详读 · Consistency Policy(用一致性蒸馏给扩散策略提速一个数量级)¶
卡片版见 卡片-ConsistencyPolicy。本页是全文精读:动机 → 方法(逐模块公式直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2405.07503(v2, 2024-06-28,RSS 2024 会议论文)· 项目页 · 代码 作者:Aaditya Prasad、Kevin Lin、Linqi Zhou、Jeannette Bohg(斯坦福)+ Jimmy Wu(普林斯顿)。经费来自 Toyota Research Institute。
0. 一句话定位¶
把 Diffusion Policy 当教师,用图像生成里的一致性轨迹模型(CTM)蒸馏出一个单步/3 步的学生策略——推理从 DDPM 的 100 步去噪压到 1 步,在受限笔记本 GPU 上把延迟从约 192ms 降到约 21ms(≈9×),而成功率与 DDPM/DDiM 基本持平。目标场景:移动操作机器人、四旋翼等装不下高端 GPU、又要低延迟决策的平台。三个关键设计:一致性目标的选择(CTM-local)、降低初始采样方差、预设 chaining 步。
1. 问题与动机¶
- 扩散策略的硬伤 = 推理慢:扩散模型靠反复去噪出动作,每出一个动作要多次前向;步数越少质量越掉。Diffusion Policy 用 DDPM 100 步,在 NVIDIA T4 上约 1 秒/动作(3070Ti 上约 1.5 秒)。
- 这把扩散策略锁死在准静态任务(简单抓放、装配);动态任务(平衡物体、动态环境导航)需要更高控制频率;机载算力受限的机器人更跑不动。
- 目标:保住 Diffusion Policy 的性能,大幅砍掉推理时间。
- 为什么选蒸馏而非别的加速(见 §2 相关工作):
- 少步采样器(DDiM/EDM):可变步数,但推理步数一砍质量就掉(DDiM 9 步在 ToolHang 只剩 .14)。
- 并行采样(ParaDiGMS):用 Picard 迭代并行收敛 ODE 上的点,但显存暴涨;机器人现场算力本就被别的进程占用,实际加速会因 VRAM 受限而缩水,且仍慢于单步。
- 蒸馏:拿预训练教师教学生"迈大步",其中一致性模型这一支既能单步也能多步采样 → 本文采用。
2. 与相关加速路线的关系(取舍)¶
- DDPM:解的是反向 SDE(含布朗运动的随机去噪),固定 100+ 步,是 Diffusion Policy 里最慢的框架;但随机性带来多模态(后面局限会回收这一点)。
- DDiM:可解释为积分确定性 ODE,支持可变步数(训 100 推 15),但少步仍掉质量。
- EDM[Karras 2022]:同样积分确定性 ODE、允许少步,差别在 preconditioning 和 weighting。本文把教师从 DDPM 换成 EDM,因为 EDM 是一致性蒸馏更常用的多步框架。
- 一致性蒸馏谱系:Song 等[31] 的 Consistency Models(相邻点、都拉回 s=0)→ Kim 等[14] 的 CTM(任意非相邻点 t,u 拉回任意 s)。本文研究把 CTM 适配到机器人域。
- 同期 RL 工作[4,8] 也用一致性模型做状态控制,但 [8] 用的是 consistency training(用蒙特卡洛估计代替教师、免教师),本文实测它在高维图像策略上成功率不够(见表 X)。
- 为何只跟 Diffusion Policy 系比:原 Diffusion Policy 已打赢此前所有 IL 基线(含 Behavior Transformer);RT-1/RT-2 等靠大规模预训练、要跑云端,不符合本文"机载受限"设定,故不比。
3. 方法¶
3.1 预备:扩散的 ODE 视角¶
- 学一个把高斯噪声
x_T ~ N(0,I)映到专家动作x_0 ~ p0(x|o)的过程;t∈[0,T],t 大=更噪。 - 写成概率流 ODE(PFODE):
dx_t = [μ(x_t,t) − ½σ(t)²∇log p_t(x_t|o)] dt(式1)。EDM 取μ=0, σ(t)=√(2t)。 ∇log p_t是 score,不可解 → 用神经网络近似。一步去噪 = 在当前位置算 score 近似 + 数值积分。- 采噪声样本:
x_t = x + t·ε,ε~N(0,I);送进网络前归一化到单位方差。
3.2 教师模型(EDM)¶
- 教师
s_φ(x_t,t;o)按 EDM 训,用来估 PFODE 轨迹导数:dx_t/dt = −(x_t − s_φ(x_t,t;o))/t(式2)。 - 损失用 Denoising Score Matching(DSM):
L_DSM = E[d(x_0, s_φ(x_t,t;o))](式3)。 - 度量
d用 pseudo-Huber:d(x,y)=√(‖x−y‖² + c²) − c(式4),c = 0.00054·√D(D 为数据维度,沿用 Song[29])。它在 l1/l2 间架桥、比 EDM 原用的 l2 更抗离群。 - 数值积分用 Heun 二阶解法器,时间离散化沿用 EDM。
3.3 学生模型(Consistency Policy)= CTM 蒸馏(图2)¶
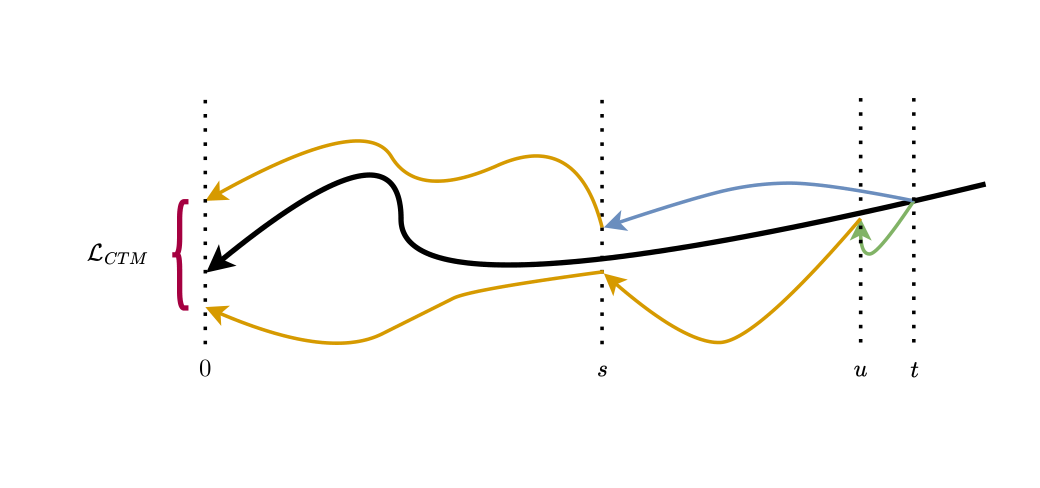
- 学生
g_θ(x_t, t, s; o):输入位置x_t、时间t、目标停步 s、观测o,输出对x_s(更早时刻)的估计。 - CTM 目标(直觉):同一条 PFODE 上的两点
(x_t,t)、(x_u,u)去噪到同一个x_s应当一致。流程: x_s^(t) = g_θ(x_t,t,s;o)(式6,唯一不加 stopgrad、回传梯度的一步)x_s^(u) = g_θ(x_u,u,s;o)(式7)- 把两者都再用
g_θ(·,s,0;o)拉回时刻 0,在全去噪动作空间算损失:L_CTM = d(g_θ(x_s^(t),s,0;o), g_θ(x_s^(u),s,0;o))(式5)。 - 教师怎么提供蒸馏信号:先采
x_t ~ N(0,t²I),再用教师 EDM 走t−u步得到x_u。 - 最终损失:
L_CP = α·L_CTM + β·L_DSM(式8)。α,β可调。 - 采样配方:让 t、u 相邻(即
u=t−1,"local consistency")效果最好(见表 V)。
3.4 推理:单步 vs 3 步¶
- 单步(最快):采
z ~ N(0,I),算x = g_θ(z,T,0;o),直接执行。 - 关键技巧——降初始方差:采
z~N(0,I)而非标准的N(0,T²I),让起点更靠近高斯均值、更在分布内、避免离群(呼应 Pearce[20]:模仿学习里不该把输出推离专家分布高似然中心)。见表 VI。 - 3 步(更准):链式细化——T→0 去噪,再加噪到
t1、去噪回 0,重复到t2。 - chaining 步怎么选(关键设计):图像扩散经验[7,11]说早-中段时间步贡献主要特征。本文按离散时间网格等分而非连续时间等分,三步链在
{t_{2N/3}, t_{N/3}}(N=总步数),自动聚焦早-中段。见表 VII。
3.5 实现细节¶
- 沿用 Diffusion Policy 的动作序列预测与 1D 卷积 UNet(FiLM 注入观测+时间步 t)。
- 学生在 UNet 基础上扩展 FiLM 块以接纳停步 s 的条件;用教师参数热启动,并把扩展的 FiLM 层零初始化避免拖慢热启动收敛。
- 选 UNet 而非 Diffusion Transformer,理由同 DP:Transformer 更难调超参;本方法与骨干正交,配好的 Transformer 应同样获益。
4. 实验¶
4.1 设置¶
- 6 个仿真任务 / 3 基准:Robomimic(Lift/Can/Square/ToolHang,4 个单臂任务,图像观测,每任务 200 条熟练人演示)、Push-T(状态观测,200 条演示)、Franka Kitchen(状态,566 条演示,长时多阶段)。

- 基线:Diffusion Policy 的 DDPM 与 DDiM 变体 + ParaDiGMS 并行采样。所有方法共用 UNet 架构、图像编码器、归一化、输入输出格式(2 帧观测:腕部相机图 + 第三人称图 + 末端位姿;输出末端位姿序列)。
- NFE 口径(关键且偏向基线):以 Number of Function Evaluations 衡量速度。DP 原用 DDPM 100 步、DDiM 15 步;本文把 ParaDiGMS 报告的加速比 3.7×(DDPM)/1.6×(DDiM)折算进去,得 DDPM 100/3.7≈27 NFE、DDiM 15/1.6≈9 NFE(向下取整)——即乐观假设并行加速不掉点,给基线最强待遇。
- 评测:用最佳 checkpoint 在线评 200 次 rollout 取均值±标准误(同 ParaDiGMS)。Push-T 报目标区域覆盖率。
4.2 仿真主结果(表 I:成功率 / Push-T 覆盖率)¶
| 方法 | NFE | Lift | Can | Square | ToolHang | Push-T |
|---|---|---|---|---|---|---|
| DDPM | 27 | 1.00 | .97±.01 | .93±.02 | .79±.03 | .87±.03 |
| DDiM | 9 | 1.00 | .82±.03 | .85±.03 | .14±.02 | .78±.03 |
| CP(ours) | 1 | 1.00 | .98±.01 | .92±.02 | .70±.03 | .82±.03 |
| CP(ours) | 3 | 1.00 | .95±.02 | .96±.01 | .77±.03 | .84±.03 |
单步 CP 在难任务(Square/ToolHang)成功率落在 DDPM 与 DDiM 之间,但快至少一个数量级。3 步 CP 普遍优于单步、与 DDPM 持平,且比 DDiM/DDPM 分别快 3×/9×。Can 上单步(.98)反超 3 步(.95)——简单任务上首步已够好,链式反而可能变差;ToolHang 上 3 步(.77)远超单步(.70)——难任务链式细化空间大。
4.3 Franka Kitchen(表 II:p_x = 完成 ≥x 个物体的频率)¶
| 方法 | NFE | p1 | p2 | p3 | p4 |
|---|---|---|---|---|---|
| DDPM | 27 | 1.00 | 1.00 | 1.00 | .98±.01 |
| DDiM | 9 | 1.00 | .98±.01 | .98±.01 | .93±.02 |
| CP(ours) | 1 | .99±.01 | .96±.01 | .95±.02 | .93±.02 |
| CP(ours) | 3 | .99±.01 | .96±.01 | .97±.01 | .94±.02 |
单步 CP 前两阶段强,后期长时阶段略掉(作者承认长时环境里 CP 学不好的机理需进一步探究)。
4.4 仿真推理速度(表 III,NVIDIA P5000,Square,50 rollouts 均值)¶
| 方法 | NFE | 推理时间(ms) |
|---|---|---|
| DDPM | 100 | 110 |
| DDiM | 15 | 11 |
| CP(ours) | 1 | 1 |
| CP(ours) | 3 | 2 |
注意此表用原始 NFE(未折 ParaDiGMS)。单步 CP 1ms,比 DDPM 快约百倍。
4.5 真实世界(3 任务)¶
- Trash Clean Up:捡垃圾→放进桶→关盖(图5,10 次试验,随机起点)。
- Plug Insertion:抓电源适配器→插入插座,接触密集、要精度(图6,20 次,随机起点,图像 256×256)。
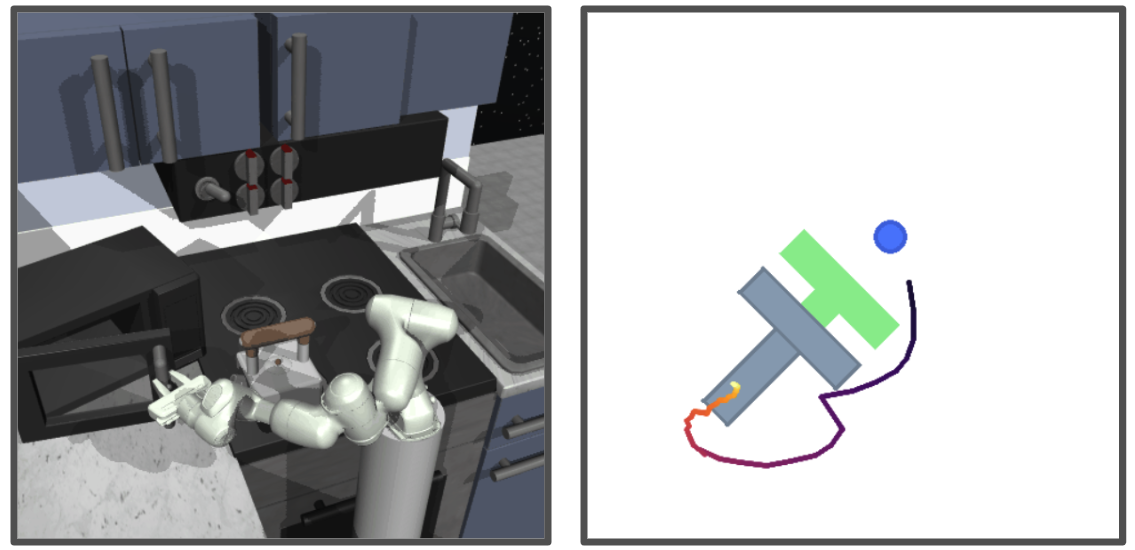
- Microwave(移动操作,Kinova Gen3 7-DoF + 全向移动底盘):开微波炉→取西兰花袋→放入→关门→按"蔬菜"键(图7,10 次,静态起点,长时 + 移动底盘控制)。
- 硬件:前两任务用笔记本单卡 3070 Ti(8GB)推理(ParaDiGMS 因显存跑不动);DDPM 100 步在该卡上约 1.5 秒/前向,故基线选更现实的 DDiM 15 步。动作序列长 16,每步 10D(3D 位置 + 6D 旋转 + 1D 夹爪);微波炉任务动作 13D。

表 IV:真实世界结果¶
| 任务 | DDiM 成功率 | DDiM 推理(ms) | CP 成功率 | CP 推理(ms) |
|---|---|---|---|---|
| Trash Clean Up | 0.8±.13 | 192 | 0.8±.13 | 21 |
| Plug Insertion | 0.6±.11 | 198 | 0.7±.10 | 22 |
| Microwave | 0.5±.16 | — | 0.4±.15 | — |
前两任务 CP 成功率持平/略高、延迟约 1/9;移动操作微波炉任务 CP 略低于 DDiM(见局限)。
4.6 消融全表¶
表 V — 一致性目标(Square):三种目标都保留辅助 DSM 项。
| 方法 | 成功率 |
|---|---|
| Consistency Distillation(相邻 t,u;s=0) | .88±.02 |
| CTM(任意 t,u,s) | .91±.02 |
| CTM-local(ours)(相邻 t,u;任意 s) | .92±.02 |
CTM 与 CTM-local 成功率相近、都略胜 Consistency Distillation;但 CTM 因 t→u 多步教师去噪而训练贵——即便限制 t−u≤10,CTM 仍比另两者慢 40%+(RTX A5000 实测)。故选 CTM-local:同样准、训练快。
表 VI — 初始采样方差(Square):
| 初始方差 | 1 步 | 3 步 |
|---|---|---|
| 1(原始) | .9±.02 | .91±.02 |
| 1/T²(ours,低方差) | .92±.02 | .96±.01 |
低方差两种都更好,对 3 步增益更大(步间再加噪能保住表达力/多模态)。
表 VII — chaining 步划分(3 步):
| 划分方式 | Square | Tool Hang |
|---|---|---|
| 离散时间等分(ours) | .96±.01 | .77±.03 |
| 连续时间等分 | .94±.02 | .72±.03 |
离散等分在难任务 ToolHang 上明显更好。
表 VIII — 对教师质量的鲁棒性(Square):
| 教师成功率 | 学生成功率 |
|---|---|
| .92±.02 | .92±.02 |
| .88±.03 | .92±.02 |
| .84±.03 | .88±.03 |
教师变差,学生只轻微相关下滑——因为 DSM 项(式3)与教师无关能托底。对"现场没法充分测教师"的部署很友好。
表 IX — 去掉 s→0 段的 dropout(Square):
| dropout | 成功率 |
|---|---|
| 启用 | .92±.02 |
| 仅 s→0 段禁用 | .86±.03 |
反直觉发现:dropout 在 CTM 目标里贡献了大部分一致性信号。机理:热启动后
g_θ太强,x_s^(t)、x_s^(u)即便不在同一轨迹也会被 s→0 段拉到几乎相同输出 →L_CTM趋零、无信号(实测无 dropout 时d(x_s^(t),x_s^(u))比拉回 0 后的差大两个数量级以上)。dropout 让 s→0 段不再确定性、迫使损失直接约束d(x_s^(t),x_s^(u))自一致。全文 dropout=0.2。
表 X — Consistency Training(免教师,单步):
| 方法 | Lift | Square |
|---|---|---|
| CT Policy([8] 风格,蒙特卡洛代教师) | .91±.02 | .55±.04 |
| CP(ours) | 1.0 | .92±.02 |
免教师的 consistency training 在简单 Lift 尚可,高维难任务 Square 崩到 .55——证明在图像策略上蒸馏 > 免教师训练。
表 XI(附录 A)— 真实推理时间拆解(3070 Ti):
| 方法 | 图像编码(ms) | 网络前向(ms) | 总推理(ms) |
|---|---|---|---|
| DDiM | 6 | 179 | 192 |
| CP(ours) | 6 | 13.5 | 21 |
总加速 9×,但网络部分加速 13.3×(接近 15× 的步数比);总加速被图像编码、数据搬运等固定开销拉低。策略网络占比越大,本方法越划算。
4.7 附录 B — 低方差采样的机理探究¶
作者在 CIFAR-10 上跑 EDM 验证:低方差初始区在图像域几乎无学到的 support(生成出灰块,图8),高方差区正常(图9)。猜测:机器人动作维度(h×10,h=动作时域)远低于图像(32×32×3),按流形假设动作流形更低维,score 模型只在足够低维流形上才支持低方差中心区;高维高斯质量集中在边缘、中心 support 弱。这解释了"降初始方差"为何对机器人有效、对图像可能无效。
5. 局限 / 存疑(作者诚实点的 + 精读补充)¶
- 牺牲多模态:DDPM 的多模态来自积分 SDE(随机);EDM/CTM 学的是确定性 ODE,蒸馏后教师 EDM 与学生 CP 都丢了部分多模态(Push-T 上偏向一侧)。作者称在标准评测任务上没受伤,未来想用更复杂采样找回多模态。→ 与 详读-DiffusionPolicy 强调的"多模态是扩散策略卖点"形成直接张力。
- 训练不如 DP 稳:一致性目标自指(式5),训练略不稳。
- 训练更慢:CP 要先训教师、每步还要跑教师 + 多次学生前向;达到 DP 同等性能需更多 epoch、更长每 epoch,难任务(微波炉)尤甚。用推理时间换训练时间。
- 移动操作偏弱:微波炉任务 CP(.4) < DDiM(.5);且作者坦承因时间限制没把 CP 训到收敛。
- 长时任务后期掉点(表 II p3/p4)机理未明。
- 基线口径偏向自己有利也偏向基线:把 ParaDiGMS 加速乐观地折进 DDPM/DDiM 的 NFE(假设并行不掉点),是"给基线最强待遇"——结论"仍快一个数量级"因此更稳。
6. 核心洞见¶
- 加速扩散策略最实用的一招 = 蒸馏成单步,且与具体扩散策略形式正交——理论上 Octo 这类扩散策略也能照样蒸馏成单/少步(作者列为未来方向)。
- 三个让它真正 work 的工程决策:① 一致性目标用 CTM-local(同 CTM 准、训练快 40%);② 降初始方差到 1/T²(更在分布内);③ 离散时间等分的预设 chaining(早-中段聚焦、开箱即用,免去每任务调链步)。
- dropout 的意外角色:在 CTM 里它不是防过拟合,而是一致性信号的主要来源——一个值得别的蒸馏工作注意的反直觉机理。
- 对教师质量鲁棒(DSM 托底):实践上不必反复挑最优教师,降低部署门槛。
7. 🗣️ 外部评价¶
- 🌐 正式发表于 RSS 2024(Robotics: Science and Systems,机器人顶会,经同行评审):官方论文 PDF、arXiv abs。RSS 不公开评审意见,未检索到公开的逐条 review 文本(如实记录)。
- 🌐 被后续工作当作"单步/少步策略"的代表基准引用:如 ConRFT(用 consistency policy 做 VLA 强化微调,arXiv 2502.05450)、One-Step Flow Policy Mirror Descent(arXiv 2507.23675)、OMP One-step MeanFlow Policy(arXiv 2512.19347)等都把它列为"扩散策略一步化"的参照点。
- 🌐 收录于多个机器人论文阅读清单(如 YanjieZe/Paper-List)。
- 🧑(精读者 ding 看法):方法本身是把图像生成成熟技术(CTM)干净地搬到机器人域,贡献偏"适配 + 工程决策 + 机理观察"而非全新理论;卖点是"实测能在笔记本 GPU 实时"这件落地事,证据扎实(9 任务 + 全消融 + 真实部署),但多模态损失和训练更慢是后续流匹配单步路线(如 MeanFlow Policy)想绕开的点。
8. 🧑⚖️ 审稿人视角(🤖)¶
- 新颖性中等:CTM[14]、EDM[13]、低方差采样思路均来自图像域;核心增量是"适配机器人 + 三个设计决策 + dropout 机理"。作者也坦诚定位为 adaptation,没硬吹。
- 实验充分:6 仿真 + 3 真实 + 8 张消融表,且对教师质量鲁棒性这种"部署相关"问题做了专门实验,加分。
- 基线口径需警惕但处理得当:把 ParaDiGMS 加速折进 NFE 是"乐观给基线",明确写出,结论不被夸大。
- 可改进:① Push-T 多模态丢失只定性提及,缺定量(如模式覆盖率);② 移动操作任务"没训到收敛"使该结论说服力打折;③ 单步在 ToolHang(.70) 明显弱于 DDPM(.79),"competitive"措辞略宽松。
- 可复现性高:开源代码 + 项目页 + 沿用 DP 基础设施 → 证据等级 A。
9. 对我们¶
- 扩散/流策略提速"两条路"的蒸馏代表:与 卡片-AdaFlow(方差自适应 ODE、按需调步、免蒸馏)构成对照——一个训练期蒸馏成定步单步、一个推理期自适应变步。两条路都为"把生成式策略上实时控制"服务。
- 母本是 详读-DiffusionPolicy:本工作把 DP 当教师,读懂 DP 的 receding-horizon / 动作序列 / UNet 设计是读懂本文的前提;本文把 DP 的"慢"这一局限(DP 详读 §7 已点名指向"Consistency/一步扩散")真正补上。
- 可借的工程招式:① 教师→单步学生蒸馏流程可直接套我们自己的扩散/流策略;② 降初始方差到 1/T² 是低成本即插即用的推理改进;③ 离散时间等分 chaining、CTM-local 都是省调参的默认配方;④ dropout 作为一致性信号来源这一观察,提醒蒸馏时别随手关 dropout。
- 与流匹配单步路线对照:本文的"丢多模态 + 训练慢"正是后续 MeanFlow / 一步流策略(卡片-AdaFlow 之外)想改进的靶子,值得把它作为"蒸馏路线基线"长期对照。