详读 · π0-FAST(FAST:VLA 的频域动作 tokenization)¶
卡片版见 卡片-π0-FAST。本页是全文精读:动机 → 方法(逐模块) → 实验(全表) → 局限/洞见 → 外评 → 对我们。 来源:arXiv 2501.09747(v1,2025-01-16)· 项目页 · HF tokenizer 作者:Karl Pertsch*、Kyle Stachowicz*、Brian Ichter、Danny Driess、Suraj Nair、Quan Vuong、Oier Mees、Chelsea Finn、Sergey Levine(Physical Intelligence + UC Berkeley + Stanford;* 为核心贡献者)
0. 一句话定位¶
把连续机器人动作块先做 DCT(离散余弦变换)压缩、量化、再 BPE 编码成少量"高信息量"离散 token——让自回归 VLA(下一 token 预测)第一次能学高频、灵巧动作。配合 卡片-π0 训成 π0-FAST:在 1 万小时机器人数据上追平扩散版 π0,但训练快 5 倍。FAST 不改底层 transformer,是个即插即用的 tokenizer。
1. 问题与动机:为什么"逐维逐帧分箱"会崩¶
- 自回归 VLA(RT-2 / OpenVLA 路线)把动作离散成 token 做 next-token 预测。主流 tokenizer 是朴素分箱:每一维、每一帧独立切成 N=256 个均匀 bin。
- 高频动作下这套完全失效:动作块
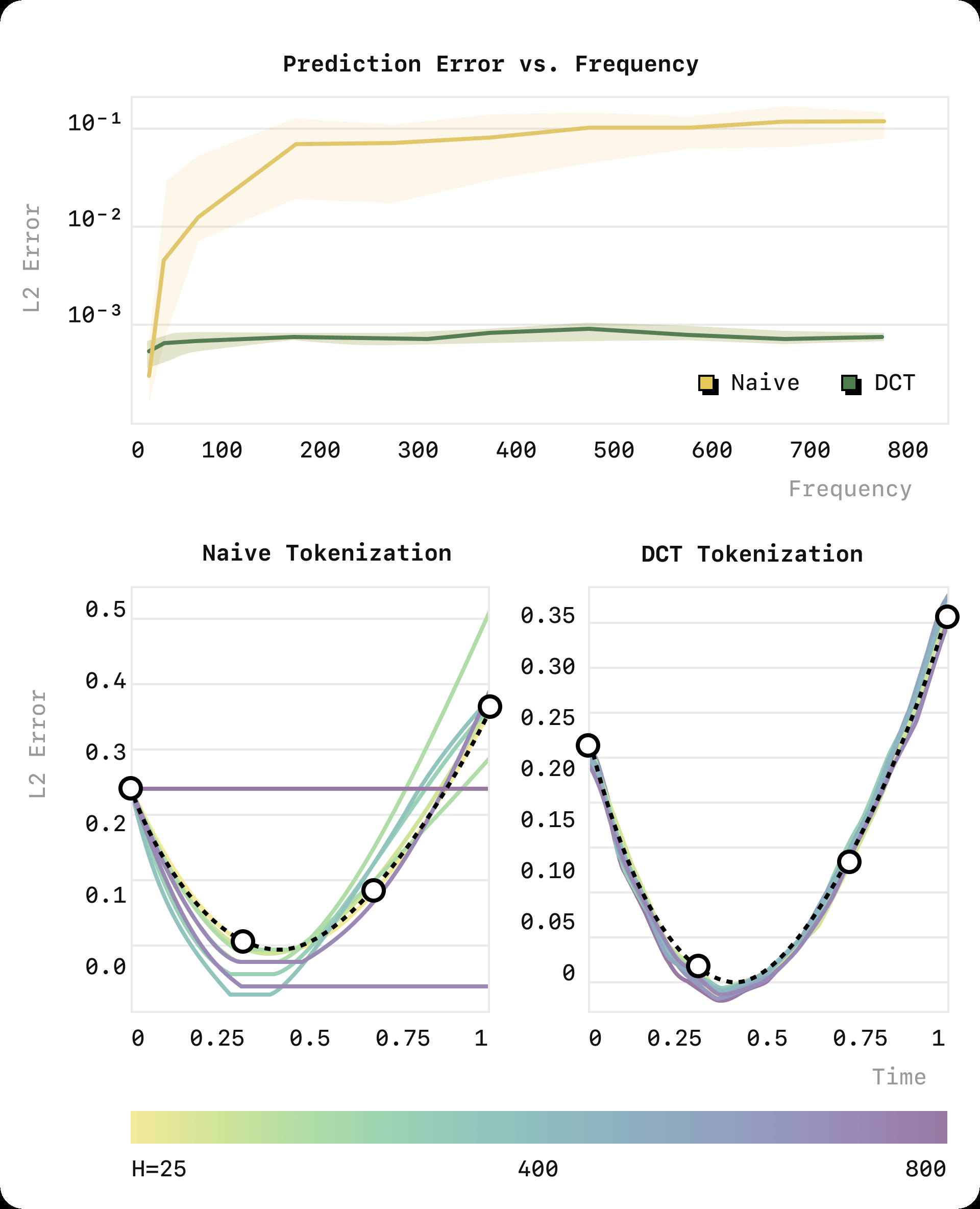
a_{1:H}逐帧 token 化会产生几百个 token/块,且相邻帧高度相关(频率越高,每帧变化越小)→ 每个 token 的边际信息趋近 0 → next-token 目标退化成"复制上一个 token",模型陷在差的局部最优。 - 这不是数据复杂度问题:作者用三次样条插值玩具实验(图3)证明——同一底层信号,仅提高采样率(25→800 帧),朴素分箱的预测 MSE 急剧上升直到"只会复制第一帧",而 DCT 方案在所有频率上 MSE 都很低。
- 现实佐证:OpenVLA 在低频 BridgeV2/RT-1 上行、在高频 DROID 上拟合困难。
2. 核心思想:动作要先"压缩"再 token 化¶
关键洞见——机器人动作信号在训练前必须压缩,以降低相邻 token 的相关性。类比语言模型用 BPE 压缩文本;但动作是连续的,所以用信号压缩的经典工具 DCT(JPEG 同款)。DCT 把信号表成不同频率余弦的和:低频抓整体形状,高频抓突变;平滑信号的能量集中在少数低频系数上,丢掉小系数即可压缩。作者强调:任何足够有效的压缩方法用在动作目标上都能提速 VLA 训练,DCT 只是简单、解析、快(相对学习式 VQ)。
3. FAST tokenization 算法(逐步)¶
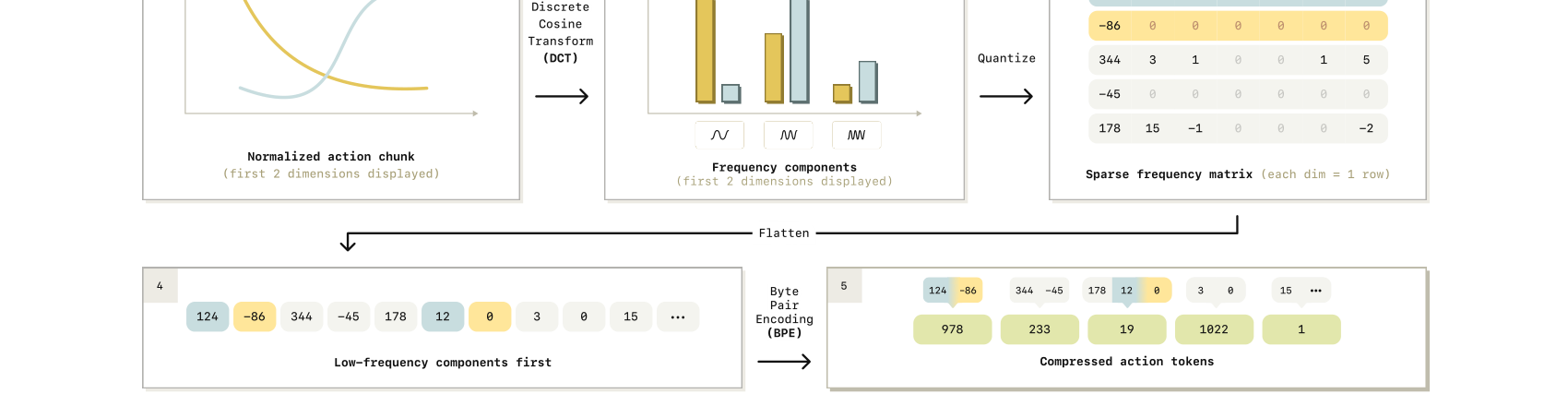
- 分位归一化:每维把训练集的 1% 与 99% 分位映射到
[-1, 1]。用分位数而非 min/max 抗离群点,也让跨本体(不同动作尺度)统一。 - 逐维 DCT:对每个动作维度独立做 DCT,时域 → 频域。
- 量化(scale-and-round):系数乘缩放因子 γ 后取整,丢掉不显著系数 → 得到稀疏频率矩阵(每维一行,多数为 0)。γ 是"有损率 ↔ 压缩率"的旋钮。
- 展平(列优先):把
|A|×H矩阵拉成一维整数向量,交错各维、低频分量在前。作者实测列优先(先预测决定整体形状的低频)比行优先rollout 更稳。 -
BPE 编码:对展平向量训一个 BPE,无损地"挤掉"成片的 0、合并高频共现组合 → 最终稠密动作 token。选 BPE 是因为实现成熟、输出定长词表可直接塞进 VLM 词表。
-
只有两个超参:DCT 取整前的缩放 γ、BPE 词表大小。都不敏感,单数据集实验全程用 γ=10、BPE 词表 1024。
- 全流程可逆,解码快。集成方式同前作:把动作 token 覆盖写进 VLM 里最少用的那些 token。
- FAST+(通用 tokenizer):BPE 词表是唯一需"学"的部分(每个新数据集要重训,虽只要几分钟)。于是作者在 ~100 万条 1 秒动作块(单臂/双臂/移动机器人,关节空间与末端执行器空间,各种控制频率)上训了个通用 tokenizer FAST+,可作黑盒直接套任意机器人,三行 HuggingFace
AutoProcessor代码即用。
4. 全量数字表¶
4.1 压缩率(表I,1 秒动作块)¶
每块 token 数,朴素分箱 vs FAST:
| 数据集 | 动作维 | 控制频率 | 朴素 token | FAST token | 压缩比 |
|---|---|---|---|---|---|
| BridgeV2 | 7 | 5 Hz | 35 | 20 | 1.75× |
| DROID | 7 | 15 Hz | 105 | 29 | 3.6× |
| Bussing | 7 | 20 Hz | 140 | 28 | 5.0× |
| Shirt Fold | 14 | 50 Hz | 700 | 53 | 13.2× |
关键现象:FAST 每块约 30 token/臂(双臂≈60),几乎与控制频率无关——说明它逼近了动作信号的内在复杂度。高频任务(叠衣 50Hz)压缩收益最大(13.2×)。FAST+ 在未见过的多样数据集上也能把 token 数普遍砍 2×。
4.2 训练/推理与规模数字¶
散落全文的关键量:
| 项 | 数值 |
|---|---|
| 主干 | π0 = PaliGemma-3B;OpenVLA = Prismatic-7B |
| 通用 tokenizer FAST+ 训练数据 | ~100 万条 1 秒真实动作轨迹(跨本体) |
| 泛化策略训练数据规模 | ~1 万小时;903M 自有时间步 + 9.1% 开源(BRIDGE v2/DROID/OXE) |
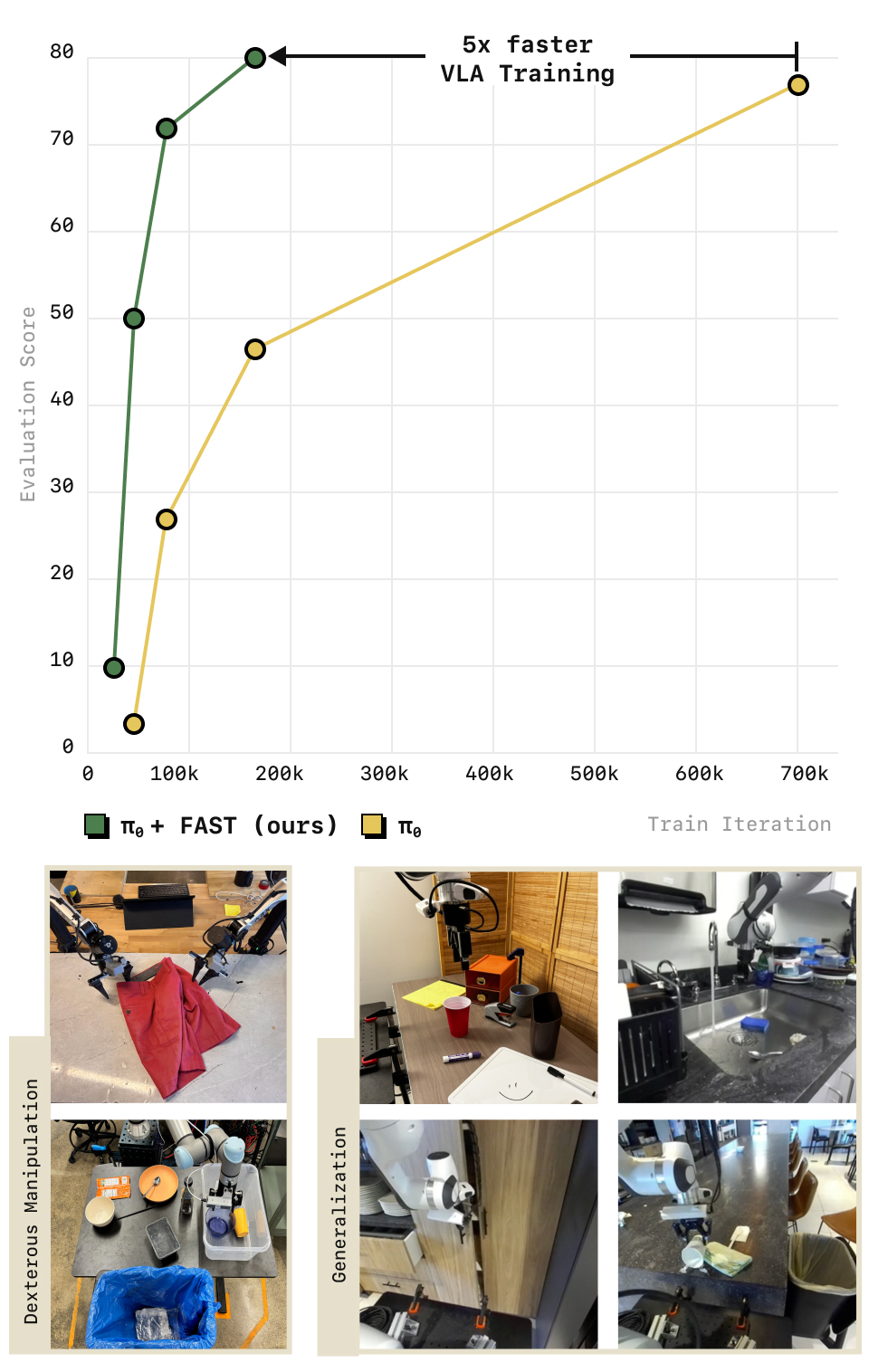
| 训练加速 | π0-FAST 比扩散 π0 快 5×(GPU 小时);Table Bussing 上少 3× 训练步达到同等性能 |
| 训练配置 | AdamW(b1=.9,b2=.95),1k 步线性 warmup 后恒定 LR 5e-5;3 epoch=240k 步@batch256;3B VLA 约 4 天 / 8×H100 |
| 推理速度(短板) | 扩散 π0 ≈ 100ms/块;π0-FAST ≈ 750ms/块(NVIDIA 4090) |
| 推理为何慢 | 需自回归解 30–60 个动作 token(vs 扩散 10 步);且用全 2B LM 解码(vs 扩散版 300M "action expert") |
| FAST 超参 | DCT 缩放 γ=10,BPE 词表 1024 |
| 评测任务 | 7 个:6 真机 + 1 仿真(Libero) |
4.3 主要实验结论(图6/9/11,多为柱状条无具体表)¶
- 图6(tokenizer 对比,Libero/Bussing20Hz/Shirt50Hz/DROID15Hz):朴素分箱在高频任务(Bussing、Shirt Fold)几乎零进展;压缩类(FAST、FSQ)显著有效;FAST ≥ FSQ(尤其灵巧高频任务),且 FAST 无需另训神经网络。FAST+ 通用版 ≈ 单数据集专用版。
- DROID 零样本:FAST 首次让 VLA 在 DROID 上训成可零样本跨环境泛化(三所大学校园不同桌面、背景、视角、新物体),仅用自然语言提示,无需 co-train/fine-tune——前作(含原 DROID、OpenVLA)都做不到。
- 图9(vs 扩散 π0,单任务):小数据集(Libero、Shirt Fold <50h)两者相当;大数据集(Bussing)FAST 收敛快 3×;DROID 上FAST 更听语言指令(扩散 π0 常忽略指令)。
- 图11(泛化通才策略,含叠衣等最难任务):π0-FAST 追平扩散 π0,但训练算力少得多(5× 更少 GPU 小时)。
- 消融:① 换主干到 OpenVLA,FAST 同样大幅提升高频叠衣性能 → 与主干无关;② 去掉 BPE:性能下降(但仍胜朴素分箱)——因为留下大量重复 0-token 稀释学习信号、且推理要解几百个 token 变慢。

5. 局限(作者诚实点 + 我补)¶
- 推理慢是硬伤:750ms/块,静态任务能忍,动态任务不行。作者把 LLM 加速术(投机解码、量化、定制 kernel)列为 future work。
- 仅在静态机械臂上测了策略;移动机器人/灵巧手/人形只做了 FAST+ 的离线压缩演示,没真跑策略。
- 是有损压缩,γ 调压缩率 ↔ 重建精度。
- BPE 仍需按数据集训(FAST+ 用通用版回避,但通用版在极端新本体上未必最优)。
- 自回归 vs 扩散"谁是更优 VLA 架构"作者明说尚无定论。
6. 核心洞见¶
- tokenization 是自回归 VLA 的命门:把"动作压缩"当成 tokenizer 设计的第一性原理,比加大模型/数据更直接地解决高频学习。
- 频域压缩 = 解相关:DCT 把"相邻帧高相关、低边际信息"的时域信号转成"少数高信息系数",恰好喂饱 next-token 目标。
- 简单打败复杂:解析的 DCT+BPE(2 个不敏感超参)胜过学习式 VQ/FSQ(需逐数据集调、训练麻烦)。
- 自回归的隐藏红利:比扩散 π0 更听语言(DROID 上更守指令)——暗示离散 token 路线在"语言落地"上可能有结构性优势。
7. 🗣️ 外部评价¶
- 🌐 被官方生态采纳:FAST tokenizer 以
physical-intelligence/fast在 HuggingFace 发布(AutoProcessor,1M 轨迹训练),π0-FAST 已并入 LeRobot 作为官方模型——工程落地度高。来源:HF 模型卡、LeRobot pi0fast 文档。 - 🧑 后续工作针对其短板改进:FASTer(OpenReview k6nTUFoqeT / arXiv 2512.04952)批评 FAST 的固定 DCT+BPE 与逐 token 解码慢,提出可学习神经 action tokenizer + 块状(block-wise)自回归解码 + 轻量 action expert 来提速;另有 BEAST(OpenReview rQCl1sf62w)用 B 样条编码作为 FAST 的替代路线。社区也有 uynitsuj/FASTer 用"DCT 早停"trick 给 π0-FAST 推理提速。
- 🧑 推理速度被反复诟病:RSS 2025 VLA 综述指出自回归 VLA(如 π0-FAST)实际控制频率约 1.3Hz,远低于扩散 π0 的 ~10Hz,动态任务吃亏。来源:Medium · RSS 2025 VLA Summary。
- 🌐 PI 自己的迭代承认 FAST 训练有痛点:后续 "Knowledge Insulation"(π0.5 KI)专门处理 FAST 离散 token 训练中的梯度干扰问题,让 VLA"训得快、跑得快、泛化更好"——侧面印证 FAST 一代在训练稳定性/推理速度上有改进空间。来源:PI · Knowledge Insulation。
检索说明:本文未走正式会议同行评审(arXiv 直发),故无 OpenReview 评审帖;上述为生态采纳情况 + 后续论文/社区对其方法的延续与批评。
8. 🤔 我的判断(🤖)¶
- 方法优雅、可信度高:第一性原理清晰(压缩→解相关→喂饱 next-token),证据链完整(玩具实验→压缩率表→多任务→规模化→消融),且开源 tokenizer + 进 LeRobot,复现门槛低。证据级 A。
- 真正价值不止"快 5×",而是让自回归路线在灵巧高频任务上第一次站得住——把"扩散 vs 自回归"从"扩散碾压"拉回到"各有所长"。语言落地更好这点对"指令泛化"很关键。
- 最大保留:推理 750ms/块的硬伤,使它当下更适合静态长程灵巧任务而非动态实时控制;后续 FASTer/KI 都在补这块,说明社区共识也是"方法对、工程未完"。
- 对路线选择的启示:tokenizer 是被长期低估的杠杆。任何要做自回归动作模型的团队,FAST+ 应作为默认基线而非自己造分箱。
9. 对我们¶
- 与 卡片-π0 / 卡片-π0.5 配套理解:π0=扩散/流匹配版,π0-FAST=自回归版,同团队同主干(PaliGemma-3B)。选型时这就是"扩散 head vs 离散 token"的同源 A/B 对照。
- 动作表示对照:与 卡片-OpenVLA-OFT 是同一议题(动作怎么表示喂给 VLA)。FAST 给出"频域压缩 token"这一新选项,可与连续回归 head、扩散 head、VQ 并列比较(见 概念-模型架构基础)。
- 可直接借用:FAST+ 是即插即用黑盒 tokenizer,若我们做自回归动作模型,不要再用朴素分箱。
- 关注后续:FASTer 的"可学习 tokenizer + 块状解码"与 PI 的 KI,是这条线的下一步,值得各建一张卡片对照。