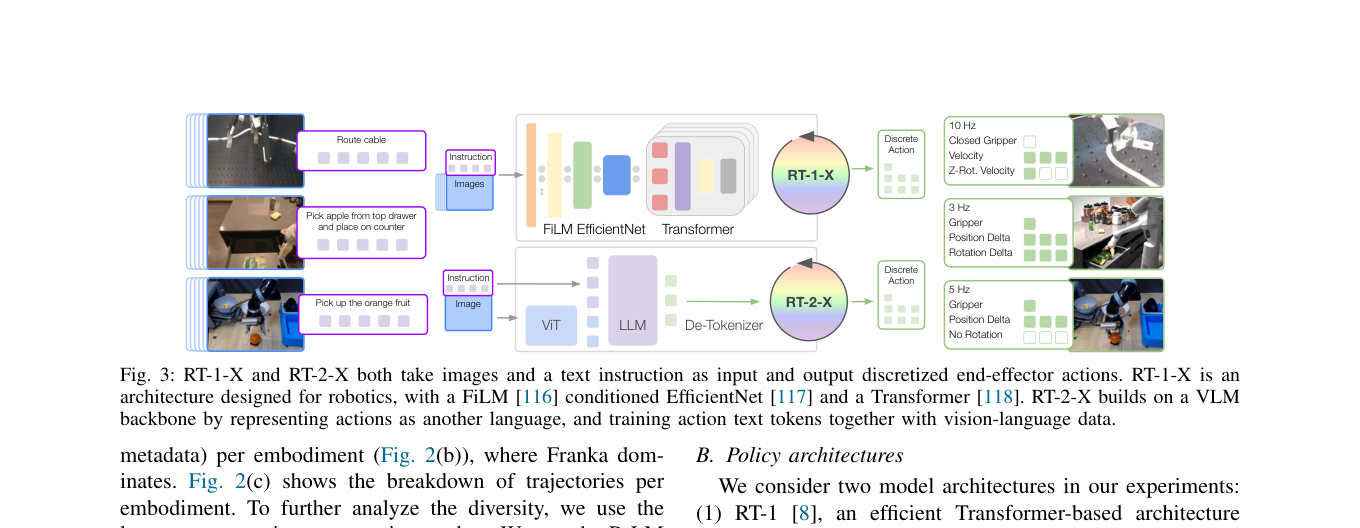
3.1 数据格式对齐(粗对齐)¶
- 观测:近期图像历史 + 语言指令;每个数据集选一个标准相机视角,缩放到统一分辨率。
- 动作:统一成 7 维末端执行器动作(x, y, z, roll, pitch, yaw, 夹爪开合,或这些量的速率)。各数据集动作先按本数据集归一化再离散化,输出按本体不同反归一化解释。
- 故意不对齐的部分:不统一各数据集的坐标系,动作值可为绝对/相对位置或速度(沿用各机器人原控制方案)。所以同一个动作向量在不同机器人上会产生很不同的运动;相机位姿/属性也仍差异很大。→ 这是"粗对齐"哲学:让模型自己从数据里学差异。
3.2 两个策略架构¶
- RT-1-X(卡片-RT-1 衍生):35M 参数 Transformer,专为机器人控制设计。输入 15 帧图像历史 + 语言;图像过 ImageNet 预训练 EfficientNet,语言转 USE 嵌入,二者经 FiLM 层交织出 81 个 vision-language token,喂 decoder-only Transformer 输出离散动作。本地推理,3–10 Hz。
- RT-2-X(卡片-RT-2 衍生):大型 VLA,把"动作"当成另一种语言文本 token(如
1 128 91 241 5 101 127),于是任意预训练 VLM 都能微调成机器人控制器,继承 VLM 的网络泛化。本文用 RT-2-PaLI-X 变体(视觉 ViT + 语言 UL2,主要在 WebLI 上预训练)。云端托管推理。 - 动作 token 化:每维离散成 256 个桶,共 8 维(1 维终止 episode + 7 维末端运动);两模型都用类别交叉熵目标。
3.3 训练口径(关键脚注)¶
- Robotics data mixture:实验统一用 9 种机械臂本体的数据(取自 RT-1、QT-Opt、Bridge、Task-Agnostic Robot Play、Jaco Play、Cable Routing、RoboTurk、NYU VINN、Austin VIOLA、Berkeley Autolab UR5、TOTO、Language Table 等数据集)。
- 9 ≠ 22:实验用 9 个本体,少于全数据集的 22 个——因为数据集是持续扩充的,做实验时这 9 个就是当时的全部数据。
- RT-1-X 只用 robotics mixture 训;RT-2-X 用 co-fine-tuning(约 1:1 混合原始 VLM 数据与 robotics mixture)。
4. 实验结果¶
总规模:3600 次评测试验,跨 6 种不同机器人。三问:(1) 正迁移?(2) 对未见任务的泛化?(3) 模型大小/架构/数据构成的影响?
4.1 同分布:小数据域(图4)—— RT-1-X 平均 +50%¶
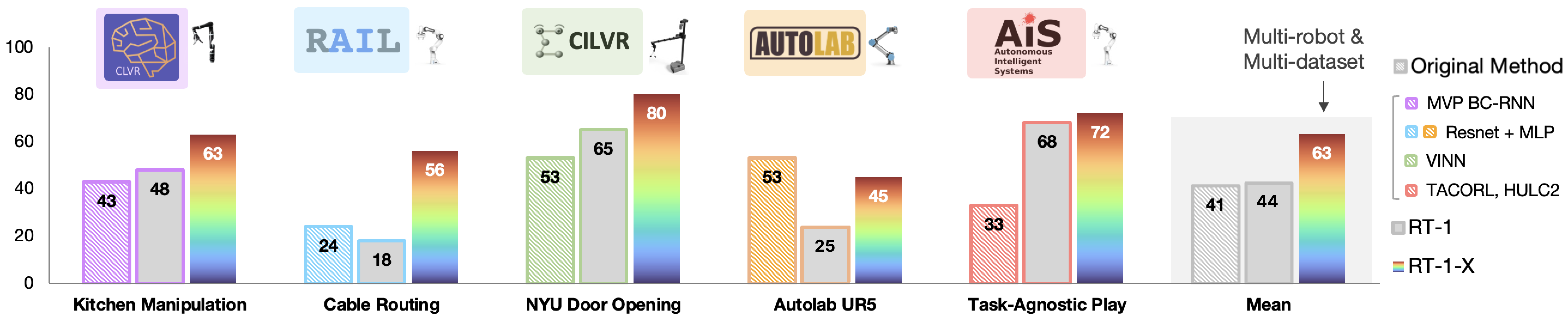
成功率(%),三条柱 = Original Method(各域作者的专用模型)/ RT-1(单域训练)/ RT-1-X(全 X 数据联训):
| 域(本体) | Original | RT-1 | RT-1-X |
|---|---|---|---|
| Kitchen Manipulation | 43 | 48 | 63 |
| Cable Routing | 24 | 18 | 56 |
| NYU Door Opening | 53 | 65 | 80 |
| Autolab UR5 | 53 | 25 | 45 |
| Task-Agnostic Play | 33 | 68 | 72 |
| Mean(均值) | 41 | 44 | 63 |
- RT-1-X 在 5 域中的 4 域超过各域专用 Original Method,均值 63 vs 41/44 ≈ 高约 50%。RT-1 与 RT-1-X 网络架构相同,故提升可归因于"在 X 数据上联训"。
- 唯一例外 Autolab UR5:RT-1-X(45) < Original(53)。诚实读数:不是每个域都赢。
4.2 同分布:大数据域(表I)—— RT-1-X 反而欠拟合,RT-2-X 才扳回¶
成功率(%):
| 评测设置 | Bridge @IRIS(Stanford) | Bridge @RAIL(UCB) | RT-1 paper 6 skills @Google |
|---|---|---|---|
| 本体 | WidowX | WidowX | Google Robot |
| Original Method (LCBC) | 13 | 13 | — |
| RT-1 | 40 | 30 | 92 |
| RT-1-X | 27 | 27 | 73 |
| RT-2-X (55B) | 50 | 30 | 91 |
- 关键结论:大数据域里 RT-1-X 打不过单域 RT-1(27<40、27<30、73<92)→ 该模型容量在大数据上欠拟合。
- 但高容量的 RT-2-X(55B) 同时超过 Original 与 RT-1 → 跨本体训练能在数据富集域增益,但前提是架构容量足够大。
4.3 跨分布泛化与消融(表II)—— RT-2-X 涌现技能 ~3׶
两列指标:Emergent Skills(来自别的机器人数据集、本体自身数据里没有的技能) 与 RT-2 Generalization(未见物体/背景/环境),单位 %:
| 行 | 模型 | 规模 | 历史 | 数据 | Web 预训练 | 初始化 | Emergent | Generalization |
|---|---|---|---|---|---|---|---|---|
| (1) | RT-2 | 55B | 无 | Google Robot action | 是 | Web 预训练 | 27.3 | 62 |
| (2) | RT-2-X | 55B | 无 | Robotics data | 是 | Web 预训练 | 75.8 | 61 |
| (3) | RT-2-X | 55B | 无 | Robotics data 去掉 Bridge | 是 | Web 预训练 | 42.8 | 54 |
| (4) | RT-2-X | 5B | 2 | Robotics data | 是 | Web 预训练 | 44.4 | 52 |
| (5) | RT-2-X | 5B | 无 | Robotics data | 是 | Web 预训练 | 14.5 | 30 |
| (6) | RT-2-X | 5B | 2 | Robotics data | 否 | 从零 | 0 | 1 |
| (7) | RT-2-X | 5B | 2 | Robotics data | 否(仅微调) | Web 预训练 | 48.7 | 47 |

读表(作者结论): - 跨本体涌现:RT-2-X(2) 比 RT-2(1) 在 Emergent 上 ~3×(75.8 vs 27.3)→ 把"别的机器人"的数据并进来,让一个本来就数据充足的机器人也学会了它自己数据里没有的技能。 - 是 Bridge 的功劳:去掉 Bridge 数据后(3),Emergent 从 75.8 掉到 42.8 → 跨 WidowX→Google Robot 的迁移确实来自 Bridge。 - 历史有用:(4) vs (5),加 2 帧历史 Emergent 44.4 vs 14.5、Gen 52 vs 30。 - Web 预训练是命门:(4) vs (6),无 Web、从零 → Emergent/Gen 几乎归零(0 / 1)。 - 容量越大迁移越强:(2) 55B vs (4) 5B,Emergent 75.8 vs 44.4。 - co-fine-tune ≈ fine-tune:(4) vs (7) 两指标接近——与原 RT-2 结论相反,作者归因于本文 robotics 数据比以往更多样。
5. 头条数字(一眼记住)¶
- RT-1-X:小数据域成功率比"各域 SOTA 专用方法 / 单域 RT-1"平均高约 50%(均值 63 vs 41/44)。
- RT-2-X:相对"只用本体自身数据训练"的模型,泛化/涌现提升约 3×(涌现技能 75.8% vs 27.3%)。
- 数据:22 本体 / 60 数据集 / 34 实验室 / 21 机构 / 527 技能 / 160266 tasks / 1M+ 轨迹。
- 评测:3600 trials / 6 机器人。
6. 诚实局限(作者自陈 + 读数)¶
- 不涉及差异极大的感知/驱动模态:实验都是带相机的机械臂操作,没有覆盖很不同的传感器/执行器形态。
- 不研究"泛化到全新机器人":测的是数据集内已有本体,未见本体(unseen embodiment)不在范围内。
- 没有给出"何时正迁移、何时不发生"的判据——Autolab UR5 就是反例(RT-1-X 反而更低),但论文未能预测。
- 容量决定成败:RT-1-X 在大数据域欠拟合,必须上 RT-2-X 级别容量才稳。
- 实验只用 9 本体(< 全集 22),结论是"当时数据"的快照。
- 粗对齐的代价:7-DoF 动作 + 不统一坐标系 → 同一动作向量在不同机器人上含义不同,靠模型硬学。
7. 核心洞见¶
- "并集 > 各自":单个机器人数据集都太窄,但统一格式后的并集能撑起正迁移——这是把"规模化预训练"范式搬进机器人的第一块地标。
- 不弥合 gap 也能迁移:不需要专门的 embodiment-bridging 机制,高容量模型 + 多本体数据自己就能吃下异构、产生跨机器人能力转移。
- VLM 骨干是放大器:RT-2-X 的 Web 预训练 + 大容量,是跨本体涌现与泛化的主要来源(消融里 Web、规模、历史缺一不可)。
- 基建价值 > 算法新意:论文最大产出是统一数据集 + 工具 + 开放 checkpoint,把跨本体研究的门槛拉低。
8. 对我们¶
- 数据互通基建:OXE 是"把分散机器人数据统一成标准格式"的范式样板,与 概念-机器人数据与标注 里"数据护城河 / 标准化"的主线直接对齐。
- 公开基座:数据 + RT-1-X checkpoint 公开,是后续 VLA / 跨本体工作的起点;本库的 卡片-DROID(亦为大规模采集数据集)、卡片-RT-2(RT-2-X 的骨干来源)与本文同生态,可互为上下游对照。
- 方法启示(公开方向):① "粗对齐 7-DoF 动作 + 不弥合 gap"是低成本接入异构数据的可借套路;② 跨本体涌现的前提是足够容量 + Web 预训练——对照本库 RT 系列(卡片-RT-1 / 卡片-RT-2)的版本叙事看,正是"容量 + 多样数据"两条腿。