详读 · WorldVLA(自回归动作世界模型)¶
卡片版见 卡片-WorldVLA。本页是全文精读:定位 → 动机 → 逐模块方法(动作模型与世界模型融为一体的统一自回归)→ 全量数字表 → 局限 → 洞见 → 外部评价 → 审稿人视角 → 对我们。 来源:arXiv 2506.21539(2025-06-26)· 代码 作者:Jun Cen、Chaohui Yu、Hangjie Yuan、Yuming Jiang、Siteng Huang、Jiayan Guo、Xin Li、Yibing Song、Hao Luo、Fan Wang、Deli Zhao、Hao Chen(阿里巴巴达摩院 + 湖畔实验室 + 浙江大学)
0. 一句话定位¶
把 VLA(动作模型)和世界模型塞进同一个离散自回归 LLM:图像、文本、动作三种模态共用一套词表,模型既能"看图+指令→出动作"(policy),又能"看图+动作→出下一帧"(world model)。两边混合训练互相增强——世界模型逼模型学环境物理使动作更准,动作模型逼模型更懂画面使预测更真。外加一个动作注意力掩码,治自回归连发多动作时的误差累积。
1. 问题与动机¶
- VLA 的盲点:动作只被当成"输出",从不作为"输入"喂回去深挖——模型对动作本身缺乏理解,不知道一个动作会把世界推向什么状态。
- 世界模型的盲点:能据"当前观测+动作"预测未来帧(双重理解视觉与行为动态),但不能直接吐动作,无法独立做策略规划。
- 切入点:两者恰好互补。把它们统一进一个框架,让"预测未来帧"这件事顺便把环境物理学进动作模型;让"生成动作"这件事顺便把画面理解喂进世界模型。
- 附带难题:动作分块(action chunking)一次出多步对效率很关键,但作者发现纯自回归连发动作会掉点——因为预训练 MLLM 只见过图文、没见过动作,动作泛化弱,早期错误会沿自回归链传染给后续动作。
2. 三类模型的统一视角(图1)¶
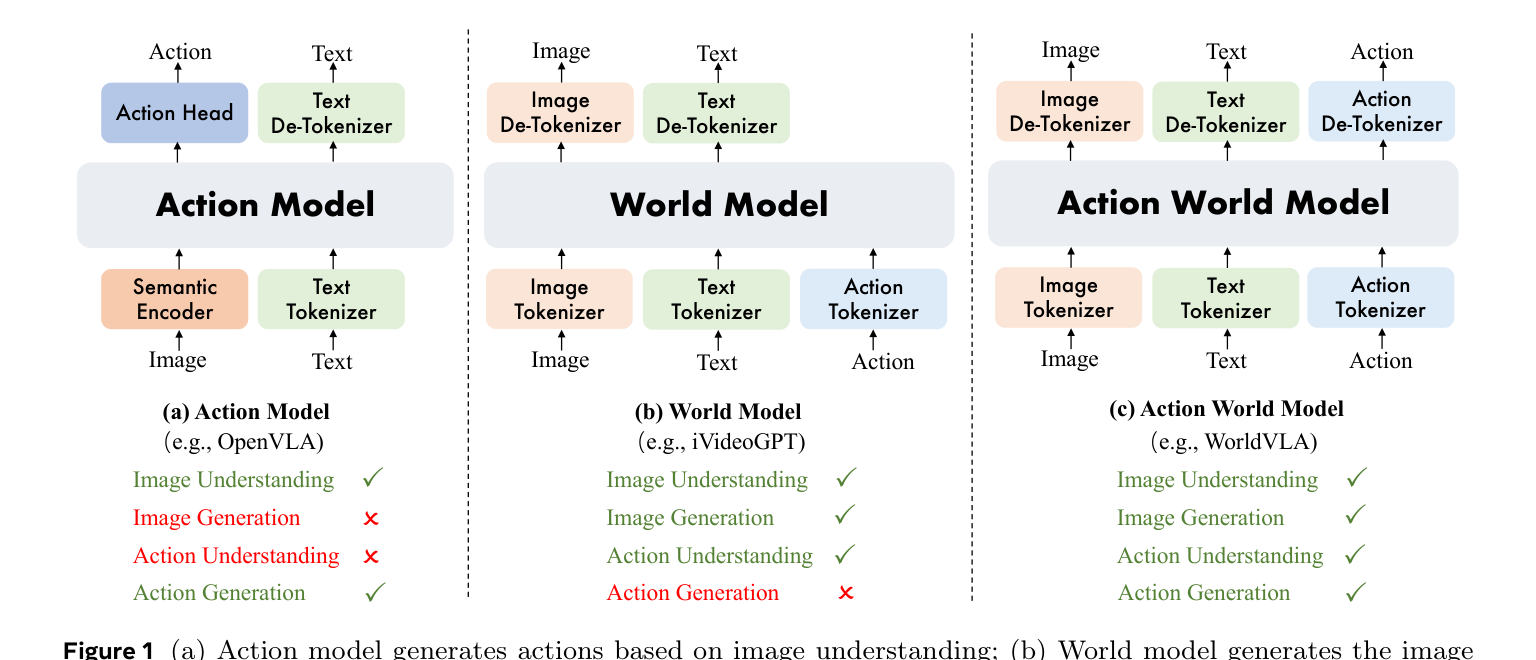
- (a) 动作模型(如 OpenVLA):图像理解✓、动作生成✓,但图像生成✗、动作理解✗。
- (b) 世界模型(如 iVideoGPT):图像理解✓、图像生成✓、动作理解✓,但动作生成✗。
- (c) 动作世界模型(WorldVLA):四项全✓——图像/动作的理解与生成统一。
- 对照表(论文 Table 1,T 文本 / V 视频 / A 动作):动作模型输入 T+V 出 A;世界模型输入 T+V+A 出 V;WorldVLA 输入 T+V+A,同时出 V+A(连续侧的对应物是 UVA)。
3. 整体架构(图2)¶
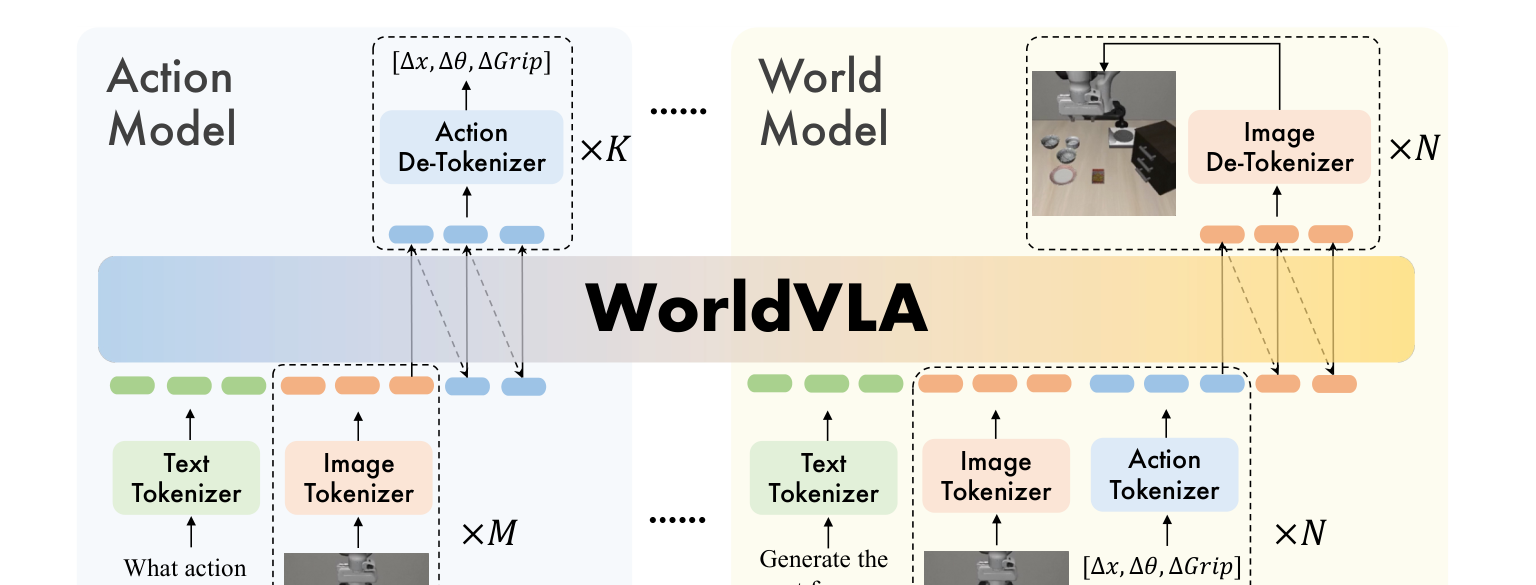
- 骨干:从 Chameleon(混合模态早融合模型)初始化——天生统一图像理解与生成。
- 三个 tokenizer + 共享词表:
- 图像:VQ-GAN(带对人脸/显著物体的感知损失),压缩比 16,码本 8192;256×256 图 → 256 token,512×512 图 → 1024 token。
- 动作:把连续动作每一维离散成 256 个 bin(bin 宽由训练数据范围定);每个动作 = 7 个 token(3 相对位置 + 3 相对角度 + 1 绝对夹爪状态)。
- 文本:BPE,词表 65,536(其中含 8192 图像 token + 256 动作 token)。
- 文本/动作/图像全部离散成 token,统一在自回归方式下训练。
4. 逐模块方法¶
4.1 问题形式化¶
- 动作模型 πθ:
a_t = πθ(a_t | o_{t-h:t}, l)——据历史观测序列 + 语言指令出动作。 - 世界模型 fϕ:
o_t = fϕ(o_t | o_{t-h:t-1}, a_{t-h:t-1})——据历史观测 + 历史动作出下一帧。 - 统一模型 Mψ 同时承担两者:
M_policy出动作、M_world出未来状态,共享表征做决策与环境建模。
4.2 两类训练数据的 token 序列¶
- 动作模型数据:文本提示 = "What action should the robot take to + 任务 + ?";序列
[BOS]{text}[BOI]{image}…[EOI][EOS][BOA]{action}…[EOA][EOS],输入 M 张图、输出 K 个动作,只在动作 token 上算损失L_action。 - 世界模型数据:提示 = "Generate the next frame based on the current image and the action."(不需任务指令——动作本身已完全决定下一状态);序列把"图+动作→下一帧"重复 N 次,只在生成的图像 token 上算损失
L_world。 - 为什么混训(作者三条理由):① 世界模型学环境物理,利于操作;② 世界模型能"模拟+评估"候选动作后果、避开坏状态;③ 世界模型要精确解读动作输入,反过来帮动作模型出更合适的动作。反向地,动作模型增强画面理解,支撑世界模型的视觉生成。
4.3 动作注意力掩码(核心创新,图3)¶
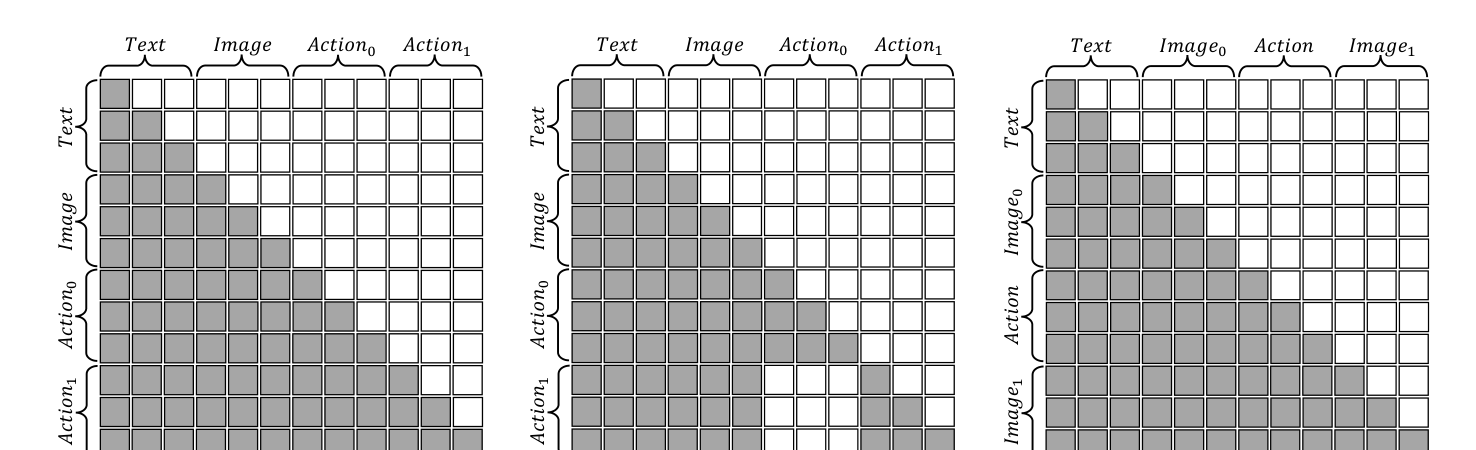
- (a) 默认因果掩码:当前 token 只能看前面所有 token。对连发动作块不行——后面的动作过度依赖前面的动作(同模态、共享空间),而非锚在视觉输入上;动作模态预训练没见过、泛化弱 → 误差沿动作序列累积。
- (b) 本文动作掩码:当前动作只看文本和图像,屏蔽掉所有在先的动作。于是多个动作可并行生成、各自独立、只由视觉决定 → 切断误差传播。
- (c) 世界模型分支:仍用常规因果掩码。
4.4 训练目标¶
L = L_action + α·L_world(式4)。因图像 token(256 或 1024)远多于动作 token(7),用 α=0.04 平衡两边损失贡献。
5. 实验(全量数字)¶
5.1 设置¶
- 基准:LIBERO(Spatial / Object / Goal / Long / 90)。Long 是 10 个长程任务,90 用于预训练。
- 数据:仿 OpenVLA 滤掉失败轨迹与空操作;因世界模型评测要成对的视频-动作真值,按 90% 训 / 10% 验切(Table 2 例外,用全部数据保公平)。
- 默认超参:输入图像数 M=2;动作块 K=10(LIBERO-Long)/ K=5(其余三项);世界模型 N=1 省算力;α=0.04。
- 指标:动作模型每任务 50 次 rollout 记成功率 SR;世界模型在验证集记 FVD / PSNR / SSIM / LPIPS。
5.2 LIBERO 主表(Table 2,SR %)¶
| 模型 | 连续/离散 | 预训练 | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|---|---|
| Diffusion Policy | 连续 | ✗ | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo | 连续 | ✓ | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| DiT Policy | 连续 | ✓ | 84.2 | 96.3 | 85.4 | 63.8 | 82.4 |
| Seer | 连续 | ✗ | – | – | – | 78.7 | – |
| Seer | 连续 | ✓ | – | – | – | 87.7 | – |
| OpenVLA-OFT | 连续 | ✓ | 96.9 | 98.1 | 95.5 | 91.1 | 95.4 |
| UVA | 连续 | ✗ | – | – | – | 93.0 | – |
| OpenVLA | 离散 | ✓ | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| WorldVLA (256×256) | 离散 | ✗ | 85.6 | 89.0 | 82.6 | 59.0 | 79.1 |
| WorldVLA (512×512) | 离散 | ✗ | 87.6 | 96.2 | 83.4 | 60.0 | 81.8 |
读数:WorldVLA 是离散模型,无预训练也超过同为离散、且有预训练的 OpenVLA(81.8 vs 76.5 平均)。512 分辨率 > 256(因 Chameleon 骨干本就在 512 上优化、且细节多对抓取有利)。注意它仍不及连续侧的 OpenVLA-OFT(95.4),离散 token 化天然有信息损失。
5.3 动作模型消融(Table 3,SR %)¶
| # | 动作模型 | 世界模型 | 动作分块 | 本文掩码 | Goal | Object | Spatial | Long | Average |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✗ | ✗ | ✗ | 67.3 | 82.9 | 77.8 | 23.0 | 62.8 |
| 2 | ✓ | ✓ | ✗ | ✗ | 73.1 | 88.0 | 80.2 | 27.3 | 67.2 |
| 3 | ✓ | ✗ | ✓ | ✗ | 79.6 | 82.9 | 36.7 | 16.9 | 54.0 |
| 4 | ✓ | ✗ | ✓ | ✓ | 84.4 | 90.9 | 81.8 | 49.3 | 76.6 |
| 5 | ✓ | ✓ | ✓ | ✓ | 85.1 | 90.9 | 84.0 | 52.4 | 78.1 |
三个关键对比: - 世界模型帮动作模型:行2 vs 行1(+4.4 平均),行5 vs 行4(+1.5)。 - 纯自回归分块掉点:行3 vs 行1,Spatial 从 77.8 崩到 36.7、Long 从 23.0 到 16.9,平均 62.8→54.0。 - 本文掩码救回来:行4 vs 行3,平均 54.0→76.6(Spatial 36.7→81.8、Long 16.9→49.3)。摘要口径:自回归分块掉 10%~50% SR,掩码带来 +4%~+23%。
5.4 世界模型消融(Table 4)¶
| 模型 | 10帧 FVD↓ | PSNR↑ | SSIM↑ | LPIPS↓ | 50帧 FVD↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|---|---|---|
| 纯世界模型 | 250.0 | 29.62 | 90.73 | 11.97 | 718.6 | 23.98 | 83.41 | 15.60 |
| 动作世界模型 | 255.1 | 29.77 | 90.40 | 11.94 | 674.1 | 24.30 | 83.55 | 15.44 |
读数:长视频(50帧)上动作模型明显帮世界模型——FVD 718.6→674.1(约 −6%;摘要里"减少 10% FVD"是另一处对照口径,详见下方"存疑")。短的 10 帧上两者基本持平(FVD 甚至略升 250.0→255.1)。结论方向:越长越受益。
5.5 其它消融¶
-
世界模型 vs 视频预测模型(图7):两者都是视觉生成,区别在世界模型以动作为条件、视频预测不带动作。结论:世界模型在所有评测任务上都提升动作模型;视频预测只在 2 个任务有益、1 个任务反而有害——因为缺动作条件时下一帧不唯一、有歧义,引入训练噪声。
-
历史图像帧数(Table 5,SR% / FPS):
| 配置 | 1帧 SR | 1帧 FPS | 2帧 SR | 2帧 FPS | 4帧 SR | 4帧 FPS |
|---|---|---|---|---|---|---|
| 不用动作分块 | 58.4 | 2.27 | 67.3 | 1.77 | 78.7 | 1.22 |
| 用动作分块 | 74.0 | 3.67 | 84.4 | 3.13 | 84.7 | 2.78 |
单帧不够(VQGAN 语义弱于 CLIP);多帧渐好,但用动作分块时 2 帧已饱和(84.4 vs 4帧 84.7),故默认 2 帧,兼顾 SR 与速度。
- 用世界模型预训练动作模型(Table 6,SR %):
| 配置 | Goal | Object | Spatial | Long | Average |
|---|---|---|---|---|---|
| 无世界模型预训练 | 67.3 | 82.9 | 77.8 | 23.0 | 62.8 |
| 有世界模型预训练 | 73.1 | 84.0 | 79.8 | 30.2 | 66.8 |
把世界模型当预训练权重(要求模型先理解视觉+动作+状态转移物理),再训动作模型,平均 +4。
5.6 定性(图4 / 图5)¶

图4:纯动作模型直接奔向目标位置但没抓住奶酪/酒瓶;动作世界模型会反复尝试直到抓稳再移动。

图5:纯世界模型出现物理崩坏——打不开抽屉(a)、移盘后碗凭空消失(b)、碗抬不上灶台(c);动作世界模型给出连贯且物理合理的后续帧。
6. 局限 / 存疑(含作者自陈)¶
- 离散 token 化天花板:作者自陈离散动作/图像 token 有信息损失,整体仍打不过连续动作模型(OpenVLA-OFT 95.4 vs WorldVLA 81.8)。卖点是"统一框架"而非"屠榜 SR"。
- 图像 tokenizer 表达力弱:VQGAN 语义不如 CLIP,单帧明显不够(要靠多帧补)。作者把"统一的高质量 tokenizer"列为未来方向。
- "+4% / −10%"口径待对齐:摘要称比同骨干动作模型 +4% 抓取 SR、FVD 降 10%;但 Table 3 世界模型增益(行2 vs 行1)平均 +4.4 而 Long 维度差异更大,Table 4 的 50 帧 FVD 是 −6%(718.6→674.1)。不同对比设定下数字不同,引用时需注明是哪一组对照(待核)。
- 只在 LIBERO 仿真:无真机实验、无大规模/跨本体验证;规模化(数据+模型)只是被列为未来工作。
- 动作块过长反掉点:图6 显示块太长机器人来不及及时调策略,性能回落——掩码缓解误差累积,但不解决"块长 vs 反应及时"的根本权衡。
- N=1、单步世界模型:为省算力世界模型只滚 1 步,长程"想象+规划"能力未充分压测。
7. 核心洞见¶
- 统一即增强:把"预测未来帧"和"生成动作"放进同一自回归模型并混训,二者双向受益——世界模型给动作灌物理常识,动作模型给世界模型灌行为理解。这是比"两个独立模型拼接"更紧的耦合方式。
- 动作是 MLLM 的弱模态:预训练只见图文、没见动作,所以自回归连发动作会因泛化弱而误差累积。注意力掩码这一招极轻量(不加参数),却把分块从崩溃救回(行3→行4 平均 +22.6),是本文最实用的工程技巧。
- 世界模型 > 视频预测:以动作为条件消除了"下一帧不唯一"的歧义,这解释了为何带动作的世界模型比不带动作的视频预测更能帮策略——条件信息的完整性决定监督信号的干净度。
🗣️ 外部评价¶
- 🌐 Moonlight/liner 等文献速读站:复述其"统一动作+世界模型、注意力掩码缓解动作块误差累积"的核心贡献,定位为 VLA × 世界模型融合的代表作;均为 AI 生成式综述,非同行评审。来源:Moonlight Literature Review、liner Quick Review。
- 🌐 HuggingFace Papers 页有收录与讨论入口(社区关注度指标)。来源:HF Papers 2506.21539。
- 🧑 未检索到正式 OpenReview / 同行评审记录(搜索 "WorldVLA OpenReview" 命中的是其它论文如 cd33uUB609 "World Action Models are Zero-shot Policies"、DriveVLA-W0,并非本文)。截至检索日,本文以 arXiv 预印本形式存在,无公开审稿意见——如实记录。来源:arXiv 检索。
- 🌐 后续工作引用:已有 World-VLA-Loop(闭环视频世界模型+VLA)、"Do World Action Models Generalize Better than VLAs?" 等鲁棒性研究把它作为对照线索(说明该路线被跟进)。来源:World-VLA-Loop、Robustness Study。
🧑⚖️ 审稿人视角(🤖)¶
(以下为我整理的批判性提问,非真实审稿意见) - 基线不对等:主表把"无预训练的离散 WorldVLA"和"有预训练的离散 OpenVLA"比赢了,但真正的强基线(OpenVLA-OFT、UVA)是连续模型且大幅领先。应补:同骨干、同数据下,连续 head 版 vs 统一离散版的直接对照,否则"统一框架优越性"被分辨率/骨干红利混淆。 - 掩码消融不够干净:行3→行4 的巨大增益里,"动作并行 vs 串行"和"是否能看历史动作"两个变量耦合。应拆:能看历史动作但并行、不能看历史动作但串行,分别多少。 - 世界模型增益的统计显著性:Table 4 短视频 FVD 反升、长视频才降,样本与方差未报;50 rollout 的 SR 也未给置信区间。+4% 是否在噪声内? - 泛化主张缺证据:全程 LIBERO 仿真,未做真机、未做分布外/跨本体。"学到环境物理"更像在单一仿真分布内的拟合,需 OOD 测试支撑。 - 效率账:统一自回归 + 1024 图像 token,推理 FPS 仅 1~3(Table 5),相比连续动作 head 的实时性差距应明确讨论。
8. 对我们(深一层)¶
- 融合路线对照:与 卡片-LaWAM 的"语言-动作-世界模型"同属"世界模型 × VLA 融合"潮流,但路径不同——LaWAM 走其路线,WorldVLA 走离散自回归、共享词表、Chameleon 骨干这条;可并排比较"耦合粒度"与"是否共享同一 LLM"。
- 与 Genie 类对照:详读-Genie(若有)是纯生成式世界模型/可玩环境,WorldVLA 则把世界模型降格为动作模型的辅助监督——一个把世界模型当目的、一个当手段,正好两端。
- 可借的工程招:① 注意力掩码切断动作误差累积——任何"自回归连发动作 chunk"的离散 VLA 都能直接搬;② 混训世界模型数据当辅助任务/预训练(Table 6)灌物理先验;③ 动作=7 token、每维 256 bin 的离散化是 OpenVLA 系标准做法,做离散 VLA 时的默认配置。
- 判断:思路漂亮、技巧实用,但当前数字打不过连续 SOTA,价值在"统一范式"的探索与那个轻量掩码技巧,不在刷榜。引用其"+4%/−10%"时务必标清对照组(见存疑)。
数据来源:arXiv 2506.21539 全文 Table 1–6、Fig 1–7。带"待核/口径"处为多组对照下数字不一致、引用时需指明设定。