详读 · TacForeSight(力引导的触觉世界模型,用于接触密集操作)¶
卡片版见 卡片-TacForeSight。本页是全文精读:动机 → 方法(逐模块公式直觉) → 实验(全表) → 洞见/局限 → 对我们。 来源:arXiv 2606.11184(2026-06-09,6页 RA-L/会议体例)· 项目页 作者:Yujie Zang、Yuhang Zheng、Xian Nie(共一)等,通讯 Shuicheng Yan(颜水成, NUS)+ Wenchao Ding(丁文超, 复旦)。单位:TARS Robotics · 新加坡国立 NUS · 上海交大 · 中科院自动化所 · 复旦。
0. 一句话定位¶
抓住一个时序非对称规律——手腕 6 轴力/力矩(wrench)的变化比指尖触觉早一拍——把"先到的力"当条件去预测"还没到的触觉",在一个压缩隐空间里推演短时未来触觉,再把这个"前瞻接触先验"喂给策略,让机器人在接触密集任务里前瞻控制而非被动反应。全系统极小(世界模型 11.8M + 策略 68.9M)、实时(20Hz / RTX4090D)。
1. 问题与动机(图1)¶
- 接触密集操作的痛点:执行中接触力、局部几何、物体位姿的微小变化会迅速改变交互状态 → 打滑(slippage)、错位(misalignment)、失接触(contact loss)。要做好必须持续感知并调节正在演化的物理交互。
- 旧法的局限:近年模仿学习把触觉/腕力塞进视觉运动策略,但要么把力和触觉当两个模态硬融合成联合表征,要么当被动反馈做反应式控制。它们没有显式建模"全局力"与"局部触觉"在时空上的非对称角色——
- 腕部 wrench:高频(120Hz)、给全局外载变化线索;
- 光学触觉:捕捉细粒度局部形变。
- 关键观察(核心切入):在 Bulb Insertion & Locking(灯泡插入锁定) 中,腕部 wrench 的突变一致地早于指尖触觉响应出现 → 存在一个 coarse-to-fine 的时序依赖:全局力是未来触觉状态的领先指标(leading indicator)。
- 类比人类感觉运动控制:人用"载荷相关线索"去预判物体交互状态、引导局部接触微调(文献 Johansson & Flanagan)。作者据此显式建模 force→tactile 的预测过程。
2. 核心思想¶
不是"提高触觉分辨率"或"更强的融合",而是把跨模态因果(力先于触觉)做成一个预测环: 1. 用高频腕力作条件,在隐空间预测短时未来触觉潜变量(世界模型 TacForceWM); 2. 把"当前触觉 + 预测的未来触觉"通过 cross-attention 建成当前↔未来交互,得到"前瞻触觉表征"; 3. 用这个前瞻表征门控(gating)视触觉融合——接触/扰动时放大触觉通道; 4. flow-matching 动作头据融合特征输出动作 chunk。
整个推演只在低维隐空间进行(不渲染高维触觉图、不做像素级视频生成) → 这是它能做到实时 20Hz 的根本原因。
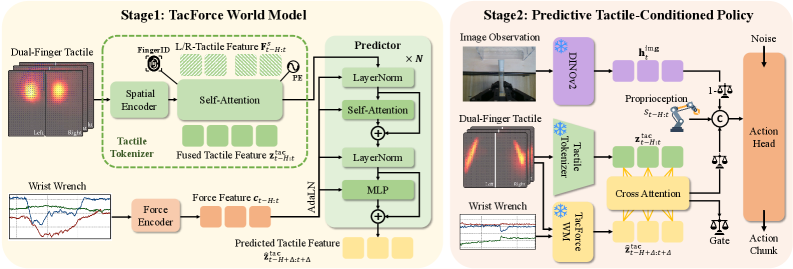
3. 总体架构(图2)¶

级联式(cascaded):Stage1 先预训练力条件世界模型预测短时触觉演化 → 冻结触觉编码器与预测器 → Stage2 用其隐表征做 flow-matching 动作序列预测。
4. 方法详解¶
4.1 触觉 Tokenizer(把形变图压成一个 token)¶
- 输入:每指触觉场
X_t^s ∈ R^{H×W×3},s∈{L,R},3 通道是每个空间位置的 3D marker 位移(稠密形变)。实测分辨率 35×20。 - 共享空间编码器 Φ_sp(残差卷积 + 分层下采样)抽局部形变特征
F_t^s,左右指共享权重。 - 加 可学空间位置嵌入 E_pos + 手指身份嵌入 E_id^s(区分左右指角色)。
- 展平成 patch token,前置
[CLS],对拼接的左右指 token 跑 Transformer(指内空间模式 + 指间交互依赖),取[CLS]作帧级触觉隐变量z_t ∈ R^{D_z}—— 一帧手内交互状态的紧凑表示。
4.2 力编码器(把 120Hz 力对齐成触觉的条件)¶
- 输入 6 轴 wrench 序列
w_{t-nH:t} ∈ R^{nH×6}(采样率是触觉的 n 倍)。 - 先投影到隐空间,再用 dilated causal 1D 卷积(WaveNet 式)抓多尺度时序力变化,因果下采样把高频力特征对齐到触觉隐序列:
c_{t-H:t} = G_φ(w_{t-nH:t})。 - 直觉:保持时间因果性(只用过去),把连续 wrench 模式翻译成"对触觉演化有物理信息量"的条件流。
4.3 隐动力预测器(chunk 式预测未来触觉)¶
- 关键设计:预测未来隐变量而非重建原始触觉(借 V-JEPA 思路,省算力),且chunk 式(一次预测一段)而非逐帧单步 → 时序更连贯。
- 给当前触觉隐 chunk
z_{t-H:t}与对齐力条件c_{t-H:t},预测带时间偏移 Δ 的未来 chunk:ẑ_{t-H+Δ:t+Δ} = T_ψ(z_{t-H:t}, c_{t-H:t}),T_ψ是力条件隐 Transformer。 - 力条件经 AdaLN(自适应层归一化)注入(DiT 式)——按当下 wrench 上下文调制中间特征。直觉:力不是简单拼接进去,而是"调相机参数式"地改写每层归一化,使预测随力实时变。
4.4 世界模型训练目标¶
- 预测损失同时监督绝对未来隐与其一阶时序差分(抓演化趋势、防止预测过平滑):
L_pred = MSE(Ẑ, Z) + λ_dyn · MSE(∇Ẑ, ∇Z),∇ 是 chunk 维一阶差分,λ_dyn=1.00。 - 防表征坍塌:借 LeJEPA 的 SIGReg(Sketched Isotropic Gaussian Regularizer),把触觉隐分布正则到各向同性高斯,
λ_sig=0.09。 - 总目标:
L_WM = L_pred + λ_sig · L_sig。
4.5 预测式触觉条件策略(Stage2)¶
- 多模态特征抽取:冻结 DINOv2-small 编 RGB →
h_t^img;本体历史s_{t-K+1:t}经 MLP →h_t^s;触觉 tokenizer 编近 H 帧 →z_{t-H:t};冻结的世界模型据此+力特征预测未来触觉Ẑ_t。 - 当前↔未来触觉交互(cross-attention):分别给当前/未来隐加可学时间嵌入,以当前隐作 Query、预测未来隐作 Key/Value 做 CA,残差结构把"当下接触状态"用"预测动力学"增强,再时间维平均得紧凑前瞻触觉表征
h_t^tac。 - 自适应视触觉门控融合(逐通道,非 token 级):
α = σ(MLP(h_t^tac)),h_t^vt = (1-α)⊙h_t^img + α⊙h_t^tac。直觉:门控由触觉算出,接触/动态时放大触觉、平稳时偏视觉,避免触觉噪声污染。 - flow-matching 动作头:融合特征
h_t^vt+ 本体h_t^s拼成全局条件y_t;线性插值路径A_t^(τ)=(1-τ)A^(0)+τA^(1),时序 U-Netv_θ学速度场L_FM = E‖v_θ(A^(τ),τ,y_t) - u_t‖²;推理从噪声积分 ODE(τ:0→1)得动作 chunk。
5. 实验¶
5.1 设置¶
- 平台:7-DoF UFactory xArm7 + Robotiq 2F-85 夹爪 + 腕装 RealSense D435 + UFactory 6 轴力/力矩传感器 + 双指各一 Xense 光学触觉。图像/触觉 30Hz,腕 wrench 120Hz,触觉输出 35×20 3D 位移图。
- 训练:世界模型 11.8M 参数、2700 条力-触觉交互 episode(任务演示 + 多样接触数据)、150k steps、
λ_dyn=1.00 / λ_sig=0.09;冻结后训 flow-matching 策略 68.9M 参数;8× A100。推理 20Hz / RTX4090D。 - 基线:DP(Diffusion Policy, 仅腕 RGB+本体)、DP+Tactile+Force(DP 多模态扩展)、KineDex(触觉感知、联合预测动作+触觉)、FoAR(力感知 + 未来接触预测器,公平起见点云编码器换 2D RGB)、RDP(Reactive Diffusion Policy,反应式视触觉在线精修)。
- 指标:每法每任务 20 次独立 trial,报平均完成分。Wiping/Swiping = 完成长度/目标长度;Tube Adjustment/Bulb Locking 两阶段(过一阶 50%、全过 100%);Wire Insertion 全插入才算成功;扰动设置下必须从扰动恢复并完成才算成功。
5.2 任务(图3)¶
5.3 主结果(表I:完成分%,每格 20 trials)¶
| 策略 | Wiping | Swiping | Adjustment | Locking | Insertion | Wiping-P | Swiping-P | Adjustment-P |
|---|---|---|---|---|---|---|---|---|
| DP | 70 | 35 | 30 | 10 | 15 | 0 | 0 | 0 |
| DP+Tactile+Force | 80 | 40 | 35 | 30 | 15 | 25 | 0 | 35 |
| KineDex | 30 | 35 | 25 | 45 | 30 | 10 | 0 | 0 |
| FoAR | 50 | 50 | 35 | 25 | 20 | 30 | 0 | 25 |
| RDP | 85 | 50 | 25 | 55 | 0 | 35 | 65 | 0 |
| Ours(TacForeSight) | 100 | 85 | 70 | 80 | 60 | 90 | 85 | 85 |
- 5 个常规任务平均 79.0%,全面大幅超基线;最难的 Wire Insertion 它 60% 而 RDP 直接 0%。
- 三个扰动任务平均 86.7%(90/85/85),优势在扰动下更明显——预测式触觉先验提升了"接触动态变化时的恢复鲁棒性"。多数基线在扰动列大量挂零(尤其 Swiping-P 仅 RDP 65%、其余全 0)。
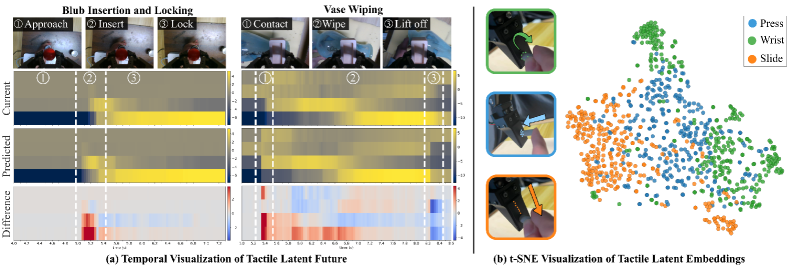
5.4 触觉表征分析(图4)¶
- 时序前瞻:预测的未来触觉隐在接触状态切换前约 200ms 就出现接触相关变化,隐差异在关键接触阶段切换处显著 → 世界模型确实抓到时序接触演化、给出前瞻线索。
- 判别性:在未见过的 force-tactile episode(按压/扭转/滑动)上,触觉编码器抽的序列级嵌入在 t-SNE 里按接触模式形成清晰分簇 → 学到了超出训练分布的接触判别表征。
5.5 消融一:世界模型用什么作条件(表II)¶
| 条件 | MSE↓ | Cos↑ | KL_sym↓ |
|---|---|---|---|
| w/o Condition | 0.027 | 0.954 | 0.014 |
| RGB Image | 0.025 | 0.973 | 0.013 |
| Robot State | 0.022 | 0.975 | 0.011 |
| Wrist Wrench | 0.017 | 0.992 | 0.009 |
腕力条件三项指标全胜:相比无条件,MSE 0.027→0.017、KL_sym 0.014→0.009、Cos 0.954→0.992。说明腕 wrench 是预测触觉演化信息量最高的物理条件(它直接捕捉接触中的物理交互变化),胜过 RGB 和机器人状态。
5.6 消融二:策略各组件(表III:完成分%,20 trials)¶
| 变体 | Wiping | Wiping-P | Swiping-P |
|---|---|---|---|
| Parallel fusion(力-触觉直接并联) | 80 | 25 | 10 |
| w/o force condition | 70 | 50 | 75 |
| w/o predicted tactile | 65 | 15 | 15 |
| w/o cross-attention | 100 | 65 | 0 |
| w/o adaptive gate | 90 | 65 | 75 |
| Ours | 100 | 85 | 90 |
- 去掉预测触觉(只用当前触觉)在两个扰动任务上重挫(15/15) → 未来触觉先验对"维持/恢复接触"关键。
- Parallel fusion 扰动下很差(25/10) → 简单力-触觉拼接不足以鲁棒恢复。
- 去 cross-attention 在 Swiping-P 直接 0% → 显式当前↔未来交互重要。
- 去自适应门控:Wiping-P 降到 65%,且恢复时间从 2.56s 增到 4.06s → 门控改善扰动恢复时的接触调节。
- 全模型 100/85/90 全项最佳。
6. 诚实读数 / 局限¶
- 样本偏小:每格仅 20 trials,5 任务 + 3 扰动,无置信区间/方差报告;任务为作者自选接触密集任务,有挑任务嫌疑,统计强度有限。
- 承诺开源未落地:项目页声明"models & datasets will be made publicly available",但截至成稿尚未实际放出,无第三方复现/评阅(2026-06 太新)。证据等级 B。
- 硬件门槛:需 2× Xense 光学触觉 + 6 轴 F/T + 视触觉,整套估 ¥8–15 万;触觉传感器易损/需标定。
- "200ms 前瞻"是 PCA 定性可视化(图4a)结论,非严格量化前瞻精度指标。
- 基线公平性微调:FoAR 把原点云编码器换成 2D RGB"以求公平"——可能影响其上限。
- 级联+冻结:世界模型预训练后冻结,未端到端联训,是否最优未消融。
7. 核心洞见¶
- 跨模态时序因果是可利用的免费先验:力先于触觉这一非对称性,让"用先到的力预测滞后的触觉"成立——这是别家(并联融合/被动反馈)没显式建模的角度。
- 隐空间预测 = 前瞻 + 实时的兼得:只在低维隐空间推演(不渲染触觉图/不生成视频),是它在 11.8M+68.9M 小体量下做到 20Hz 的根本,证明"预测式物理推理"可以很轻。
- 门控由触觉算、按接触阶段变:与 TacVLA/OmniVTA 的 gating 共识一致——接触时放大触觉、平稳偏视觉,是接触密集策略的稳健范式。
8. 对我们¶
- 与 卡片-LaWAM 同构:都是"隐空间预测未来 + 小推演器 + gating",只是 LaWAM 在视觉、它在触觉 → 隐空间世界模型是跨模态可复用范式(详见 TacForeSight×LaWAM-对照)。
- 它补了 LaWAM 没有的"跨模态因果条件":用先行的力预测滞后的触觉,这个 trick 可搬到我们的多模态推演器(把"先行模态"当 AdaLN 条件)。
- 可对照方向:视觉侧 卡片-LaWAM 与触觉侧本篇是同构的隐空间预测,对照见 TacForeSight×LaWAM-对照。
- 架构基础对照:AdaLN 条件注入、cross-attention 当前↔未来、flow-matching 动作头都是可复用积木,归入 概念-模型架构基础。
- 互为对照(数据/部署路线):它加指尖触觉+力把接触做精;另一类思路用更少/更廉价的力触觉做接触感知,两条路线可长期对照。