详读 · VLA-Touch(不重训 base VLA,在"规划+控制"两层外挂触觉)¶
卡片版见 卡片-VLA-Touch。本页是全文精读:动机 → 方法(逐模块) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2507.17294(v2, 2025-07-29)· 项目页 · 代码 作者:Jianxin Bi、Kevin Yuchen Ma、Ce Hao、Mike Zheng Shou、Harold Soh(通讯)(新加坡国立 NUS,CS 系 + Smart Systems Institute)
0. 一句话定位¶
给现成 VLA(本文用 RDT-1B)在两个层级"贴"触觉、全程不微调 base VLA:规划层用预训练触觉-语言模型 Octopi 把触感翻成文字("软/硬/粗糙/力")喂给 GPT-4o 做闭环重规划;控制层用一个插值扩散控制器(BRIDGeR)拿低维触觉力信号去精修 VLA 生成的动作块。卖点是模块化、解耦、零重训——可套到任意 VLA(OpenVLA/π0)上探"触觉到底有没有用"。
1. 问题与动机¶
- SOTA 的 VLA 主要在视觉+语言+动作数据上训练,没有处理触觉的内建机制;视觉对物体软硬、表面纹理、接触事件有歧义 → 接触密集任务受限。
- 把触觉塞进大基础模型有两难:① 没有大规模触觉多模态数据集来重训;② base VLA 没有触觉输入模态/接口。
- 作者假设触觉在两个层级都有用,对应人脑两套结构:
- 规划层(前额叶/高级认知):推理软硬、粗糙度等"视觉看不出"的属性 → 决定"挑哪个/怎么放"。
- 控制层(后顶叶/运动):感知接触力、摩擦、接触事件 → 做精细的力调制、保持接触。
- 切入点:不动 base VLA,用松耦合模块分别在这两层外挂触觉,从而能隔离测量触觉各自的贡献。
2. 总体框架:双层触觉反馈(图1)¶
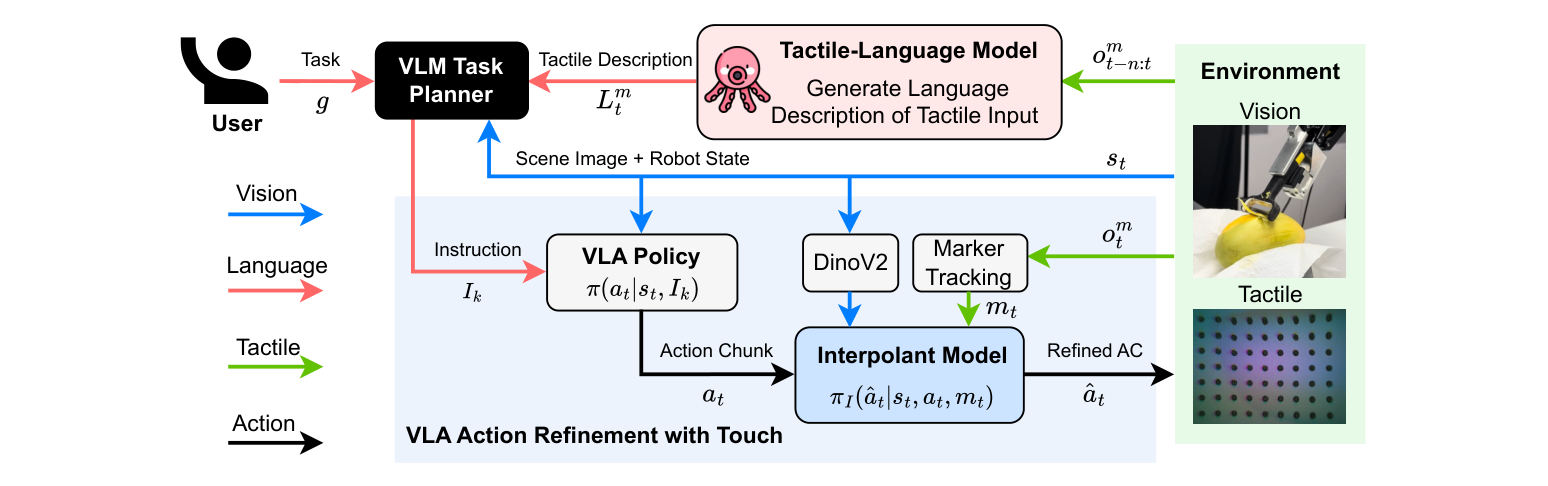
类比人类神经系统的三个模块:
1. 任务规划器(≈前额叶):GPT-4o,吃任务目标 g + 场景图 s_t + 语言化触觉反馈,产出一条原子操作指令 I_k 给 VLA 执行。
2. 触觉-语言模型 TLM(≈次级体感皮层):Octopi,把一段触觉序列 o^m_{t-n:t}(6 帧 GelSight 图)转成软硬/粗糙的语言描述 L^m_t,反馈给规划器更新指令。
3. 触觉增强控制器(≈后顶叶):插值(BRIDGeR)控制器,把 VLA 生成的动作块 a_t 用视觉嵌入 + 触觉力 m_t 精修成 â_t。
两层是循环交替的:规划器出指令 → VLA 出动作块 → 控制器逐段精修执行 → 指令完成/超步后,Octopi 取触感转语言 → 规划器据此出下一条指令,直到目标达成(见下方 Algorithm 1)。
3. 方法详解¶
3.1 触觉辅助的任务规划(规划层)¶
- 循环规划:语言条件 VLM(GPT-4o)据目标+当前观测生成单句原子动作(一个动作、最多碰一个物体)+ "需要检索的信息";VLA 执行;完成或超最大步后触发 Octopi 取触感 → 转语言 → 喂回规划器出新指令。这套"高层规划 ↔ 低层控制"交替沿用已有 VLA 范式(π0/分层)。
- Prompt 设计(附录A):告诉 GPT-4o 它有"单臂+夹爪+触觉传感器(能分类软硬/粗糙/表面)",强制每步只回一个动作并等用户反馈,物体用空间方位(左/右)指代。
- Octopi:[35] 为 GelSight 预训练的触觉-语言模型,吃 6 帧触觉序列,推软硬、粗糙等属性并转语言。
- 力的特殊处理:Octopi 没有预训练做力估计,所以力走另一条路——用 marker tracking 算力向量,连同参考基准向量一起喂给 GPT-4o(参考值在力是相对/未归一化时当标定点)。
3.2 触觉精修 VLA 动作(控制层)¶
- base VLA:Robot Diffusion Transformer RDT-1B(方法对其它 VLA 也通用)。
- 为什么用 BRIDGeR 插值,而不是普通扩散:普通扩散从高斯噪声起步去噪;BRIDGeR 用随机插值(stochastic interpolant)从一个"有信息的源分布"出发——这里源分布就是VLA 生成的动作分布。因为 VLA 已经抓住了大部分目标行为,只缺触觉带来的精修 → 从它出发步数更少、效果更好。
- 数学上(附录C):
a_t = I(t,a_0,a_1,x) + γ(t)z,边界I(0)=a_0(源=VLA动作)、I(1)=a_1(目标=专家动作),γ(0)=γ(1)=0,z高斯噪声;前向 SDEda_t = b_F(t,a_t,x)dt + √(2ε(t))dW_t。 - 控制器
π_I(â | a, s_t, m_t):输入源动作块a(长度T_i ≤ T_a)、状态s_t(RGB + 本体感知)、触觉力m_t,输出精修动作块。 - 触觉表示
m_t:从 7×9 marker 位移算每点力向量,聚合成一个总力向量+幅值m_t=(X,Y,M)(学 Reactive Diffusion Policy [9] 的思路,但只用聚合力、不用逐 marker,降噪 + 更紧凑)。 - 训练:监督学习,配对集 = "VLA 生成动作 ↔ 专家动作"(从专家演示采状态,再让 VLA 在这些状态上生动作当源)。
- 推理:滑窗精修(Algorithm 1)——不重叠地逐段精修源动作块,执行完一段从上段终点接着下一段,直到整块精修完执行完。
Algorithm 1(伪代码精简):初始化指令
I_0(GPT-4o 据目标+场景图) → while 任务未完成:更新观测/触觉 → while 指令未完成:RDT 出动作块 → while 块未精修完:插值控制器精修T_r步 → 执行 → 更新观测;执行失败则 break 去重规划 → 取触感o^m_t→ Octopi 转语言L^m_t→ GPT-4o 据(g, 场景图, L^m_t, I_k)出下一条指令I_{k+1}。
3.3 实现细节(附录C,复现关键)¶
- 硬件:Franka Emika Panda + Robotiq 2F-140 夹爪,一根手指装 GelSight Mini(7×9 marker + 内置相机);2× RealSense(一台固定俯视当场景相机、一台腕装);推理在单卡 RTX 4090。
- 数据采集(动觉示教 kinesthetic teaching,10 Hz,含 2 路相机 + GelSight 图 + 末端位姿/夹爪态):
| 任务 | Pick 段 | 主任务段 | 时长 |
|---|---|---|---|
| Cup | 40 ep | Place 60 ep | 8 min |
| Wipe | 40 ep | Wipe 60 ep | 15 min |
| Peel | 60 ep | Peel 120 ep | 30 min |
- 训练流水(单 RTX4090):① 先在无关 Franka 数据上微调 RDT 对齐动作空间(100k 步,≈80 小时);② 在自采数据上微调 VLA(不带触觉模态),每任务 20k 步(≈16 小时);③ 用这个 VLA 在数据观测上生成动作块,配触觉构成
D_VLA训练插值控制器。T_a=64、n=2。 - 推理:取 VLA 生成的 64 步动作块的前 48 步做精修;控制器最高 8 Hz 更新/精修,精修动作由笛卡尔 PD 控制器以 8 Hz 执行(Mango Peeling 例外,用阻抗控制器)。
4. 实验¶
4.1 设置(三个真机接触任务,图2)¶
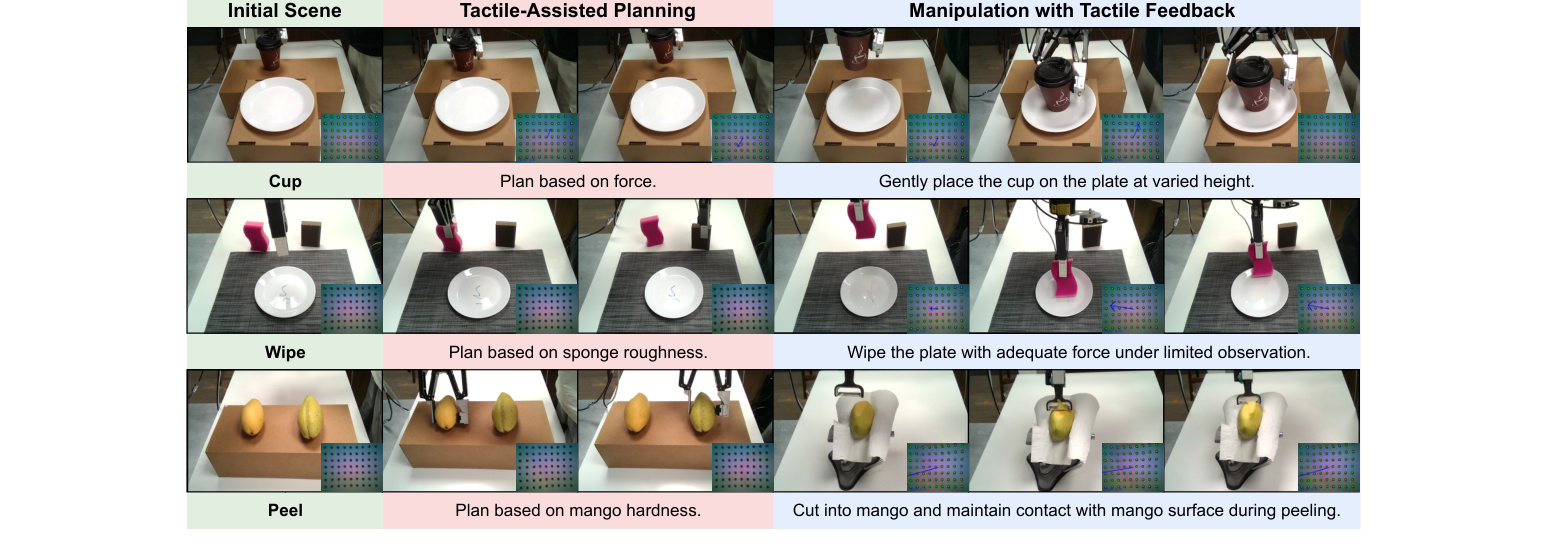
- Cup:拿起带盖杯,靠触觉判断是否有水,放到对应位置且不洒。
- Wipe:摸两块海绵选更光滑的,用它擦掉盘上的墨。
- Peel:摸两个芒果选更软/更硬的,用手持削皮器削选中的那个。
- 三个研究问题:Q1 触觉是否提升规划?语言化描述 vs 原始触觉图哪个更好?Q2 触觉是否帮控制?插值扩散 vs 简单残差控制器?Q3 双层 vs 只一层?
4.2 规划结果(图3,每条件 20 trials)¶
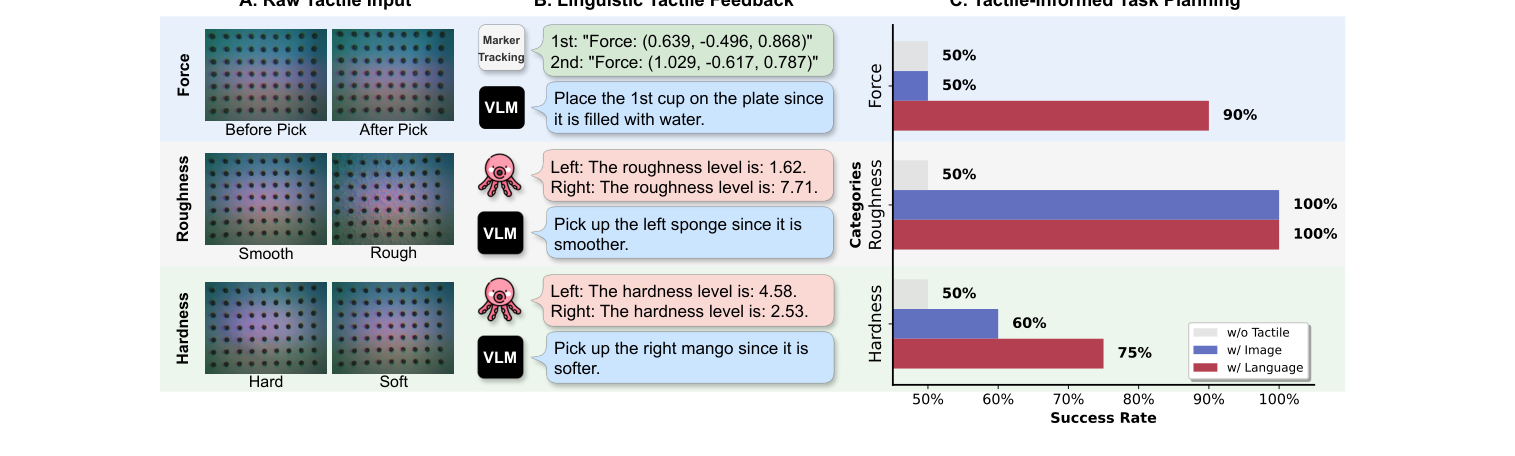
三种给 GPT-4o 的方式对比(成功率,越高越好):
| 属性 | 仅场景图(无触觉) | + 原始触觉图 | + Octopi 语言(本文) |
|---|---|---|---|
| 力 Force | 50%(≈瞎猜) | 50% | 90% |
| 粗糙 Roughness | 50% | 100% | 100% |
| 软硬 Hardness | 50% | 60% | 75% |
- 只给场景图,GPT-4o 对触觉属性直接摆烂("I can't determine"),逼它选就是随机水平(50%)。
- 给原始触觉图:粗糙度判得准(100%),但力(50%)、软硬(60%)弱。
- 给 Octopi 语言描述:力 90%、软硬 75% 大幅改善 → 结构化语言比原始触觉图更"可被 GPT-4o 用"。规划效率最高 +40%。
4.3 操作结果(Table 1,每格 x/20)¶
| 任务 | 评估阶段 | RDT | Residual | Interpolant(本文) | w/o Touch | w/o Vision |
|---|---|---|---|---|---|---|
| Cup | Pick | 9 | 7 | 12 | 10 | 10 |
| Cup | Place | 7 | 6 | 10 | 5 | 7 |
| Wipe | Pick | 11 | 15 | 17 | 15 | 15 |
| Wipe | Partial | 8 | 13 | 16 | 12 | 10 |
| Wipe | 完整 | 5 | 6 | 12 | 7 | 8 |
| Peel | Pick | 13 | 14 | 18 | 16 | 13 |
| Peel | Partial | 8 | 12 | 13 | 12 | 8 |
| Peel | 完整 | 6 | 7 | 10 | 5 | 5 |
- 插值控制器在所有任务所有指标上都最高。相对原始 RDT 提升:Cup +42% / Wipe +140% / Peel +67%;相对残差控制器:Cup +67% / Wipe +100% / Peel +42%。
- 作者解释:插值扩散能更好抓多模态动作分布;残差(LSTM)控制器学成"平均策略",会系统性偏移、在大芒果上提前抬刀。
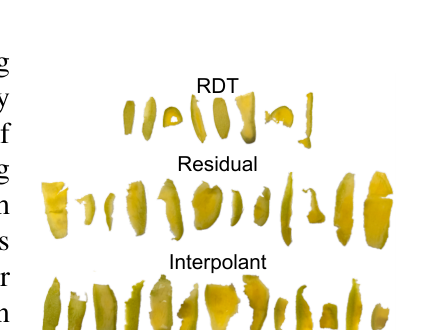
三任务只有 3 个、各 20 trials,样本偏小,读结论时记得。
4.4 双层消融(Table 2,x/20)¶
| 任务 | w/o Planning | w/o Control | VLA-Touch(双层) |
|---|---|---|---|
| Cup | 5 | 6 | 9 |
| Wipe | 5 | 5 | 12 |
| Peel | 6 | 4 | 7 |
- 去掉规划层触觉:Cup −44% / Wipe −58% / Peel −14%。
- 去掉控制层触觉:Cup −33% / Wipe −58% / Peel −43%。
- 结论:两层都不可少,缺一层都明显掉点。双层比"只一层"最高 +35%;操作成功率比纯视觉 VLA 最高 +35%。
4.5 控制器内部消融(多模态必要性,见 Table 1 末两列)¶
- 去触觉(w/o Touch):基本 pick 影响小,但接触密集阶段崩——Cup 放置 −50% / Wipe −42% / Peel −50%(控制器测不到接触力/摩擦/工具-物交互)。
- 去视觉(w/o Vision):退化较轻但明显——Cup 放置 −30%;Wipe 完整 12→8(抓到海绵边缘);Peel 完整 10→5。→ 视、触都要。
4.6 附录B 的"反直觉"读数(诚实)¶
- Octopi 原版把属性离散成类别(如粗糙=光滑/略糙/糙)以便对齐语言;但离散粒度太粗,分不出细微差别。
- 消融对比:(a) 用 Octopi 完整语言描述 vs (b) 直接用分类器的连续数值输出。Wipe(两海绵差异大)两者都 100%;Peel(软硬差异微妙):语言描述只 60%,连续数值 75%。
- 即:用自然语言表达触感会丢精度——这点和"语言化反馈更好用"的主线互相矛盾又互补,作者诚实地把它列在附录。
5. 核心洞见 / 未来¶
- 关键结论:把触觉拆到规划(语言化)+ 控制(力信号精修)两层、且都不重训 base VLA,就能拿到接触任务的明显增益;插值扩散从"VLA 动作分布"出发精修,比残差控制器更能吃多模态。
- 作者列的未来:① 主动抓取(视触觉联合动态调抓姿);② 事件触发推理(接触状态切换时才重推、稳定期省算力);③ 任务无关的精修方法以 scale 到更多任务;④ 更丰富的高/低层触觉形式(连续触觉嵌入而非语言)、规划器-TLM-控制器更紧耦合以降冗余/延迟。
6. 局限 / 存疑(诚实)¶
- 夹爪与 Octopi 预训练数据不一致 → 接触测量有偏,软硬判断尤其受影响(正文 §6 + 附录B 都点了)。
- 只验"跨位置/物体"泛化(杯高、墨迹、芒果个体),未验跨任务——跨任务要显著更多训练。
- 插值控制器仅 8 Hz,没吃上高频触觉(≥25 Hz)——动态接触下有提升空间(与 ② 事件触发互为伏笔)。
- 样本小:仅 3 个真机任务、各 20 trials;规划成功率也是 20 trials/条件。
- 开源程度:代码已开源(正文声明),但处理后数据需向作者申请,复现需自采/申请。
7. 对我们(深一层)¶
- 最契合"不重训 base VLA"取向、最可上手:想给现有 VLA(OpenVLA/π0)试触觉,首选这条——代码 + 依赖件(RDT-1B/Octopi/BRIDGeR)全开源,硬件用商用可得的 GelSight Mini。见 卡片-VLA-Touch 的可用性速判。
- 与内部路线的对照:
- 和 卡片-TacVLA 互补:VLA-Touch 是外挂精修(轻)、TacVLA 是改内部加 gating token(深);两者都指向"接触才触发"。
- 和 卡片-Tactile-VLA 对照:后者把触觉做进 VLA 内部端到端,本文坚持解耦不重训——两条路线正好两端。
- 机制可借:① 触觉双层拆分(语义层走语言、控制层走低维力)这套解耦很干净;② 用 BRIDGeR 从策略分布出发的插值扩散做"动作精修",是一个可迁到我们 base policy 的轻量加层思路。
- 它自己也想做"事件触发推理"——再次印证"接触才触发"是跨工作共识(呼应 TacVLA/TacForeSight 的 gating,与"触觉常开/当图片"路线相左)。
- 诚实点的价值:附录B"连续数值 > 语言描述(软硬)"提醒我们——别迷信把触觉一律翻成语言,细粒度场景保留数值/嵌入可能更好。