详读 · Genie(生成式可交互环境 / 基础世界模型)¶
卡片版见 卡片-Genie。本页是全文精读:动机 → 方法(逐模块) → 实验(全表/全量数字) → 诚实局限 → 洞见 → 对我们。 来源:arXiv 2402.15391v1(2024-02-23,Google DeepMind,ICML 2024 最佳论文) 作者(同等贡献):Jake Bruce、Michael Dennis、Ashley Edwards、Jack Parker-Holder、Yuge (Jimmy) Shi、Tim Rocktäschel* 等(DeepMind)+ Jeff Clune(UBC)。
0. 一句话定位¶
第一个完全从无标注互联网视频、无动作标签训练出来的"生成式可交互环境"。 用一张图/一句文本/一张草图当首帧,就能逐帧用"潜动作"操控生成一个像游戏的世界。10.7B 参数,作者称之为该领域的基础世界模型(foundation world model)。关键创新:把"动作"做成完全自监督学出来的离散潜动作(latent action),从而摆脱"世界模型必须要动作标注"的老约束。
1. 问题与动机¶
- 视频生成模型越来越强,但和 ChatGPT 那种可交互体验之间还有鸿沟——视频模型只能"看",不能"逐帧地玩"。
- 传统世界模型(World Model)要 next-frame 预测就得喂动作标注的数据(video + actions),而互联网视频没有动作标签、标注又贵。
- Genie 的切入:只用视频训练,把帧间"发生了什么"压成一个小离散动作集自监督学出来 → 既能逐帧控制,又能 scale 到互联网规模数据。
下表是作者给的"新模型类别"定位(表格前留空行):
| 模型类 | 训练数据 | 可控粒度 |
|---|---|---|
| World Models | 视频 + 动作 | 帧级(frame-level) |
| Video Models | 视频 + 文本 | 视频级(video-level) |
| Genie | 仅视频 | 帧级 |
2. 总体架构(图3)¶
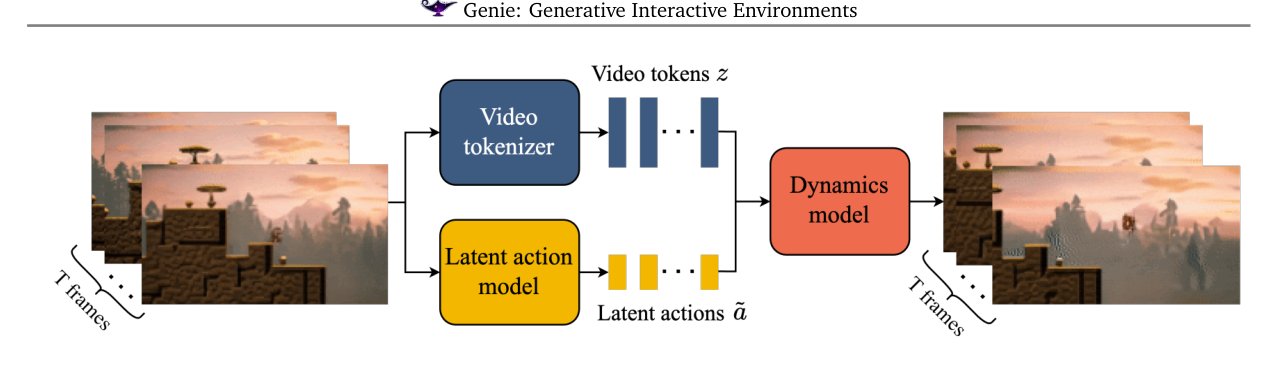
三大件 + 一根脊梁(ST-Transformer): 1. 潜动作模型(LAM):从相邻帧推断帧间潜动作 ã。 2. 视频 tokenizer:把原始帧压成离散 token z。 3. 动力学模型(dynamics):给定过去 token + 潜动作,预测下一帧 token。
两阶段训练:先单独训 tokenizer;再联合训 LAM(直接吃像素)和 dynamics(吃 token)。
2.1 脊梁:ST-Transformer(图4)¶
- 视频 token 量可达 O(10⁴),普通 transformer 的二次内存吃不消。
- ST-Transformer = L 个时空块,每块 = 空间注意力层(在单帧内 1×H×W token 上) + 时间注意力层(跨 T 帧、同一 token、带因果 mask) + 1 个 FFW。
- 关键工程取舍:每块只放 1 个 FFW(省掉空间层后的 FFW),把省下的容量让给模型其它部分——作者说这"显著改善结果"。
- 收益:主导计算量(空间注意力)随帧数线性增长(不是二次),适合长交互的一致动力学。
2.2 潜动作模型 LAM(图5,核心创新)¶
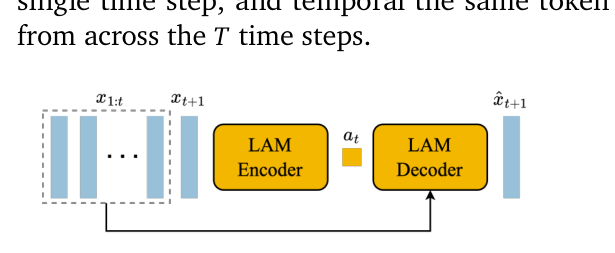
- Encoder 吃所有历史帧 x₁:ₜ + 下一帧 x_{t+1} → 出连续潜动作 ã₁:ₜ;Decoder 用历史帧+潜动作重建 x̂_{t+1}。
- 用 VQ-VAE 目标把潜动作离散化,码本大小 |A| 故意取很小 = 8——为了①人类可玩性②强制可控性(动作太多就没法"像手柄按键一样"被理解)。
- 因为 Decoder 只看得到历史 + 潜动作,ã_t 被逼着去编码"过去→未来"最有意义的变化。
- 推理时整个 LAM 几乎全丢掉,只留 VQ 码本——用户直接选离散动作 0..|A|-1 替代它。
- 同样用 ST-Transformer,时间层因果 mask 让一次性吃整段视频 x₁:T、一次出全部 ã₁:T₋₁。
2.3 视频 tokenizer(图6,ST-ViViT)¶
- VQ-VAE,把 T 帧 (T×H×W×C) 压成离散 token z₁:T。
- 与前作只做空间压缩不同,Genie 在 encoder/decoder 都用 ST-Transformer把时间动态也编进去 → 每个 z_t 因因果性含此前所有帧的信息 → 生成质量更好。
- 对比 Phenaki 的 C-ViViT(全时空注意力、随帧数二次增长、算力贵),Genie 的 ST-ViViT 随帧数线性,更省。
2.4 动力学模型 dynamics(图7)¶
- decoder-only 的 MaskGIT transformer。
- 每步吃 token z₁:ₜ₋₁ + stop-grad 的潜动作 ã₁:ₜ₋₁ → 预测下一帧 token ẑ_t;交叉熵损失对齐 GT token。
- 训练时按 Bernoulli mask 率(在 0.5~1 间均匀采) 随机遮 token。
- 重要发现:潜动作不按惯例"拼接(concatenate)到帧",而是当作加性嵌入(additive embedding)——这样可控性更好。
2.5 推理:动作可控视频生成(图8)¶
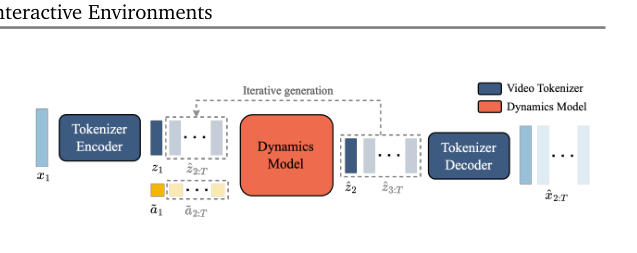
- 玩家给首帧 x₁ → tokenizer 编码成 z₁;选离散动作 a₁∈[0,|A|) → 码本索引得 ã₁ → dynamics 预测 z₂ → 自回归滚下去。
- 既能"回放"(喂 GT 首帧 + 从视频推断的动作),也能"造新轨迹"(改动作)。
- 作者注:动作语义跨不同输入保持一致——"理解潜动作就像学一个新手柄的按键"。
3. 实验设置与数字¶
3.1 数据¶
- Platformers(2D 平台跳跃游戏):按关键词从公开互联网视频筛 → 55M 段 16s 片段(10FPS、160×90、每段 160 帧),约 244k 小时;再过质量分类器精筛到 6.8M 段 = 30k 小时(只剩原始 ~10%,但 FVD 更好,见表4)。论文引言里说总语料 >200,000 小时。
- Robotics:把 RT-1 数据(~130k 真机演示) + 一份仿真数据 + 早期工作(QT-Opt)的 209k 真机 episode 合在一起,只当视频用、丢掉动作。
3.2 指标¶
- 保真度:FVD(Fréchet Video Distance,越低越好)。
- 可控性:自定义 Δ_t PSNR(t=4)= PSNR(用 GT 推断动作生成的帧) − PSNR(用随机采样动作生成的帧);越大说明"换动作画面差越多"=潜动作越起作用。
3.3 最终 Genie 模型 / 训练配置(精确数字)¶
- 视频 tokenizer:200M 参数,patch 4,码本嵌入维 32、1024 码。
- LAM:300M 参数,patch 16,码本嵌入维 32、8 码(=8 个潜动作)。
- 序列长 16 帧、10 FPS;训练用 bfloat16 + QK-norm 稳大规模训练。
- 推理:每帧 25 个 MaskGIT 步,温度 2,随机采样。
- 最终 dynamics = 10.1B,batch 512,125k 步,256× TPUv5p;+tokenizer+LAM 共 10.7B 参数(摘要里圆整为 11B),训练 942B token。网站版另训了个更大的 decoder 把 token 解到 360p。
4. 缩放实验(图9)¶
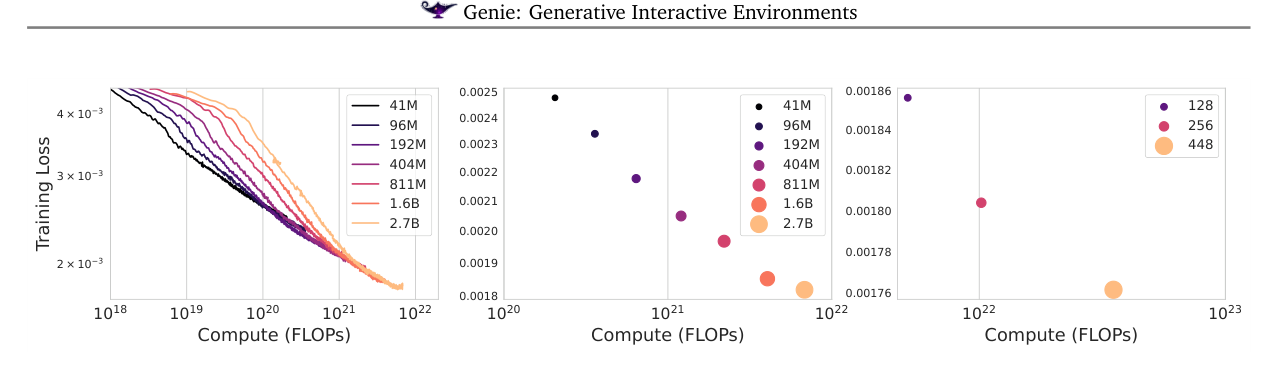
- 缩模型:固定 tokenizer/LAM,dynamics 从 40M 到 2.7B,每增大一档最终训练损失稳定下降 → 架构随算力优雅缩放。
- 缩 batch:2.3B 模型,batch 128/256/448(=1.9M/3.8M/6.6M token),越大越好。
- 附录 Table 10 给出各档(41M..2.7B)的层数/头数/d_model 与训练天数、FLOPs(如 2.7B:36 层 22 头 d_model 3072,TPUv3 16 天,6.91×10²¹ FLOPs);Genie dynamics(Table 12):10.1B = 48 层 36 头 d_model 5120,6.6×10²² FLOPs。
5. 定性结果¶
- OOD 起手图都能玩(图10):用 Imagen2 文生图、手绘草图、真实照片当首帧,仍出现清晰的"角色移动"等游戏行为,证明大规模视频训练带来的鲁棒泛化。
- 3D/视差(parallax)涌现(图12):同一潜动作下前景比中/远景位移更大——学到了平台游戏常见的视差感。
- 学物理/形变(图11):机器人模型能学薯片袋等物体的形变。
5.1 机器人模型(图13,关键迁移证据)¶

- 用 Platformers 上最优超参训了个 2.5B Robotics 模型,测试集 FVD = 82.7。
- 无任何动作标签,却学出跨不同起始帧一致、且有语义(下/上/左)的潜动作,并学到机械臂控制 + 物体交互/形变 → 暗示"用互联网视频造机器人基础世界模型"的路径。
6. 用潜动作训智能体(图14/15)¶
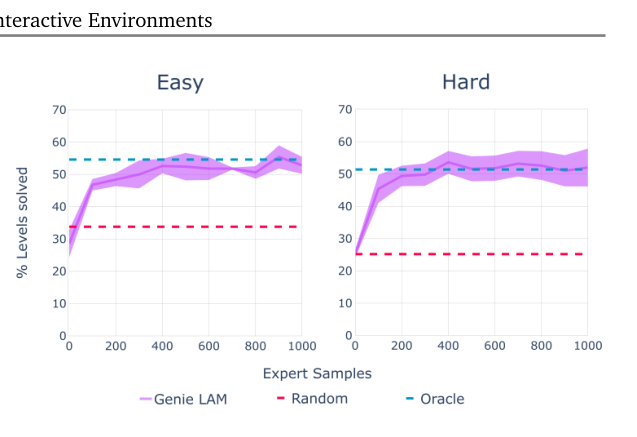
- 思路:用冻结的 LAM 给未见过环境的专家视频打"潜动作标签" → 训策略 π(a|x) 预测专家潜动作;再用很少量带真实动作的专家数据建"潜动作→真实动作"的映射字典。
- 在程序生成的 2D 平台环境 CoinRun(hard/easy)上,对比 oracle BC(能看真实动作=上界)与 random(下界)。
- 核心结果:LAM-based 策略仅需 200 个专家样本适配就达到 oracle 同等分数——尽管它几乎肯定没见过 CoinRun。证明学到的潜动作一致、可迁移(潜→真映射不含当前观测信息)。
7. 消融实验(全表)¶
7.1 LAM 输入:像素 vs token(Table 2)¶
| 设置 | 数据 | #参数 | FVD↓ | Δ_t PSNR↑ |
|---|---|---|---|---|
| Token-input | Platformers | 2.3B | 38.8 | 1.33 |
| Pixel-input (Genie) | Platformers | 2.5B | 40.1 | 1.91 |
| Token-input | Robotics | 1B | 257.8 | 1.65 |
| Pixel-input (Genie) | Robotics | 1B | 136.4 | 2.07 |
结论:token 输入在 Platformers 上 FVD 略好,但可控性(Δ_t PSNR)更差,且在 Robotics 上连 FVD 都更差。说明 tokenize 会丢掉运动/动态信息 → LAM 该吃原始像素。
7.2 Tokenizer 架构(Table 3,patch 10 / batch 128 / seqlen 16)¶
| Tokenizer | #参数 | 显存 | FVD↓ | Δ_t PSNR↑ |
|---|---|---|---|---|
| ViT(纯空间) | 230M | 0.3GB | 114.5 | 1.39 |
| C-ViViT(Phenaki) | 225M | 1.6GB | 272.7 | 1.37 |
| ST-ViViT(本文) | 205M | 0.9GB | 81.4 | 1.66 |
ST-ViViT 在 FVD 和可控性上都最好,显存只是适中。C-ViViT 全时空注意力显存最贵却最差(易过拟合、需强正则)。
7.3 数据精筛(Table 4) / tokenizer batch(Table 6)¶
| 数据 | #参数 | FVD↓ |
|---|---|---|
| 原始(55M 段) | 580M | 61.4 |
| 精筛(6.8M 段) | 580M | 54.8 |
"高质量 > 数量":精筛集只剩 ~10% 体量,FVD 反而更好。 Tokenizer batch 缩放(Table 6):batch 64 → PSNR 35.7;batch 384 → PSNR 36.5(边际收益)。
8. 诚实局限(作者自述 / 我读出来的)¶
- 会幻觉:继承自回归 transformer 的毛病,会编出不真实的未来。
- 只有 16 帧记忆 → 长时域一致性差(环境难长期保持一致)。
- 约 1 FPS → 离"流畅可交互帧率"还有距离,需要后续提速。
- 不开源:明确不放 checkpoint、训练集、数据样例(出于安全/版权/责任)。→ 复现性受限;但附录 F 给了一个可在单张中端 TPU/GPU 一周内跑完的 CoinRun 小规模复现案例。
- 评测主要在 2D 平台游戏这个相对受限域;Robotics/agent 部分更像"可行性证明"而非系统评测。
- |A|=8 的小动作集是"可玩性 vs 表达力"的折中——真实精细操作的动作空间远比 8 个离散码丰富。
9. 核心洞见¶
- 最大贡献是范式:"动作"不必来自标注,可以自监督地从帧间变化里学出一个小离散潜动作空间",从而把世界模型解锁到纯视频、互联网规模。
- 三处一致的工程哲学:①处处用线性代价的 ST-Transformer 换长时一致性;②潜动作码本极小 + 加性嵌入逼出可控性;③LAM 吃像素而非 token保住运动信息。
- 双向价值:既是"可玩的生成环境",又是"给无标注视频自动打动作标签的工具"(冻结 LAM)→ 后者对下游模仿学习/智能体训练意义可能更大。
10. 对我们¶
- 潜动作 = 本库一条主线:与 卡片-LaWAM / 详读-LaWAM 的"潜动作世界模型"思路同源——都在回答"机器人数据缺动作标注,怎么自监督地学出可控动作表示"。Genie 是这条线在纯视频、超大规模上的代表作,可作对照基准。
- 世界模型谱系:可挂到 综述-世界模型,并与 卡片-DreamerV3、卡片-UniSim(Genie 正文点名对比,需 text+action 标注)、卡片-iVideoGPT、卡片-NWM、卡片-DINO-WM、卡片-Cosmos、卡片-VPP 横向比较。
- 数据复用:Genie 直接把 卡片-RT-1 的 RT-1 数据"当视频用、丢动作"——印证"现有机器人数据集去掉动作标签也能喂世界模型"这一可公开方向。
- 可借机制:①ST-Transformer 线性时空注意力(长序列视频/触觉序列都可借);②极小离散码本 + 加性嵌入逼可控性;③"冻结 LAM 给无标注视频打潜动作标签 → 少量真实动作做映射"的低标注模仿学习配方。
- 互为对照:Genie 走"纯视觉、超大规模、2D 游戏域";本库另一类工作(如 详读-VT-WM、触觉世界模型)走"接触/力觉、真机域"——两条路线在"世界模型给机器人当数据引擎"上长期对照。