详读 · RoboVLMs("造 VLA 到底什么重要"——600+ 实验消融指南)¶
卡片版见 卡片-RoboVLM。本页是全文精读:定位 → 三大问题 → 大规模消融结论(哪种 backbone / 结构 / 历史 / 动作空间更好) → 全量数字表 → 局限 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2412.14058 v4(2024-12 首发,2026-02-13 v4)· 已正式发表于 Nature Machine Intelligence (2026-02) · 项目页 · 代码 作者:Xinghang Li、Peiyan Li、Minghuan Liu、Hanbo Zhang(通讯)、Tao Kong(通讯)、Huaping Liu(通讯) 等 — 清华 + 字节跳动 Research + 上交 + 新国大 + 北京智源(BAAI)
0. 一句话定位¶
不是又一个新模型,而是一份实证指南:作者搭了一个统一框架 RoboVLMs,把任意 VLM「零成本」转成 VLA,然后用 8+ 种 VLM 主干 × 4 种策略结构 × 600+ 组实验,逐项回答"造 VLA 时到底什么重要"——which backbone / how to formulate / when to add cross-embodiment data。最终用结论拼出的最佳配置(KosMos-2 + 策略头 + 连续动作 + 历史)在 CALVIN / SimplerEnv / 真机三处都刷到 SOTA。
1. 动机:四类机器人策略,为什么选 VLA¶
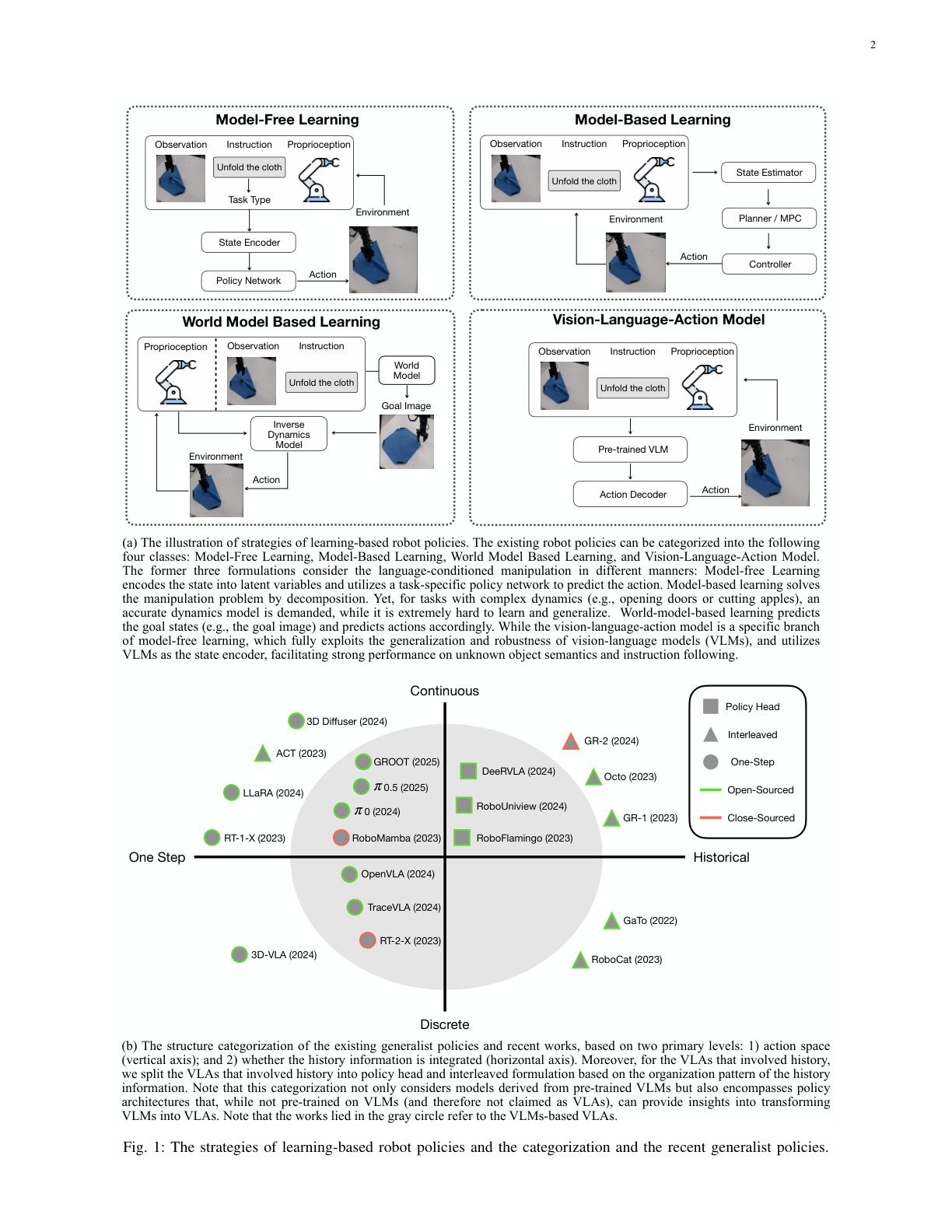 作者把已有策略分四类:① Model-Free(状态编码→策略网络出动作);② Model-Based(依赖显式机器人/环境模型,复杂动力学难泛化);③ World-Model-Based(预测目标图像→逆动力学出动作);④ VLA(Model-Free 的一个特化分支,用大规模预训练 VLM 当 state encoder,继承其语义泛化与鲁棒)。核心信念:VLA 能继承 VLM 在 web 级数据上学到的多模态表征,从而在机器人数据有限时也能适配开放世界——但"VL 预训练到底如何帮到机器人策略"此前没人系统验证过,这正是本文要填的坑。
作者把已有策略分四类:① Model-Free(状态编码→策略网络出动作);② Model-Based(依赖显式机器人/环境模型,复杂动力学难泛化);③ World-Model-Based(预测目标图像→逆动力学出动作);④ VLA(Model-Free 的一个特化分支,用大规模预训练 VLM 当 state encoder,继承其语义泛化与鲁棒)。核心信念:VLA 能继承 VLM 在 web 级数据上学到的多模态表征,从而在机器人数据有限时也能适配开放世界——但"VL 预训练到底如何帮到机器人策略"此前没人系统验证过,这正是本文要填的坑。
2. 两轴结构分类法 + 三大研究问题¶
 图1b 的两轴分类(全文骨架):
- 纵轴 = 动作空间:离散(Discrete,把动作分 bin 当 token 自回归)vs 连续(Continuous,MLP 直接回归浮点)。
- 横轴 = 历史信息:One-Step(只用当前观测)vs Historical(滑窗历史);历史又分两种聚合方式——Interleaved(交错):把历史观测/动作 token 交错塞进 VLM 主干里融合;Policy Head(策略头):VLM 每步只出单步表征,历史交给一个额外的策略头(RNN/Transformer/Diffusion)融合。
- 由此得四种代表结构:One-Step-Discrete(RT-2/OpenVLA)、One-Step-Continuous(π0/ACT)、Interleaved-Continuous(GR-1/Octo/GR-2)、Policy-Head-Continuous(RoboFlamingo/RoboUniview)。
图1b 的两轴分类(全文骨架):
- 纵轴 = 动作空间:离散(Discrete,把动作分 bin 当 token 自回归)vs 连续(Continuous,MLP 直接回归浮点)。
- 横轴 = 历史信息:One-Step(只用当前观测)vs Historical(滑窗历史);历史又分两种聚合方式——Interleaved(交错):把历史观测/动作 token 交错塞进 VLM 主干里融合;Policy Head(策略头):VLM 每步只出单步表征,历史交给一个额外的策略头(RNN/Transformer/Diffusion)融合。
- 由此得四种代表结构:One-Step-Discrete(RT-2/OpenVLA)、One-Step-Continuous(π0/ACT)、Interleaved-Continuous(GR-1/Octo/GR-2)、Policy-Head-Continuous(RoboFlamingo/RoboUniview)。
图2 三大问题(=本文三条主线):How 怎么建模(观测视界 / 动作空间 / 历史聚合)· Which 用哪个主干(VLM 结构 + VL 预训练数据量)· When 何时加额外数据(in-domain / cross-embodiment)。再细分成 6 个可执行研究问题(Q1.1 起,见 Extended Table 1)。
3. ⭐ 重点:大规模消融的核心结论¶
这是全篇的价值所在。下面每条都是作者用控制变量实验得出的"what matters"。
3.1 Which backbone:KosMos 与 PaliGemma 完胜——关键是"VL 预训练是否充分",不是参数量¶
8 个主干在 CALVIN(单侧视图、公平对齐)跑出的 Avg.Len.(满分 5):
| Backbone | 视觉 token 数 | VL 预训练数据量 | 模型大小 | Avg.Len. |
|---|---|---|---|---|
| Flamingo (enc-dec) | 64 | 1B+ | 3B | 1.57 |
| Flamingo | 64 | 1B+ | 4B | 1.71 |
| Flamingo | 64 | 1B+ | 9B | 1.83 |
| Qwen-VL | 256 | 350K | 9B | 0.30 |
| MoonDream | 576 | 未知 | 3B | 1.81 |
| Uform | 256 | 10M | 1.3B | 2.28 |
| KosMos | 64 | 90M | 2B | 3.59 |
| PaliGemma | 256 | 10B | 3B | 3.82 |
读数:KosMos 仅 2B / 64 token,却碾压 9B 的 Flamingo(3.59 vs 1.83)——说明决定性因素是充分的视觉-语言对齐预训练,而非堆参数或堆视觉 token。Qwen-VL/LLaVA 不加 perceiver resampler 降采样视觉 token 时表现异常崩坏(Qwen 0.30),作者归因于图像分辨率 / 视觉 token 数量。
Finding 2:VLA 受益于在更大 VL 数据集上充分预训练的 VLM 主干。
3.2 How formulate(结构):连续动作 > 离散;历史关键;策略头 > 交错¶
CALVIN ABCD→D 上,固定 chunk=10、只执行首步、≤5 epoch(核心结构消融表 = 原文 Table I):
| Backbone | 结构 | 动作空间 | 1 | 2 | 3 | 4 | 5 | Avg.Len. |
|---|---|---|---|---|---|---|---|---|
| LLaVA | One-Step | Disc. | 0.809 | 0.484 | 0.278 | 0.175 | 0.103 | 1.85 |
| LLaVA | One-Step | Cont. | 0.793 | 0.592 | 0.420 | 0.329 | 0.235 | 2.37 |
| LLaVA | Interleaved | Cont. | 0.892 | 0.645 | 0.436 | 0.282 | 0.181 | 2.44 |
| LLaVA | Policy-Head | Cont. | 0.873 | 0.678 | 0.506 | 0.376 | 0.275 | 2.71 |
| Flamingo | One-Step | Disc. | 0.681 | 0.318 | 0.133 | 0.062 | 0.029 | 1.22 |
| Flamingo | One-Step | Cont. | 0.681 | 0.354 | 0.158 | 0.076 | 0.035 | 1.30 |
| Flamingo | Policy-Head | Cont. | 0.964 | 0.896 | 0.824 | 0.740 | 0.662 | 4.09 |
| KosMos | One-Step | Disc. | 0.424 | 0.097 | 0.023 | 0.005 | 0.002 | 0.55 |
| KosMos | One-Step | Cont. | 0.935 | 0.868 | 0.814 | 0.768 | 0.702 | 4.09 |
| KosMos | Interleaved | Cont. | 0.987 | 0.915 | 0.824 | 0.737 | 0.660 | 4.12 |
| KosMos | Policy-Head | Cont. | 0.967 | 0.930 | 0.899 | 0.865 | 0.826 | 4.49 |
| PaliGemma | One-Step | Disc. | 0.316 | 0.096 | 0.021 | 0.005 | 0.001 | 0.44 |
| PaliGemma | One-Step | Cont. | 0.933 | 0.863 | 0.808 | 0.751 | 0.688 | 4.04 |
| PaliGemma | Interleaved | Cont. | 0.949 | 0.896 | 0.851 | 0.803 | 0.754 | 4.25 |
| PaliGemma | Policy-Head | Cont. | 0.984 | 0.933 | 0.888 | 0.835 | 0.779 | 4.42 |
三条结论(每条在 4 个主干上都成立): - 连续动作 > 离散动作:尤其长视界。离散把动作量化成 bin,长任务复合误差累积(KosMos 离散仅 0.55 vs 连续 4.09)。连续能表精确浮点。 - 历史观测关键:同主干下,带历史一律碾压 One-Step;历史越长越好(但算力涨)。 - 策略头 > 交错:交错把历史塞进 VLM 主干,破坏了 VLM 原生的 VL 融合格式,且训练/推理显存与 FLOP 显著更高;策略头保留 VLM 原始处理方式、另用小头融历史,又好又省。
Finding 3.1:最佳结构 = 多步历史观测输入 + 连续动作输出 + 策略头融合历史。
3.3 泛化 & 数据效率:策略头同样最优;大 VLM 更省数据¶
- 泛化(CALVIN ABC 训→D 测,零样本新场景):KosMos+策略头掉点最少,其余结构大幅下滑。
- 数据效率(Extended Table 4,缩放训练数据量,Avg.Len.):
| 结构 | 0.1x | 1x | 5x |
|---|---|---|---|
| Flamingo P.H. 3B | 0.13 | 4.09 | 4.21 |
| Flamingo P.H. 4B | 0.55 | 3.79 | — |
| Flamingo P.H. 9B | 0.83 | 3.97 | — |
| KosMos Inter. | 2.49 | 4.12 | 4.46 |
| KosMos P.H. | 2.52 | 4.49 | 4.51 |
在 10% 数据下 KosMos P.H. 仍达 2.52,远超 Flamingo 9B 的 0.83;且 Flamingo 同族里 9B>4B>3B(大模型更数据高效)。
Finding 3.2:策略头融合历史在泛化与数据效率上都最优。
3.4 训练目标 & 执行范式:Flow Matching ≈ MSE+BCE;执行整 chunk 最好¶
基于 PaliGemma 的 One-Step-Continuous(对齐 π 系列设定,原文 Table IIa,Avg.Len.):
| 训练目标 | 训练集 | 执行范式 | Avg.Len. |
|---|---|---|---|
| Flow Matching | ABC | Chunk | 3.68 |
| Flow Matching | ABC | First | 2.45 |
| Flow Matching | ABC | Ensemble | 3.14 |
| MSE+BCE | ABC | Chunk | 3.57 |
| MSE+BCE | ABC | First | 2.19 |
| MSE+BCE | ABC | Ensemble | 3.14 |
| Flow Matching | ABCD | Chunk | 4.09 |
| Flow Matching | ABCD | Ensemble | 4.12 |
| MSE+BCE | ABCD | Chunk | 4.04 |
| MSE+BCE | ABCD | First | 3.06 |
- 扩散损失(Flow Matching)只比 MSE+BCE 略好、差距不显著——短视界任务里确定性目标已够好,扩散的推理开销不划算。
- 执行整段 chunk(Chunk)最好,只执行首步(First)最差:First 丢了时间一致性,长任务尤其崩。Chunk 还能把推理频率拉到 >30Hz 实时。
Finding 3.3:One-Step-Continuous 下扩散损失与 MSE 损失相当;推理聚合关键是保持执行一致性。
3.5 MoE(动作专家):帮泛化、不帮已见场景¶
仿 π0 给每层 VLM 加一个动作专家 FFN(VL token 走原 FFN、动作 token 走专家 FFN,靠 self-attention 交互;原文 Table IIb):
| 训练目标 | 用 MoE | 训练集 | Avg.Len. |
|---|---|---|---|
| MSE+BCE | ✓ | ABC | 3.69 |
| MSE+BCE | ✗ | ABC | 3.57 |
| Flow Matching | ✓ | ABC | 3.84 |
| Flow Matching | ✗ | ABC | 3.68 |
| MSE+BCE | ✓ | ABCD | 3.46 |
| MSE+BCE | ✗ | ABCD | 4.04 |
| Flow Matching | ✓ | ABCD | 3.84 |
| Flow Matching | ✗ | ABCD | 4.10 |
- 零样本(ABC):MoE 一律涨点——MoE 保住了预训练 VL 表征不被动作监督污染 → 泛化更好。
- 已见场景(ABCD):MoE 反而掉点——熟悉场景下直接微调 VLA 让它"专化拟合"更划算。
Finding 3.4:MoE 提升泛化,但不能提升已见场景表现。
3.6 When cross-embodiment:预训练单独用处不大,"co-train→post-train"才有用;in-domain 数据最香¶
三种用法:Co-train(in-domain + 跨本体一锅训,RT-2/OpenVLA/Octo 路线)、Post-train(先 co-train 再用 in-domain 微调,π0 路线)、Finetune(只用 in-domain)。用 KosMos P.H. + OXE 跨本体数据。SimplerEnv 平均成功率(Extended Fig 4):
| 环境 | 配方 | 平均成功率 |
|---|---|---|
| WidowX+Bridge | Bridge Finetune | 0.44 |
| WidowX+Bridge | OXE Co-Train | 0.40 |
| WidowX+Bridge | Post-Train | 0.50 |
| Google Robot | RT-Partial Finetune | 0.30 |
| Google Robot | RT Finetune(同机器人额外 in-domain) | 0.68 |
| Google Robot | OXE Co-Train | 0.47 |
| Google Robot | Post-Train | 0.56 |
- 单纯 co-train 跨本体数据,提升不显著(Bridge 0.40 甚至略低于纯 Finetune 0.44)。
- Post-train 有潜力:Bridge 上 0.50 > 0.44;但 Google Robot 上只在高频的 pick-coke-can 涨、其余掉——因为 OXE 里 pick-and-place 占比极大,post-train 偏向高频技能、牺牲低频。
- in-domain 数据最关键:同机器人、哪怕任务无关的 in-domain 数据(RT Finetune 0.68)也比大规模跨本体数据有用得多。
- 跨本体预训练帮 few-shot(Extended Fig 5):CALVIN few-shot(每任务仅 10 条轨迹),OXE 预训练让单任务成功率 +17.2%、每 rollout 多完成 0.25 个任务(Avg.Len. 0.57 vs 0.32)。
Finding 4:额外 in-domain 数据(即便不同任务)有益;跨本体 co-train 再 post-train 能进一步提升高频任务与 few-shot 表现。
4. SOTA 对比 & 真机¶
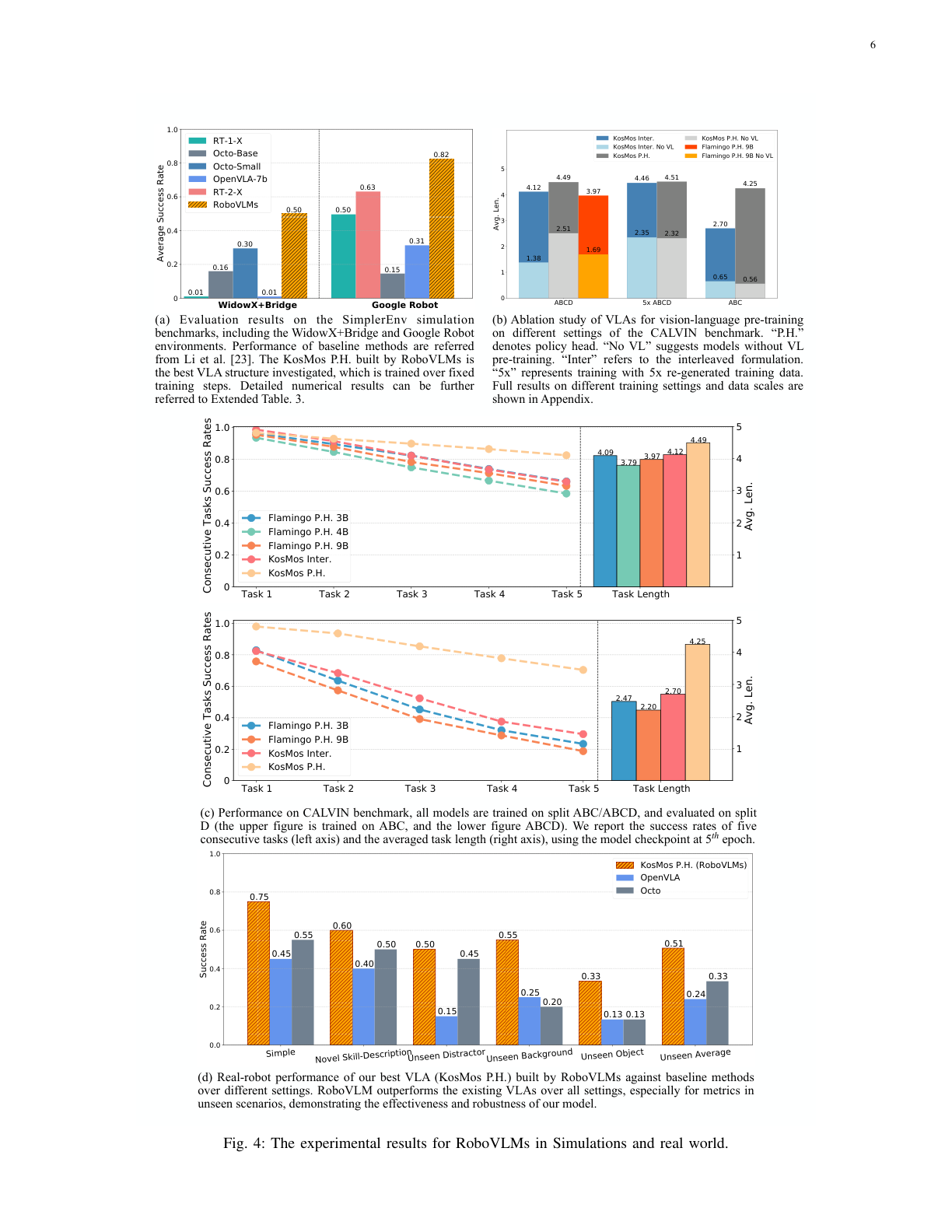
CALVIN(Extended Table 2,Avg.Len. 满分 5):
| 方法 | 训练集 | Avg.Len. |
|---|---|---|
| RT-1 | ABCD | 2.45 |
| HULC | ABCD | 3.06 |
| GR-1(前 SOTA) | ABCD | 4.21 |
| KosMos P.H. (RoboVLMs) | ABCD | 4.49 |
| GR-1 | ABC→D | 3.06 |
| KosMos P.H. (RoboVLMs) | ABC→D | 4.25 |
ABC→D 零样本新场景:比 GR-1 多完成 1.19 个任务(4.25 vs 3.06),单任务 +12.6%、连续 5 任务总成功率 +30.3%。
SimplerEnv(Extended Table 3,Google Robot 平均成功率):RoboVLMs 在 Pick Coke Can 0.970、Move Near 0.565 等普遍领先;OpenVLA-7b、Octo 大幅落后(如 Bridge 上 OpenVLA-7b 多任务 final≈0)。
VL 预训练的必要性(Supplementary Table 2,是否带 VL 预训练):
| 结构 | 无 VL 预训练 | 有 VL 预训练 |
|---|---|---|
| KosMos Inter. | 1.38 | 4.12 |
| KosMos P.H. | 2.51 | 4.49 |
| Flamingo P.H. 9B | 1.69 | 3.97 |
去掉 VL 预训练几乎腰斩——VL 预训练是泛化与数据效率的地基。
真机(Kinova Gen3 7-DoF + Robotiq 2F-85 夹爪 + 头/腕双相机,105 任务 / 74K 轨迹的字节真机基准;20 任务×5 设定×3 rollout):微调 Octo-Base / OpenVLA / KosMos P.H. 对比,KosMos P.H. 在全部 5 个设定(Simple + 4 个 Unseen:干扰物/背景/目标物/新技能描述)都最好,尤其 Simple 与 Unseen Background。还涌现自纠错能力(Open The Oven 第一次没够到把手→第二次自己重定位,训练集里无此类数据),基线无此能力。
5. 方法补充(RoboVLMs 框架机制)¶
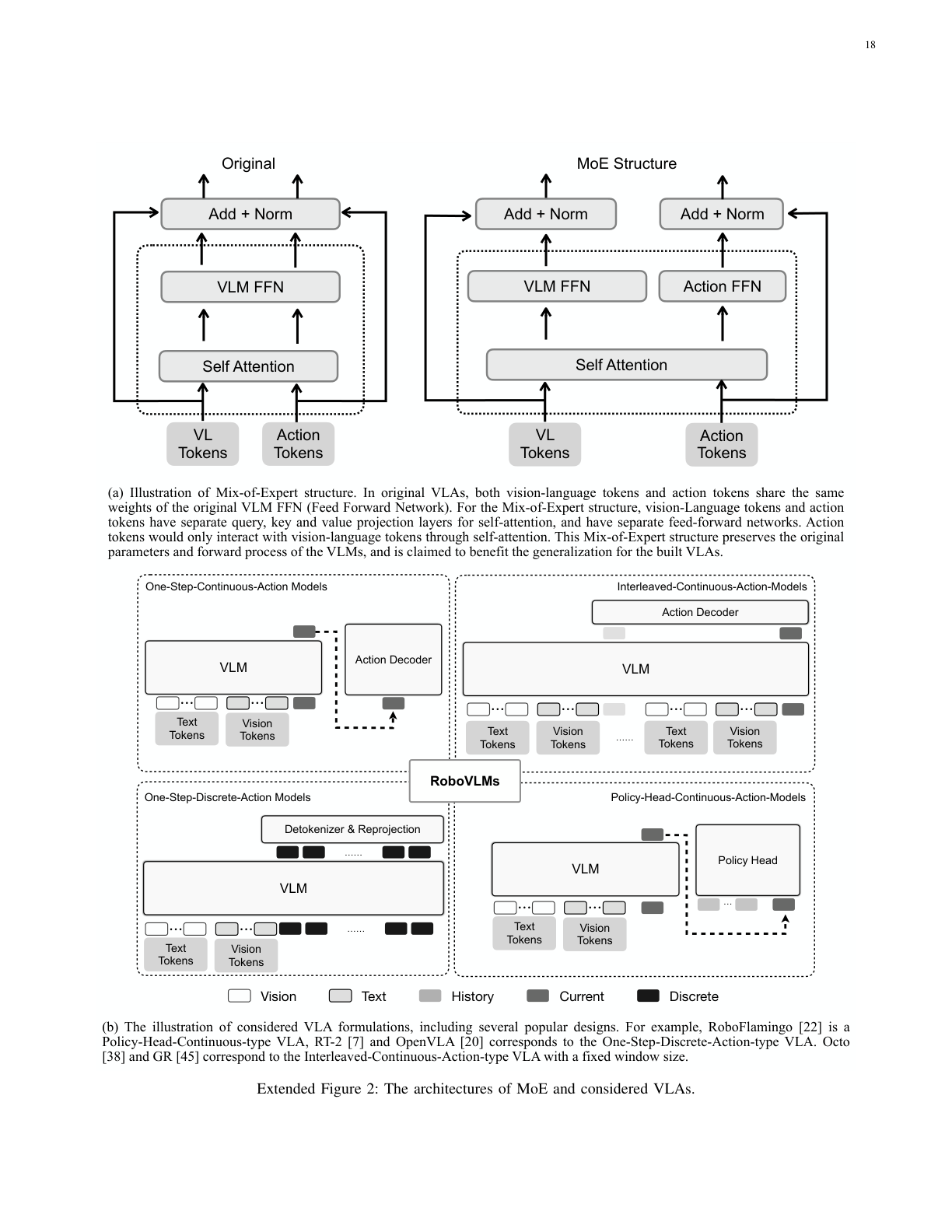 - 动作建模:7 维动作(6-DoF 末端位姿 + 夹爪开合)。归一化用训练集 1st/99th 分位裁剪再线性映到 [-1,1];离散化时每维分 256 bin,加 offset(默认10) 占用 tokenizer 尾部 token。
- 连续动作损失:前 6 维 MSE + 夹爪维 BCE(式7);离散动作损失:逐维 CE(式8,类文本下一 token 预测)。
- 四种结构的 token 组织(式9–15):One-Step 用 [LRN] token 经 MLP 出动作;Interleaved 把 [OBS]/[LRN] 交错成序列喂主干;Policy-Head 主干每步出 [LRN],再交给额外策略头 h(RNN/Transformer/Diffusion) 融历史出 chunk。交错结构只能配 decoder-only;策略头 enc-dec / decoder-only 都行。
- 训练配置:CALVIN 窗口 16 / chunk 10 / 侧+腕视图 / batch 128 / 5 epoch;真机窗口 8;全部在 4×8 张 A100-80G 上训。
- 动作建模:7 维动作(6-DoF 末端位姿 + 夹爪开合)。归一化用训练集 1st/99th 分位裁剪再线性映到 [-1,1];离散化时每维分 256 bin,加 offset(默认10) 占用 tokenizer 尾部 token。
- 连续动作损失:前 6 维 MSE + 夹爪维 BCE(式7);离散动作损失:逐维 CE(式8,类文本下一 token 预测)。
- 四种结构的 token 组织(式9–15):One-Step 用 [LRN] token 经 MLP 出动作;Interleaved 把 [OBS]/[LRN] 交错成序列喂主干;Policy-Head 主干每步出 [LRN],再交给额外策略头 h(RNN/Transformer/Diffusion) 融历史出 chunk。交错结构只能配 decoder-only;策略头 enc-dec / decoder-only 都行。
- 训练配置:CALVIN 窗口 16 / chunk 10 / 侧+腕视图 / batch 128 / 5 epoch;真机窗口 8;全部在 4×8 张 A100-80G 上训。
6. 局限 / 存疑(作者自陈 + 我补)¶
- 作者承认本工作仍属初步:① 动作 tokenization / 策略头 / 训练目标未充分探索(VQ-VAE、VQGAN、FAST tokenizer 都没试);② 考察的 VLM 主干集合有限,可继续扩;③ 这么大模型做实时机器人控制仍是挑战。
- 我补:评测重 CALVIN(桌面单臂、固定 34 技能),结论对双臂/移动/灵巧手/接触密集任务的迁移性未验证;动作只到 7 维末端,无力/触觉维度(与本库 卡片-Tactile-VLA / 卡片-VLA-Touch 路线正交)。
- "KosMos 最佳"部分受视觉 token 数=64这一实现细节影响(Qwen/LLaVA 需额外 resampler 才正常),结论里 backbone 与 token 预算两个变量未完全解耦。
7. 核心洞见¶
- "什么重要"的优先级:VL 预训练充分度 > 历史 + 连续动作 + 策略头结构 > in-domain 数据 ≫ 跨本体数据单独使用 ≈ 扩散损失 vs MSE 的选择。换言之,先选对充分预训练的 VLM、用对结构,比纠结扩散/MoE/跨本体这些"花活"重要得多。
- 反直觉点:① 大家追捧的离散动作 token(RT-2/OpenVLA 路线)在长视界明显劣于连续动作;② 大家堆的跨本体预训练单独用并不稳定涨点,要靠 post-train 才兑现;③ 扩散策略在短视界 VLA 上相对 MSE 没有显著优势。
- 工程价值:RoboVLMs 是一张"选 backbone / 动作头 / 历史融合 / 训练配方"的决策查表,能省掉大量盲试。
🗣️ 外部评价¶
- 🌐 正式发表于 Nature Machine Intelligence (2026-02),DOI s42256-025-01168-7 —— 经同行评审接收,是对其方法论与实证严谨性的强背书。题目从 v1 的"Towards Generalist Robot Policies: What Matters..."演进为终版"What Matters in Building Vision-Language-Action Models for Generalist Robots"。(来源:arXiv v1 / Nature MI)
- 🌐 社区文献综述(themoonlight.io 评论、HuggingFace Papers 页)以描述性概述为主,复述其核心结论(连续动作 + 策略头最优、KosMos/PaliGemma 领先),未见独立的方法学批评。
- ⚠️ 未找到 OpenReview 同行评审帖:本文走期刊(Nature MI)而非会议公开评审通道,故无 OpenReview 公开 review/rebuttal 可引;上述检索(OpenReview / review / critique)均未命中实质性第三方批评。如实记录,避免编造。
🤔 我的判断(🤖)¶
- 可信度高:结论建立在 600+ 受控实验 + 统一框架公平对比 + 开源(代码/权重/数据集 BDRBench20 全放出)+ Nature MI 同行评审,证据等级 A。这正是本库少有的"消融指南型"论文,价值在可迁移的工程决策而非单个 SOTA 数字。
- 最该带走的三句话:① 选 VLM 主干看"VL 预训练够不够充分"而非参数量(KosMos 2B 胜 Flamingo 9B);② 结构默认上「连续动作 + 历史 + 策略头」;③ 数据上优先攒 in-domain(哪怕任务无关、同机器人即可),跨本体数据靠"co-train→post-train"两段式才兑现、且偏向高频技能。
- 保留意见:结论强绑 CALVIN/SimplerEnv 桌面单臂 + 7 维末端动作,迁到双臂/灵巧手/力触觉任务需重测;"扩散无显著优势"只在短视界成立,长视界/高多模态轨迹未必。
🔗 对我们¶
- 决策查表:自建/选型 VLA 时,直接照搬其优先级——先挑充分 VL 预训练的 decoder-only 主干(KosMos-2 / PaliGemma 量级),上「连续动作 + 历史 + 策略头」,再考虑要不要 MoE(只为泛化)。
- 与 卡片-OpenVLA 的对照:OpenVLA 走的正是本文判定为劣的 One-Step-Discrete 路线(离散动作 token、单步),本文实验里 OpenVLA 在 SimplerEnv/真机均被 KosMos P.H. 明显超过——这条对照值得在我们评估离散 vs 连续动作头时引用。
- 概念锚点:本文的两轴分类(动作空间 × 历史聚合)+ 四种结构 + enc-dec/decoder-only 区分,是理解整个 VLA 家族的骨架,应并入 概念-模型架构基础 作为 VLA 结构分类的标准参照。
- 缺口提示:它完全不碰力/触觉,正好是本库 卡片-Tactile-VLA / 卡片-VLA-Touch / 详读-TacVLA 这一支的互补空间——"RoboVLMs 把视觉 VLA 的结构选型敲定了,触觉维度怎么并进这套最优结构"是可接的研究问题。