详读 · RoboCat(自我改进的多本体通用操作智能体)¶
卡片版见 卡片-RoboCat。本页是全文精读:定位 → 动机 → 逐模块方法(自我改进数据飞轮 / VQ-token)→ 全量数字 → 局限 → 洞见 → 外部评价 → 我的判断 → 对我们。 来源:arXiv 2306.11706v2(2023-12-22)· TMLR 12/2023 · DeepMind 官博 作者:Konstantinos Bousmalis、Giulia Vezzani、Dushyant Rao、Coline Devin、Alex X. Lee、Maria Bauza 等(共 39 人,全部 Google DeepMind);资深通讯 Raia Hadsell、Francesco Nori、Nicolas Heess。
0. 一句话定位¶
一个视觉目标条件(goal image)的决策 Transformer,用 Gato 架构 + 冻结 VQ-GAN 图像 tokeniser,原生吃下不同机器人(不同自由度/观测/动作/控制频率)的异构经验,做到:① 单模型跨多本体多任务;② 仅 100–1000 条示范就微调到全新任务/全新机器人;③ 把微调后的策略自己跑出来的数据回灌进下一轮训练 → 自我改进飞轮。核心卖点是飞轮与多本体原生兼容,不是某个单任务 SOTA。
1. 问题与动机¶
- 机器人学习长期"一个任务训一个模型":任务设计 + 采数成本极高,异构机器人数据难以规模化复用。
- 语言/视觉的基础模型(Transformer 规模化)证明了多任务统一建模可行;机器人侧 RT-1 / PaLM-E / Gato 起步,但要么共享同一动作空间、要么只示范了有限机器人操作能力。
- RoboCat 的切入:要做操作领域的"基础智能体(foundation agent)"——在大规模异构机器人经验上训练,能快速微调适配大量下游任务/新本体,并能自产数据持续变强。
- 关键设计赌注:用"视觉目标图"指定任务。好处是——轨迹自己的最后一帧天然就是"事后目标(hindsight goal)",无需额外人工标注即可把任意(含次优)数据回收进训练集 → 这正是自我改进飞轮的燃料。
2. 自我改进飞轮(核心机制,图1)¶
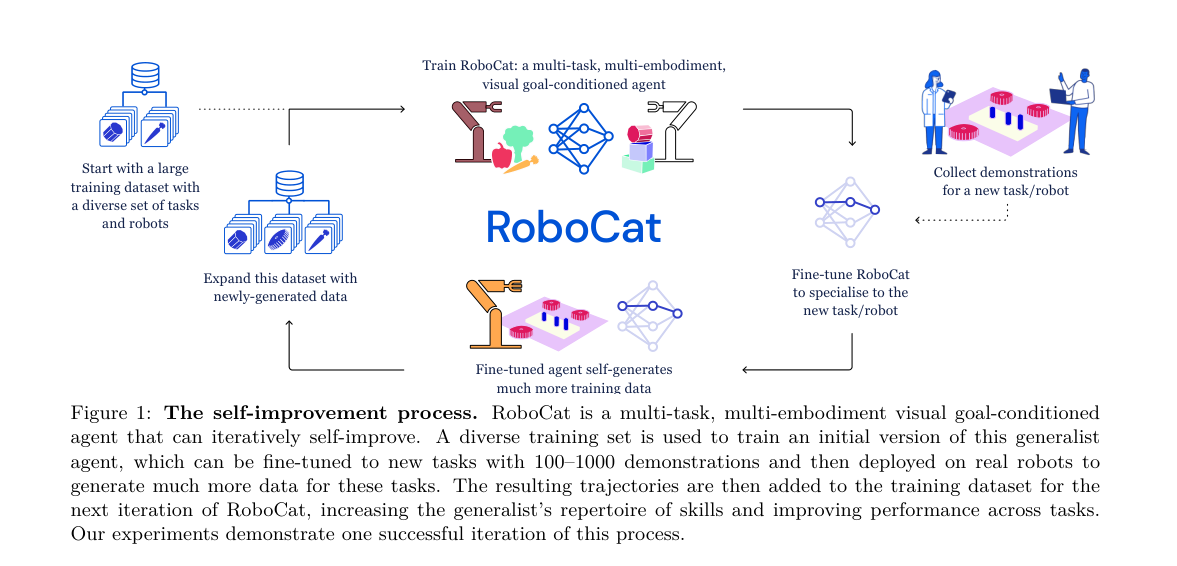 五步循环(本文只完整跑通一轮):
1. 训通才:在多任务/多本体/视觉目标条件的大数据集上训 RoboCat 初版。
2. 采示范:对一个新任务/新机器人,人工遥操作采 100–1000 条示范。
3. 微调专精:
五步循环(本文只完整跑通一轮):
1. 训通才:在多任务/多本体/视觉目标条件的大数据集上训 RoboCat 初版。
2. 采示范:对一个新任务/新机器人,人工遥操作采 100–1000 条示范。
3. 微调专精:θ_ft = argmax_θ L(θ; D_demo),从通才权重初始化,得到专精该任务的策略(可能在旧任务上退化)。
4. 自产数据:把冻结的微调策略部署到真机自动跑大量轨迹(官博:每任务自练 ~10,000 次),用事后目标重标注(语义等价目标需奖励模型判成功)。
5. 并回训下一代:D_next = D ∪ (D_demo ∪ D_imp),重训新 VQ-GAN再训新通才。
⚠️ 作者反复强调:这不是在线 RL——采数用的是冻结模型,人起停;学习是从固定数据源做的离线监督学习,与采数完全解耦(也是其 AGI 安全论证:无自主在线学习)。
3. 逐模块方法¶
3.1 任务表示:视觉目标条件 + 事后目标¶
- 策略
π(a_t | o_t, g_t),o_t=(x_t, I_t)(本体感知 + 图像),g_t是目标状态的一张图(只说"做哪个任务",不指定要到达的具体状态;只按末状态判成败)。自回归建模P_θ(a_t | x_<t, I_<t, g_<t)。 - 目标来源两种:① 事后目标——用同一条轨迹的最后一帧
g=I_{T+1}(任何轨迹对自己末帧"必然成功",故无需标注,次优/失败数据也能用);② 语义等价目标——用同任务另一条成功轨迹的末帧(需奖励模型判成功)。失败轨迹只用事后目标。
3.2 架构与 token 化(VQ-token 是关键提速点)¶
- 基于 Gato 解码器式 Transformer。本体感知 / 动作 token 化沿用 Gato。
- 图像用冻结预训练 VQ-GAN(而非 Gato 的在线 ViT patch):每张图一次性编码成 8×8=64 个离散 token,可预先离线编码 → 通才训练显著提速、便于快速迭代。VQ-GAN 在 ImageNet + Gato 控制图(Atari、MuJoCo)+ 自家机器人操作图上预训练(多样性提升泛化)。
- 变长原生多本体:不同机器人本体感知维
L、动作维Q不同,靠 Transformer 变长输入输出天然吸收,无需统一动作/观测表示。 - 上下文:固定 1024 token(约 3 个时间步历史)。
- 训练损失(式3)= 动作 token 预测 + 未来图像 token 预测:除预测动作外,额外预测 k=5 步后的图像 token(相邻帧太像,故跳 5 步)。消融证明加图像预测能提升性能(Gato 只预测动作)。
3.3 微调¶
- 每任务采 100–1000 条遥操作示范,与通才同样的 token 化 + 目标增广;从通才权重初始化做监督微调。
3.4 真机自主采数的两个工程难点¶
- 成功检测(奖励模型):众包标注"任务在第几步后算成功"→ 训二分类视觉奖励模型,用于语义等价目标重标注 + 判何时该 reset。最终评测数字仍人工肉眼计数保准确。
- 自主复位(policy pool 策略池):手写 reset 几乎和解任务一样难。观察到"某些任务的末状态 = 另一些任务的始状态",于是把一组首尾状态重叠的策略凑成池子轮流跑,互为复位 → 自动复位 + 提高机器人利用率 + 增加初始条件多样性。分无状态池(按序跑,如抓取)与有状态池(按奖励模型判当前态选下一个策略,如插入成功后跑取出)。所有插入/取出任务不用任何外部 reset,只靠互逆的取出/插入。
4. 全量数字¶
4.1 规模一览¶
| 维度 | 数字 |
|---|---|
| 任务总数 | 253(240 训练 + 13 微调) |
| 任务族 | 5 仿真 + 11 真实 |
| 本体 | 2 仿真 + 3 真实 |
| 物体 | 123 仿真 + 134 真实 |
| 真机数量 | 36 台(15 Panda + 17 Sawyer + 4 KUKA) |
| 主模型 | 1.18B 解码器 Transformer(24 层,embed 2048,FFN 隐 8196) |
| 小模型(消融) | 364M |
| 上下文 | 1024 token(≈3 步历史);每图 8×8 token;未来图像预测 k=5 |
| 微调样本 | 100–1000 条示范/任务 |
| VFM 基线 | 评了 59 个,选最优两个:NFNet-f6(438M)、Swin-L(197M),均 CLIP 预训练 |
4.2 本体与物体(图2、图3)¶
 - 训练本体:Sawyer 7-DoF(仿真)/ 5-DoF(真实)、Panda 7-DoF(仿真+真实),均配 Robotiq 平行夹爪;动作 = 6-DoF/4-DoF 笛卡尔末端控制 + 1 维夹爪。
- Held-out 本体:KUKA 14-DoF + 自研三指手,只在微调阶段出现(训练完全没见过)。
- 训练本体:Sawyer 7-DoF(仿真)/ 5-DoF(真实)、Panda 7-DoF(仿真+真实),均配 Robotiq 平行夹爪;动作 = 6-DoF/4-DoF 笛卡尔末端控制 + 1 维夹爪。
- Held-out 本体:KUKA 14-DoF + 自研三指手,只在微调阶段出现(训练完全没见过)。
 - RGB 物体 116 个(参数化形状,研究堆叠/搭建);NIST-i 齿轮(大中小)+ 3 桩底座(1mm 公差,真机底座不固定更难);YCB 水果(苹果/香蕉/桃/柠檬/草莓)+ YCB-i 蔬菜(胡萝卜/黄瓜/辣椒/土豆)+ 碗;形状匹配木块(圆/五边形/方)。
- RGB 物体 116 个(参数化形状,研究堆叠/搭建);NIST-i 齿轮(大中小)+ 3 桩底座(1mm 公差,真机底座不固定更难);YCB 水果(苹果/香蕉/桃/柠檬/草莓)+ YCB-i 蔬菜(胡萝卜/黄瓜/辣椒/土豆)+ 碗;形状匹配木块(圆/五边形/方)。
4.3 最终 RoboCat 在评测任务上的成功率(Table 1,节选)¶
| 类别 | 本体·任务族·物体 | 平均成功率 |
|---|---|---|
| 训练·仿真 | Sawyer 7-DoF 堆叠(RGB&齿轮) | 82% |
| 训练·仿真 | Panda 7-DoF 堆叠 | 80% |
| 训练·仿真 | Panda 搭塔 / 搭金字塔 | 60% / 65% |
| 训练·仿真 | Panda 齿轮 抬升 / 插桩 | 88% / 75% |
| 训练·真实 | Sawyer 堆叠(红上蓝 / 蓝上绿) | 80% / 45% |
| 自我改进任务·真实 | 搭塔 / 倒金字塔 | 23% / 17% |
| 自我改进任务·真实 | 蔬菜抬升 / 水果抬升 | 54% / 54% |
| 自我改进任务·真实 | 齿轮 抬升 / 插桩 / 取桩 | 94% / 77% / 97% |
| 微调(500/1000 条) | Panda 水果入碗 插入 / 取出 | 84%/84% · 64%/72% |
| 微调(500/1000 条) | Panda 形状插底座 / 取出 | 6%/13% · 70%/82% |
| 微调(500/1000 条) | KUKA 14-DoF 齿轮抬升(全新本体) | 56% / 86% |
评测协议:每任务对 ≥100 episode 取平均、每 episode 用不同目标图与随机初态;选 checkpoint 时每 5000 步评 25 集,最优 checkpoint 再评 100 集。全文做了数万次真机评测。
4.4 对比基线 / 飞轮 / 泛化(图5、图7c、Table 2/3)¶
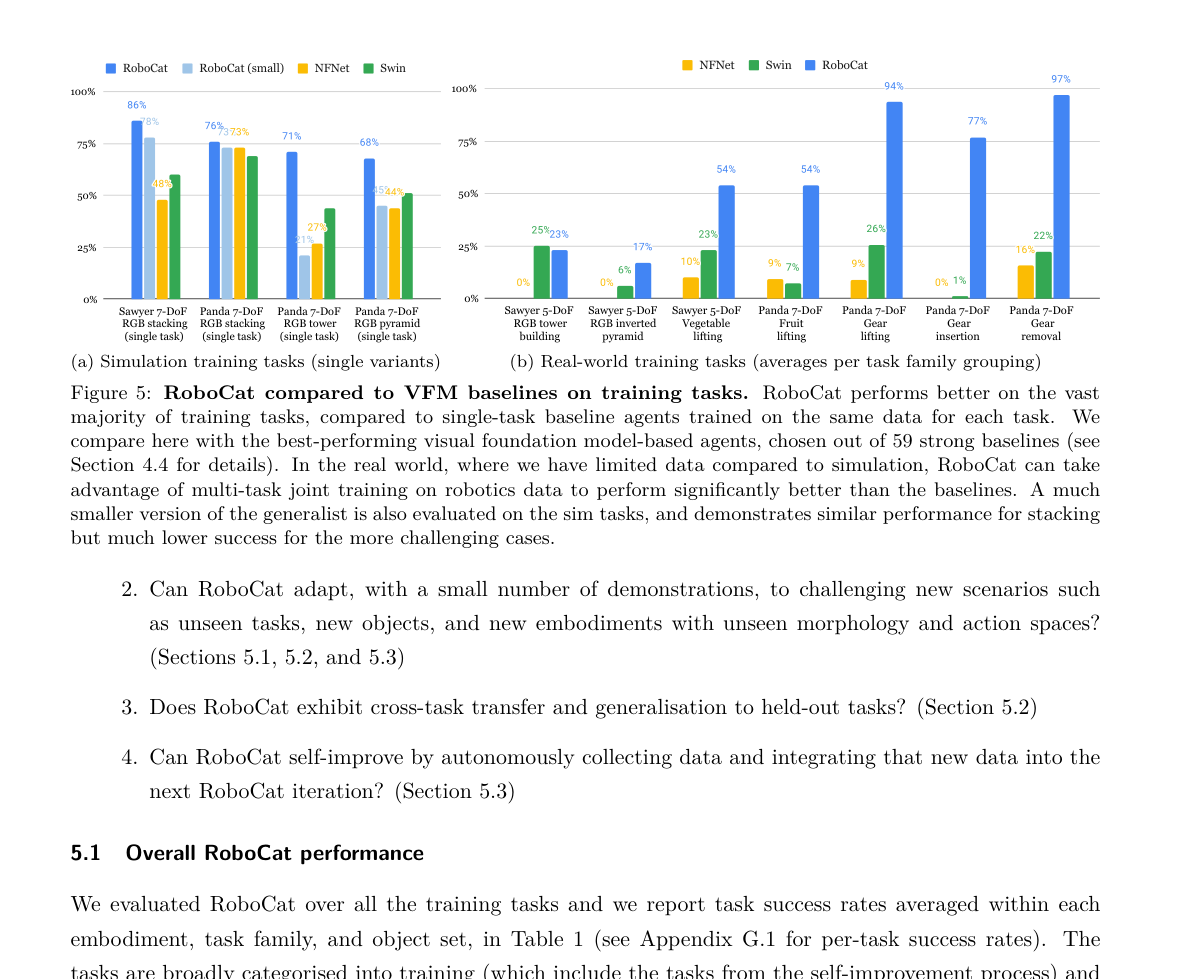
RGB Stacking Mastery 基准(Table 2,与前作同条件 Sawyer 真机)
| 方法 | T1 | T2 | T3 | T4 | T5 | 平均 |
|---|---|---|---|---|---|---|
| RoboCat | 87% | 70% | 82% | 93% | 68% | 80% |
| BC-IMP(专才) | 75% | 61% | 74% | 95% | 88% | 79% |
| Gato(通才) | 58% | 59% | 81% | 96% | 96% | 78% |
解读:RoboCat 在会很多别的任务的同时,单基准上与专才/Gato 打平(≈80%)——卖点是"广而不弱",不是刷爆这一个榜。
自我改进有效性 / 数据来源(Table 3,蓝上绿真机变体,0-shot=0%)
| 微调数据来源 | 100 集 | 500 集 |
|---|---|---|
| 专家 agent 数据 | 63% | 84% |
| 人类示范数据 | 82% | 88% |
同任务上 RoboCat-lim 用 500 条达 88%,对比 Gato 报告的 60%。倒金字塔任务连遥操作员成功率也只有 52%(任务本身极难)。
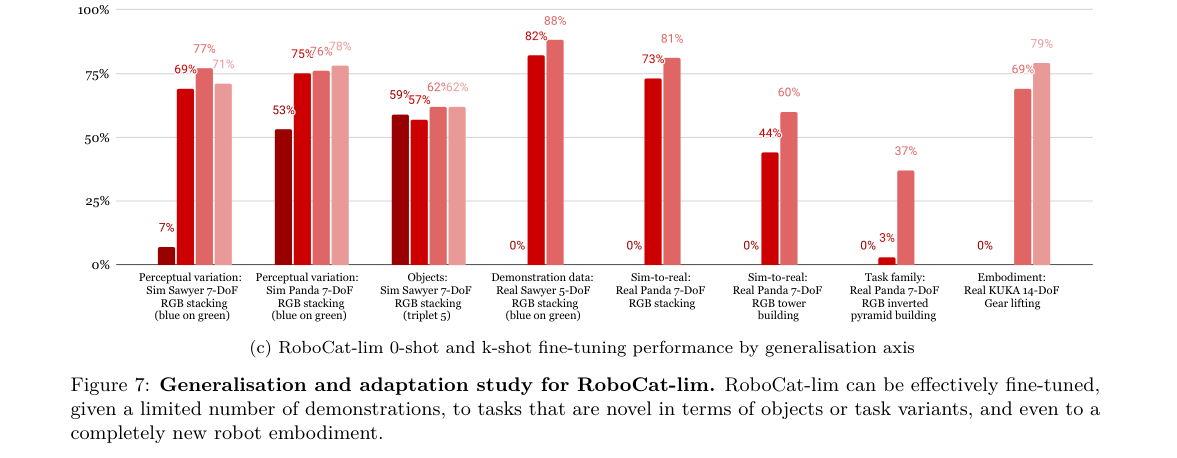 - 正迁移:训更多任务的完整 RoboCat 在 RoboCat-lim 那批任务上反而更好(不是被稀释,而是跨任务正迁移)。
- 新本体:KUKA 14-DoF 零样本 0%(动作/观测空间全不同),微调后 69%(RoboCat-lim)/ 86%(完整 RoboCat,1000 条)——证明多本体训练的价值。
- 飞轮净收益:364M 小实验中,"微调+自产数据回灌"的自改进模型在全部 4 个任务上优于只把示范直接塞进训练的基线;官博:早期版本未见任务 36% → 训练更多样后翻倍。
- 正迁移:训更多任务的完整 RoboCat 在 RoboCat-lim 那批任务上反而更好(不是被稀释,而是跨任务正迁移)。
- 新本体:KUKA 14-DoF 零样本 0%(动作/观测空间全不同),微调后 69%(RoboCat-lim)/ 86%(完整 RoboCat,1000 条)——证明多本体训练的价值。
- 飞轮净收益:364M 小实验中,"微调+自产数据回灌"的自改进模型在全部 4 个任务上优于只把示范直接塞进训练的基线;官博:早期版本未见任务 36% → 训练更多样后翻倍。
5. 局限 / 存疑(含作者自陈)¶
- 纯行为克隆,无 RL:靠视觉目标能从失败/次优数据学,但不显式用奖励、不在线交互;作者把 RL 列为未来工作。
- 实验室封闭环境:所有本体都在标准 cage 内、背景视觉相近;作者明说尚未验证不同筐底纹理 / 野外视觉多样性下的鲁棒性。
- 只跑通一轮飞轮:"one successful iteration"——长期多轮的累积收益/是否会数据污染/退化,未验证。
- 依赖奖励模型 + 众包标注做成功检测与语义等价重标注,引入标注/分类器误差。
- 任务规模与公差受限:3 步历史上下文很短;插入是 mm 级桌面任务,非长程复杂装配。
- 不开源:未释放权重/数据(仅研究用、未部署);社区有非官方复现(kyegomez/RoboCAT),与官方无关。
- 形状插底座极弱:微调 500 条仅 6%、1000 条 13%——需重定向的精细插入仍是硬骨头。
6. 核心洞见¶
- 视觉目标 = 免费的事后标注:把任务用"目标图"指定,使任意轨迹(含失败)天然可重标注回收,这才是自我改进飞轮能转起来的底层原因——比"奖励工程"或"语言标注"门槛低。
- 冻结 VQ-token 是规模化的工程关键:图像一次性离线 token 化,让 1.18B 通才在异构数据上训得动、迭代快;外加未来图像预测做辅助监督提样本效率。
- 多本体原生兼容比"统一动作空间"更可扩展:用变长序列吸收异构 DoF,新本体只需少量微调即可挂上(KUKA 0→86%)。
- 范式 > 单点 SOTA:单基准只打平专才,但"一个模型 + 飞轮 + 低成本上新本体"是面向 foundation agent 的路线证明。
🗣️ 外部评价¶
- 🌐 TMLR 接收(2023/12,Google DeepMind),公开评审:OpenReview vsCpILiWHu。这是经过同行评审的正式刊出(A 级出处)。
- 🌐 DeepMind 官方博客自述定位为"自我改进的机器人智能体":1000 条示范后新机械臂抓齿轮成功率 86%;早期版本未见任务 36% → 训练更多样后翻倍。blog
- 🌐 主流科技媒体多为转述式正面报道(介绍"自训练/自产数据"卖点,少独立批判):InterestingEngineering、IoT World Today、OpenDataScience。
- 🧑 社区复现:kyegomez/RoboCAT 为个人非官方实现(DeepMind 未开源权重/数据),可参考结构但非作者背书。
- ⚠️ 检索到的英文外评以新闻转述 + 官方口径为主,未找到有分量的独立"差评/复现质疑"长文;OpenReview 评审意见为正式评价来源(如需细看审稿人异议,见该 forum)。本节如实标注:缺独立批判性深评。
🤔 我的判断(🤖)¶
- 真正可借的是"飞轮设计"而非模型本身:视觉目标 → 事后目标免标注 → 冻结模型自产数据 → 离线监督回灌。这套对我们的数据流水线有直接启发——只要任务能用"末状态图"判成败,就能把评测/部署时跑出的废数据变成训练燃料。
- 诚实度可圈:作者自己点出单基准只打平、形状插入很弱、只跑一轮、实验室封闭——不是夸大型 PR 论文。
- 对资源的清醒:36 台真机 + 数万次真机评测 + 1.18B 模型,是工业级体量,直接复用不现实;价值是方法论(A 级证据,范式价值 > 复用价值),与卡片判断一致。
- 与当前 VLA 主线的关系:它走视觉目标条件而非语言条件,作者自己也把语言/VLM 条件列为未来工作——所以它更像"会自产数据的多本体 BC 通才",而非语言可指挥的 VLA。看它要看飞轮,不要拿它当 RT-2 类语言 VLA 对标。
7. 对我们(深一层)¶
- 数据飞轮 = 数据护城河的另一形态:和遥操作采数(详读-DexTeleop-0)互补——DexTeleop 攻"人采得又快又好",RoboCat 攻"模型自己采得多"。两条路都指向同一痛点:接触/操作数据贵。归到 概念-机器人数据与标注 一起看。
- 免标注回收机制可直接迁移:我们若有"目标图判成败"的任务,可照搬事后目标重标注,把部署轨迹无成本回灌。
- 冻结 VQ-token + 未来帧预测是一个低成本提样本效率的配方,值得在自己的小模型上试。
- 关联:卡片-RoboCat(摘要级)· 卡片-Octo(另一通用操作策略,对照"语言/动作扩散 vs 视觉目标 BC")· 概念-机器人数据与标注。