详读 · SpatialVLA(空间表示增强的通用 VLA)¶
卡片版见 卡片-SpatialVLA。本页是全文精读(含正文 + 附录):定位 → 动机 → 逐模块方法(Ego3D 位置编码 / 自适应动作网格)→ 全量数字表 → 局限 → 洞见 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2501.15830 v5(2025-05-19,RSS 2025 接收)· 项目页 · 代码 作者:Delin Qu、Haoming Song、Qizhi Chen(共一)、Dong Wang(通讯)、Bin Zhao(通讯)、Xuelong Li 等 —— 上海 AI Lab + 复旦 / 上交 / 浙大 / 上科大 / 西工大

0. 一句话定位¶
在 PaliGemma2 这个 VLM 上造一个通用机器人策略:用 Ego3D Position Encoding 把单目深度反投影出的 3D 点位注入视觉 token(免相机外参标定),用 Adaptive Action Grids 把连续动作按数据分布自适应离散成空间动作 token(一步动作只需 3 个 token,而非 RT-2/OpenVLA 的 7 个)。1.1M 真机轨迹预训练,零样本即可跨机控制,且换新机器人时只需把动作网格按新分布重新离散即可高效后训练。核心主张:空间理解是操作的关键。
1. 问题与动机¶
- 现有 VLA(RT-2、OpenVLA、π0 等)主要吃 2D 观测,缺乏对 3D 物理世界的精确感知——而人天生会构建结构化的空间心理表示来对位操作。
- 做"有 3D 空间智能的通用策略"有两个异构性难题:
- 观测不 3D 对齐:不同机器人相机型号/安装位置各异 → 3D 观测空间未标定。
- 动作特性各异:自由度、控制器、工作空间、任务复杂度不同 → 难学可泛化的空间动作。
- SpatialVLA 的切入:给观测和动作都造空间对齐、机器人无关(robot-agnostic)的表示,从而跨本体控制 + 快速适配。
2. 模型架构(图2)¶
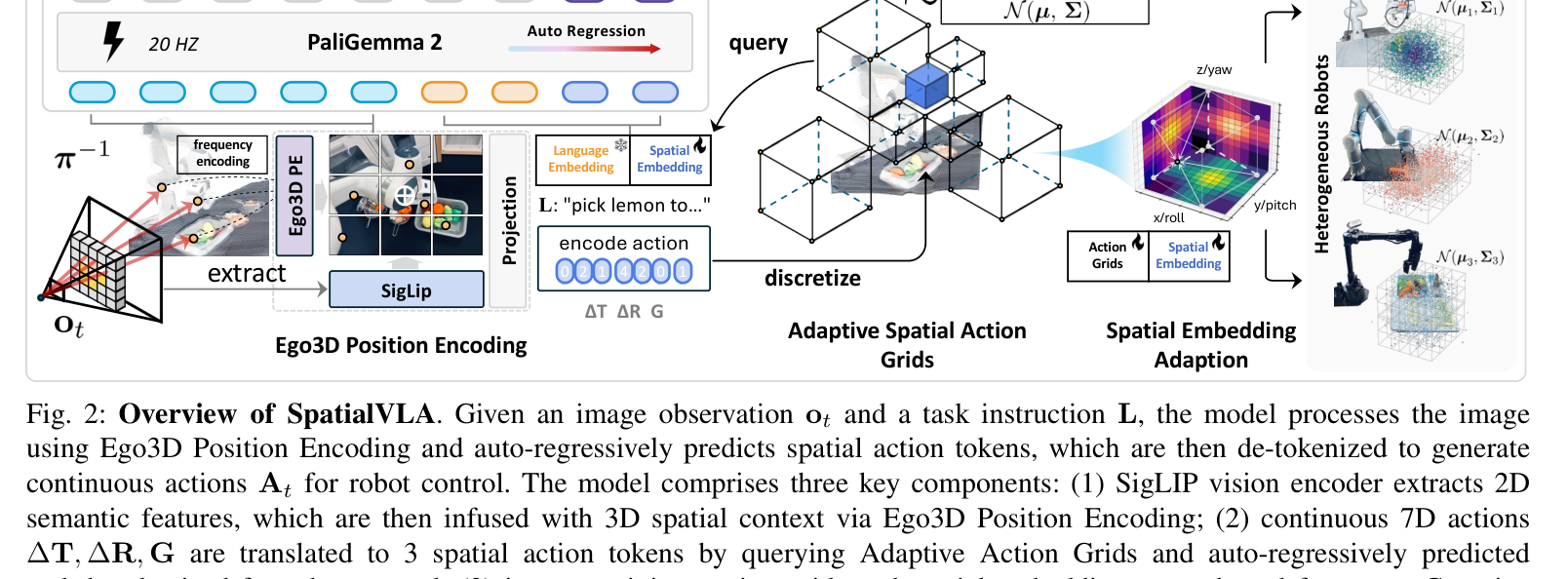
输入:图像观测 o_t(只用一路第三人称相机、单帧)+ 语言指令 L;输出:未来动作块 A_t(chunk T=4)。训练目标是标准自回归交叉熵 next-token:
L(θ) = E[ L(a_t, ã_t) ],其中 ã_t = τ(O_3d, L),再去 token 化成连续动作 a_t。
三大组件:(1) SigLIP 视觉编码器出 2D 语义特征;(2) Ego3D PE 注入 3D;(3) Gemma2 自回归出动作 token。骨干用 PaliGemma2(SigLIP 视觉塔 + Gemma2 LLM),深度用 ZoeDepth(冻结)。
2.1 Ego3D Position Encoding(观测侧注入 3D)¶
- 用 ZoeDepth 估深度图
D,配相机内参做反投影π⁻¹→ 得每像素自我中心坐标系下的 3D 位置p={x,y,z}(不需机器人-相机外参标定,对任意本体通用)。 - SigLIP 出 2D 语义特征
X ∈ R^{d×h×w};对应 3D 位置P ∈ R^{3×h×w}经正弦编码 γ(·) + 可学习 MLP 得 3D 位置嵌入,直接相加到视觉 token:
O_3d = X + P' = X + MLP(γ(P)) (公式 2)
- 工程细节(附录):对每个 sub-patch 取高频点云编码的均值,再投到 SigLIP patch 维度;MLP 用 LayerNorm + 零权重初始化抑制深度噪声。
2.2 Adaptive Action Grids(动作侧自适应离散,图3)¶
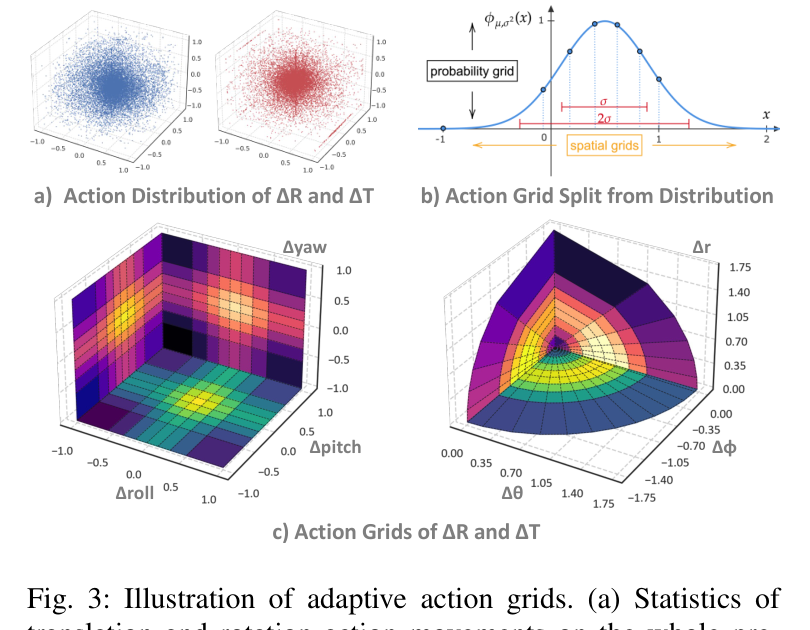
单臂 7 维动作 a={x,y,z,roll,pitch,yaw,grip} 拆三块:
- 平移 ΔT:把
(x,y,z)转极坐标(ϕ,θ,r),解耦"方向(ϕ,θ)"与"距离r"(方向切更细)。 - 旋转 ΔR:
(roll,pitch,yaw)。 - 夹爪:2 个离散 token(开/合)。
离散方式(关键创新,非均匀):先把每个变量归一化到 [-1,1],在全数据混合上拟合高斯 N(µ_a,Σ_a),再按等概率 1/M 切 M 段(公式 4)——即让网格集中在高频动作区,而非均匀切。
- 附录精确 bin 数:
θ→16、ϕ→32、r→8(范围[0,π]/[-π,π]/[0,√3]);roll/pitch/yaw 各 16。 - 网格线性化为 V = 8194 个空间动作 token 嵌入(
M_trans = M_rot = 4096,夹爪 2),与 LLM embedding 共享参数。 - 因此一步动作只生成 3 个 token(trans/rot/grip),对比 RT-1/RT-2/OpenVLA 的 7 个 → 推理更快。
2.3 Spatial Embedding Adaption(后训练侧的迁移技巧)¶
换新机器人/任务时:在后训练数据上拟合新高斯 N(µ_new,Σ_new) → 重做网格 G_new → 新动作 token 嵌入用预训练网格的三线性插值初始化(公式 6,按质心距离加权)。即把预训练学到的空间动作知识"平移"到新本体,加速收敛、改善初始化(图8 验证特征对齐)。

3. 训练配置(全量数字)¶
- 数据:1.1M 真机演示 = OXE 子集 + RH20T;按真机实测表现改了 OpenVLA 的混合权重(下调 Kuka/Toto/Berkeley Fanuc/FMB;FMB 过多会让机器人显著右偏、Kuka 缺清晰 prompt)。
- 混合权重 Top(附录表 VI):Bridge 15.34% / Fractal 14.71% / Droid 11.66% / BC-Z 8.64% / Kuka 7.06% / RH20T 5.67% / Stanford Hydra 5.15% / Language Table 5.06%(共 28 个数据集)。
- 算力:64× A100,10 天,batch 2048,AdamW,lr 2e-5,linear scheduler,无 weight decay,warmup 0.005,DeepSpeed ZeRO-1。
- 两阶段:stage1 全量训 160k 步 → 90% acc;stage2 移除 DROID 再训 40k 步 → >95% acc(去 DROID 后准确率明显跳升、loss 下降)。
- 冻结文本 embedding:保留 VLM 世界知识,利于指令跟随、训练更快(消融 #9 验证)。
- 参数/部署:3.5B 参数(vs RT-2-X 55B);输入 224×224 单图;输出每次 4 个动作(12 token,总词表 V=8194);推理 ~20Hz(正文另处 21Hz)/ 单张 RTX 4090 / 8.5GB 显存;夹爪 stick step 从 1 调到 15(真机关键)。
- 架构维度(附录表 VII):SigLIP 27 层、hidden 1152;Gemma2 26 层、hidden 2304;Ego3D PE MLP:Linear(204→1152)+LN+ReLU+Linear。
4. 实验结果(全量表)¶
评测覆盖 7 类场景、24 个真机任务、3 个仿真环境(SimplerEnv / LIBERO / 真机 WidowX / 真机 Franka)。
4.1 SimplerEnv · Google Robot(表 I,%)¶
| 方法 | VM·Pick Coke | VM·Move Near | VM·Drawer | VM 平均 | VA 平均 |
|---|---|---|---|---|---|
| RT-1 (Converged) | 85.7 | 44.2 | 73.0 | 74.6 | 63.3 |
| RT-2-X (55B) | 78.7 | 77.9 | 25.0 | 60.7 | 64.3 |
| Octo-Base | 17.0 | 4.2 | 22.7 | 16.8 | 1.1 |
| OpenVLA | 16.3 | 46.2 | 35.6 | 27.7 | 39.8 |
| RoboVLM (fine-tune) | 77.3 | 61.7 | 43.5 | 63.4 | 51.3 |
| π0* (open-pi-zero) | 88.0 | 80.3 | 56.0 | 70.1 | — |
| SpatialVLA (zero-shot) | 81.0 | 69.6 | 59.3 | 71.9 | 68.8 |
| SpatialVLA (fine-tune) | 86.0 | 77.9 | 57.4 | 75.1 | 70.7 |
VM=Visual Matching,VA=Variant Aggregation。零样本 VM 71.9% 超第二名 RoboVLM +15.6;且 3.5B 直接超 55B 闭源 RT-2-X(71.9 vs 60.7 / 68.8 vs 64.3)。
4.2 SimplerEnv · WidowX(表 II,#Overall 平均,%)¶
| 方法 | Spoon | Carrot | Stack Block | Eggplant | Overall |
|---|---|---|---|---|---|
| RT-1-X | 0 | 4.2 | 0 | 0 | 1.1 |
| Octo-Small | 47.2 | 9.7 | 4.2 | 56.9 | 30.0 |
| OpenVLA | 0 | 0 | 0 | 4.1 | 1.0 |
| RoboVLM (fine-tune) | 29.2 | 25.0 | 12.5 | 58.3 | 31.3 |
| SpatialVLA (zero-shot) | 20.8 | 20.8 | 25.0 | 70.8 | 34.4 |
| SpatialVLA (fine-tune) | 16.7 | 25.0 | 29.2 | 100.0 | 42.7 |
"Put Eggplant in Yellow Basket"微调后 100% 成功率。
4.3 LIBERO 微调(表 III,SR%,三种子 500 trials)¶
| 方法 | Spatial | Object | Goal | Long | Average | Rank |
|---|---|---|---|---|---|---|
| Diffusion Policy (scratch) | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 | 5 |
| Octo (fine-tune) | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 | 3 |
| OpenVLA (fine-tune) | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 | 2 |
| TraceVLA (fine-tune) | 84.6 | 85.2 | 75.1 | 54.1 | 74.8 | 4 |
| SpatialVLA (fine-tune) | 88.2 | 89.9 | 78.6 | 55.5 | 78.1 | 1 |
Average 第一;Spatial 88.2%(空间关系理解最强);但 LIBERO-Long 仍弱(缺长程观测架构)。
4.4 真机 Franka(图6,自报):单任务 82% ≈ Diffusion Policy 81%;指令跟随比 OpenVLA +12%(DP 仅 26%);多任务 57% 居首。¶
4.5 预训练消融(表 IV,Google Fractal + Bridge 混合,从零训,%)¶
| # 设置 | Pick Coke VA | Pick Coke VM | Move Near VA | Move Near VM |
|---|---|---|---|---|
| #1 SpatialVLA(全) | 81.6 | 70.7 | 79.2 | 85.4 |
| #2 ~线性 256 bin | 40.7 | 19.0 | 47.1 | 52.9 |
| #3 ~均匀分布(非高斯) | 77.9 | 28.0 | 64.2 | 55.0 |
| #4 分辨率 1026 | 74.4 | 67.3 | 59.1 | 54.2 |
| #5 分辨率 4610 | 76.7 | 68.0 | 69.8 | 79.2 |
| #6 分辨率 6166 | 80.9 | 74.0 | 74.0 | 79.2 |
| #7 分辨率 8194 | 81.6 | 70.7 | 79.2 | 85.4 |
| #8 −Ego3D 编码 | 68.9 | 70.3 | 66.7 | 62.0 |
| #9 −冻结 LLM embedding | 70.2 | 50.7 | 63.1 | 62.5 |
关键读数:① 自适应网格 vs 传统线性 256-bin(#1 vs #2):Google 任务 VA/VM +36.5 / +42.1;② 去 Ego3D(#1 vs #8)VA 从 81.6/79.2 跌到 68.9/66.7(应对光照/纹理/视角变化全靠它);③ 高斯分布优于均匀切(#1 vs #3);④ 分辨率 1026→8194 持续涨,6166 后趋于平台甚至下降(附录 Q1:高分辨率非越大越好)。
4.6 后训练消融(表 V,%)¶
| 设置 | 效果 |
|---|---|
| 大数据(Fractal/Bridge) +高斯自适应(#1 vs #2) | 仅微增(+2.9% on Move Near VM),因大数据分布已贴近预训练 |
| LIBERO 小数据 LoRA +空间嵌入自适应(#4 vs #5) | Spatial/Object/Goal/Long +4.6 / +5.1 / +2.2 / +5.4 |
| LIBERO 上 LoRA vs 全参(#3 vs #4) | LoRA 更优(小数据首选 LoRA, r=α=32) |
4.7 附录:分辨率 / 细粒度 / 深度消融¶
- 动作离散分辨率(表 VIII):1026→4610→6166→8194 整体上升,8194 最佳但 6166 后趋平;自适应网格的 4610 半数分区即超 8196 均匀分区(#1 U8196)。
- 超越 pick-place 的细粒度任务(表 IX,4 任务平均 ACC):SpatialVLA(ZoeDepth) 72.7% > 传感器深度 70.5% > 无深度 45.4% > OpenVLA 54.5%。结论:ZoeDepth 预测深度比真传感器深度更平滑、更好用(传感器深度噪声大);ZoeDepth 冻结、仅占 8.6% 参数、+0.06s/动作。
5. 局限(作者自陈 · 第 V 节)¶
- 高斯建模次优:极端单轴运动时网格会在某坐标轴聚簇、丢失其他轴运动能力;数据噪声也会扭曲网格。未来想用 VAE 等隐式分布建模 + 显式网格结合。
- 自回归解码偏慢:每动作 3 token,虽 21Hz 但慢于 diffusion 解码(一次解多步);未来想把 diffusion 解码 + 空间网格结合、探索动态 token 数。
- 长程任务弱:只靠当前帧 + 历史 token,LIBERO-Long 吃亏;缺高效历史感知机制。
- 数据质量:OXE 质量参差会拖累训练,需要更优数据配比 / 蒸馏高质量子集。
- 高自由度本体参数开销:更高分辨率/维度会撑大 128k 词表;humanoid 等需在本体间共享动作网格(未来工作)。
6. 核心洞见¶
- 把"动作"也当成空间结构来表示:与 3D-LLM/LEO/3D-VLA 只关注 3D 理解不同,SpatialVLA 把 3D 空间性同时灌进观测和动作两侧——这是它区别于其他 3D 基础模型的关键点。
- 免标定的 Ego3D:用单目深度估计在相机系造 3D,绕开跨本体相机外参标定,是"可规模化跨本体"的工程关键。
- 分布自适应离散 > 均匀离散:动作天然聚于分布中心,等概率切网格把表示预算花在高频动作上,既省 token 又提精度;半数分区即超均匀全量分区。
- 网格重离散 = 新的后训练范式:换本体不靠纯 LoRA/全参微调,而靠"重做网格 + 插值初始化嵌入",小数据上额外加几个点。
🗣️ 外部评价¶
- 🌐 RSS 2025 接收:官方 GitHub 仓库明确标注 "Accepted at RSS 2025"。来源:GitHub - SpatialVLA/SpatialVLA。
- 🌐 未找到公开的逐条审稿讨论:RSS 不像 ICLR/NeurIPS 那样公开 OpenReview 评审线程,搜索 "SpatialVLA OpenReview" 命中的是同名后续工作与他人论文,没有针对本文的公开 reviewer critique(如实记录)。来源:OpenReview 搜索结果。
- 🌐 第三方文献综述(themoonlight.io):肯定其"免标定注入 3D + 高效(20Hz、少 token)+ 强泛化(超 RT-1/Octo/RoboVLM)+ 1.1M 规模";但点出依赖高端 GPU、对动作表示局限讨论不足、评测偏重空间任务、对视觉以外感知模态探索不足。该综述本身只复述论文、未做独立批判。来源:themoonlight.io review。
- 🌐 后续工作侧面反映其局限:有 OpenReview 投稿 "SpatialVLA-Mamba" 以用 Mamba 状态空间模型替代解码、追求更高效率为卖点,间接印证"自回归解码偏慢"是公认改进点。来源:SpatialVLA-Mamba @ OpenReview。
🤔 我的判断(🤖)¶
- 真实卖点是"工程上把 3D 灌进 VLA 两侧 + 高效 token 化",不是某个全新理论。Ego3D 用现成 ZoeDepth、动作侧用高斯自适应离散——组合拳干净、复现门槛低(全开源 + 权重)。
- 数字可信度较高:对比覆盖广(RT 系列/Octo/OpenVLA/RoboVLM/π0),消融指向明确(去 Ego3D、换线性 256-bin 都大跌),且3.5B 超 55B RT-2-X 这条很有说服力。但要注意——SimplerEnv 是仿真、真机 Franka/WidowX 多为自报且 11 trials/任务样本偏小,单点数字别过度解读。
- 诚实点:作者自己承认高斯次优、长程弱、解码偏慢,没硬吹;表 IX 还自曝"ZoeDepth 比真传感器深度更好用"这种反直觉但解释合理的结论。
- 对位/精细操作的相关性:它的强项正是空间布局变化 / 高度变化 / 指令对位(Franka #1 prompt 73%、LIBERO-Spatial 88.2%、WidowX 高度变化任务),这正是插拔/对准类任务需要的能力。
- 存疑:单目深度在透明/反光/无纹理物体上 ZoeDepth 会不会崩?论文未测;真机也都是常规家居物体。
7. 对我们¶
- 可借的具体件:① Ego3D PE 这套"单目深度反投影 + 正弦编码 + 加到视觉 token"几乎是即插即用的 3D 注入模块,做需要空间对位的任务时值得抄;② 分布自适应动作离散比线性 256-bin 明显好,且省 token——若我们走自回归 token VLA 路线,这是低成本升级点。
- 同生态:与 卡片-3D-VLA 同属"给基础模型注入 3D"流派,但 3D-VLA 重世界理解/预测、SpatialVLA 重动作空间的 3D 化 —— 两者正好互为对照(理解 vs 行动)。骨干 PaliGemma2 与 π0 同源;动作 token 化思路承自 RT-2/OpenVLA(见 卡片-OpenVLA)。
- 战场判断:开源 + 权重 + RSS 接收,是当前"3D-aware 通用 VLA"里复现性最好的基线之一;做空间敏感任务时可直接拿来当 baseline / 初始化。