详读 · DINO-WM(在预训练视觉特征上学世界模型 → 零样本规划)¶
卡片版见 卡片-DINO-WM。本页是全文精读:动机 → 逐模块方法 → 全量数字 → 局限/洞见 → 外部评价 → 审稿人视角 → 对我们。 来源:arXiv 2411.04983(v2, 2025-02-01)· 项目页 · 作者:Gaoyue Zhou、Hengkai Pan、Yann LeCun、Lerrel Pinto(NYU Courant + Meta AI) 发表轨迹:ICLR 2025 被拒 → ICML 2025 录用(PMLR v267)。详见下方「外部评价」。
0. 一句话定位¶
不在像素上重建未来,而是在冻结的 DINOv2 patch 特征空间里学一个动作条件的动力学模型(去 token 化的 causal ViT),训练只需离线轨迹、只用一个潜空间一致性损失;测试时把"到达目标图"变成在潜空间里用 MPC + CEM 优化动作序列——从而零样本规划:无需专家示范、无需奖励、无需预训练逆模型。
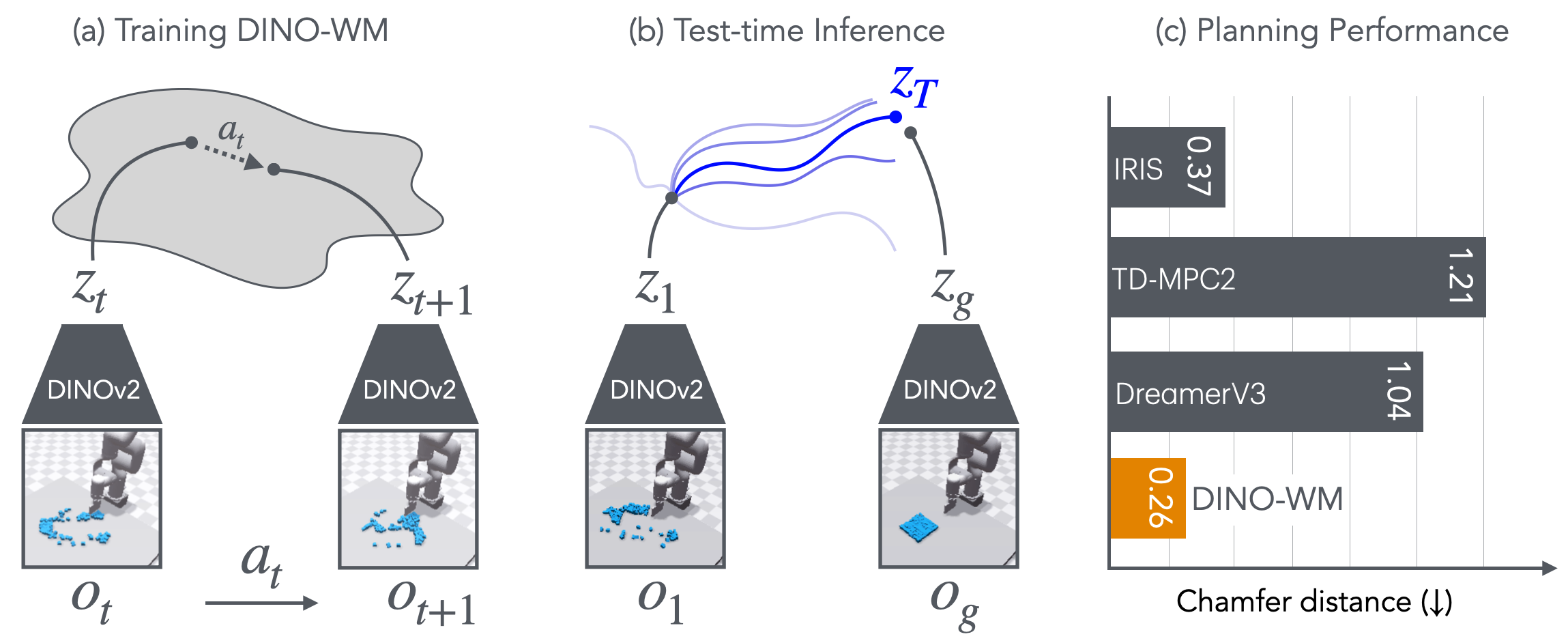
1. 动机:好的离线世界模型应该满足三条¶
作者主张世界模型要真正通用,应:① 能在离线、预采集轨迹上训练;② 支持测试时行为优化(test-time optimization);③ 支持任务无关推理(task-agnostic)。
现有两条路线都不够: - 在线 world model(DreamerV3、TD-MPC2):模型只在被优化策略覆盖的区域准确,每换一个任务就要重训;且常把奖励/折扣/终止条件等任务相关信息塞进表征,使模型天然 task-specific。 - 离线 world model:去掉了任务依赖,但解任务时通常要强辅助信息——专家示范、结构化关键点、预训练逆模型、稠密奖励——这些又牺牲了通用性。 - 中心问题:有没有一种辅助信息,能帮离线世界模型解任务、又不损通用性? DINO-WM 的答案是——用预训练视觉特征(DINOv2 patch)作为建模空间,把"感知"这件通用的事外包给大规模预训练,从而放松对任务特定数据覆盖的依赖。
同时反对"生成式视频模型即世界模型":扩散视频模型靠文本条件、计算昂贵、单步可产生不合物理的大跳变,难以精确到达视觉目标、也难配合 MPC 这类测试时优化。
2. 方法逐模块¶
整体是 POMDP (O, A, p),目标是学 p(o_{t+1}|o_≤t, a_≤t)。三个组件(参数统称 θ):
- 观测模型 z_t ~ enc_θ(z_t|o_t):就是冻结的 DINOv2,全程不训练。把图像编码成 patch 嵌入 z_t ∈ R^{N×E}。
- 转移模型 z_{t+1} ~ p_θ(z_{t+1}|z_{t−H:t}, a_{t−H:t}):可训练的 ViT。
- 解码器 ô_t ~ q_θ(o_t|z_t):可选,仅用于可视化/可解释,训练与转移模型完全解耦。
2.1 观测模型 = 冻结 DINOv2(不重建)¶
论点:感知是通用任务、受益于大规模互联网数据,给新环境从零学观测模型既低效又常不可行。故直接用 DINOv2 patch 特征(带空间 + 物体中心先验),冻结。这是与 DreamerV3 等"为当前任务学观测模型"的根本分歧。
2.2 转移模型 = 去 token 化的 causal ViT¶
- 用 ViT 处理 patch 特征,去掉 tokenization 层(输入已是 patch 嵌入)→ 变成 decoder-only transformer。
- 帧级 causal attention(关键设计):latent
z_t的每个 patch 向量z_t^i只 attend 到历史{z_{t−H:t−1}^i}。与 IRIS 的区别:IRIS 在 token 级自回归(还要 attend 同帧已生成的前 k 个 token),DINO-WM 把一帧的所有 patch 当整体一次预测,作者认为更能抓全局结构与时序动力学,时序泛化更好(消融见 §3.4 表6)。 - 动作 / 本体条件:把 K 维动作经 MLP 升维后拼接到每个 patch 向量
z_t^i;有本体感(proprioception)时同样拼接进 latent。 - 训练 = teacher forcing + 潜空间一致性损失(无像素重建):把轨迹切成长 H+1 的片段,对每个预测帧计算
L_pred = ‖ p_θ(enc_θ(o_{t−H:t}), ϕ(a_{t−H:t})) − enc_θ(o_{t+1}) ‖²
其中 ϕ 是动作编码器。整个世界模型训练完全在潜空间,不重建任何像素。
2.3 解码器(只为可解释)¶
转置卷积栈把 patch 表征解回像素,损失 L_rec = ‖q_θ(z_t) − o_t‖²。与转移模型独立训练:① 不影响世界模型的推理/规划能力;② 规划时无需重建像素、省算力。作者还消融了"把解码器损失反传给预测器"——发现反而掉点(§3.4 表7),印证"特征学习与重建目标解耦"更好。
2.4 测试时规划(visual goal reaching)¶
- 输入当前观测
o_0与目标图o_g(都编码到潜空间),规划 = 找动作序列让末态逼近目标:C = ‖ẑ_T − z_g‖²,其中ẑ_t = p(ẑ_{t−1}, a_{t−1}),ẑ_0 = enc(o_0),z_g = enc(o_g)。 - 用 MPC + 交叉熵方法(CEM) 优化动作(采样→选 top-K→更新分布→重采样→执行前 k 个动作→滚动重规划)。
- 因模型可微,也试了梯度下降(GD)直接优化动作;但CEM 经验上更好(§3.4 表8:GD 仅 0.22/0.28,远低于 CEM/MPC)。
- 规划方法本身是标准件——作者强调它们只是度量世界模型质量的手段。
3. 实验与全量数字¶
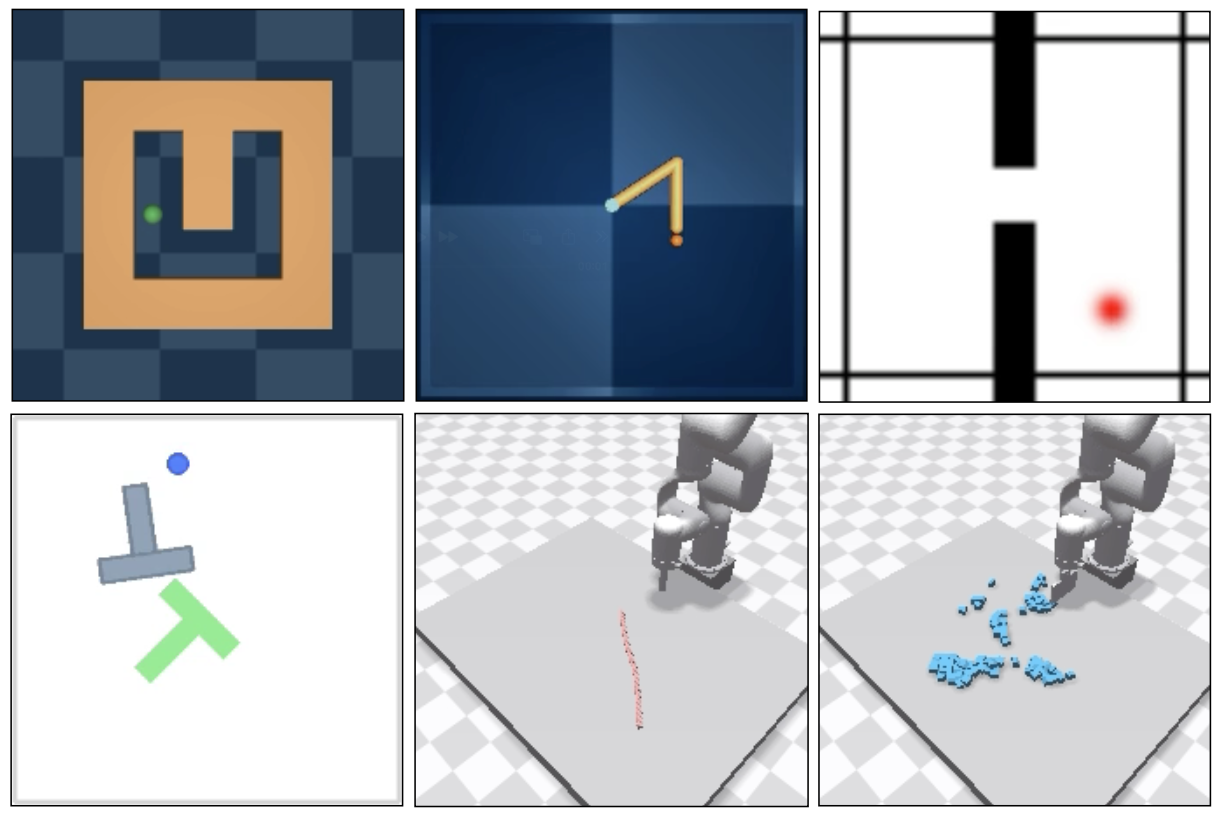
3.1 六个环境¶
Maze(PointMaze,D4RL 2-DoF 球导航)、Wall(双房间过门)、Reach(DM Control 2 关节臂,要求整臂匹配位姿)、Push-T(推 T 块,接触密集)、Rope(XArm 推软绳,Flex 仿真)、Granular(约一百颗粒聚成形状)。观测均为 224×224 RGB。导航/Reach/PushT 用成功率 SR↑(采 50 对起止态);Rope/Granular 因仿真慢用 Chamfer 距离 CD↓(10 实例)。
3.2 主结果:六环境规划(表1)¶
| Model | Maze SR↑ | Wall SR↑ | Reach SR↑ | PushT SR↑ | Rope CD↓ | Granular CD↓ |
|---|---|---|---|---|---|---|
| IRIS | 0.74 | 0.04 | 0.18 | 0.32 | 1.11 | 0.37 |
| DreamerV3 | 1.00 | 1.00 | 0.64 | 0.30 | 2.49 | 1.05 |
| TD-MPC2 | 0.00 | 0.00 | 0.00 | 0.00 | 2.52 | 1.21 |
| Ours (DINO-WM) | 0.98 | 0.96 | 0.92 | 0.90 | 0.41 | 0.26 |
读数:简单环境(Maze/Wall)与 DreamerV3 持平;在接触/形变密集的 Reach/PushT/Rope/Granular 上大幅领先。TD-MPC2 全 0——因去掉奖励信号后它学不出可用潜表征(其设计依赖奖励)。论文摘要称在最难任务上规划成功率平均超过既有工作 45%。
3.3 预训练编码器的作用(表2)+ 泛化(表3)¶
把观测模型换成不同预训练编码器(其余不变):
| Model | Maze | Wall | Reach | PushT | Rope CD↓ | Granular CD↓ |
|---|---|---|---|---|---|---|
| R3M | 0.94 | 0.34 | 0.40 | 0.42 | 1.13 | 0.95 |
| ResNet(ImageNet) | 0.98 | 0.12 | 0.06 | 0.20 | 1.08 | 0.90 |
| DINO CLS | 0.96 | 0.58 | 0.60 | 0.44 | 0.84 | 0.79 |
| DINO Patch (Ours) | 0.98 | 0.96 | 0.92 | 0.90 | 0.41 | 0.26 |
结论:简单 Maze 大家都接近满分;一旦需要精细控制与空间理解,把图像压成单个全局向量的编码器(R3M/ResNet/DINO CLS)显著掉点——patch 表征保留空间信息才是关键(不是"用了 DINO"本身,而是"用 patch")。
未见配置泛化(WallRandom 随机墙/门、PushObj 训 4 形测 2 新形、GranularRandom 粒子数减半):
| Model | WallRandom SR↑ | PushObj SR↑ | GranularRandom CD↓ |
|---|---|---|---|
| IRIS | 0.06 | 0.14 | 0.86 |
| DreamerV3 | 0.76 | 0.18 | 1.53 |
| R3M | 0.40 | 0.16 | 1.12 |
| ResNet | 0.40 | 0.14 | 0.98 |
| DINO CLS | 0.64 | 0.18 | 1.36 |
| Ours | 0.82 | 0.34 | 0.63 |
WallRandom 明显最好(学到了"墙/门"的一般概念);PushObj 对所有方法都难(只训了 4 种形状,难推断新形物理参数)——作者诚实点出这是共同短板。
3.4 预测质量 + 关键消融¶
LPIPS↓(解码后预测帧 vs 真值,越低越像;摘要称最难任务上比 SOTA 改善 56%):
| Method | PushT | Wall | Rope | Granular |
|---|---|---|---|---|
| R3M | 0.045 | 0.008 | 0.023 | 0.080 |
| ResNet | 0.063 | 0.002 | 0.025 | 0.080 |
| DINO CLS | 0.039 | 0.004 | 0.029 | 0.086 |
| AVDC | 0.046 | 0.030 | 0.060 | 0.106 |
| Ours | 0.007 | 0.0016 | 0.009 | 0.035 |
数据规模 scaling(PushT,表5):
| 数据量 | SR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|
| n=200 | 0.08 | 0.949 | 0.056 |
| n=1000 | 0.48 | 0.973 | 0.013 |
| n=5000 | 0.72 | 0.981 | 0.007 |
| n=10000 | 0.88 | 0.984 | 0.006 |
| n=18500 | 0.92 | 0.987 | 0.005 |
causal mask 消融(PushT,随历史长度 h,表6):
| h=1 | h=2 | h=3 | |
|---|---|---|---|
| w/o mask | 0.76 | 0.36 | 0.08 |
| with mask | 0.76 | 0.88 | 0.92 |
无 mask 时模型训练能"偷看未来帧",h 一长就崩(0.08);加 mask 后历史越长越好。
其他关键数字: - 解码器损失反传:w/o decoder loss 0.92 vs with 0.80(表7,解耦更好)。 - 规划器(表8):CEM 0.8/0.86/0.74(Maze/PushT/Wall),GD 仅 0.22/0.28,MPC(CEM+滚动重规划)0.98/0.90/0.96。 - 推理/规划时间(A6000,表10):单步推理 0.014s(batch32)、仿真单步 rollout 3.0s、CEM 规划(100 样本×10 步)53.0s → 形变环境里相对真实仿真大幅加速。 - 架构(A.9):DINOv2 出 (14×14, 384) 特征(输入 resize 196×196);ViT 主干 depth=6、16 头、MLP 2048、约 19M 参数;动作 emb 维 10;AdamW,predictor lr 5e-5、decoder lr 3e-4、100 epoch、batch 32;各环境同一套超参,仅 H 与 frameskip 不同(多数 H=3 frameskip=5;Wall/Rope/Granular H=1)。
3.5 与生成式视频模型对比(定性,图6)¶
对比扩散式 AVDC:AVDC 能生成视觉逼真的未来,但缺物理合理性(单步大跳变、到不了精确目标态);其动作条件变体在长程也会偏离真值。


4. 局限(作者自述 + 通读)¶
- 依赖足够覆盖的离线数据集:复杂环境难采全;作者建议未来配探索策略 + 在线更新。
- 仍需真值动作:训练要 (o, a) 配对,难直接吃海量纯视频(无动作)。
- 只在动作空间规划:未来可加分层(高层规划 + 低层控制)解更精细任务。
- 通读补充:评测环境多为 2D / 简单 3D(审稿人指其"本质 2D");规划 53s/次对反应式实时控制偏慢;冻结 DINOv2 意味着遇到与互联网图像差异极大的域(特殊传感器/夜视等)可能失配;无真机实验,全在仿真。
5. 核心洞见¶
- "世界模型不必做像素重建":在冻结的通用视觉特征上学动力学,省掉解码、更稳更省算,且把表征与任务/重建解耦后泛化更好。
- 真正起作用的是 patch(空间)特征,不是"用 DINO"这个品牌——CLS 全局向量同样掉点。这条对"该用什么表征建世界模型"很有指导性。
- 把通用性问题转化为表征问题:用预训练感知替代"任务特定数据覆盖/奖励/逆模型",是离线世界模型走向 task-agnostic 的一条干净路线。
🗣️ 外部评价¶
- 🌐 ICLR 2025 被拒(OpenReview forum GARbxyCV13)。四位审稿人评分 6 / 6 / 6 / 5(rating),soundness 普遍 3、presentation 2–3、contribution 多为 2。元审稿(meta-review)给 Reject,核心理由:"贡献声明与实际分析脱节"——论文指出离线世界建模的痛点(需辅助目标/数据覆盖),但没有严格论证 DINOv2 特征为何能提供好的规划空间,"实证显示 DINOv2 特征有效,却没分析为什么这些特征是好的规划空间",且担心方法是否真解决了覆盖难题、还是"因无关原因而成功"。
- 🌐 审稿人共性批评(同上链接):基准多样性不足、缺 DMControl/RoboMimic/MetaWorld 等标准 RL/机器人基准;评测基本是 2D 任务;baseline 不公平(TD-MPC2 在去奖励设定下评测、其余 baseline 未换用 DINOv2 编码器);"先进性有限"(潜空间世界模型 + 预训练视觉并非全新);缺与扩散方法(AVDC)的定量对比与推理速度分析。审稿人也认可其简单可扩展、零样本测试时规划、形变任务预测质量高。
- 🌐 ICML 2025 录用(PMLR v267 / proceedings.mlr.press/v267/zhou25t.html,ACM DL 10.5555/3780338.3783523)。即同一工作先被 ICLR 拒、后被 ICML 收——可见社区对其评价处于"扎实但理论解释偏弱"的边界地带。
- 🧑 作者自报:代码与模型开源(dino-wm.github.io),声称最难任务规划 SR 平均 +45%、LPIPS +56%。
🧑⚖️ 审稿人视角(🤖)¶
- 贡献:把"冻结预训练 patch 特征 + 动作条件 causal ViT + 测试时 MPC"组合成一个干净的离线、任务无关世界模型范式;最大经验贡献是证明patch(而非全局)特征 + 不重建能在接触/形变任务上显著超过 DreamerV3/IRIS/TD-MPC2。
- 扎实度:实验面较广(6 环境 + 3 泛化套件 + scaling + 多项消融 + 推理时延),消融(mask、解码器损失、CEM vs GD、编码器对比)支撑了核心设计选择,数字自洽。
- 薄弱点:① 缺机理解释——为何 DINOv2 patch 是好的规划空间,只有结果没有分析(元审稿的主刀点);② 基准偏 2D/仿真,无真机、无标准 RL 基准;③ baseline 公平性有争议(去奖励评 TD-MPC2、baseline 未统一换 DINOv2);④ "passive/offline data"的叙事与"仍需真值动作"存在张力。
- 显著性:高。作为 LeCun/Pinto 系"非重建世界模型"的代表作,对后续 卡片-NWM、JEPA 系工作有承接意义,影响力(引用/复现)已超出其会议命运。
- 可复现:较好——开源代码/模型、超参齐全、用公开基准(D4RL/DMC/PushT),但形变环境依赖 Flex、规划耗时长。
- 综合评级(🤖):B+ / 弱接收。想法干净、工程扎实、经验说服力强;扣分在理论解释薄、评测局限于仿真 2D、baseline 公平性——恰与真实审稿轨迹(ICLR 拒 / ICML 收)吻合。
6. 对我们¶
- 同生态对照:与 卡片-NWM(Navigation World Model,同 LeCun/NYU 系)一脉——都走"潜空间预测、测试时规划、少/无奖励"。DINO-WM 是"通用控制 + 形变操作",NWM 偏"导航";可并列看 LeCun 系世界模型的两个落点。
- 与 卡片-LaWAM 的关系:若 LaWAM 关注"语言/动作潜空间世界模型",DINO-WM 提供了一个纯视觉、无语言条件的对照点——它特意反对"靠文本条件的生成式视频当世界模型",主张精确视觉目标用潜空间 MPC 更可控。两者对"世界模型该不该绑语言/该不该重建"的取舍正好相反,值得做立场对照。
- 可借机制:① 冻结预训练 patch 特征 + 只做潜空间一致性损失——给我们自己的世界模型省掉解码器与像素监督;② 帧级 causal mask 这个小设计对带历史的时序预测很实用(防训练偷看未来);③ CEM-MPC 在潜空间规划作为"用世界模型解任务"的标准评测手段。
- 教训:好工作也会因"只给结果不给机理"在顶会被拒——我们写自己的方法时,对"为什么这个表征/设计有效"的分析要补够,别只堆 SOTA 数字。