详读 · NWM(Navigation World Models / 导航世界模型)¶
卡片版见 卡片-NWM。本页是全文精读:动机 → 逐模块方法(CDiT 条件扩散 Transformer / 能量函数规划) → 全量数字表 → 局限 → 洞见 → 外部评价 → 审稿人视角 → 对我们。 来源:arXiv 2412.03572(v2, 2025-04-11)· 项目页 作者:Amir Bar¹、Gaoyue Zhou²、Danny Tran³、Trevor Darrell³、Yann LeCun¹²(¹FAIR at Meta ²NYU ³Berkeley AI Research)
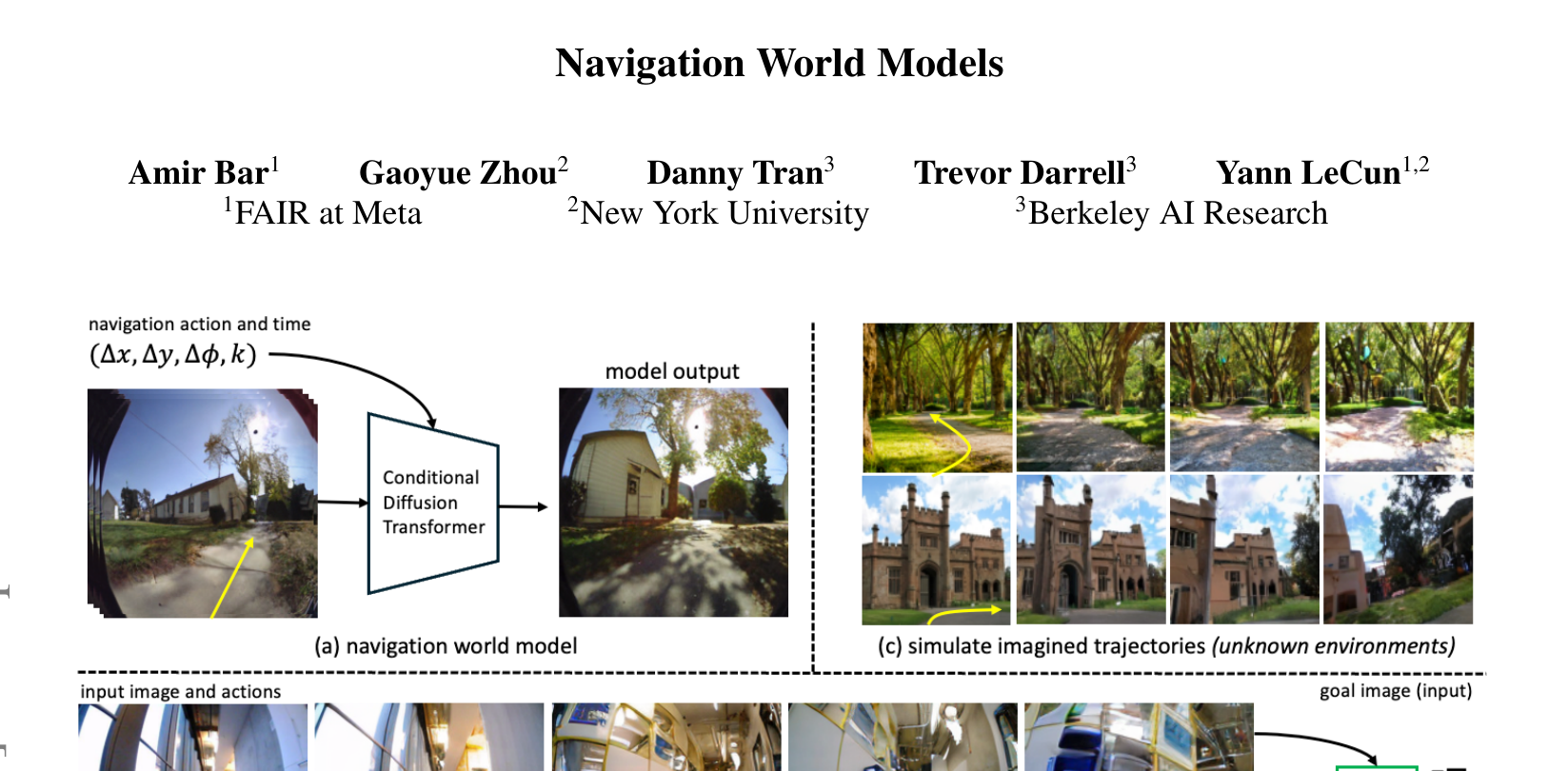
0. 一句话定位¶
把"给定当前画面 + 一个导航动作 → 预测下一帧画面"训练成一个 1B 参数的条件扩散 Transformer(CDiT),于是导航不再靠"固定策略输出动作",而是在想象里 rollout 多条轨迹、用末帧和目标图的感知相似度打分、挑最优(MPC + 交叉熵法)。已知环境里"模拟"轨迹、陌生环境里从单张图"想象"路径。是 卡片-DINO-WM 的"导航域 + 像素生成版"对照物。
1. 问题与动机¶
- 当前 SOTA 视觉导航策略(GNM[53]、NoMaD[55])是"硬编码"的:训练完行为就定死,无法事后加约束(如"不准左转")。
- 监督式导航策略不能按难度动态分配算力——简单/困难场景一视同仁。
- 人类规划时会想象未来轨迹、考虑约束与反事实(counterfactual)。NWM 想把这种"想象 + 验证"能力做进模型:用世界模型模拟候选轨迹并验证是否到目标,约束可在规划时动态注入。
- 与 DIAMOND[1]、GameNGen[66] 等扩散世界模型同源,但关键差异:NWM 跨多环境 / 多本体(human + robot)训练单一大模型,不用任务/动作 embedding(区别于 TD-MPC2[22])。也借鉴 NVS(NeRF/Zero-1-2-3/GCD),但不依赖任何 3D 先验,纯从自然视频学时序动态。
2. 形式化(Formulation)¶
- 数据:egocentric 视频 + 导航动作
D={(x₀,a₀,...,x_T,a_T)}。动作aᵢ=(u,ϕ):u∈R²控制前后/左右平移,ϕ∈R控制 yaw 偏航角(假设平地、pitch/roll 固定,可自然扩到 3D)。 - 学一个随机映射 world model
F:从过去 m 帧 latentsτ和动作aτ→ 未来 latentsτ₊₁,即sτ₊₁ ∼ Fθ(sτ₊₁ | sτ, aτ)。latent 来自预训练 Stable Diffusion VAE(压缩 latent,可解码回像素做可视化)。 - 时间位移 k(关键设计):把动作扩成
aτ=(u,ϕ,k),k∈[T_min,T_max],指定"往未来/过去走几步"。则平移/旋转是 τ→m(m=τ+k−1)的累加(公式2):u_{τ→m}=Σuₜ,ϕ_{τ→m}=Σϕₜ mod 2π。实践允许 ±16 秒时移。→ 同时学"动作"和"环境时序动态"。 - 动作-时间纠缠问题:若到某地点总在某时刻发生,模型可能只看时间忽略动作(或反之)。对策:训练时每个状态采多个目标(goals),制造"同地点不同时刻"的自然反事实。
3. CDiT:条件扩散 Transformer(核心创新)¶
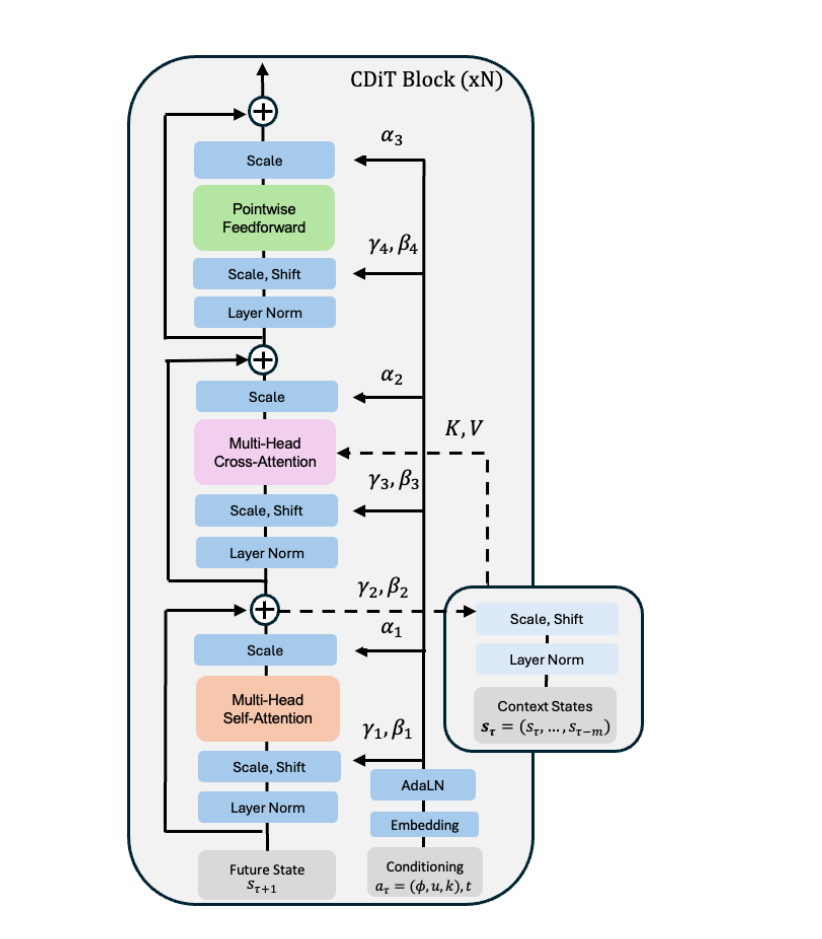
3.1 为什么不用普通 DiT¶
- 普通 DiT[44] 把所有上下文 token 全喂进去做 self-attention:复杂度被
O(m²n²d)主导(m=帧数、n=每帧 token 数、d=维度),对上下文长度二次方,扩展差。 - CDiT 把第一层注意力只约束在"正在去噪的目标帧"的 token 内;要用过去帧信息,则加一层交叉注意力——当前帧每个 query token 去 attend 过去帧(作 K/V),再用 skip connection 融合。复杂度被交叉注意力
O(mn²d)主导,线性于上下文。 - 收益:可用更长上下文;相同参数量下 CDiT 比 DiT 快 ×4 且预测更好(如 CDiT-L vs DiT-XL),扩到 1B 时只需 <2× FLOPs、却比标准 DiT 少 4× FLOPs 同时预测更准。
3.2 条件注入¶
动作 a∈R³ 每个标量 → sin-cos 特征 → 2 层 MLP → 拼成 ψa∈Rd;时移 k、扩散步 t 同样得 ψk、ψt;求和 ξ=ψa+ψk+ψt(公式3)→ 喂 AdaLN 生成 scale/shift 系数,调制 LayerNorm 与注意力输出。无标签数据:算 ξ 时直接省去动作项(这就是能吃 Ego4D 的机制)。
3.3 扩散训练¶
- 前向加噪
s⁽ᵗ⁾τ₊₁=√αt·sτ₊₁ + √(1−αt)·ε,ε∼N(0,I)。反向去噪网络Fθ(sτ₊₁|sτ,aτ,t)。 - 目标:
L_simple = E‖sτ₊₁ − Fθ(s⁽ᵗ⁾τ₊₁|sτ,aτ,t)‖²(MSE);另按 DiT 预测噪声协方差并用变分下界L_vlb监督。噪声 schedule / 超参同 DiT[44]。
4. 用世界模型做规划(核心应用)¶
4.1 能量函数 + MPC + 交叉熵法¶
给定起始 latent s₀ 和目标 s*,找动作序列 (a₀,...,a_{T−1}) 最大化到达 s* 的似然。定义能量函数(公式4):
E = −S(s_T, s*) + Σ I(aτ∉A_valid) + Σ I(sτ∉S_safe)
S(s_T,s*):把 s_T、s* 解码回像素后算感知相似度(LPIPS / DreamSim),越像分越高。
- 两个约束项(指示函数大惩罚):动作约束 A_valid(如"不准先左后右")、状态约束 S_safe(如"别走悬崖边")。→ 这就是"规划时动态加约束"的实现。
- 求 argmin E(公式5),用 MPC + 交叉熵法(CEM)(gradient-free、population-based)。Appendix:无约束时假设轨迹为直线、只优化端点(3 变量 Δx/Δy/ϕ),映成 8 个等距步、步长 k=0.25s;采样 N=120 候选、每候选因随机性评 M 次取平均,短horizon(2s)只跑 1 轮迭代就够。
4.2 排序模式(Ranking)¶
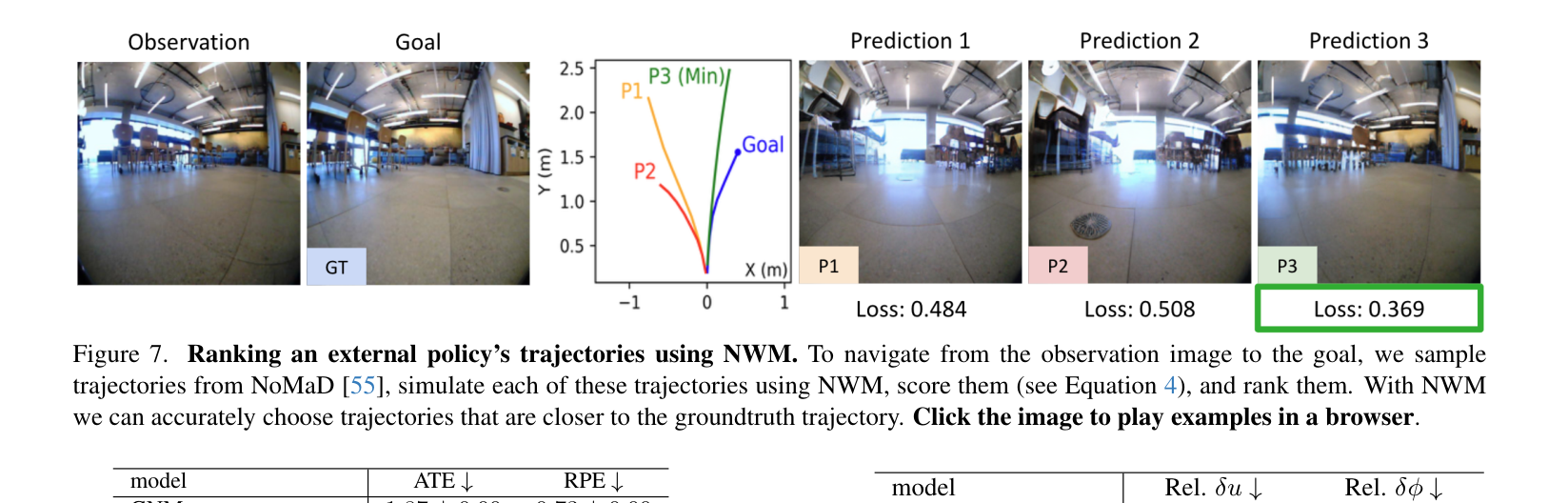
有现成策略 Π(用 NoMaD[55])时:从 Π 采 n∈{16,32} 条轨迹,每条用 NWM autoregressive rollout,按末帧与目标图的 LPIPS 排序、选能量最低的。→ 给现成策略当"重排器"。
5. 实验与全量数字¶
5.1 设置¶
- 数据集:机器人(SCAND 社交合规导航、TartanDrive 越野、RECON 开放世界、HuRoN 社交交互——均有位姿可推动作)+ 无标签 Ego4D(只用时移动作)。GO Stanford 仅作陌生环境(OOD)评测。过滤掉倒退运动(同 NoMaD)。
- 数据规模(Appendix):SCAND 484 训/121 测段;TartanDrive 1000/251;RECON 9468/2367;HuRoN 2451/613;Ego4D 用 1619 视频 / 超 908 小时(仅训练)。
- 指标:轨迹 ATE(绝对轨迹误差)/RPE(相对位姿误差);感知 LPIPS / DreamSim;像素 PSNR;生成质量 FID / FVD。
- 基线:DIAMOND[1](UNet 扩散世界模型)、GNM[53]、NoMaD[55]、Forward(永远向前的退化基线)。
- 默认配置:CDiT-XL 1B 参数,上下文 4 帧,4 个目标,batch 1024(×4 目标=4096),SD VAE tokenizer,AdamW lr 8e−5,训练后每模型采 5 次报均值±std,8×8 H100。
5.2 消融(RECON,预测 4 秒后;越低越好除 PSNR)¶
| 消融项 | 设置 | LPIPS↓ | DreamSim↓ | PSNR↑ |
|---|---|---|---|---|
| #goals | 1 | 0.312 | 0.098 | 15.044 |
| 2 | 0.305 | 0.096 | 15.154 | |
| 4 | 0.296 | 0.091 | 15.331 | |
| #context | 1 | 0.304 | 0.097 | 15.223 |
| 2 | 0.302 | 0.095 | 15.274 | |
| 4 | 0.296 | 0.091 | 15.331 | |
| 条件 | time only | 0.760 | 0.783 | 7.839 |
| action only | 0.318 | 0.100 | 14.858 | |
| action+time | 0.295 | 0.091 | 15.343 |
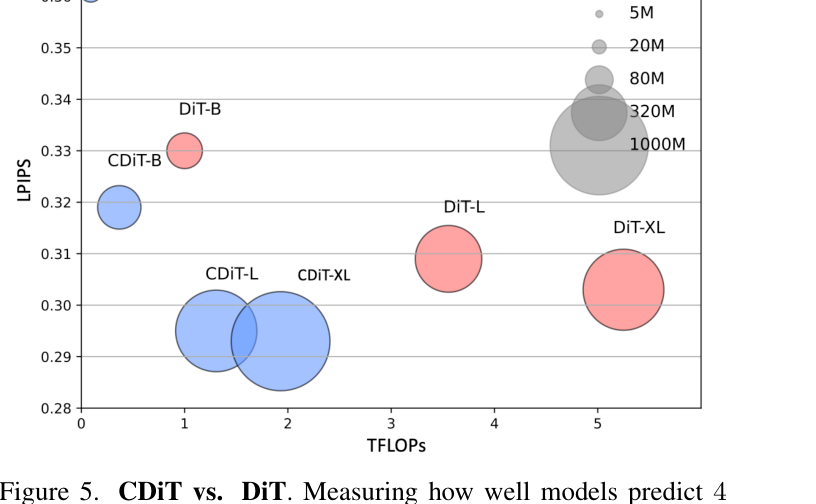
读数:4 目标、4 上下文最好;只给时间几乎崩(LPIPS 0.760),只给动作也掉一截,action+time 最佳——证实两者都有用。CDiT vs DiT 见图5:相同参数下 CDiT 比 DiT 快 ×4 且更准。
5.3 视频合成质量 FVD(16 秒 @4FPS,越低越好;Appendix 表6)¶
| 数据集 | DIAMOND | NWM (ours) |
|---|---|---|
| RECON | 762.73 ± 3.36 | 200.97 ± 5.63 |
| HuRoN | 881.98 ± 11.60 | 276.93 ± 4.35 |
| TartanDrive | 2289.69 ± 6.99 | 494.25 ± 14.43 |
| SCAND | 1945.09 ± 8.45 | 401.70 ± 11.22 |
NWM 全面碾压 DIAMOND(FVD 普遍低 3–4 倍)。图4(正文)另示:1FPS 变体起初更准,但 8 秒后误差累积 + 丢上下文,被 4FPS 反超。
5.4 目标条件视觉导航(RECON,预测 2 秒轨迹;表2)¶
| 模型 | ATE↓ | RPE↓ |
|---|---|---|
| GNM | 1.87 | 0.73 |
| NoMaD | 1.93 | 0.52 |
| NWM + NoMaD (×16) | 1.83 | 0.50 |
| NWM + NoMaD (×32) | 1.78 | 0.48 |
| NWM(独立规划) | 1.13 | 0.35 |
5.5 全 in-domain 导航(Appendix 表7,ATE/RPE,≤2 秒)¶
| 模型 | RECON ATE/RPE | HuRoN | TartanDrive | SCAND |
|---|---|---|---|---|
| Forward | 1.92 / 0.54 | 4.14 / 1.05 | 5.75 / 1.19 | 2.97 / 0.62 |
| GNM | 1.87 / 0.73 | 3.71 / 1.00 | 6.65 / 1.62 | 2.12 / 0.61 |
| NoMaD | 1.95 / 0.53 | 3.73 / 0.96 | 6.32 / 1.31 | 2.24 / 0.49 |
| NWM+NoMaD ×16 | 1.88 / 0.51 | 3.73 / 0.95 | 6.26 / 1.30 | 2.18 / 0.48 |
| NWM+NoMaD ×32 | 1.79 / 0.49 | 3.68 / 0.95 | 6.25 / 1.29 | 2.19 / 0.47 |
| NWM(独立) | 1.13 / 0.35 | 4.12 / 0.96 | 5.63 / 1.18 | 1.28 / 0.33 |
诚实读数:独立 NWM 在 RECON/Tartan/SCAND 大幅最优,但 HuRoN(ATE 4.12)反而不如 NoMaD(3.73)——HuRoN 是动态人流室内场景,独立规划吃亏;此时排序模式(×32→3.68)才是最好。Tartan 被向前运动主导(Forward 基线已很强)。
5.6 带约束规划(RECON,表3,相对无约束的终点差异)¶
| 约束 | Rel.δu↓ | Rel.δϕ↓ |
|---|---|---|
| forward first | +0.36 | +0.61 |
| left-right first | −0.03 | +0.20 |
| straight then forward | +0.08 | +0.22 |
三种约束(先直走/先转/先左右)都被满足,性能仅小幅下降——验证"规划时动态加约束"可行(监督策略做不到)。
5.7 加无标签 Ego4D → 泛化到陌生环境(表4/5,LPIPS 4 秒后)¶
| 数据 | GO Stanford(OOD) LPIPS↓ | RECON(已知) LPIPS↓ |
|---|---|---|
| in-domain only | 0.658 | 0.295 |
| + Ego4D 无标签 | 0.652 | 0.368 |
加 Ego4D 改善 OOD(GO Stanford 0.658→0.652,DreamSim 0.478→0.464),但已知环境反而退化(RECON LPIPS 0.295→0.368)——in-domain 模型更贴合自身分布。例外是 SCAND(含动态人流),加无标签数据有帮助。
5.8 实时性(Appendix 表8,单条 4 秒轨迹,RTX 6000 Ada,秒)¶
| NWM | +Time Skip | +蒸馏 | +4-bit 量化 |
|---|---|---|---|
| 30.3 | 14.7 | 0.4 | 0.1(估计) |
"Time Skip"(相邻动作合并、只模拟 8 个未来态而非 16)不掉导航性能;扩散去噪步 250→6 蒸馏再加速、视觉质量轻微损失。组合后可 2–10Hz 实时;4-bit 量化(未实测)可再 ×4。Test-time adaptation(在陌生环境上 fine-tune 2k 步)与世界模型规划正交,可叠加改善(表9)。
6. 局限(作者自陈,正文 §5)¶
- OOD 下的模式坍缩(mode collapse):陌生环境长 rollout 时,模型慢慢丢上下文、生成的画面越来越像训练数据(见图10)。是图像生成里已知现象。
- 难以模拟时序动态(如行人运动)——大多数情况下做不好。
- 作者认为前两点更长上下文 + 更多数据有望缓解。
- 当前只 3-DoF 导航动作;扩到 6-DoF(乃至控制机械臂关节)是 future work。

7. 核心洞见¶
- 范式转变:把导航从"策略直接出动作"换成"世界模型想象 + 能量打分挑轨迹"。好处是约束可后注入、算力可按难度动态分配(多采样/多迭代)。
- CDiT 是让这件事 scale 起来的工程关键:交叉注意力把上下文复杂度降到线性,才撑得起 1B + 长上下文 + 多本体。
- 无标签视频是泛化燃料:Ego4D 这种 action-free 数据靠"只留时移动作"就能喂进同一架构,换来 OOD 想象力(但牺牲 in-domain 精度——有取舍)。
- 排序 vs 独立规划要看场景:静态/几何主导场景独立 NWM 强;动态人流场景该退回"给 NoMaD 当重排器"。
- 讨论里坦承:不确定是什么表征让它 work(无显式地图),猜测 egocentric 下一帧预测可能催生 allocentric(全局)表征。

🗣️ 外部评价¶
- 🌐 CVPR 2025 Best Paper Honorable Mention(最佳论文荣誉提名)。一作 Amir Bar 推特确认这是他加入 LeCun 实验室后的首篇博士后论文。这是该工作最硬的外部背书。来源:Amir Bar 推特、CVPR 2025 Best Papers 官方。
- 🌐 themoonlight.io 文献综述(偏正面/推广性、未列缺点)总结其卖点:相对常规 DiT 少 4× FLOPs、上下文线性复杂度、在熟悉与陌生环境都有效、可在规划时注入约束、能给现有策略加成。来源:Moonlight Review。
- 🌐 第三方综述(emergentmind)归纳该类方法共性局限(非专指本文,需谨慎):OOD 下丢上下文、latent/符号表征可能丢失精细几何、长 horizon 误差累积、密集采样规划算力昂贵、模块化把导航规划与视觉建模分离导致 state-action 错配。来源:emergentmind: Lightweight Navigation World Model。
- 🧑 Synced(机器之心英文版)报道把它定位为 LeCun 团队"用可控视频生成革新视觉导航"的代表作。来源:Synced Review。
说明:CVPR 走非公开评审,未检索到逐条 OpenReview 评分;上述为公开报道/综述与官方奖项,已标注谁说。
🧑⚖️ 审稿人视角(🤖)¶
- 强:① 把"世界模型 + 扩散视频生成"干净地落到导航并拿 SOTA + 荣誉提名;② CDiT 的线性上下文是真有用的架构贡献(消融扎实,FLOPs-性能曲线清楚);③ 能量函数 + 约束 + MPC 的"规划时加约束"是相对监督策略的真实增量;④ 吃无标签 Ego4D 的机制优雅。
- 可质疑:① 核心评测靠感知相似度(LPIPS/DreamSim)当 reward——这是"画面像不像目标",不是"真到没到目标",与真实导航成功率有 gap,可能高估;② 几乎全是离线/回放评测,无真实闭环上机(实时性只给单卡 runtime 估计);③ HuRoN 上独立 NWM 不如 NoMaD、加 Ego4D 伤 in-domain——泛化是有代价的取舍而非免费午餐;④ 只 3-DoF、平地假设,离"控机械臂"承诺还远;⑤ 模式坍缩 + 行人动态做不好,长 horizon 想象可靠性存疑。
- 总评:架构贡献(CDiT)与范式叙事(world-model-as-planner)都站得住,奖项实至名归;但"导航成功"的证据偏代理指标 + 离线,真实机器人闭环是最大未验证缺口。
8. 对我们(深一层)¶
- 与 卡片-DINO-WM 的对照(同 LeCun/Pinto 生态,NWM 还引了 DINO-WM[77]):两者都是"世界模型 + CEM/MPC 规划",但表征路线相反——DINO-WM 在 DINO 冻结特征的 latent 上预测、不解码像素、主打操作/zero-shot 规划;NWM 在 VAE latent 上预测并解码回像素、用感知相似度打分、主打导航 + 可视化想象。latent 预测(DINO-WM)省算力、抗细节幻觉;像素生成(NWM)可解释、可做视频但易模式坍缩。这是我们选世界模型路线时的关键二选一。
- 与 卡片-LaWAM / 详读-LaWAM 的对照:LaWAM 走"语言/动作"语义条件,NWM 走"连续导航动作 + 时移"几何条件。NWM 的 CDiT 线性上下文 + AdaLN 条件注入是可借的高效自回归视频世界模型骨架。
- 可借机制:① 能量函数把"目标相似度 + 硬约束"统一成可优化目标 + CEM 这套规划框架,迁移到操作域(末态相似度→任务完成度)值得试;② action-free 视频(只留时移)喂同一模型的训练技巧,对我们"无动作标签的海量视频"利用直接有用;③ Time Skip + 扩散步蒸馏把扩散世界模型压到实时,是部署侧的现成招。
- 要警惕的坑:NWM 暴露的"像素生成世界模型在 OOD 长 horizon 会模式坍缩"是通病——若我们走像素路线,长程规划要么短 horizon + 频繁重规划,要么退回 latent 路线(DINO-WM)。
- 战场定位:NWM = "世界模型用于导航"的标杆;我们更关心操作,但"模拟未来观测 → 打分 → 挑轨迹"的规划范式跨域通用,值得作为操作世界模型的参照基线。