详读 · VPP(Video Prediction Policy,视频预测策略)¶
卡片版见 卡片-VPP。本页是全文精读:定位 → 动机 → 逐模块方法(公式直觉) → 全量数字表 → 诚实局限 → 核心洞见 → 外部评价 → 审稿人视角 → 对我们。 来源:arXiv 2412.14803(v2,2025-05-04)· 项目页 · 代码 作者:Yucheng Hu、Yanjiang Guo(共同一作)… Jianyu Chen(通讯)等。清华 IIIS + 上海 AI Lab + 上海期智 + RobotEra(星动纪元)+ UC Berkeley。ICML 2025 Spotlight。
0. 一句话定位¶
把一个视频扩散模型(VDM)当"会预见未来的视觉编码器":只跑一次前向(不完整去噪)就拿到它内部"含未来动态"的潜表征,喂给一个轻量 diffusion policy 头去隐式学逆动力学——策略只要"在预测出的未来里追踪机械臂自己的运动"就能出动作。于是把视频模型的泛化能力迁移到机器人策略上,且能保持高频闭环。
1. 问题与动机(图1)¶
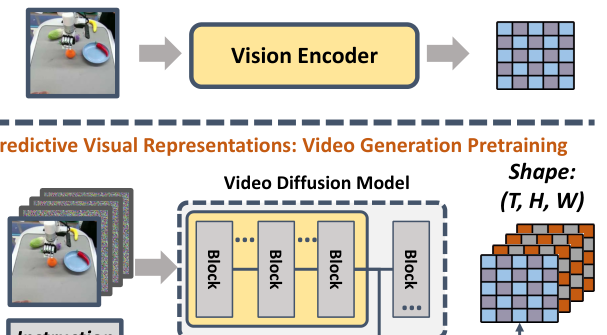
- 通用机器人策略的关键是视觉编码器。但主流编码器(单图重建 MAE、双图/图文对比学习:R3M / VIP / VC-1 / Voltron)只抽当前静态信息,没有显式的"未来"。而具身任务本质是动态的。
- VDM 近年在视频生成上很强,直接对整段视频序列建模,文本引导视频预测(TVP)甚至能据当前观测+指令预测未来帧,说明它懂物理动态。
- 核心假设:TVP 模型内部的潜变量天然是一个形如
(T, H, W)的张量——1 个当前步 +(T−1)个预测未来步,作者称之为 "预测式视觉表征(predictive visual representations)"。它比旧编码器多了"未来"这一维。 - 关键洞见:下游策略可以靠在预测表征里追踪机器人自身运动来隐式学逆动力学;只要视频模型把未来预测对,策略就只需少量演示把"动作空间"对齐到"视觉空间"。
2. 与前人的区别(动机层)¶
- SuSIE / UniPi:只预测单个未来关键帧/目标图再学逆动力学;且完整去噪很慢→ 低频甚至开环。VPP 预测一序列未来、且只跑单步前向当编码器→ 高频闭环。
- GR-1(卡片-GR-1):自回归一次只出一帧,预测质量逊于扩散,且不用预训练视频基座。VPP 用 SVD 基座微调,预测一段未来。
- Vidman:用 OXE 视频预训练但不在下游任务上微调视频模型→ 次优。
- 一句话:VPP = "用预训练视频基座 + 在下游微调 + 取内部表征(单步) + 序列未来"四件事一起做,前人各缺一两件。
3. 方法详解(图2)¶
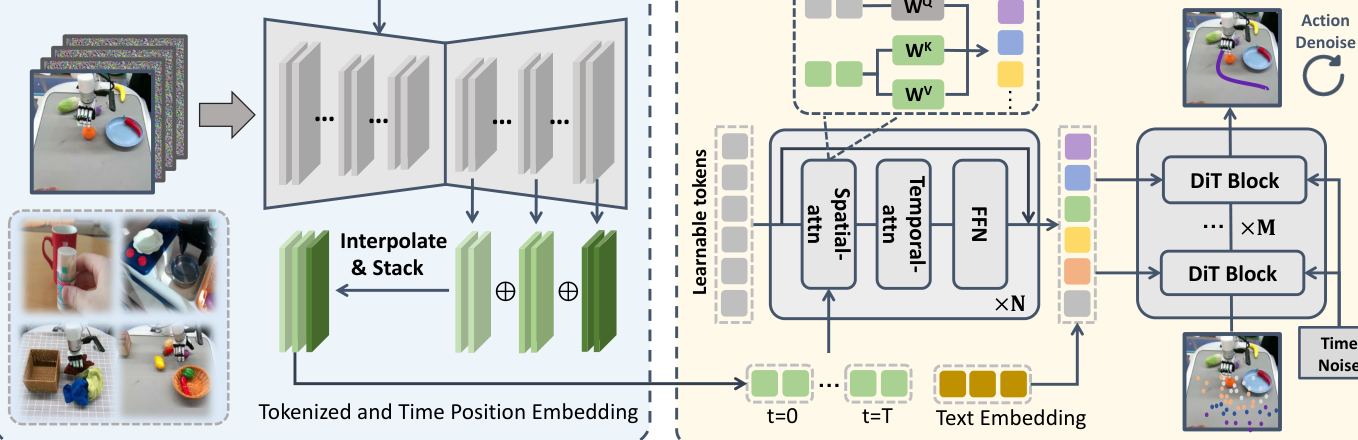
3.1 阶段一:操作域文本引导视频预测(TVP)模型¶
- 基座选开源 Stable Video Diffusion(SVD,1.5B 参数)。原版 SVD 只条件于首帧
s0,作者加 CLIP 语言特征l_emb(cross-attention)让它可被指令控制,并把输出分辨率改成 16×256×256(16 帧)以提效;其余结构保留。记为Vθ。 - 训练目标是标准扩散重建整段视频
x0 = s0:T(公式3直觉:把加噪视频xt还原回原视频):L_D = E‖Vθ(xt, l_emb, s0) − x0‖² - 多源混训 + 系数加权(公式4):
L_video = λ_H·L_DH + λ_R·L_DR + λ_C·L_DC,分别对应互联网人手操作 DH、互联网机器人 DR、自采 DC,按质量/规模配采样比(仿 Octo,卡片-Octo)。 - 训完冻结 TVP,进入下游动作学习。
3.2 阶段二:在"预测式表征"上学动作¶
- 把 VDM 当编码器而非去噪器:只跑单步前向。把当前帧
s0与"最噪潜变量"(≈白噪声)拼起来喂Vθ,直接取中间潜特征。作者强调:单步前向虽出不了清晰视频,但已含"未来轨迹的粗略走向"(图4验证)。 - 跨层特征聚合(免手选层):取上采样层第 m 层特征
Lm ∈ R^{T×Cm×Wm×Hm},插值到统一Wp×Hp,再沿通道维拼成Fp。多相机视角(第三人称 + 腕部)各自独立预测 →Fp_static, Fp_wrist。 - Video Former:用固定长度
T×L的可学习 token,对每帧做空间注意力聚合多视角特征,再做时间注意力 + FFN,把高维序列表征压成定量 tokenQ''(公式5)。 - 动作生成:
Q''经 cross-attention 注入 diffusion transformer(DiT)policy 头,去噪重建动作序列a0(公式6:L_diff = E‖Dψ(ak, l_emb, Q'') − a0‖²)。配 action chunking(10 步)提频。
3.3 推理为什么能高频¶
- 每个观测只过一次 TVP(<160ms),不做多步去噪;DiT policy 头采样 10 步。整体延迟 ~140ms,在消费级 RTX 4090 上达 7–10Hz 闭环。对照:去 Video Former 后延迟升到 ~450ms(见表4)。
4. 实验与全量数字¶
4.1 CALVIN ABC→D(长程,训 ABC 测未见 D;指标=连续完成 5 链任务的平均长度)¶
注:本表"1–5"为完成第 i 个连任务的成功率,"Avg.Len"满分 5。
| 类别 | 方法 | 1 | 2 | 3 | 4 | 5 | Avg.Len ↑ |
|---|---|---|---|---|---|---|---|
| 直接动作 | RT-1 | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| Diffusion Policy | 0.402 | 0.123 | 0.026 | 0.008 | 0.00 | 0.56 | |
| Robo-Flamingo | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.47 | |
| 未来预测类 | Uni-Pi | 0.560 | 0.160 | 0.080 | 0.080 | 0.040 | 0.92 |
| MDT | 0.631 | 0.429 | 0.247 | 0.151 | 0.091 | 1.55 | |
| SuSIE | 0.870 | 0.690 | 0.490 | 0.380 | 0.260 | 2.69 | |
| GR-1 | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 | |
| Vidman | 0.915 | 0.764 | 0.682 | 0.592 | 0.467 | 3.42 | |
| 3D 类 | RoboUniview | 0.942 | 0.842 | 0.734 | 0.622 | 0.507 | 3.65 |
| 本文 | VPP | 0.965 | 0.909 | 0.866 | 0.820 | 0.769 | 4.33 |
| 数据效率 | GR-1 (10%ABC) | 0.672 | 0.371 | 0.198 | 0.108 | 0.069 | 1.41 |
| VPP (10%ABC) | 0.878 | 0.746 | 0.632 | 0.540 | 0.453 | 3.25 |
- "提升多少"有三个口径,注意区分:摘要说相对提升 18.6%(4.33 vs 3D 类 SOTA RoboUniview 3.65);引言说41.5%(vs GR-1 3.06);正文又写"从 3.35 提到 4.33"(约 +29%,疑指 3D Diffuser Actor 口径)。数值本身 4.33 是确定的,"提升百分比"取决于拿谁当基线。
- 数据效率亮点:VPP 只用 10% 标注数据(Avg.Len 3.25)就超过多数方法用 100% 数据的结果(如 GR-1 满数据 3.06)。
4.2 MetaWorld(单一语言条件策略解 50 个任务,按难度分组)¶
| 难度(任务数) | RT-1 | Diffusion Policy | SuSIE | GR-1 | VPP |
|---|---|---|---|---|---|
| Easy (28) | 0.605 | 0.442 | 0.560 | 0.725 | 0.818 |
| Middle (11) | 0.042 | 0.062 | 0.196 | 0.327 | 0.493 |
| Hard (11) | 0.015 | 0.095 | 0.255 | 0.451 | 0.526 |
| 平均 (50) | 0.346 | 0.279 | 0.410 | 0.574 | 0.682 |
平均成功率比最强基线 GR-1 高 10.8 个百分点(0.682 vs 0.574)。
4.3 真实世界(两平台;Table 5 类别平均成功率)¶
平台一:Franka Panda(空间鼠标遥操采 2000 条、30+ 任务、6 类);平台二:Xarm + 12-DoF Xhand 灵巧手(Vision-Pro 重定向采数,100+ 任务、13 类,含 4 个工具使用任务)。
| 平台 / 设定 | Diffusion Policy | SuSIE | GR-1 | VPP |
|---|---|---|---|---|
| Panda · Seen | 0.42 | 0.56 | 0.52 | 0.85 |
| Panda · Unseen | 0.25 | 0.46 | 0.38 | 0.73 |
| 灵巧手 · Seen | 0.28 | 0.45 | 0.32 | 0.75 |
| 灵巧手 · Unseen | 0.11 | 0.28 | 0.15 | 0.60 |
| 灵巧手 · 工具使用 | 0.05 | 0.23 | 0.15 | 0.68 |
- Panda 评测 200+ rollouts、灵巧手 500+ rollouts。摘要的"真实灵巧操作成功率 +31.6%"即此处 VPP 相对最强基线的增量量级(绝对值见表)。
- 附录细分(Table 7)特别说明问题:灵巧手上 Cup-upright / Stack / Pass / Unplug 这几类,所有基线(DP/SuSIE/GR-1)几乎全 0(如 Cup-upright 0.00/0.00/0.00),而 VPP 分别拿到 0.64 / 0.64 / 0.48 / 0.52——接触密集 + 高自由度任务上是"从能不能做"的量级差,不是小幅提升。
4.4 视频预测质量(图4 + FVD)¶

Bridge 数据集上 FVD(越低越好):
| 指标 | VideoFusion | Tune-A-Video | Seer | VPP |
|---|---|---|---|---|
| FVD ↓ | 501.2 | 515.7 | 246.3 | 41.4 |
VPP 的 FVD(41.4)远低于前代 TVP(Seer 246.3)——作者归因于用了 SVD 视频基座(前人没用)。
4.5 关键消融¶
消融一:换掉"预测式表征"(其余不变),Table 3。
| 编码器 | 预训练类型 | Avg.Len ↑ |
|---|---|---|
| VDM(本文) | 视频生成 | 4.33 |
| Stable-VAE | VAE 图像重建 | 2.58 |
| VC-1 | MAE 重建 | 1.23 |
| Voltron | MAE 未来重建 + 语言生成 | 1.54 |
消融二:视频预训练 + 架构(Table 4,延迟在 RTX 4090 上测)。
| 配置 | Avg.Len ↑ | 延迟 ↓ |
|---|---|---|
| VPP(全) | 4.33 | ~140ms |
| w/o 互联网数据 | 3.97 | ~140ms |
| w/o Calvin 视频 | 3.31 | ~140ms |
| w/o 互联网数据 + w/o SVD 预训练 | 1.63 | ~140ms |
| w/o Video Former | 3.86 | ~450ms |
| w/o 特征聚合(只用末层) | 3.60 | ~140ms |
消融三:取哪一层特征 / 用几个扩散时间步 / 单视角(Table 10-12)。
| 维度 | 取值与 Avg.Len |
|---|---|
| 上采样层 | L3=3.72 · L6=3.88 · L9=4.29 · L12=4.05 · 聚合(VPP)=4.33(中间偏后层最佳) |
| 扩散时间步 | t=10→4.21 · t=20→4.33 · t=30→4.25(多步无增益、还更慢) |
| 单视角(仅第三人称) | 3.58(仍超用双视角+深度的 3D Diffuser Actor) |
| 去掉 Temporal-attn | 4.18;2 步去噪 |
消融读数:① 拿掉 SVD 预训练直接崩到 1.63 → 视频基座是命根;② 旧式 SSL 编码器(VC-1/Voltron)只有 1.2–1.5,远不如预测式表征;③ 单步去噪足矣,多步只增延迟无收益(印证"当编码器不当去噪器"的核心主张)。
4.6 系统/训练规模(附录)¶
- 阶段一数据共 375,192 条轨迹:互联网人手 something-something-v2 191,642(采样比 0.30)+ 互联网机器人(RT-1 87,212、Bridge 23,377、BC-Z 43,264 等)+ 自采(Panda 2,000、灵巧手 2,476)。
- 算力:TVP 微调 2–3 天 / 8×A100;下游策略 6–12 小时 / 4×A100。
- TVP 预测 horizon=16;可视化用 30 步去噪 + CFG=7.5。
- ⚠️ 数字待核小矛盾:正文说灵巧手采 "4,000 条轨迹",附录 A.2 与表8 写 "2.5k / 2,476 条";正文说 13 类,附录说 10 类。以附录细表为准存疑。
5. 诚实局限 / 存疑¶
- 强依赖视频模型质量:整条链路的天花板是 TVP 的预测准不准;预测错→表征错→动作错。审稿人亦点此。
- 算力门槛高:阶段一 8×A100×2–3 天,普通实验室复现成本不低(虽推理只需单张 4090)。
- 长时程/复杂动态:单步前向取的是"粗略未来走向",更长时域或快速接触动态是否够用未深究。
- 对比公平性争议:SVD 基座 1.5B 参数,对照的 Voltron 仅 ~83M——表征对比里参数量差一个量级(审稿人 xoHf 提出,作者用更多消融回应)。
- CALVIN"提升幅度"口径不一(18.6% / 41.5% / 29%),看相对数时需指明基线。
- 真实灵巧手数据量记述前后不一致(见 4.6)。
- 不含力/触觉:纯视觉预测路线,接触密集任务靠视觉预测+逆动力学硬吃;与触觉路线(本库 卡片-Tactile-VLA 等)是互补而非替代。
6. 核心洞见¶
- 最大贡献是"换视角":把视频扩散模型从"生成器/去噪器"重新定位成"自带未来维度的视觉编码器",只取单步前向的内部表征——既拿到"预见未来"的好处,又躲开"完整去噪太慢"的致命伤。这是它能同时高性能 + 高频闭环的关键。
- "隐式逆动力学"是省数据的来源:策略不需理解新物体/新背景,只需在预测出的未来里追踪机器人自身→ 泛化主要由视频模型扛,策略层只需少量演示对齐。这解释了 10% 数据就超满数据基线、以及未见任务上的强泛化。
- 预测式表征 > 静态 SSL 表征(4.33 vs VC-1 1.23)是本文最干净的实证支撑。
🗣️ 外部评价(同行评议/社区)¶
- 🧑 ICML 2025 评审(OpenReview
c0dhw1du33,录为 Spotlight):4 位审稿人,评分约 4/4/4/3→4(一位 rebuttal 后由 3 升 4),整体正面、共识"动机扎实、评测对齐前人标准、表述清晰"。主要意见: - 训练数据偏 pick-and-place 倾斜;对"物理动态到底编码了什么"分析偏少;相对 GR-1 的提升来源归因不够清楚(Reviewer Y6gd)。
- 性能高度依赖视频扩散模型质量;算力成本大(8×A100×2–3 天);长时程动态捕捉存疑(Reviewer uxTn)。
- 缺与基线的推理速度对比;特征提取的扩散时间步选择交代不清(Reviewer 6CJo)。
- 对比公平性:SVD(1.5B) vs Voltron(~83M) 参数量不对等;与 UniPi 的控制效率主张需澄清(Reviewer xoHf,rebuttal 后加层分析等消融后升分)。
- 来源:OpenReview forum c0dhw1du33(注:公开 API 未直接放出逐条评审正文,以上为论坛页汇总转述,细节以原页为准存疑)。
- 🌐 themoonlight.io 文献综述:纯正面复述(且其引用的"28.1%/28.8%"提升数字与原文 18.6%/31.6% 不符,疑为其转写误差,不采信其数字)。来源:Moonlight review。
- 🌐 收录信息:ICML 2025 Poster/Spotlight 页 · PMLR/ACM 收录。
🧑⚖️ 审稿人视角(🤖 我的专业判断)¶
- 贡献创新性(高):把 VDM 当"预测式编码器、只跑单步"这一观察既新且实用,干净地解决了视频生成式策略"慢/开环"的老大难。属于"小切口、大收益"的好点子。
- 实验扎实度(高):两仿真(CALVIN/MetaWorld)+ 两真机(Panda/灵巧手),含 200–500+ rollouts、消融覆盖编码器/预训练/层/时间步/视角,FVD 量化预测质量。覆盖面在同期工作里偏上。
- 薄弱点 / 存疑:① 提升百分比口径混乱(18.6/41.5/29),易给人挑基线之嫌;② 编码器对比参数量不对等(1.5B vs 83M),"赢在表征类型"还是"赢在参数+数据"未完全切干净;③ 真机数据量记述前后矛盾;④ 全程无力/触觉,接触密集任务的成功更多靠"视觉预测够准 + 数据覆盖"。
- 显著性(高):灵巧手上把多类"基线全 0"的任务做到 0.5–0.8,是质变级证据;数据效率(10%→超满数据基线)对工程落地很有吸引力。
- 可复现性(中):代码已开源(roboterax/video-prediction-policy)、超参/数据比例附录齐全(+);但阶段一需 8×A100 量级算力、依赖特定 SVD 基座,门槛偏高(−)。
- 一句话评级:A−(强接收级 / ICML Spotlight 名副其实)——思路漂亮、实证有质变证据;扣分在"提升口径/对比公平性"的表述与算力门槛。
7. 对我们(深一层)¶
- 同一脉络对照:VPP 与 卡片-GR-1 / 卡片-GR-2 同属"视频预测先验 → 操作"一脉,但 VPP 把"生成器"降级为"单步编码器",是对 GR-1 自回归逐帧路线的效率级改进——做我们的世界模型路线图(综述-世界模型)时,这是"世界模型当表征器 vs 当 rollout 器"的关键样本。
- 与"世界模型当独立 rollout"区分:对照 卡片-iVideoGPT / 卡片-Cosmos / 卡片-DreamerV3——VPP 证明"不必真生成清晰未来、取中间表征即可",工程上更轻,值得我们在自己的预测式表征实验里优先试这条捷径。
- 可借机制:① 单步前向取扩散中间层特征当表征;② 跨上采样层插值+拼接的"免手选层"聚合;③ Video Former 把(时间×空间×多视角)压成定量 token 再喂 DiT policy。三者都可直接迁到我们的 VLA/策略头(参 卡片-DiffusionPolicy / 卡片-RDT-1B)。
- 互补缺口 = 我们的切入点:VPP 全程无触觉。接触密集/灵巧任务它靠"视觉预测够准"硬吃——这正是触觉世界模型(卡片-VT-WM / 卡片-TacForeSight / 卡片-OmniVTA)能补的位置:把"预测式表征"从视觉扩到视触觉,可能在 Cup-upright/Unplug 这类纯接触判定的任务上再上一截。