详读 · AdaFlow(方差自适应的流匹配策略)¶
卡片版见 卡片-AdaFlow。本页是全文精读:定位 → 动机 → 逐模块方法(含公式直觉)→ 全量数字表 → 局限 → 洞见 → 外部评价 → 对我们。 来源:arXiv 2402.04292v2(2024-11-22,NeurIPS 2024)· 代码 · OpenReview 作者:Xixi Hu、Bo Liu、Xingchao Liu、Qiang Liu(UT Austin,整流流 Rectified Flow 原班人马)
0. 一句话定位¶
把模仿学习策略建成状态条件 ODE(流匹配 / rectified flow),再配一个方差自适应 ODE 求解器:在线根据"当前状态动作分布有多发散(方差)"动态决定积分步数——单模态状态退化成 1 步生成(和 BC 一样快),多模态状态才多步、保多样性。不蒸馏、不 reflow,训练/推理成本接近 BC,平均每步任务只用约 1.1~1.6 次网络调用(NFE)。
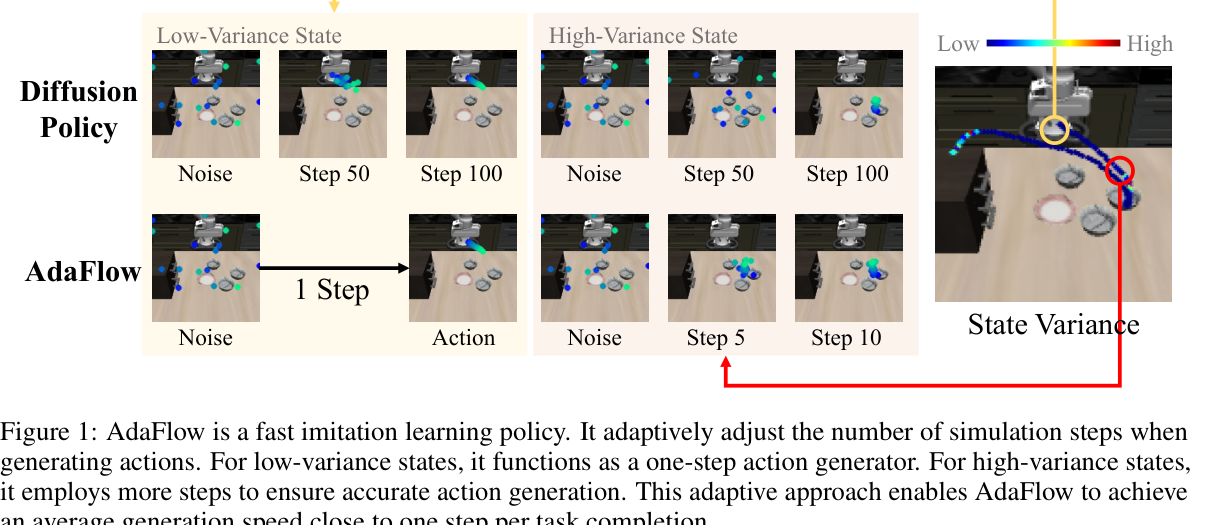
1. 问题与动机¶
- 扩散策略(Diffusion Policy)的硬伤是推理慢:DDPM/DDIM 要递归几十到上百步才出一个动作。BC 快但学不出多模态行为(一个状态多种合理动作时会平均/坍塌)。
- 现有"提速"路线各有缺:
- 能量模型 / 扩散模型:能多模态,但都要递归采样。
- Rectified Flow / Consistency Models:能 1 步,但需要额外的 reflow / 蒸馏阶段——reflow 要先用初版 ODE 仿真造伪"噪声-数据"对,训练贵,而且把 ODE 拉直后生成质量会变差。
- 自适应步长 Runge-Kutta 等通用自适应 ODE 解法:能调步,但砍不掉多少步数,因为不是针对策略 ODE 的内在结构设计的。
- 核心观察(本文卖点):rectified flow 学到的 ODE,其"直不直"取决于该状态动作分布有多确定——确定(方差=0)→ 轨迹是直线 → 1 步 Euler 即精确;越多模态越弯、越需要多步。于是不同状态该花的算力天然不同,而训练损失的条件方差正好量化了这一点。AdaFlow 就是把这个方差估出来、拿来在线调步。
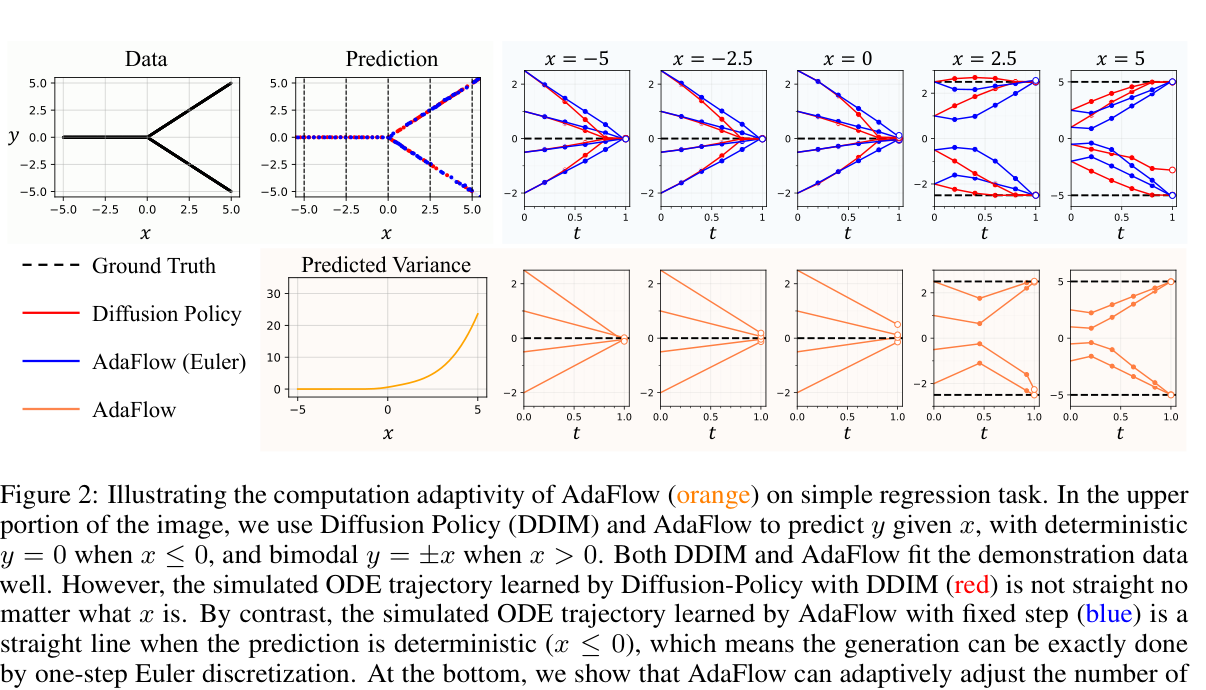
2. 方法逐模块¶
2.1 流匹配策略(速度场,训练目标)¶
- 把策略写成状态条件概率流 ODE:
dz_t = v_θ(z_t, t | s) dt,z_0 ~ N(0, I),积到z_1即为动作a。s是状态/观测,作为额外输入喂进速度网络。 - 用线性插值
x_t = t·a + (1−t)·x_0构造监督,最小化状态条件最小二乘:L(θ) = E ‖a − x_0 − v_θ(x_t, t | s)‖²(对 t 积分)。 - 这就是 rectified flow 在策略上的应用:理想情况下学到的
π_θ匹配专家π_E。注意:ODE 真实轨迹z_t与线性插值x_t一般不重合,只有当所有线性轨迹不相交(即该状态确定)时才重合成直线。
2.2 方差作为"复杂度/弯曲度"指标(理论核心)¶
- 命题 3.1:若某状态动作方差
var(a|s)=0(Dirac 确定),则最优速度场给出dz_t=(a−z_0)dt,轨迹是指向z_1的直线,可用单步 Euler 精确求解z_1 = z_0 + v*(z_0, 0|s)。 - 定义条件方差
σ²(x,t|s) = var(a − x_0 | x_t=x, s) = E[‖a − x_0 − v*‖² | x_t, s]。命题 3.2:确定状态下该方差为 0。→ 方差=多模态程度=轨迹弯曲度=该状态需要的步数。 - 方差估计网络
σ²_φ:速度网络v_θ训好后,用高斯负对数似然再训一个σ²_φ(公式 7)。实践用两阶段:先训v_θ,再在其特征上微调几层线性层当σ_φ(导航/操作任务里直接吃 U-Net 瓶颈特征,开销可忽略)。也可联合训练,效果相当但更慢。
2.3 方差自适应 ODE 求解器(推理核心,算法 1)¶
- 命题 3.3(局部误差界):单步离散化后边际分布与真实分布的 2-Wasserstein 距离满足
W₂(p*_{t+ε}, p_{t+ε})² ≤ ε_t²·E[σ²(z_t,t|s)]。→ 离散化误差被条件方差 × 步长平方界住。 - 于是给定误差阈值
η,步长规则(公式 9):ε_t = Clip( η / σ(z_t,t|s), [ε_min, 1−t] )。方差大 → 步小、多走几步;方差≈0 →ε_t=1−t一步到终点。ε_min防步长无谓地小。 - 命题 3.5(全局误差界):在 Lipschitz + 有界曲率假设下,自适应方案的总误差
W₂(p*_1, p_1) ≤ C·(N_ada/N_max)·ε_min。即实际走的步数N_ada越少于定步 Euler 的N_max,误差界越好——少花算力还更准(好状态下)。 - 与 Rectified Flow 的区别:RF 要靠 reflow 拉直轨迹才能 1 步(训练贵、质量降);AdaFlow 只用初版 ODE,靠"按方差调步"在确定状态自然 1 步、在多模态状态自动多步,省掉 reflow/蒸馏。
3. 实验与全量数字¶
四套任务:① 1D 回归玩具(验证自适应性);② D4RL Maze2D 二维迷宫导航(验证多模态);③ RoboMimic(Lift/Can/Square/Transport/ToolHang)+ Push-T;④ LIBERO(6 个 Kitchen 子任务)。机器人任务沿用 Diffusion Policy 的架构与设置;指标=成功率 + NFE(Number of Function Evaluations,越低越快)。
3.1 定性对比(表1)¶
| 能力 | BC | Diffusion Policy | Rectified Flow | AdaFlow |
|---|---|---|---|---|
| 行为多样性 | ✗ | ✓ | ✓ | ✓ |
| 快速动作生成 | ✓ | ✗ | ✓ | ✓ |
| 无需蒸馏 / reflow | ✓ | ✓ | ✗ | ✓ |
AdaFlow 自称是唯一三项全 ✓ 的:既多样、又快、还不用额外蒸馏阶段。
3.2 迷宫导航(表2,数字=成功率,NFE 越低越好)¶
| 方法 | NFE↓ | Maze1 | Maze2 | Maze3 | Maze4 |
|---|---|---|---|---|---|
| Rectified Flow(需 reflow) | 1 | 0.82 | 1.00 | 1.00 | 0.80 |
| BC | 1 | 1.00 | 1.00 | 0.92 | 0.76 |
| BC-GMM | 1 | 0.84 | 1.00 | 0.88 | 0.72 |
| Diffusion Policy | 1 | 0.00 | 0.32 | 0.16 | 0.08 |
| Diffusion Policy | 5 | 0.58 | 1.00 | 0.84 | 0.76 |
| Diffusion Policy | 20 | 0.62 | 0.98 | 0.84 | 0.82 |
| AdaFlow | 1.56 | 0.98 | 1.00 | 0.96 | 0.86 |
Diffusion Policy 在 NFE=1 时几乎全崩(Maze1=0.00),要 NFE≥5 才像样;AdaFlow 仅 1.56 NFE 就在 Maze3/4 拿最高。
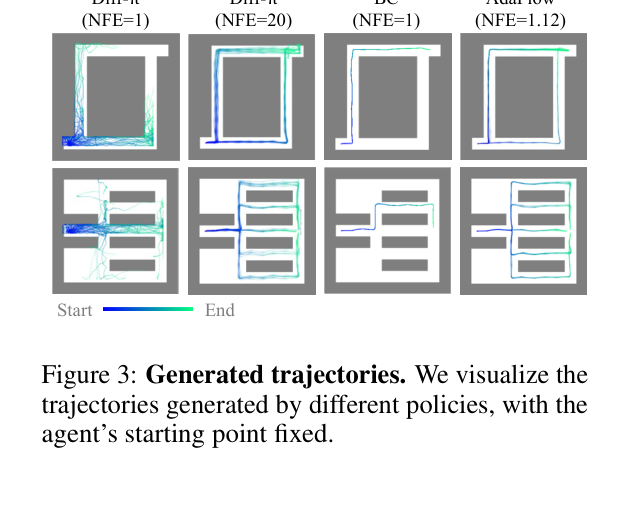
3.3 RoboMimic + Push-T(表3,ph=熟练演示 / mh=混合演示)¶
| 方法 | NFE↓ | Lift ph/mh | Can ph/mh | Square ph/mh | Transport ph/mh | ToolHang ph | Push-T |
|---|---|---|---|---|---|---|---|
| Rectified Flow(需 reflow) | 1 | 1.00 / 1.00 | 0.94 / 1.00 | 0.94 / 0.92 | 0.90 / 0.76 | 0.88 | 0.92 |
| LSTM-GMM | 1 | 1.00 / 1.00 | 1.00 / 1.00 | 0.95 / 0.86 | 0.76 / 0.62 | 0.67 | 0.69 |
| IBC | 1 | 0.79 / 0.15 | 0.00 / 0.01 | 0.00 / 0.00 | 0.00 / 0.00 | 0.00 | 0.75 |
| BET | 1 | 1.00 / 1.00 | 1.00 / 1.00 | 0.76 / 0.68 | 0.38 / 0.21 | 0.58 | - |
| Diffusion Policy | 1 | 0.04 / 0.04 | 0.00 / 0.00 | 0.00 / 0.00 | 0.00 / 0.00 | 0.00 | 0.04 |
| Diffusion Policy | 2 | 0.64 / 0.98 | 0.52 / 0.66 | 0.56 / 0.12 | 0.84 / 0.68 | 0.68 | 0.34 |
| Diffusion Policy | 100 | 1.00 / 1.00 | 1.00 / 1.00 | 1.00 / 0.97 | 0.90 / 0.72 | 0.90 | 0.91 |
| AdaFlow | 1.17 | 1.00 / 1.00 | 1.00 / 0.96 | 0.98 / 0.96 | 0.92 / 0.80 | 0.88 | 0.96 |
AdaFlow 用 1.17 NFE 打平甚至超过 Diffusion Policy NFE=100(约 10× 更快这一主张的来源),且在多个 mh(混合演示,更多模态)列更稳。Diffusion Policy NFE=1 全崩。
3.4 LIBERO 6 任务(表4)¶
| 方法 | NFE↓ | T1 | T2 | T3 | T4 | T5 | T6 | 平均 |
|---|---|---|---|---|---|---|---|---|
| Rectified Flow(需 reflow) | 1 | 0.90 | 0.82 | 0.98 | 0.82 | 0.82 | 0.96 | 0.88 |
| Diffusion Policy | 1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Diffusion Policy | 2 | 0.00 | 0.58 | 0.36 | 0.66 | 0.36 | 0.32 | 0.38 |
| Diffusion Policy | 20 | 0.94 | 0.84 | 0.98 | 0.78 | 0.82 | 0.92 | 0.88 |
| AdaFlow | 1.27 | 0.98 | 0.80 | 0.98 | 0.82 | 0.90 | 0.96 | 0.91 |
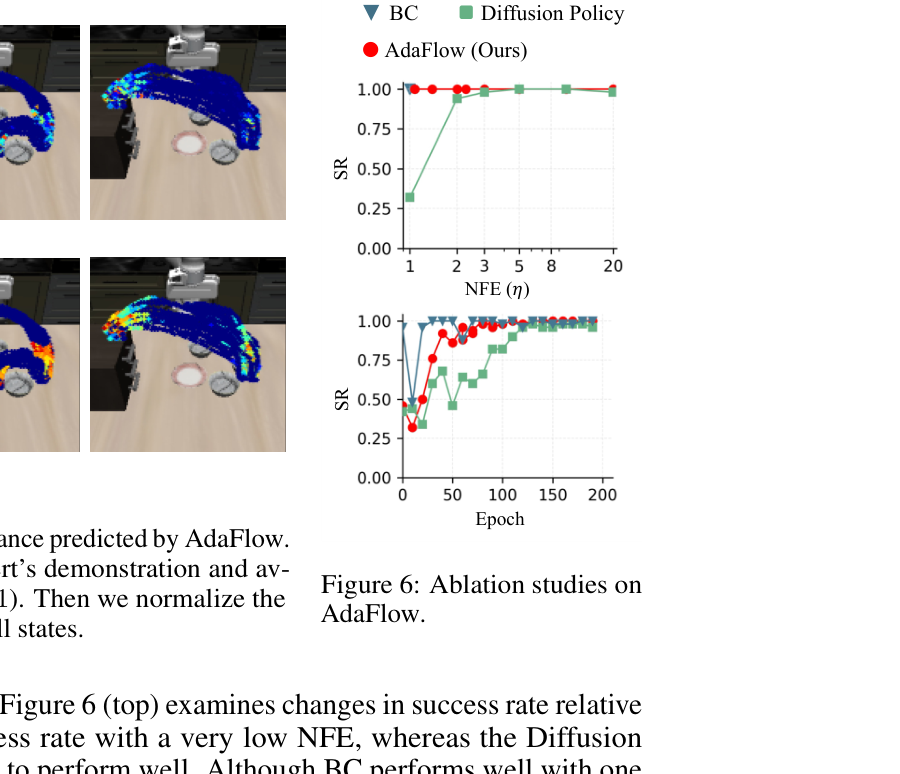
3.5 消融与诊断¶
方差估计网络的价值(表5,迷宫)——去掉方差估计(退化为定步 Euler)成功率明显下降:
| 配置 | Maze1 | Maze2 | Maze3 | Maze4 |
|---|---|---|---|---|
| w/o 方差估计 | 0.78 | 1.00 | 0.92 | 0.80 |
| AdaFlow(全) | 0.98 | 1.00 | 0.96 | 0.86 |
与标准 Rectified Flow 对比(表8,迷宫)——η 越大步数越少:
| 方法 | NFE↓ | Maze1 | Maze2 | Maze3 | Maze4 |
|---|---|---|---|---|---|
| 1-RF | 1 | 1.00 | 1.00 | 0.98 | 0.80 |
| 1-RF | 5 | 0.82 | 1.00 | 0.94 | 0.80 |
| 2-RF(reflow,需贵蒸馏) | 1 | 0.82 | 1.00 | 1.00 | 0.80 |
| AdaFlow(η=1.5) | 1.56 | 0.98 | 1.00 | 0.96 | 0.86 |
| AdaFlow(η=2.5) | 1.12 | 1.00 | 1.00 | 0.94 | 0.78 |

3.6 关键超参与成本(表7 + 正文,📄)¶
- η(误差阈值,越大越快越粗):1D 玩具 0.1 / 迷宫 1.5 / RoboMimic & LIBERO 1.0;ε_min:玩具·迷宫 5 / RoboMimic·LIBERO 10。
- 动作预测 horizon 16、观测输入 2 帧、动作执行 horizon 8(沿用 Diffusion Policy)。Diffusion Policy 推理步:玩具/RoboMimic/LIBERO 100(DDPM)、迷宫 20。
- 方差网络很小:4 层 MLP + SiLU、隐藏维 512,开销相对主模型可忽略。
- 训练贵的是基线:RoboMimic 的 Transport 训+评要 1 个多月 GPU 时,ToolHang 可达 3×;作者直接拿 Diffusion Policy 开源预训练权重微调 500 epoch 再比。
4. 局限 / 存疑(诚实)¶
- 理论假设强:命题成立依赖"无限数据 + 无限容量 + 完美优化",以及 Lipschitz/有界曲率;条件方差定义在审稿中被指表述不够严谨(见下)。现实里"方差=0 → 严格 1 步"是理想化。
- 任务维度偏低:迷宫/RoboMimic/LIBERO 都是相对低维标准基准,未验证高维(如人形全身控制)下能否同样省步。
- 统计显著性弱:成功率表多为单点数字,缺误差棒/多种子方差;正文未单列"局限"章节。
- NFE 随
η漂移:同一迷宫 NFE 在 1.12(η=2.5)~1.56(η=1.5)间变化,"平均约 1 步"是挑了较优工作点的说法,需连同η一起看。 - 两阶段训练:要先训速度场再训方差网络(或联合但更慢),比纯 BC 多一环。
- 仍是离线模仿学习;作者把 offline RL 留作未来工作。
5. 核心洞见¶
- "用预测方差决定推理算力" 是最可迁移的点:把"这一步该想多久"变成一个可学的、状态相关的量,而不是全局固定步数。本质是测试时算力自适应(test-time compute scaling)在策略上的早期形态——后续 2025 年已有多篇沿此思路(如 difficulty-aware stochastic interpolant policy)。
- 方差 ↔ 轨迹直线度 ↔ 离散化误差 这条链把"多模态程度"和"该走几步"用一个量统一起来,比通用自适应 RK 更贴策略 ODE 的结构。
- 相对 Consistency/RF 蒸馏路线,AdaFlow 的卖点是省掉蒸馏阶段:训练管线接近 BC,工程上更轻。
🗣️ 外部评价¶
- 🌐 NeurIPS 2024 接收(Poster),OpenReview 决定
Accept (poster)。来源:OpenReview forum ugXKInqDCC · NeurIPS poster 93256。 - 🧑 四位审稿人评分(rating / soundness / presentation / contribution),源自 OpenReview:
- R1:7 / 3 / 3 / 3 —— 认可思路,但指出主要弱点是没把 AdaFlow 相对 Rectified Flow / Consistency Models 的优劣讲全(推理时的取舍呈现不完整)。
- R2:6 / 2 / 2 / 2 —— 批评"理论分析"不够严谨、仅在极强且不现实的条件下成立;条件方差定义(是否对到 t 的整条路径取条件)表述含糊。
- R3:6 / 3 / 3 / 3 —— 肯定变长步求解器 + 误差界;但测试环境维度偏低,是否能 scale 到高维(如人形控制)不清楚,实验设置/指标细节可更充分。
- R4:6 / 3 / 2 / 3 —— 定位为把 Rectified Flow 扩到模仿学习;弱点:有 typo、(投稿时)未给代码、实验数据缺统计显著性、未讨论局限。
综合:评分 7/6/6/6,共识是"想法漂亮、实验扎实于标准基准",但理论严谨性、与 RF/Consistency 的全面对比、高维可扩展性、统计显著性是公认软肋。来源同上 OpenReview。
🧑⚖️ 审稿人视角(🤖)¶
- 新意:把"训练损失条件方差 ↔ ODE 离散化误差"这条联系挑明,并据此设计按状态调步的求解器——确实是对 rectified flow 的一个干净增量,且免蒸馏。值得发表。
- 该追问的:① 命题里"方差=0 严格 1 步"在有限数据/网络下只是近似,论文对"近似坍塌到 1 步"导致的误差累积没给经验量化;② 表里 NFE 与
η强耦合,应给SR-NFE 帕累托前沿(带种子方差)而非单点;③ 高维/长程任务(如 LIBERO 全套、真实机器人)缺席,"省步"红利是否随维度衰减未知;④ 基线 Diffusion Policy 用 DDPM 步数(100/20)而非更强的 DPM-Solver 等快采样器,对比的"扩散慢"有点偏向自己。 - 可信度:评 A-。结论方向(流策略 + 自适应步 = 快且多样)可信且被后续工作延续,但具体数字宜按"标准基准、单点、低维"理解。
6. 对我们(深一层)¶
- 同一战场、不同路线:与 详读-DiffusionPolicy 是直接对手——AdaFlow 想在保住多模态的前提下把 DP 的"上百步"压到约 1 步。与 卡片-ConsistencyPolicy(一致性蒸馏提速)是两条提速路:Consistency 走蒸馏,AdaFlow 走按需调步、不蒸馏。三者放一起就是"扩散/流策略推理加速"的谱系。
- 流匹配家族:底子(rectified flow / 速度场)与 卡片-π0、卡片-RDT-1B 等 flow-based 策略相通;"方差自适应"这一招原则上可叠加到任何 flow-based VLA 的动作头上。
- 可借机制:✅ 有开源代码;"用预测方差/不确定度决定这一步花多少算力"的思路,可迁移到我们的生成式策略与触觉策略——接触瞬间(多模态、高风险)多算几步,自由空间少算,正对我们关心的接触密集任务。
- 对照实验想法:若我们做 flow-based 动作头,可同时报 SR-NFE 帕累托前沿,把 AdaFlow 的"自适应步"当作几乎零成本的推理侧 baseline。