详读 · OpenVLA-OFT(VLA 微调配方:同时优化速度与成功率)¶
卡片版见 卡片-OpenVLA-OFT。本页是全文精读:定位 → 动机 → 逐模块方法(公式直觉) → 全量数字表 → 诚实局限 → 核心洞见 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2502.19645v2(2025-04-28)· 项目页/代码 作者:Moo Jin Kim、Chelsea Finn、Percy Liang(斯坦福)
0. 一句话定位¶
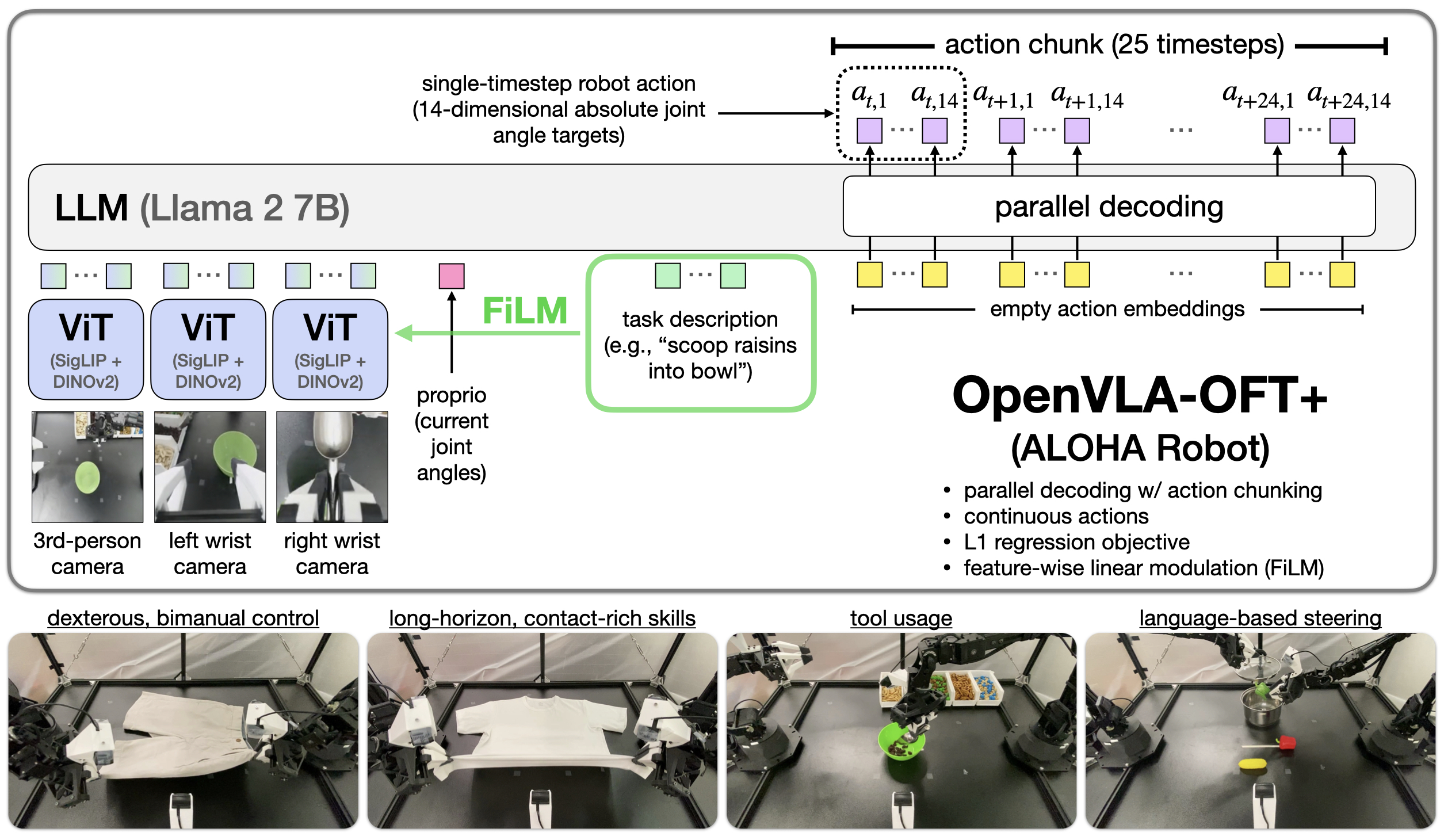
不是新底座、不是新架构——而是一篇"怎么微调 VLA"的实证配方论文(OFT = Optimized Fine-Tuning)。拿现成的 卡片-OpenVLA 当被试对象,系统对比三个设计轴(解码方式 / 动作表示 / 学习目标),得出一套组合:并行解码 + 动作分块 + 连续动作 + L1 回归(+ 可选 FiLM),把 OpenVLA 在 LIBERO 上从 76.5% 拉到 97.1%、动作生成吞吐提升 26×(单臂)到 43×(双臂 ALOHA),并能在 25Hz 双臂 ALOHA 上跑灵巧操作。
1. 问题与动机¶
- VLA 在新机器人/新任务上必须微调才好用,但"怎么微调最有效"几乎没人系统研究——大家默认沿用预训练那套配方(或 LoRA 变体),但这不一定最优。
- 原生 OpenVLA 的痛点:自回归逐 token 出动作 → 3–5Hz,远低于高频控制需要的 25–50+Hz;且自回归 VLA 在双臂任务上表现不可靠。
- 前人提速路线(更好的动作 tokenization:MiniVLA、卡片-π0-FAST)只拿到 2–13× 加速,且 FAST 仍有 ~750ms 块间延迟——自回归的迭代生成是根本瓶颈。
- 本文切入点:绕开自回归,用并行解码 + 连续动作,把"速度"和"质量"一起拿下,且不引入额外低层控制器、不做在线 RL,纯离线模仿学习一次训完。
2. 三个被研究的设计轴(图2)¶

| 设计轴 | 选项 A(原 OpenVLA) | 选项 B / C(本文探索) |
|---|---|---|
| 动作生成方式 | 自回归逐 token | 并行解码(双向注意力,单次前向) |
| 动作表示 | 离散(每维归一化到 [-1,1] 再分 256 桶) | 连续(MLP 动作头直出实数) |
| 学习目标 | 下一 token 预测(交叉熵) | L1 回归 / 条件去噪扩散 |
3. 方法详解(逐模块 + 直觉)¶
3.1 并行解码 + 动作分块(提速的核心)¶
- 自回归要
D次顺序前向(D=动作维度);分块到 K 步更要K·D次——在 A100 上单步动作就 0.33s,分块直接不可行。 - 并行解码:把输入换成空动作 embedding(仅靠位置编码区分),因果掩码换成双向注意力,一次前向把整块
K·D个动作全吐出来。吞吐近似 K 倍,延迟几乎不变。 - 直觉:动作块内部其实可以"互相看"(双向),不必假装它们是从左到右生成的语言。作者实测并行解码不仅没掉点,反而涨点(尤其 LIBERO-Long,因为分块缓解了复合误差 / compounding error)。
3.2 连续动作 + L1 回归(提精度的核心)¶
- 离散化 256 桶会丢精细动作细节、桶越多每桶样本越稀。连续表示用一个 4 层 ReLU MLP 动作头替换原输出层,直接回归归一化动作。
- L1 目标:
min E[ |a_pred − a_gt| ](最小化预测与真值的平均 L1 距离)。直觉:L1 鼓励学中位数模式,对演示噪声更稳。 - 对照扩散:另实现一个条件去噪扩散头(DDIM、50 步、平方余弦 β 调度)。结论是 L1 ≈ 扩散的成功率,但 L1 训练收敛更快、推理更省(扩散 50 步推理延迟高达 1.9s)。
3.3 多模态输入(灵活性)¶
- 原 OpenVLA 只吃 1 张第三人称图。OFT 支持多视角图像 + 本体状态:每张图过共享 SigLIP+DINOv2 编码器出 256 patch embedding,本体状态过 2 层 MLP 投到语言空间,全部沿序列维拼接后喂解码器。
- 加 wrist 相机使视觉 patch 从 256→512,但因并行解码省出的算力 headroom,吞吐仍 71.4Hz、延迟 0.112s。
3.4 FiLM 语言接地(仅 OFT+,ALOHA 用)¶
- 现象:ALOHA 多视角(尤其腕部相机)时,策略会抓视觉里的伪相关,不听语言指令。
- FiLM:把任务语言 embedding 平均后投影成缩放/平移向量 γ、β,对视觉特征做仿射调制
F̂ = (1+γ)⊙F + β(用 1+γ 是因初始 γ、β≈0,保留预训练激活)。 - 关键实现细节:γ、β 是 D_ViT 维(按隐藏单元、跨所有 patch 调制),而不是按每个 patch 独立调制——后者语言接地很差。在每个 ViT block 自注意力后、前馈前插入,每 block 独立投影器。
- 消融:去掉 FiLM,ALOHA 语言相关任务的语言跟随掉到 33%(=随机三选一)。
4. 全量数字(真有的数)¶
4.1 LIBERO 成功率(Table I,500 试/套,4 套均值)¶
表格里分了"输入条件"分组,注意别串行比较。
| 方法(输入条件) | Spatial | Object | Goal | Long | 平均 |
|---|---|---|---|---|---|
| Diffusion Policy(从零) | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo(微调) | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| DiT Policy(微调) | 84.2 | 96.3 | 85.4 | 63.8 | 82.4 |
| OpenVLA(原配方微调,基线) | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| OpenVLA + 并行解码&分块(PD&AC) | 91.3 | 92.7 | 90.5 | 86.5 | 90.2 |
| OpenVLA + PD&AC + 连续-扩散 | 96.9 | 98.1 | 95.5 | 91.1 | 95.4 |
| OpenVLA-OFT(PD&AC+连续-L1,仅第三人称图) | 96.2 | 98.3 | 96.2 | 90.7 | 95.3 |
| π0 + FAST(微调) | 96.4 | 96.8 | 88.6 | 60.2 | 85.5 |
| π0(微调) | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| OpenVLA-OFT(全量,+腕相机+本体) | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
读数要点: - PD&AC 单独就 +14%(76.5→90.2),主要靠 LIBERO-Long 暴涨 53.7→86.5(分块抗复合误差)。 - 连续动作再 +5%(90.2→95.3)。L1 与扩散打平(95.3 vs 95.4)。 - 加多模态输入到 97.1,超过 π0(94.2)——而 π0 底座预训练数据远大于 OpenVLA。
4.2 推理效率(Table II,7 维动作,A100,100 次均值)¶
| 配置 | 吞吐(Hz)↑ | 延迟(s)↓ | LIBERO-Long SR |
|---|---|---|---|
| OpenVLA(基线) | 4.2 | 0.2396 | 53.7 |
| + 并行解码(PD) | 15.9 | 0.0629 | – |
| + PD&AC | 108.8 | 0.0735 | 86.5 |
| + PD&AC + 连续-L1 | 109.7 | 0.0729 | 90.7 |
| + PD&AC + 连续-扩散(50步) | 4.2 | 1.9070 | 91.1 |
| + 连续-扩散(DDIM 2步) | 80.3 | 0.0996 | 85.7 |
| + 连续-扩散(DDIM 1步) | 109.4 | 0.0731 | 0.0 |
| OFT 全量(+腕相机+本体) | 71.4 | 0.1120 | 94.5 |
→ PD&AC 对 baseline 提速 26×。扩散步数砍到 1 步虽快但成功率崩到 0%——说明扩散的质量强依赖去噪步数。
4.3 ALOHA 真机任务完成度(图4,0–100 分制)¶

| 任务 | ACT | Diffusion Policy | RDT-1B | π0 | OpenVLA-OFT+ |
|---|---|---|---|---|---|
| 平均 | 72.3 | 77.5 | 78.4 | 83.9 | 87.8 |
| fold shorts | 100 | 100 | 100 | 100 | 100 |
| scoop X into bowl | 71.3 | 79.2 | 73.3 | 93.3 | 100 |
| put X into pot | 23.8 | 30.8 | 44.2 | 42.1 | 51.3 |
4.4 ALOHA 语言跟随(图5)+ FiLM 消融¶
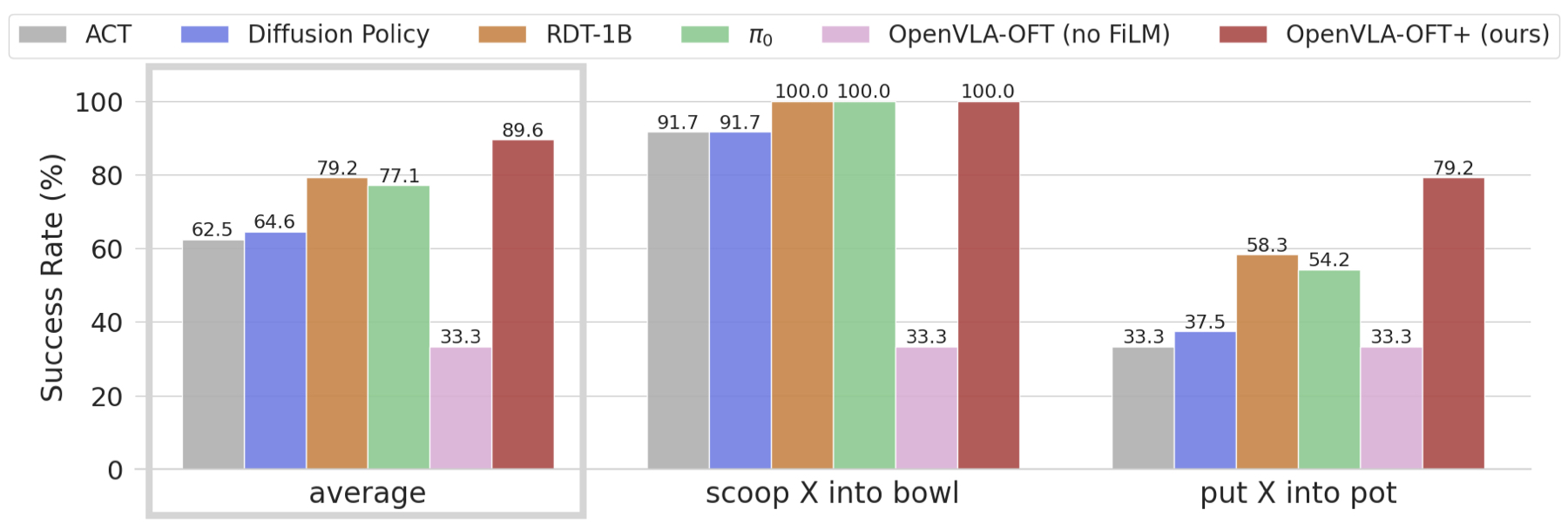
| ACT | DP | RDT-1B | π0 | OFT(无 FiLM) | OFT+ | |
|---|---|---|---|---|---|---|
| 平均语言跟随 | 62.5 | 64.6 | 79.2 | 77.1 | 33.3 | 89.6 |
| scoop(选对容器) | 91.7 | 91.7 | 100 | 100 | 33.3 | 100 |
| put(接近对的物体) | 33.3 | 37.5 | 58.3 | 54.2 | 33.3 | 79.2 |
4.5 ALOHA 推理效率(Table III,3 图+14 维状态,K=25)¶
| 方法 | 参数量 | 吞吐(Hz)↑ | 延迟(s)↓ |
|---|---|---|---|
| OpenVLA(仅加腕相机) | 7.5B | 1.8 | 0.543 |
| OpenVLA-OFT+ | 7.5B | 77.9 | 0.321 |
| RDT-1B | 1.2B | 84.1 | 0.297 |
| Diffusion Policy | 157M | 267.4 | 0.090 |
| π0(JAX) | 3.3B | 291.6 | 0.086 |
| ACT | 84M | 432.8 | 0.058 |
→ OFT+ 比 base OpenVLA 吞吐 43×(77.9/1.8)。注意它不是最快——参数最大(7.5B),ACT/π0/DP 因模型小或 JAX 实现更快;但 OFT+ 单次前向就追平了 7× 小的 RDT-1B。
4.6 其它实验(附录)¶
- 去掉 OpenVLA 机器人预训练表示 → LIBERO 均值 97.1→91.9(-5.2%):预训练表示仍有用。
- 单一策略训全 4 套 LIBERO → 96.8(≈各套独立训),证明可扩到更大微调集。
- BridgeData V2(50,365 真机演示) → OFT 69.2 vs 公开 OpenVLA 65.8,且无需 FiLM 也能听语言。
- 可训练参数:LIBERO 配置 279M(111M LoRA + 151M 动作头 + 17M 本体投影);ALOHA OFT+ 853M(多了 456M FiLM 投影器)。LoRA rank=32。
5. 诚实局限(作者自陈 + 我补)¶
- L1 是单峰:作者承认 L1 学中位数模式,难建模真多峰动作分布(同一观测有多个有效动作时);扩散更能建多峰但可能过拟合次优模式。
- 预训练 vs 微调:本文只研究微调,OFT 是否能用于大规模预训练、还是预训练必须更表达力强的扩散/流匹配——未知。
- 语言接地不一致:LIBERO 不用 FiLM 也行,ALOHA 不加 FiLM 就崩——根因(缺双臂预训练数据?)作者也说不清。
- (我补)测的基本是分布内任务:LIBERO + 各任务都用 500/几十条同分布演示微调后评测,OOD/泛化几乎没正面测(见下文外部评价)。
6. 核心洞见¶
- 解码方式 > 大家以为的:把自回归换成并行解码 + 分块,不只是提速,还实打实涨成功率(抗复合误差)。
- L1 ≈ 扩散:在 OpenVLA 这种高容量底座上,简单 L1 回归就能逼平扩散,训练/推理却快得多——"算法简单"本身是工程价值。
- 微调配方可能比预训练数据覆盖更关键:OpenVLA 预训练只见过单臂,靠 OFT 微调就在双臂 ALOHA 上压过预训练见过双臂的 π0/RDT-1B。
🗣️ 外部评价(同行评议/社区)¶
- 🌐 themoonlight.io 自动文献综述(链接):肯定其"实用增益 + 系统性消融 + 真机验证",但批评原文缺少对失败案例、算力开销、基准外泛化的批判性分析——"强调实用收益,缺对约束/失效场景的剖析"。
- 🧑 后续工作的反向批评(robustness/OOD):多篇 2025–2026 论文把 OpenVLA-OFT 当强基线后指出它的泛化软肋——SOTA VLA(含 OFT)在标准 LIBERO 各套 ~95%,但在 libero-ood 类分布外基准上 <21%;存在空间过拟合(把物体名字和它在演示里的位置绑定,换位置就抓错)。代表:LIBERO-Plus 鲁棒性分析、"When Vision Overrides Language" 反事实失败。长程任务(LIBERO-Long 90.7)也因模仿学习的误差累积明显低于短任务。
- 🧑 被广泛当可复现强基线引用(BitVLA 量化、各种 VLA 加速/剪枝工作均以 OFT 为对照),代码+权重开放,复现性口碑好。
- ⚠️ 未找到该论文专属的 OpenReview 同行评议串(标准 arXiv 公开,未检索到带评分/评审意见的 OpenReview forum 页);alphaXiv 有该论文页但抓取被 403 拦截,未能读到具体讨论。除上述自动综述+后续论文批评外,未见知名独立博客/新闻对其做显著正负评价。
🤔 我的判断(🤖)¶
- 方法扎不扎实:扎实。它的价值在受控消融(一个轴一个轴拆开比),结论可信、可操作、代码开放——这是教科书式的"recipe 论文"。并行解码+分块抗复合误差、L1≈扩散这两条是真有用的工程结论。
- 哪被高估:① "新 SOTA 97.1%" 的修辞被 LIBERO 的天花板效应放大——LIBERO 本身是易过拟合的仿真基准,>95% 区间已经饱和,真正硬通货是速度(26–43×)和 L1≈扩散,不是那 1–2 个点。② "微调配方 > 预训练数据覆盖"这条结论很大胆但要谨慎读:超过 π0/RDT 是在微调后的分布内任务上,换成 OOD(libero-ood、Bridge 仅 69.2)就现原形。③ "并行解码无损"是在这些任务上成立,多峰/高随机任务上 L1 单峰是真短板(作者自己也承认)。
- 与领域/我们方向的关系:这是把 卡片-OpenVLA 类底座真正做到实时的最直接配方。如果我们要部署 OpenVLA 级模型上真机,OFT 几乎是默认起点(并行解码+分块+连续 L1 头是低成本高回报的改造)。与 卡片-π0-FAST 正好是两条提速路线的对照:FAST 在"自回归 + 更聪明的 token 压缩"里打转,OFT 直接跳出自回归——本文实测后者吞吐和延迟都更好。
- 对接触密集/多峰需求(参考 详读-DexTeleop-0 那类力顺应、多解操作),OFT 的 L1 单峰头要打问号,那种场景可能仍需扩散/流匹配动作头——这正是作者列的未解问题。
对我们¶
- 可直接借:✅ 并行解码 + 动作分块(最高性价比改造);✅ 连续 L1 动作头(比扩散省事、效果相当);✅ FiLM 语言接地(多视角易抓伪相关时);✅ 开源代码 + 权重。
- 关联:卡片-OpenVLA-OFT(卡片版)· 卡片-OpenVLA(底座)· 卡片-π0-FAST(动作表示/提速对照)· 概念-模型架构基础
- 存疑留待:OOD 泛化、多峰动作、能否用于预训练——这三条是它没解决、也是我们若深用要补的坑。