详读 · CogACT("认知 + 动作"解耦的组件化 VLA)¶
卡片版见 卡片-CogACT。本页是全文精读:定位 → 动机 → 逐模块方法 → 全量数字表 → 局限 → 洞见 → 外部评价 → 对我们。 来源:arXiv 2411.19650v1(2024-11-29)· 项目页 · 代码 作者:Qixiu Li、Yaobo Liang、Zeyu Wang(共同一作)… Jiaolong Yang、Baining Guo 等。清华大学 + 微软亚洲研究院(MSRA)+ USTC + 中科院微电子所。项目负责人邮箱在 MSRA。
0. 一句话定位¶
不要把 VLM "改造"成动作预测器(量化成离散 token 或接个回归头),而是把"认知"和"动作"解耦:用一个 7B VLM 只产出一个"认知特征",再外挂一个专门的扩散动作 Transformer(DiT)做连续、多模态、时序相关的动作序列建模。论文用类比说:人脑有视觉皮层、语言皮层、运动皮层——运动皮层是专门管身体运动的。CogACT = Cognition + Action。
1. 问题与动机¶
- 大 VLA(建在互联网级预训练 VLM 上)泛化好,但任务成功率仍然偏低,作者认为根因是"把动作硬塞进 VLM"的两类做法都不合适:
- 离散量化派(RT-2、OpenVLA):把连续 7D 动作粗暴分桶当语言 token 自回归预测。不像图像/音频有精巧 tokenizer,这种简单量化限制动作精度、动作学习困难。
- 回归头派(RoboFlamingo 等加 LSTM/MSE 头):回归学习忽略了动作的概率性与多模态性(同一任务可有多条可行轨迹)。
- 核心直觉(解耦):VLM 的认知能力和语言输出模态,与稠密机器人动作之间有根本鸿沟。与其复用 VLM 直接出动作,不如让 VLM 只做"认知",把动作交给专用动作模块,端到端联训把两者协同起来。
2. 整体架构(图2)¶
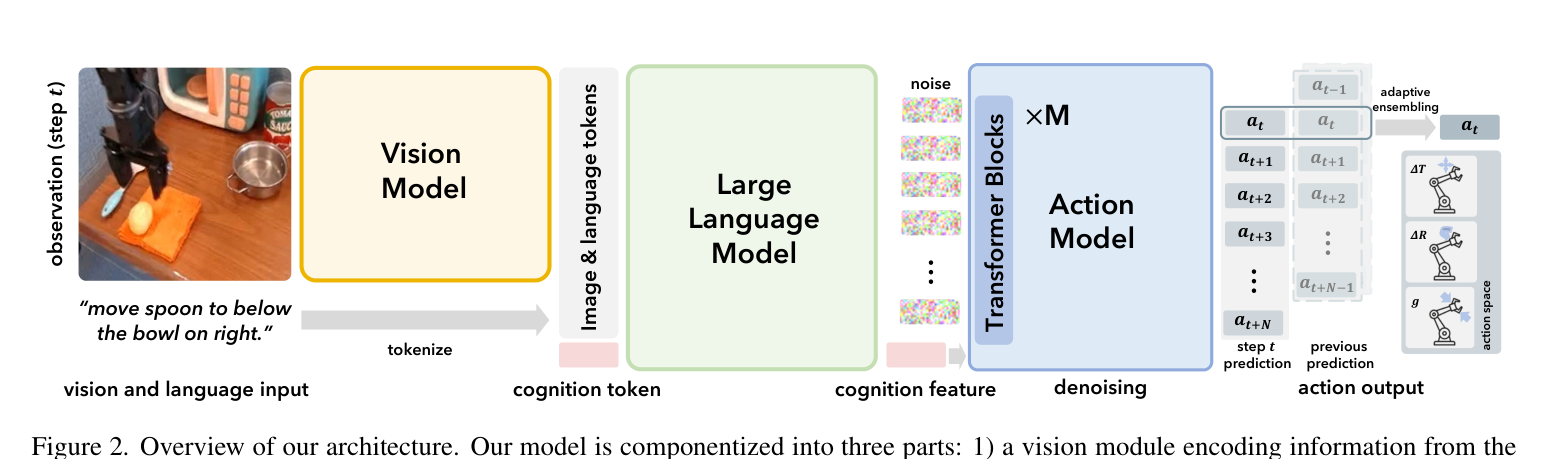
把策略 π:(指令 l, 观测 o_t) → 动作序列 (a_t,…,a_{t+N}) 拆成三块。动作 7-DoF:a = [Δx,Δy,Δz,Δϕ,Δθ,Δψ, g](末端相对平移 + 旋转 + 夹爪开合 g∈{0,1})。
- 视觉模块:沿用 [Prismatic-7B] 那套——DINOv2 + SigLIP 双视觉 ViT,特征沿通道拼接、线性投影,序列化成 256 个视觉 token。
- 语言模块:LLaMA-2 做骨干。把指令 token + 视觉 token + 一个可学习的 cognition token c 一起过因果注意力;c 对应的输出特征
f^c_t就是认知特征——它编码了"当前该执行什么动作"的整合信息,作为动作模块的条件。 - 扩散动作模块(3.2):以
f^c_t为条件 + 一串带噪动作为输入,用 DiT([Peebles & Xie] 的 diffusion transformer)多步去噪出动作。去噪步 i 用正弦位置编码加到认知特征上。一次预测当前 + N 个未来动作(默认 N=15,上下文长度 N+2=17),提升轨迹平滑度与成功率,且计算开销很小。
2.1 训练目标(3.3)¶
视觉 + 语言 + 动作三模块端到端联训/微调,标准扩散噪声 MSE:L = E[‖ε̂_i − ε‖²](预测噪声 vs 真噪声)。
2.2 自适应动作集成 AAE(3.4,图3)¶
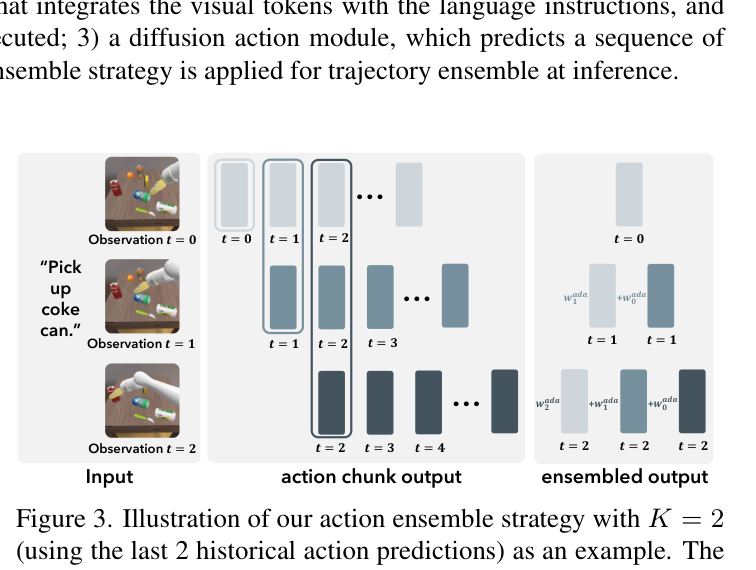
推理时每步会预测多步动作。直接连续执行(Action Chunking)或只执行当前步都不够平滑;ACT 的 Temporal Ensemble 用固定权重混合,但不同预测可能属于不同模态,硬混会得到"哪个模态都不像"的动作。CogACT 提出自适应集成:对历史与当前预测算余弦相似度,相似度越高权重越大——
ŵ_k = exp(α·⟨a_t|o_t , a_t|o_{t−k}⟩),α=0.1。
历史预测可缓存,几乎不增推理成本,却显著涨点。窗口 K 自适应:令 C = K × std(动作) 为常数(C=0.2),不同数据集/速度算出各自 K(如 Google Robot=2,BridgeV2/WidowX=7)。
3. 关键超参与训练配置(数字)¶
| 项 | 值 |
|---|---|
| 总参数 | 7.6B(VLM ~7B + 动作 DiT 最大 0.3B) |
| 动作 DiT 默认 | DiT-Base(89M) |
| 预测未来步 N | 15(上下文 17) |
| 训练数据 | OXE,子集同 Octo/OpenVLA,22.5M 帧(>100 万真机轨迹、60 数据集、22 种本体) |
| 训练 | batch 256、训练扩散步 8、lr 2e-5 恒定、135K 迭代、16× A100 ≈ 5 天、FSDP,权重初始化自 OpenVLA 的视觉/语言模块 |
| 推理 | DDIM 10 步、CFG=1.5 |
| 真机微调 | 16×A100、FSDP 全量微调、batch 256;本方法仅取 10K 步checkpoint(7.5 小时) |
动作模块结构(附录表 III):DiT-Small 13M(6 层/384/4 头)、DiT-Base 89M(12/768/12)、DiT-Large 308M(24/1024/16);对照 MLP-3 层 3M、MLP-7 层 89M。
4. 实验全量数字¶
4.1 仿真 · Google Robot(SIMPLER,表1,成功率 %)¶
| 设置 | 方法 | Pick Coke | Move Near | Open/Close Drawer | Open Top+Apple | 平均 |
|---|---|---|---|---|---|---|
| Visual Matching | RT-1 | 85.7 | 44.2 | 73.0 | 6.5 | 52.4 |
| RT-1-X | 56.7 | 31.7 | 59.7 | 21.3 | 42.4 | |
| RT-2-X (55B) | 78.7 | 77.9 | 25.0 | 3.7 | 46.3 | |
| Octo-Base | 17.0 | 4.2 | 22.7 | 0.0 | 11.0 | |
| OpenVLA (7B) | 18.0 | 56.3 | 63.0 | 0.0 | 34.3 | |
| CogACT | 91.3 | 85.0 | 71.8 | 50.9 | 74.8 | |
| Variant Aggregation | RT-1 | 89.8 | 50.0 | 32.3 | 2.6 | 43.7 |
| RT-1-X | 49.0 | 32.3 | 29.4 | 10.1 | 30.2 | |
| RT-2-X (55B) | 82.3 | 79.2 | 35.3 | 20.6 | 54.4 | |
| Octo-Base | 0.6 | 3.1 | 1.1 | 0.0 | 1.2 | |
| OpenVLA | 60.8 | 67.7 | 28.8 | 0.0 | 39.3 | |
| CogACT | 89.6 | 80.8 | 28.3 | 46.6 | 61.3 |
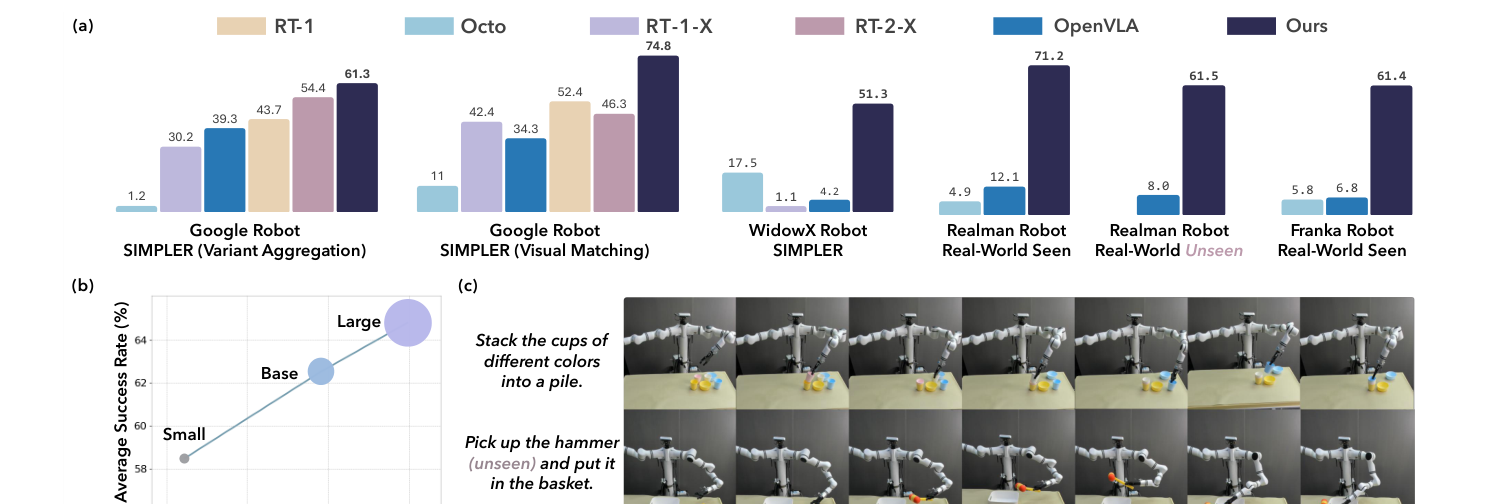
比同体量 OpenVLA 高 40+ 点;比 55B 的 RT-2-X 在 VM 高 28.5、VA 高 6.9(论文摘要总述"仿真 +18% 绝对成功率超 RT-2-X"为综合口径)。"Open Top Drawer + Apple"这种长程任务是拉开差距的关键(CogACT 50.9 vs 全员近 0)。
4.2 仿真 · WidowX Robot(SIMPLER VM,表2)¶
| 方法 | Spoon→Towel | Carrot→Plate | Stack Block | Eggplant→Basket | 平均 |
|---|---|---|---|---|---|
| RT-1-X | 0.0 | 4.2 | 0.0 | 0.0 | 1.1 |
| Octo-Base | 15.8 | 12.5 | 0.0 | 41.7 | 17.5 |
| Octo-Small | 41.7 | 8.2 | 0.0 | 56.7 | 26.7 |
| OpenVLA | 4.2 | 0.0 | 0.0 | 12.5 | 4.2 |
| CogACT | 71.7 | 50.8 | 15.0 | 67.5 | 51.3 |
4.3 真机 · Realman(7-DoF 臂 + 1-DoF 夹爪,表3)¶
全员在 OXE 预训练 + 自采 391 条演示微调(Pick 48 / Stack 67 / Place 79 + 其它 197)。

| 方法 | Pick 平均 | Stack 平均 | Place 平均 | 总平均 |
|---|---|---|---|---|
| Octo-Base | 8.3 | 0.0 | 6.3 | 4.9 |
| OpenVLA | 8.3 | 15.6 | 12.5 | 12.1 |
| CogACT | 70.8 | 82.3 | 60.4 | 71.2 |
总平均 71.2 vs OpenVLA 12.1 → +59.1 个百分点(摘要"真机超 OpenVLA 55%+"即此)。
4.4 真机 · Realman 泛化(未见桌面/干扰物,表4;未见颜色/形状/类别,表5)¶
| 测试 | OpenVLA | CogACT |
|---|---|---|
| 未见桌+未见干扰物(总平均) | 9.7 | 58.4 |
| 未见颜色 | 0.0 | 87.5 |
| 未见形状 | 6.3 | 81.3 |
| 未见类别 | 12.5 | 25.0 |
| 未见三项平均 | 6.3 | 64.6 |
未见类别最难(25.0),是泛化的薄弱环;颜色/形状泛化很强。
4.5 真机 · Franka(表6,每任务 11 次,各采 100 演示共 400)¶
| 方法 | Close Oven | Open Oven | Pick Bowl | Pick Brush | 平均 |
|---|---|---|---|---|---|
| Octo-Base | 0.0 | 0.0 | 27.3 | 0.0 | 5.8 |
| OpenVLA | 18.2 | 0.0 | 9.1 | 0.0 | 6.8 |
| CogACT | 63.6 | 72.7 | 72.7 | 36.4 | 61.4 |

4.6 消融(SIMPLER,GR=Google/WR=WidowX,VM/VA 设置)¶
动作模块结构(表7):
| 结构 | 参数 | GR-VM | GR-VA | WR-VM | 平均 |
|---|---|---|---|---|---|
| MLP-3层 | 3M | 52.2 | 52.4 | 47.1 | 50.6 |
| MLP-7层 | 89M | 61.4 | 48.0 | 48.1 | 52.5 |
| DiT-Small | 13M | 73.3 | 51.3 | 51.0 | 58.5 |
| DiT-Base | 89M | 74.8 | 61.3 | 51.3 | 62.5 |
| DiT-Large | 308M | 76.7 | 59.3 | 58.3 | 64.8 |
两点结论:① 同参数下 Transformer > MLP(注意力擅长序列建模);② 成功率近似随动作模块参数对数线性上升(图1b)——加几百 M 参数(相对 7B VLM 很小)就显著涨点,是更"省"的 VLA 扩展方式。
多步预测 N(表8):
| 未来步 N | GR-VM | GR-VA | WR-VM | 平均 |
|---|---|---|---|---|
| 0(单步) | 73.4 | 49.0 | 6.3 | 42.8 |
| 3 | 70.4 | 58.9 | 37.1 | 55.5 |
| 15 | 74.8 | 61.3 | 51.3 | 62.5 |
| 31 | 54.3 | 47.6 | 51.7 | 51.2 |
N=15 最优;N=0(单步)在 WidowX 直接崩到 6.3;N=31 太长反而退化。
集成策略(表9):
| 策略 | GR-VM | GR-VA | WR-VM | 平均 |
|---|---|---|---|---|
| Action Chunking | 67.4 | 52.5 | 32.1 | 50.7 |
| Temporal Ensemble (ACT) | 75.0 | 59.9 | 41.9 | 58.9 |
| Adaptive Ensemble (本文) | 74.8 | 61.3 | 51.3 | 62.5 |
CFG 尺度(附录表IV):CFG=1.0→平均55.7;1.5→62.5(默认);3.0→62.7(GR 略升但 WR 退化),故取 1.5。
5. 局限 / 存疑(诚实)¶
- 动作空间窄:只做单臂 7-DoF 夹爪(Δpose + 开合),未涉双手/灵巧手/力控——与 详读-DexTeleop-0 那类接触密集任务不在一个层面。
- "动作模块大"是相对而言:最大 DiT 仅 300M,作者也承认"对 LLM 而言不算大",只是针对 7D 动作空间算大;扩展实验只到 308M,更大未验证。
- 未见类别泛化弱(25%):颜色/形状靠视觉编码器外推还行,跨语义类别仍吃紧。
- 推理成本:7.6B 主干 + 扩散去噪(DDIM 10 步),论文未报真机控制频率/端到端延迟;只给"额外集成开销小"。
- 比较口径:Google Robot 上多数基线数字直接引用 SIMPLER 论文,OpenVLA 自测、Octo 加测多种子;不同方法测试次数/checkpoint 选择不完全一致(本方法真机仅测一个 10K checkpoint,基线则挑最优 checkpoint——这点对本方法其实更不利)。
- SIMPLER 仍是仿真:虽与真机相关性强,结论需真机互证(论文已补 Realman/Franka)。
6. 核心洞见¶
- 解耦 > 复用:把动作建模从 VLM 里"拆出来",比把 VLM 强行当动作生成器更有效——这是当前主流"VLM 认知 + 独立动作头/模块"范式的有力实证(与 π0、RDT-1B 同方向)。
- 扩散 + 序列 > 单步:DiT 做动作块去噪同时拿下"多模态分布"和"时序相关"两个特性;单步预测和小扩散头(如 Octo 的 3M 头)都不够。
- 动作模块也有 scaling law:成功率随动作 DiT 参数对数线性涨,提示一种比堆大 VLM 更省的 VLA 扩展路径。
- 集成要看模态:按相似度自适应加权,避免跨模态硬平均——一个简单但有效的工程点。
🗣️ 外部评价¶
- 🌐 OpenReview 提交页存在(forum?id=gG5kL0rFkV):抓取时该页仅显示摘要/元数据,公开的审稿意见、评分与 decision 未对外可见(可能为撤稿/未公开评审的会议投稿)。截至精读,未能检索到实质性的同行评审批评。— 如实记录,无法引用具体审稿意见。
- 🌐 Moonlight 文献综述:内容偏宣传性、无批判,只复述"模块化解耦 + 强实验 + 时序集成"等优点,未列局限。参考价值有限。
- 🌐 Microsoft Research 官方发布页 收录该工作(机构背书)。
- 🌐 被多篇后续 VLA 综述/工作引用为"componentized / diffusion-action VLA"的代表(如 Awesome-VLA-Papers 列表、各类 VLA survey)。
- ⚠️ 未能确认会议录用状态:arXiv 为 2024-11 v1;搜索未明确证实其 CVPR 2025 录用(同期有 CoT-VLA 等 VLA 论文在 CVPR'25)。venue 待补。
🤔 我的判断(🤖)¶
- CogACT 是"VLM 出认知特征 + 专用扩散 DiT 出动作"这一解耦范式里工程完整、数字硬的一篇:开源代码 + 权重 + 5 本体(Google/WidowX/Realman/Franka + SIMPLER)评测,复现门槛清晰,可直接作为我们动作模块的参考实现。
- 它的真正卖点不是"更大的 VLM",而是用很小的动作模块(≤300M)+ 扩散序列建模把成功率撑起来——对算力有限的我们更友好:主干可冻/复用,主要训练量压在动作 DiT 上。
- 但它停在单臂夹爪、无力/触觉。我们若做接触密集/力控任务,需要把它的"认知特征 → 动作 DiT"骨架,接上力/触觉条件与更高 DoF 动作空间——这正是 详读-DexTeleop-0(采数)与扩散动作头(执行)之间可拼的位置。
- 自适应集成(按相似度加权)是个低成本可直接借用的推理 trick。
对我们(关联)¶
- 范式对照:卡片-OpenVLA(离散量化派,同 7B、本文主要打击对象与初始化来源)↔ CogACT(解耦扩散派)。CogACT 几乎全面反超 OpenVLA(仿真 +35%、真机 +59%),是"别把动作量化"的直接证据。
- 动作模块对照:卡片-DiffusionPolicy / 卡片-RDT-1B / 卡片-π0——都用扩散建模动作多模态;CogACT 把"扩散动作头"升级成"扩散动作 模块/DiT",并嫁接到强 VLM 认知上。
- 数据底座:训练用 概念-机器人数据与标注 里的 OXE 子集(22.5M 帧),与 Octo/OpenVLA 同源,便于横评。
- 可拼接:认知-动作解耦骨架 + 力/触觉条件 + 高 DoF 动作空间 = 我们接触任务策略的一条候选路线。