详读 · 3D-VLA(3D 生成式世界模型)¶
卡片版见 卡片-3D-VLA。本页是全文精读:动机 → 逐模块方法(3D 世界模型 + 多模态生成) → 实验全表 → 局限/洞见 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2403.09631(2024-03-14,ICML 2024)· 项目页 · 代码 作者:Haoyu Zhen、Xiaowen Qiu、Peihao Chen、Jincheng Yang、Xin Yan、Yilun Du、Yining Hong、Chuang Gan(UMass Amherst 主导 + 上海交大 / 华南理工 / 武大 / MIT / UCLA / MIT-IBM Watson AI Lab)
0. 一句话定位¶
在 3D-LLM 之上,加一套"交互 token(场景/物体/位置/动作)+ 具身扩散模型(RGBD↔RGBD、点云↔点云)",让模型先想象目标状态(生成目标图像 / 深度 / 点云),再据此规划动作 token。卖点不是"动作策略多强",而是把 3D 感知 → 推理 → 生成想象 → 动作串成一个生成式世界模型,并为此自造了 2M 条 3D-语言-动作数据。
1. 问题与动机¶
- 现有 VLA(RT-2、PaLM-E)只吃 2D 图像,缺 3D 物理世界理解;人类是在 3D 空间里推理、规划、行动的。
- 即便是能在 3D 里规划的具身模型,多数也只学"感知→动作的直接映射",没有世界模型——不建模世界动态、动作与动态的关系。人靠"想象未来状态"来规划,模型也该有。
- 两大拦路虎(作者自陈):① 现有基础模型只会生成语言,不会想象"语言以外的模态(图像/深度/点云)"来模拟未来;② 现有具身数据集多是 2D 图像/视频,缺 3D 标注。
- 3D-VLA 的切入:给 3D-LLM 加交互 token + 多模态目标生成能力,并自建带 3D 标注的大规模数据补上数据缺口。
2. 总览:生成式世界模型管线(图2)¶
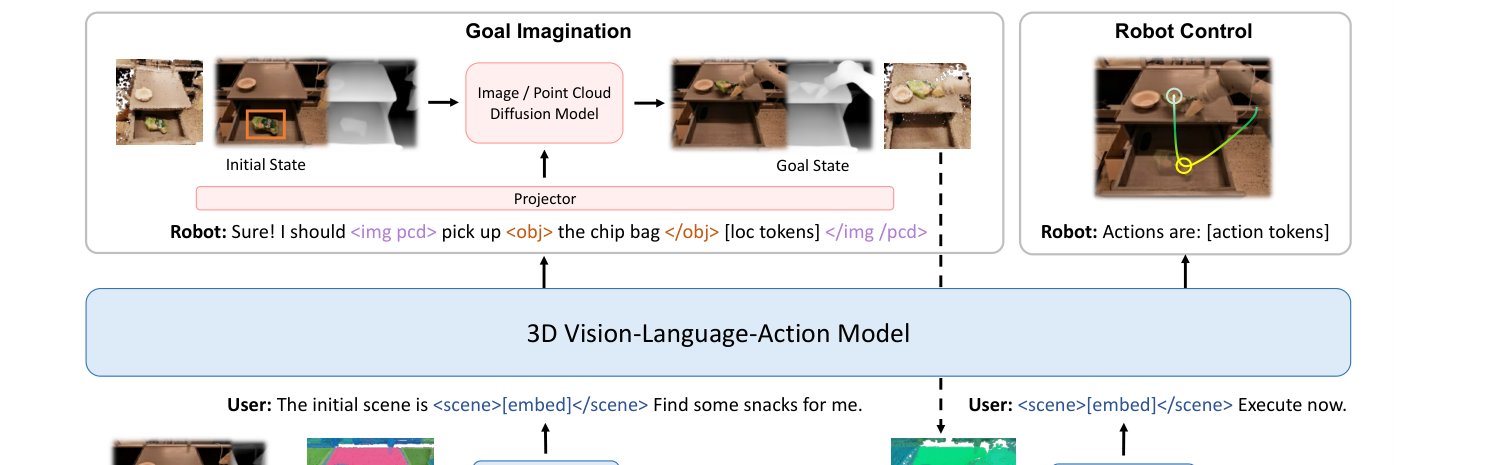 用户给"初始场景
用户给"初始场景 <scene>[embed]</scene> + 指令"→ 3D-VLA 先想象:经 Projector 调用 Image/Point-Cloud 扩散模型生成目标状态图像/点云(图中物体被高亮 <obj>/定位 [loc tokens])→ 把生成的目标喂回模型 → 输出 action tokens 做机器人控制。3D 场景特征由多视角图像经 Q-Former抽取(沿用 3D-LLM 思路,无需从零训 3D 编码器)。
3. 数据集:3D Embodied Instruction Tuning(贡献核心之一)¶
模型再好也要数据喂。作者设计了一条从现成具身数据集自动抽 3D-语言-动作三元组的流水线,得到 2M 条 3D-language-action 数据对(实际用 316k episodes)。

数据来源:
- 机器人数据:从 Open-X Embodiment 选 12 个数据集 + 带深度的 Dobb-E / RH20T + 仿真 RLBench / CALVIN。
- 人-物交互(HOI):Epic-Kitchens(无深度)、HOI4D(有 4D 标注)——给目标生成提供多样场景。
视觉标注流水线(关键工程):
- 超 95% 视频无 3D 信息 → 用 ZoeDepth 逐帧估深度;用 RAFT 估光流。
- 深度一致性技巧:相机不动的片段,用光流找"未动背景",跨帧把背景深度图按系数对齐 → 缓解单目深度的尺度漂移;再用内参/位姿把 RGB-D 抬升成点云。
- 3D bbox:spaCy 解析指令名词 → Grounded-SAM 出 2D mask → 抬升到点云得 3D bbox;被操作物体取"高光流区域内置信度最高"的 mask。
- 动作直接用数据集自带的 7-DoF 动作。
语言标注:用模板 + token(<image></image>、<pcd></pcd> 等)构造 prompt/answer,再用 ChatGPT(GPT-3.5-turbo-0125) + 2-3 个人写样例做多样化改写,覆盖 7 类任务(Verification / Task Caption / Embodied QA / Localization / Dense Caption / 图像或点云生成 / Action Prediction)。
4. 方法逐模块¶
4.1 Backbone(3D 理解)¶
- 沿用 3D-LLM 方法:多视角图像特征 → Q-Former → 3D 场景特征,可无缝塞进预训练 VLM。
- 但不加载 3D-LLM 预训练权重(3D-LLM 训在物体/室内场景,与具身设定不匹配),改用 BLIP2-FlanT5XL 当起点;训练时解冻 token 输入/输出嵌入 + Q-Former 权重。
4.2 交互 token(让 LLM 能"指物 / 定位 / 描述动态 / 出动作")¶
往词表加四类特殊 token:
- 物体
<obj> … </obj>:圈出被操作/被指物体。 - 位置
<loc0-255>:3D bbox 以 AABB 表示,用 6 个 token(min/max 角点)编码空间。 - 场景
<scene> … </scene>:包住一段静态场景嵌入;多个 scene token 组合 → 表达动态场景、支持 3D-文本交织输入。 - 动作:7-DoF 离散化 →
<aloc0-255>(臂绝对位置)、<arot0-255>(旋转)、<gripper0/1>(夹爪开合),动作间用<ACT_SEP>分隔。
4.3 注入目标生成能力(世界模型的"想象")¶
直接用现成视频扩散不行:作者发现让 Runway 按"open the drawer"生成未来帧会整场景畸变(视角变、物体形变、纹理乱、布局错);用 DreamLLM 冻结 internet 上训的 Stable Diffusion 会输出崩溃。故分两步:
- 预训练具身扩散模型(两条模态):
- RGBD→RGBD:以 Stable Diffusion V1.4 为底(在 VAE 隐空间做 latent diffusion),把 RGB latent 与 depth latent 拼接作图像条件;按指令把初始态编辑成目标态。
- 点云→点云:以 Point-E 为底,加点云条件输入。
- 对齐(Bridging):引入
<image></image>、<pcd></pcd>告诉解码器该出哪种模态;用一个 transformer Projector 把 LLM 输出特征/嵌入映射进各扩散模型的隐空间。用 LoRA 微调扩散模型避免灾难遗忘,只训新 token 嵌入、对应输出线性层、整个 Projector;同时最小化 LLM 损失 + 扩散去噪损失。
直觉:LLM 负责"理解指令 + 决定生成什么模态 + 出物体/位置 token",Projector 当翻译官把这份"意图"投到扩散模型听得懂的隐空间,扩散模型负责"画"出目标态。
5. 实验(全量数字)¶
训练规模:预训练 30 epoch / 6×32 V100(每节点 batch 4);对齐阶段 20 epoch / 6×64 V100(每节点 batch 2);AdamW,lr 从 1e-8 warmup 到 1e-5 再 cosine 衰减到 1e-6。
5.1 3D 推理与定位(held-in)¶
表1 推理(* = 零样本迁移、未在本数据集训练;下方 BLIP2 FlanT5XL 为在本数据训过的强基线):
| 任务 | 模型 | BLEU-4 | METEOR | ROUGE-L | EM@1 |
|---|---|---|---|---|---|
| Embodied QA | BLIP2 FlanT5XL(训) | 15.48 | 17.80 | 38.92 | 15.35 |
| 3D-VLA | 26.80 | 23.72 | 49.33 | 24.53 | |
| Task Caption | BLIP2 FlanT5XL(训) | 3.16 | 8.72 | 26.12 | 7.75 |
| 3D-VLA | 34.88 | 27.57 | 62.01 | 29.34 | |
| What-if QA | BLIP2 FlanT5XL(训) | 0.06 | 8.27 | 28.41 | 5.85 |
| 3D-VLA | 29.38 | 26.83 | 52.82 | 14.7 | |
| Dense Caption | BLIP2 FlanT5XL(训) | 13.96 | 17.83 | 40.56 | 13.10 |
| 3D-VLA | 34.62 | 25.25 | 55.91 | 39.49 |
表2 定位(held-in,2D MLLM 用 GT 深度投到 3D 比较):
| 模型 | IoU | Acc@25 | Acc@50 |
|---|---|---|---|
| Kosmos-2 (w/ GT Depth) | 10.92 | 12.73 | 3.85 |
| CoVLM (w/ GT Depth) | 19.81 | 25.39 | 16.61 |
| 3D-VLA | 29.33 | 42.26 | 27.09 |
读数:3D-VLA 在语言推理 4 类任务上全面碾压 2D VLM(含同数据训过的 BLIP2);定位 IoU 29.33 vs CoVLM 19.81。作者归因于"3D 信息 + 大量 3D 定位标注让模型聚焦关键物体"。注意 3D-LLM 在机器人推理任务上表现很差(零样本 BLEU 近 0)→ 印证"必须在机器人 3D 数据上训"。
5.2 多模态目标生成(Open-X 测试集,采样 4000 段未见 episode)¶
表3 RGB 目标图生成(* = 在本数据集训过):
| 模型 | PSNR↑ | CLIP Sim↑ | SSIM↑ | FID↓ |
|---|---|---|---|---|
| Instruct-P2P | 14.41 | 0.909 | 0.389 | 0.309 |
| SuSIE | 15.20 | 0.898 | 0.549 | 0.182 |
| NeXT-GPT | 8.86 | 0.199 | 0.153 | 0.432 |
| Instruct-P2P* | 16.67 | 0.941 | 0.628 | 0.178 |
| 3D-VLA w/o Pred BBox | 17.02 | 0.919 | 0.632 | 0.173 |
| 3D-VLA | 17.21 | 0.920 | 0.636 | 0.177 |
表4 点云目标生成:
| 模型 | P-FID↓ | Chamfer-L1↓ |
|---|---|---|
| Point-E* | 5.241 | 0.159 |
| 3D-VLA w/o Pred BBox | 4.914 | 0.143 |
| 3D-VLA | 4.796 | 0.139 |

读数:① 比零样本迁移的生成方法(前 3 行)明显好;② 即便对手 Instruct-P2P* 用了同样机器人数据,3D-VLA 仍多数指标更优(PSNR/SSIM/点云全项);③ 消融:去掉"预测的 bbox"输入(w/o Pred BBox)各指标小幅下降 → 中间 bbox 帮模型聚焦目标物体。注意 CLIP Sim 上 Instruct-P2P* 0.941 略高于 3D-VLA 0.920,FID 上 w/o BBox(0.173) 反而略优于全量(0.177)——并非每个细分指标都第一。
5.3 具身动作规划¶
表5 RLBench(成功率 %,pick-up-cup 的 var1 作未见任务测泛化):
| 模型 | Put Knife | Take Umbrella | Pick up Cup | Pick up Cup (unseen) |
|---|---|---|---|---|
| LanCon-Learn | 28.8 | 45.6 | 23.2 | - |
| LanCon-Learn w/ His. | 32.2 | 50.8 | 44.2 | - |
| 3D-VLA | 68 | 52 | 40 | 24 |
表6 CALVIN(长程多任务,连续完成第 N 个的成功率 %;训 A/B/C/D 测 D):
| 模型 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| MCIL | 28.2 | 2.5 | 0.3 | 0 | 0 |
| 3D-VLA | 44.7 | 16.3 | 8.1 | 1.6 | 0 |
读数:RLBench 上多数任务超基线(Put Knife 68 vs 32.2),还能做未见任务(24%);且作者强调自己是开环(open-loop)控制、基线却用了历史观测+物体状态。CALVIN 长程也优于 MCIL。诚实点:Pick up Cup(40) 低于 LanCon w/His(44.2);CALVIN 连续到第 5 个时两家都是 0,长程能力仍弱。
6. 局限 / 存疑(诚实)¶
- 开环控制:动作规划是 open-loop,无闭环反馈纠错 → 误差累积;CALVIN 第 5 连续步降到 0 印证长程脆弱。
- 动作是离散 token(绝对位置/旋转各 256 档)→ 精度受量化限制,不适合高精接触任务(对照 详读-DexTeleop-0 的力顺应连续控制)。
- 深度多为估计而非实测:>95% 数据靠 ZoeDepth 单目估深 + 光流对齐启发式 → "3D"质量上限受单目深度与尺度估计制约,可能并非真·度量 3D。
- 生成质量 = 规划质量的瓶颈:世界模型靠"想象目标"驱动规划,扩散生成不准则规划受损;目标生成只在采样测试集报指标,未见严格真机闭环验证。
- 真机验证薄弱:实验以仿真 / held-in 为主,Impact Statement 仅称"仿真训练 + 真机在人监督下部署",无真机成功率表;未与 RT-2 / OpenVLA 等强 2D VLA 在真机动作上对比。
- 算力门槛高:V100 集群(6×32 / 6×64),多阶段训练 + 多个扩散模型,复现成本大。
- 推理对比的基线偏弱(BLIP2/3D-LLM 系),未对比同期最强 3D 具身模型做动作。
7. 核心洞见¶
- 真正贡献是"把世界模型范式 + 配套 3D 数据"补进 VLA:交互 token 让一个 LLM 同时干"指物/定位/描述动态/出动作",Projector + 具身扩散让它跨模态想象未来——这是相对纯映射 VLA 的范式升级。
- 数据流水线本身价值很大:用 ZoeDepth + RAFT + Grounded-SAM + ChatGPT 把 2D 机器人数据"3D 化 + 指令多样化",是低成本造 3D 具身数据的可复用配方(对没有真 3D 传感数据的人很有用)。
- "先想象目标再规划"被消融证明有效(预测 bbox / 目标态都带来增益),印证世界模型方向;但当前实现的瓶颈在生成保真与开环控制。
🗣️ 外部评价¶
- 🌐 ICML 2024 录用,但 ICML 评审不公开(非 OpenReview 公开评审制),检索 OpenReview 仅得一份 PDF 镜像、无公开 reviewer 讨论。来源:OpenReview PDF 镜像、ICML 2024 接收(GitHub README 标注 "ICML 2024")。
- 🌐 现有第三方"评测"多为摘要型推介而非批判性同行评议:Moonlight 文献综述、Liner Quick Review 均以正面概述为主,未列弱点/失败案例(如实标注:促销性质,参考价值有限)。
- 🧑 如实说明:截至核实日(2026-06-29),未检索到公开的、具批判性的同行评审或社区深度 review;上方"局限/存疑"为本人据全文的判断,非引自外部评审。
🤔 我的判断(🤖)¶
- 它是"路线型"论文:价值在于第一个把"生成式世界模型 + 3D + 交互 token + 自建 3D 数据"拼成完整 VLA 框架,而不在于动作策略的 SOTA——动作部分(离散 token、开环、弱真机)明显是短板,别拿它当落地控制器。
- 最可借的是数据与表征工程,而非端到端权重:3D 化流水线、交互 token 设计、Projector 桥接扩散,这几块是可单独搬走的零件。
- 与同期 3D-VLA 路线对照:相比直接把 3D 点云塞进策略的 卡片-SpatialVLA,3D-VLA 多了"生成式想象"这层;相比 卡片-GR-2 的视频世界模型路线,它做的是多模态(图/深/点云)目标生成而非视频预测——三者可作"世界模型如何辅助 VLA"的三种代表实现对照。
- 存疑点:单目估深支撑的"3D"成色、开环规划的真机可用性,是这条路线能否落地的两个关键变量,需后续工作(或真机复现)回答。
8. 对我们¶
- 想做"世界模型预测后规划"或需要 3D 输入时的开源参考:代码 + 权重齐全(GitHub),可借其交互 token / Projector 桥接扩散 / 3D 数据流水线。
- 数据视角:其"2D 机器人数据 → 3D 标注"流水线(ZoeDepth + 光流深度对齐 + Grounded-SAM 3D bbox + ChatGPT 指令多样化)与本库"机器人数据与标注"主题直接相关,是廉价造 3D 具身数据的配方。
- 路线对照:与 卡片-SpatialVLA(3D 表征塞进策略)、卡片-GR-2(视频世界模型)构成"世界模型 × VLA"三角,长期对照看哪条路线在真机落地更稳。
- 互补:动作精度/接触控制不是它的强项 → 接触密集任务仍看 详读-DexTeleop-0 那类力顺应路线;3D-VLA 更适合"高层想象 + 规划"。